عمليات Apache Spark التي يدعمها Hive Warehouse Connector في Azure HDInsight
توضح هذه المقالة العمليات المستندة إلى شرارة، والمدعومة بواسطة Hive Warehouse Connector (HWC). سيتم تنفيذ جميع الأمثلة الموضحة أدناه من خلال غلاف Apache Spark.
المتطلب الأساسي
أكمل خطوات إعداد موصل Hive Warehouse.
الشروع في العمل
لبدء جلسة شرارة، قم بالخطوات التالية:
استخدم الأمر ssh للاتصال بنظام مجموعة Apache Spark الخاص بك. قم بتحرير الأمر أدناه عن طريق استبدال اسم نظام المجموعة باسم نظام مجموعتك ثم إدخال الأمر:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netمن جلسة ssh الخاصة بك، قم بتنفيذ الأمر التالي لملاحظة إصدار
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorقم بتحرير التعليمة البرمجية أدناه باستخدام الإصدار
hive-warehouse-connector-assemblyالمحدد أعلاه. ثم نفّذ الأمر لبدء spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseبعد بدء إصدار spark-shell، يمكن بدء مثيل Hive Warehouse Connector باستخدام الأوامر التالية:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
تكوين Spark DataFrames باستخدام استعلامات Hive
يتم إرجاع نتائج كافة الاستعلامات التي تستخدم مكتبة HWC كإطار بيانات. توضح الأمثلة التالية كيفية إنشاء استعلام خلية أساسي.
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
نتائج الاستعلام هي Spark DataFrames، والتي يمكن استخدامها مع مكتبات Spark؛ مثل: MLIB، وSparkSQL.
كتابة Spark DataFrames لجداول Hive
لا يدعم Spark أصلاً الكتابة إلى جداول ACID المُدارة الخاصة بـ Hive. ومع ذلك، باستخدام HWC، يمكنك كتابة أي DataFrame في جدول Hive. يمكنك رؤية هذه الوظيفة في العمل في المثال التالي:
أنشئ جدولا يسمى
sampletable_coloradoوحدد أعمدةه باستخدام الأمر التالي:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()قم بتصفية الجدول
hivesampletableحيث يساويColoradoالعمودstate. يقوم استعلام الخلية هذا بإرجاع Spark DataFrame ويتم حفظ النتيجة في جدولsampletable_coloradoHive باستخدام الدالةwrite.hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()اعرض النتائج بالأمر التالي:
hive.table("sampletable_colorado").show()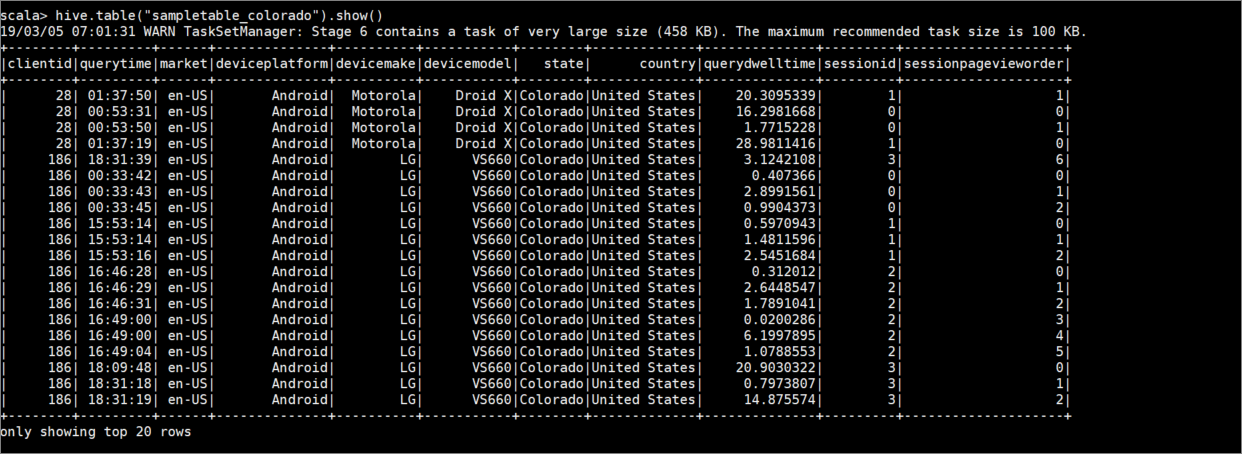
يكتب التدفق المنظم
باستخدام Hive Warehouse Connector، يمكنك استخدام Spark Streaming لكتابة البيانات في جداول Hive.
هام
عمليات الكتابة المتدفقة الهيكلية غير مدعومة في مجموعات Spark 4.0 التي تم تمكين ESP لها.
اتبع الخطوات أدناه لاستيعاب البيانات من تدفق شرارة على منفذ المضيف المحلي 9999 في جدول خلية عبر. موصل مستودع خلية النحل.
من غلاف Spark المفتوح، ابدأ دفق شرارة باستخدام الأمر التالي:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()قم بإنشاء بيانات لتيار Spark الذي قمت بإنشائه، من خلال القيام بالخطوات التالية:
- افتح جلسة SSH ثانية على نفس مجموعة Spark.
- في نافذة الأوامر، يُرجى كتابة
nc -lk 9999. يستخدمnetcatهذا الأمر الأداة المساعدة لإرسال البيانات من سطر الأوامر إلى المنفذ المحدد.
ارجع إلى جلسة SSH الأولى، وأنشئ جدول Hive جديدًا لاحتواء البيانات المتدفقة. في قذيفة شرارة، أدخل الأمر التالي:
hive.createTable("stream_table").column("value","string").create()ثم اكتب بيانات التدفق إلى الجدول الذي تم إنشاؤه حديثًا باستخدام الأمر التالي:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()هام
يجب تعيين الخيارين
metastoreUriوdatabaseيدويا حاليا بسبب مشكلة معروفة في Apache Spark. لمزيد من المعلومات حول هذه المشكلة، راجع SPARK-25460.ارجع إلى جلسة SSH الثانية، وأدخل القيم التالية:
foo HiveSpark barارجع إلى جلسة SSH الأولى، ولاحظ النشاط الموجز. استخدم الأمر التالي لعرض البيانات:
hive.table("stream_table").show()
استخدم Ctrl + C للتوقف netcat في جلسة SSH الثانية. استخدم :q للخروج من spark-shell في جلسة SSH الأولى.