نواة Jupyter Notebook على مجموعات Apache Spark في Azure HDInsight
توفر مجموعات HDInsight Spark نواة يمكنك استخدامها مع Jupyter Notebook على Apache Spark لاختبار تطبيقاتك. النواة هي برنامج يقوم بتشغيل وتفسير المعلومات البرمجية الخاصة بك. النوى الثلاثة هي:
- PySpark - للتطبيقات المكتوبة في Python2. (ينطبق فقط عـلى مجموعات إصدار Spark 2.4)
- PySpark3 - للتطبيقات المكتوبة في Python3.
- Spark - للتطبيقات المكتوبة في Scala.
في هذه المقالة، ستتعلم كيفية استخدام هذه النوى وفوائد استخدامها.
المتطلبات الأساسية
قم بإنشاء نظام مجموعة Apache Spark في HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight.
قم بإنشاء Jupyter Notebook علىSpark HDInsight
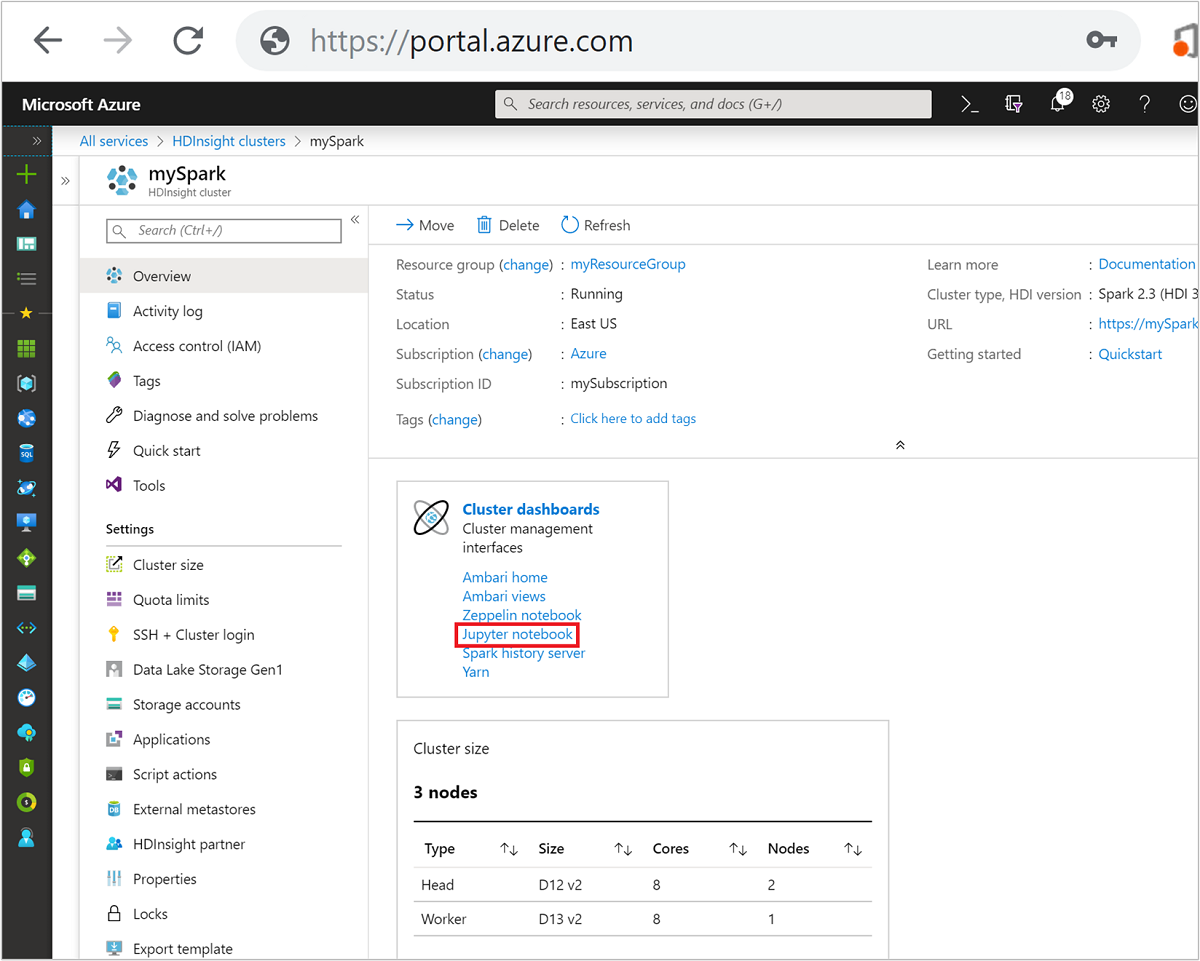
من مدخل Microsoft Azure، حدد نظام مجموعة Spark الخاص بك. راجع قائمة وعرض المجموعات للحصول على الإرشادات. يتم فتح العرض view opens.
