استخدم Apache Spark MLlib لإنشاء تطبيق للتعلم الآلي وتحليل مجموعة بيانات
تعلم كيفية استخدام Apache Spark MLlib لإنشاء تطبيق التعلم الآلي. يقوم التطبيق بتحليل تنبؤي على مجموعة بيانات مفتوحة. من مكتبات التعلم الآلي المدمجة في Spark، يستخدم هذا المثال التصنيف من خلال الانحدار اللوجستي.
MLlib هي مكتبة Spark الأساسية التي توفر العديد من المرافق المفيدة لمهام التعلم الآلي مثل:
- تصنيف
- التراجع
- تكوين أنظمة المجموعات
- النمذجة
- تحليل القيمة المفردة (SVD) وتحليل المكون الرئيسي (PCA)
- اختبار الفرضية وحساب إحصائيات العينة
فهم التصنيف والانحدار اللوجستي
التصنيف، هو مهمة شائعة لنظم التعلّم الآلي، ويتمثل في عملية فرز بيانات الإدخال إلى فئات. إن مهمة خوارزمية التصنيف هي معرفة كيفية تعيين «تسميات» لإدخال البيانات التي تقدمها لها. على سبيل المثال، يمكنك التفكير في خوارزمية التعلم الآلي التي تقبل معلومات المخزون كمدخلات. ثم يُقسم السهم إلى فئتين: الأسهم التي يجب بيعها والأسهم التي يجب الاحتفاظ بها.
الانحدار اللوجستي هو خوارزمية يمكنك استخدامها للتصنيف. واجهة برمجة تطبيقات الانحدار اللوجستية لـ Spark مفيدة للتصنيف الثنائي، أو تصنيف بيانات الإدخال إلى مجموعة من بين مجموعتين. لمزيد من المعلومات عن الانحدار اللوجستي، راجع ويكيبيديا.
باختصار، تنتج عملية الانحدار اللوجستي دالة لوجستية. استخدم الدالة للتنبؤ باحتمالية انتماء متجه الإدخال إلى مجموعة أو أخرى.
مثال التحليل التنبؤي لبيانات فحص الأغذية
في هذا المثال، يمكنك استخدام Spark للقيام ببعض التحليلات التنبؤية حول بيانات فحص الأغذية (Food_Inspections1.csv). البيانات التي تم الحصول عليها من خلال بوابة بيانات مدينة شيكاغو. تحتوي مجموعة البيانات هذه على معلومات حول عمليات فحص المؤسسات الغذائية التي أجريت في شيكاغو. بما في ذلك معلومات عن كل مؤسسة، والانتهاكات التي عُثر عليها (إن وجدت)، ونتائج التفتيش. ملف بيانات CSV متوفر بالفعل في حساب التخزين المقترن بنظام المجموعة في /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
في الخطوات التالية، يمكنك تطوير نموذج لمعرفة ما يلزم لتمرير أو فشل فحص الأغذية.
إنشاء تطبيق التعّلم الآلي في Apache Spark MLlib
قم بإنشاء دفتر ملاحظات Jupyter باستخدام PySpark kernel. للحصول على الإرشادات، راجع إنشاء ملف دفتر ملاحظات Jupyter.
استيراد الأنواع المطلوبة لهذا التطبيق. انسخ التعليمات البرمجية التالية والصقها في خلية فارغة، ثم اضغط على SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *بفضل نظام نواة PySpark، فإنك لن تحتاج إلى إنشاء أي سياقات بشكل صريح. يتم إنشاء سياق Spark وسياق Apache Hive تلقائيًا من أجلك عندما تُشغل خلية التعليمات البرمجية الأولى.
إنشاء إطار بيانات الإدخال
استخدم سياق Spark لسحب بيانات CSV الخام إلى الذاكرة كنص غير منظم. ثم استخدم مكتبة CSV الخاصة بـ Python لتحليل كل سطر من البيانات.
شغّل الأسطر التالية لإنشاء مجموعة بيانات موزعة مرنة (RDD) عن طريق استيراد بيانات الإدخال وتحليلها.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)شغّل التعليمات البرمجية التالية لاسترداد صف واحد من مجموعة بيانات موزعة مرنة (RDD) بحيث يمكنك إلقاء نظرة على مخطط البيانات:
inspections.take(1)تكون النتيجة:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]يعطيك الناتج فكرة عن مخطط ملف الإدخال. وهو يشمل اسم كل مؤسسة ونوعها. يشمل أيضًا العنوان وبيانات عمليات التفتيش والموقع من بين أمور أخرى.