من طريقة العرض Overview، في مربع Cluster dashboards، حدد Jupyter Notebook. إذا طُلب منك ذلك، أدخل بيانات اعتماد المسؤول للمجموعة.
إشعار
يمكنك أيضاً الوصول إلى مجموعة Jupyter Notebook على Spark عن طريق فتحthe following URL in your browser. استبدل CLUSTERNAME باسم مجموعتك:
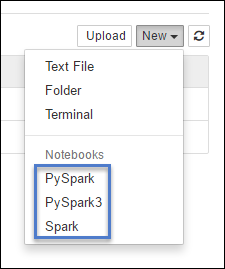
https://CLUSTERNAME.azurehdinsight.net/jupyterحدد New، ثم حدد إما Pyspark أو PySpark3 أو Spark لإنشاء دفتر ملاحظات. استخدم نواة Spark لتطبيقات Scala ونواة PySpark لتطبيقات Python2 ونواة PySpark3 لتطبيقات Python3.
إشعار
بالنسبة إلى Spark 3.1، لـن يتوفر سوى PySpark3 أو Spark.
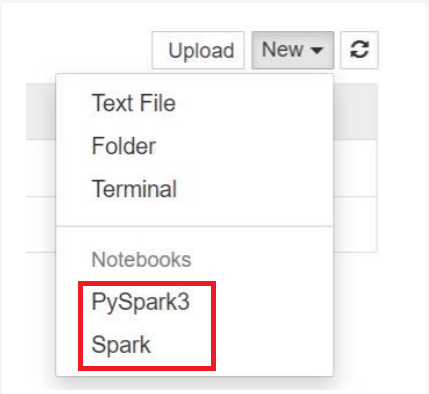
- يتم فتح دفتر ملاحظات بالنواة التي حددتها.
فوائد استخدام النوى
فيما يلي بعض فوائد استخدام النواة الجديدة مع Jupyter Notebook على مجموعات Spark HDInsight.
سياقات معدة مسبقاً. باستخدام نواة PySparkأو PySpark3أو Spark، لا تحتاج إلى تعيين سياقات Spark أو Apache Hive بشكل صريح قبل بدء العمل مـع التطبيقات الخاصة بك. هذه السياقات متاحة بشكل افتراضي. هذه السياقات هي:
sc - لسياق Spark
sqlContext - لسياق Apache Hive
لذلك، لست مضطراً لتشغيل عبارات مثل ما يلي لتعيين السياقات:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)بدلاً من ذلك، يمكنك استخدام السياقات المحددة مسبقاً في تطبيقك مباشرةً.
سحر الخلية. توفر نواة PySpark بعض "السحر" المحدد مسبقاً، وهي أوامر خاصة يمكنك الاتصال بها باستخدام
%%(على سبيل المثال،%%MAGIC<args>). يجب أن يكون الأمر السحري هو الكلمة الأولى في خلية رمز ويسمح بخطوط متعددة من المحتوى. يجب أن تكون الكلمة السحرية هي الكلمة الأولى في الخلية. إضافة أي شيء قبل السحر، حتى التعليقات، يسبب خطأً. لمزيد من المعلومات حول السحر، راجع هنا.يسرد الجدول التالي العناصر السحرية المختلفة المتاحة من خلال النواة.