شغّل التعليمات البرمجية التالية لإنشاء إطار بيانات (df) وجدول مؤقت (CountResults) مع عدد قليل من الأعمدة المفيدة للتحليل التنبؤي. يُستخدم
sqlContextللقيام بتحويلات على البيانات المُنظمة.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')الأعمدة الأربعة ذات الأهمية في إطار البيانات هي معرّف، اسم، نتائج، انتهاكات.
شغّل التعليمات البرمجية التالية للحصول على عينة صغيرة من البيانات:
df.show(5)تكون النتيجة:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
فهم البيانات
دعونا نبدأ بالتعرف على عما تحتويه مجموعة البيانات.
شغّل التعليمات البرمجية التالية لإظهار القيم المميزة في عمود نتائج:
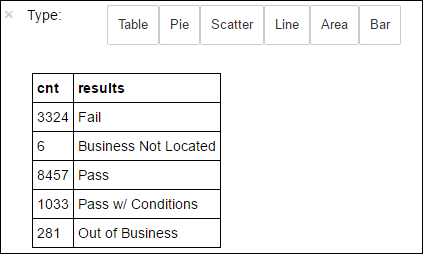
df.select('results').distinct().show()تكون النتيجة:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+شغّل التعليمات البرمجية التالية لتصور توزيع هذه النتائج:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsسحر
%%sqlمتبوعًا بـ-o countResultsdfيضمن استمرار ناتج الاستعلام محليًا على خادم Jupyter (عادة العُقدة الرئيسية لنظام المجموعة). يتم استمرار الناتج كإطار بيانات Pandas باسم محدد وهو countResultsdf. لمزيد من المعلومات حول سحر%%sqlوغيرها من السحر المتاح مع نواة PySpark، انظر توفر Kernels على دفاتر ملاحظات Jupyter مع نظم مجموعات Apache Spark HDInsight.تكون النتيجة:
يمكنك أيضًا استخدام Matplotlib، وهي مكتبة تُستخدم لإنشاء تصور للبيانات، لإنشاء رسم. نظرًا لأنه يجب إنشاء الرسم من إطار بيانات countResultsdf مُستمر محليًا، يجب أن تبدأ القصاصة البرمجية بسحر
%%local. يضمن هذا الإجراء تشغيل التعليمات البرمجية محليًا على خادم Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')للتنبؤ بنتائج فحص الأغذية، تحتاج إلى تطوير نموذج يستند إلى الانتهاكات. لأن الانحدار اللوجستي هو أسلوب تصنيف ثنائي، فمن المنطقي تجميع بيانات النتائج إلى فئتين: فشل، نجاح:
نجاح
- نجاح
- نجاح مع / الشروط
فشل
- فشل
تجاهل
- الأعمال غير موجودة
- خارج العمل
البيانات مع النتائج الأخرى ("الأعمال غير موجودة" أو "خارج العمل") ليست مفيدة، وهي تُشكل نسبة صغيرة من النتائج على أي حال.
شغّل التعليمات البرمجية التالية لتحويل إطار البيانات (
df) الحالي إلى إطار بيانات جديد حيث يتم تمثيل كل فحص كزوج انتهاك التسمية. في هذه الحالة، تسمية0.0تمثل فشل، وتسمية1.0تمثل نجاح، وتسمية-1.0تمثل بعض النتائج بالإضافة إلى هاتين النتيجتين.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')شغّل التعليمات البرمجية التالية لإظهار صف واحد من البيانات المُسماة:
labeledData.take(1)تكون النتيجة:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
إنشاء نموذج انحدار لوجستي من إطار بيانات الإدخال
المهمة النهائية هي تحويل البيانات المُسماة. تحويل البيانات إلى تنسيق تم تحليله عن طريق الانحدار اللوجستي. يحتاج الإدخال إلى خوارزمية انحدار لوجستية إلى مجموعة من أزواج متحه ميزة التسمية. حيث يكون "متجه الميزة" هو متجه الأرقام التي تمثل نقطة الإدخال. لذلك، تحتاج إلى تحويل عمود "الانتهاكات"، وهو شبه منظم ويحتوي على العديد من التعليقات في النص الحر. قم بتحويل العمود إلى صفيف من الأرقام الحقيقية التي يمكن أن يفهمها الجهاز بسهولة.