Magic مثال الوصف مساعدة %%helpيقوم بإنشاء جدول لجميع المزايا العجيبة المتاحة في المثال والوصف معلومات %%infoإخراج معلومات الجلسة لنقطة النهاية Livy الحالية تكوين %%configure -f{"executorMemory": "1000M","executorCores": 4}تكوين المعلمات لإنشاء جلسة. تعد علامة القوة ( -f) إلزامية إذا تم إنشاء جلسة بالفعل، ما يضمن إسقاط الجلسة وإعادة إنشائها. راجع Livy's POST /sessions Request Body للحصول على قائمة بالمعلمات الصالحة. يجب أن يتم تمرير المعلمات كسلسلة JSON ويجب أن تكون في السطر التالي بعد السحر، كما هو موضح في نموذج العمود.sql %%sql -o <variable name>
SHOW TABLESيتم تنفيذ استعلام Apache Hive مقابل sqlContext. إذا تم تمرير المعلمة -o، فإن نتيجة الاستعلام تستمر في سياق %% local Python كإطار بيانات Pandas.محلي %%locala=1يتم تنفيذ جميع التعليمات البرمجية في الأسطر اللاحقة محلياً. يجب أن يكون الرمز Python2 صالحاً بغض النظر عن النواة التي تستخدمها. لذلك، حتى إذا قمت بتحديد نواة PySpark3 أو Spark أثناء إنشاء دفتر الملاحظات، إذا كنت تستخدم %%localالسحر في خلية، فيجب أن تحتوي هذه الخلية على رمز Python2 صالح فقط.السجلات %%logsإخراج السجلات لجلسة العمل Livy الحالية. delete %%delete -f -s <session number>حذف جلسة عمل محددة لنقطة نهاية Livy الحالية. لا يمكنك حذف الجلسة التي بدأت من أجل النواة نفسها. تنظيف %%cleanup -fحذف جميع الجلسات الخاصة بنقطة النهاية Livy الحالية، بما في ذلك جلسة دفتر الملاحظات هذا. علم القوة -f إلزامي. إشعار
بالإضافة إلى العناصر السحرية المضافة من قِبل نواة PySpark، يمكنك أيضاً استخدام سحر IPython المدمج، بما في ذلك
%%sh. يمكنك استخدام%%shالسحر لتشغيل البرامج النصية وكتلة من التعليمات البرمجية على عقدة رأس نظام المجموعة.التمثيل الرسومي التلقائي. تصور نواة Pyspark تلقائياً ناتج استعلامات Apache Hive وSQL. يمكنك الاختيار بين عدة أنواع مختلفة من المرئيات بما في ذلك Table وPie وLine وArea وBar.
المعلمات المدعومة بمزايا %%sql العجيبة
يدعم السحر %%sql المعلمات المختلفة التي يمكنك استخدامها للتحكم في نوع الإخراج الذي تتلقاه عند تشغيل الاستعلامات. يسرد الجدول التالي الإخراج.
| المعلمة | مثال | الوصف |
|---|---|---|
| -o | -o <VARIABLE NAME> |
استخدم هذه المعلمة لاستمرار نتيجة الاستعلام، في سياق local Python %%، كإطار بيانات Pandas. اسم متغير إطار البيانات هو اسم المتغير الذي تحدده. |
| -q | -q |
استخدم هذه المعلمة لإيقاف تشغيل المرئيات للخلية. إذا كنت لا تريد تصوير محتوى خلية ما بشكل تلقائي وتريد التقاطه كإطار بيانات فقط، فاستخدم -q -o <VARIABLE>. إذا كنت تريد إيقاف تشغيل المرئيات دون التقاط النتائج (على سبيل المثال، لتشغيل استعلام SQL، مثل عبارة CREATE TABLE)، -q فاستخدمها دون تحديد وسيطة -o. |
| -m | -m <METHOD> |
حيث تكون الطريقة هي إما أخذ أو عينة (الافتراضي هو أخذ). إذا كانت الطريقة هي take، يختار نواة العناصر من أعلى مجموعة بيانات النتائج المحددة بواسطة MAXROWS (الموضحة لاحقاً في هذا الجدول). إذا كانت الطريقة عبارة عن عينة، فإن النواة تأخذ عينات عشوائية من عناصر مجموعة البيانات وفقاً -rللمعلمة، الموضحة أدناه في هذا الجدول. |
| -r | -r <FRACTION> |
هنا FRACTION هو رقم الفاصلة العائمة بين 0.0 و1.0. إذا كانت طريقة العينة لاستعلام SQL هي sample، فإن النواة تأخذ عشوائياً الكسر المحدد من عناصر مجموعة النتائج نيابة عنك. على سبيل المثال، إذا قمت بتشغيل استعلام SQL باستخدام الوسيطات -m sample -r 0.01، فسيتم أخذ عينات عشوائية بنسبة 1% من صفوف النتائج. |
| -n | -n <MAXROWS> |
MAXROWS هي قيمة عدد صحيح. تحدد kernel عدد صفوف الإخراج إلى MAXROWS. إذا كان MAXROWS رقماً سالباً مثل -1، فلن يكون عدد الصفوف في مجموعة النتائج محدوداً. |
مثال:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
يقوم البيان أعلاه بالإجراءات التالية:
- تحديد جميع السجلات من hivesampletable.