تتمثل إحدى نهج التعلم الآلي القياسية لمعالجة اللغة الطبيعية في تعيين فهرس لكل كلمة مميزة. ثم تمرير المتجه إلى خوارزمية التعلم الآلي. بحيث تحتوي قيمة كل فهرس على التكرار النسبي لتلك الكلمة في السلسلة النصية.
يُوفر MLlib طريقة سهلة للقيام بهذه العملية. أولًا، "ضع رمزًا مميزًا" لكل سلسلة انتهاكات للحصول على الكلمات الفردية في كل سلسلة. ثم استخدم HashingTF لتحويل كل مجموعة من الرموز المميزة إلى متجه ميزة يمكن تمريره بعد ذلك إلى خوارزمية الانحدار اللوجستية لإنشاء نموذج. يمكنك إجراء كل هذه الخطوات بالتسلسل باستخدام البنية الأساسية لبرنامج ربط العمليات التجارية.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
تقييم النموذج باستخدام مجموعة بيانات أخرى
يمكنك استخدام النموذج الذي أنشأته سابقا للتنبؤ بنتائج عمليات الفحص الجديدة. تستند التنبؤات على الانتهاكات التي لُوحظت. لقد دربت هذا النموذج على مجموعة البيانات Food_Inspections1.csv. يمكنك استخدام مجموعة بيانات ثانية، Food_Inspections2.csv لتقييم قوة هذا النموذج على البيانات الجديدة. مجموعة البيانات الثانية (Food_Inspections2.csv) موجودة في حاوية التخزين الافتراضية المقترنة بنظام المجموعة.
شغّل التعليمات البرمجية التالية لإنشاء إطار بيانات جديد predictionsDf يحتوي على التنبؤ الذي أنشأه النموذج. تُنشئ القصاصة البرمجية أيضًا جدولًا مؤقتًا يسمى التنبؤات استنادًا إلى إطار البيانات.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsيجب أن تشاهد ناتج مثل النص التالي:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']انظر إلى أحد التنبؤات. شغّل هذه القصاصة البرمجية:
predictionsDf.take(1)هناك تنبؤ للإدخال الأول في مجموعة بيانات الاختبار.
الأسلوب
model.transform()يُطبق نفس التحويل على أي بيانات جديدة بنفس المخطط، وتصل إلى تنبؤ بكيفية تصنيف البيانات. يمكنك القيام ببعض الإحصاءات لمعرفة كيف كانت التنبؤات:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")يبدو الإخراج مثل النص التالي:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateاستخدام الانحدار اللوجستي مع Spark يمنحك نموذجًا للعلاقة بين أوصاف الانتهاكات باللغة الإنجليزية. وما إذا كانت سنتنجح مؤسسة معينة أو تفشل في فحص الأغذية.
إنشاء تمثيل مرئي للتنبؤ
يمكنك الآن إنشاء تصور نهائي لمساعدتك في التفكير بنتائج هذا الاختبار التجريبي.
ابدأ باستخراج التنبؤات والنتائج المختلفة من الجدول المؤقت التنبؤات الذي تم إنشاؤه في وقت سابق. تفصل الاستعلامات التالية الناتج كـ true_positive، false_positive، true_negative، false_negative. في الاستعلامات أدناه، يمكنك إيقاف تشغيل التصور باستخدام
-qوحفظ الناتج أيضًا (باستخدام-o) كأطر البيانات التي يمكن استخدامها بعد ذلك مع سحر%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')وأخيرًا، استخدم القصاصة البرمجية التالية لإنشاء المخطط باستخدام Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')ينبغي أن تشاهد المخرج التالي:
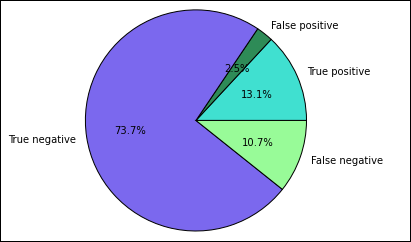
في هذا المخطط، تشير النتيجة "الإيجابية" إلى فشل فحص الأغذية، في حين أن النتيجة السلبية نجاح الفحص.
إيقاف تشغيل دفتر الملاحظات
بعد تشغيل التطبيق، يجب إيقاف تشغيل دفتر الملاحظات لتحرير الموارد. للقيام بذلك، من قائمة ملف في دفتر الملاحظات، حدد إغلاق وإيقاف. يتم إغلاق هذا الإجراء، وإغلاق دفتر الملاحظات.