- لأننا نستخدم -q، فإنه يوقف التصوير التلقائي.
- نظراً لأننا نستخدم
-m sample -r 0.1 -n 500، فإنه يأخذ عينات عشوائية بنسبة 10% من الصفوف في hivesampletable ويحد من حجم مجموعة النتائج إلى 500 صف. - أخيراً، نظراً لأننا استخدمنا
-o query2فإنه يحفظ أيضاً الإخراج في إطار بيانات يسمى query2.
الاعتبارات أثناء استخدام النواة الجديدة
أياً كانت النواة التي تستخدمها، فإن ترك دفاتر الملاحظات قيد التشغيل يستهلك موارد المجموعة. باستخدام هذه النوى، نظراً لأن السياقات معدة مسبقاً، فإن الخروج من دفاتر الملاحظات ببساطة لا يقتل السياق. وهكذا تظل موارد نظام المجموعة قيد الاستخدام. من الممارسات الجيدة استخدام الخيار Close and Halt من قائمة File في دفتر الملاحظات عند الانتهاء من استخدام دفتر الملاحظات. الإغلاق يقتل السياق ثم يخرج من دفتر الملاحظات.
أين يتم تخزين دفاتر الملاحظات؟
إذا كانت مجموعتك تستخدم Azure Storage كحساب تخزين افتراضي، فسيتم حفظ دفاتر ملاحظات Jupyter في حساب التخزين ضمن المجلد / HdiNotebooks. يمكن الوصول إلى دفاتر الملاحظات والملفات النصية، والمجلدات التي تقوم بإنشائها من داخل Jupyter من حساب التخزين. على سبيل المثال، إذا كنت تستخدم Jupyter لإنشاء مجلد myfolder وجهاز كمبيوتر محمول myfolder/mynotebook.ipynb، فيمكنك الوصول إلى دفتر الملاحظات هذا /HdiNotebooks/myfolder/mynotebook.ipynb داخل حساب التخزين. والعكس صحيح أيضاً، أي إذا قمت بتحميل دفتر ملاحظات مباشرةً إلى حساب التخزين الخاص بك على /HdiNotebooks/mynotebook1.ipynb، فسيكون دفتر الملاحظات مرئياً من Jupyter أيضاً. تبقى أجهزة الكمبيوتر المحمولة في حساب التخزين حتى بعد حذف المجموعة.
إشعار
لا تخزن مجموعات HDInsight مع Azure Data Lake Storage كتخزين افتراضي عبر تخزين دفاتر الملاحظات في التخزين المرتبط.
الطريقة التي يتم بها حفظ أجهزة الكمبيوتر المحمولة في حساب التخزين متوافقة مع Apache Hadoop HDFS. إذا قمت بـ SSH في نظام المجموعة يمكنك استخدام أوامر إدارة الملفات:
| الأمر | الوصف |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# أدرج كل شيء في الدليل الجذري - كل شيء في هذا الدليل مرئي لـ Jupyter من الصفحة الرئيسية |
hdfs dfs –copyToLocal /HdiNotebooks |
# قم بتنزيل محتويات مجلد HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# قم بتحميل دفتر ملاحظات .ipynb إلى مجلد الجذر بحيث يكون مرئياً من Jupyter |
سواء كانت المجموعة تستخدم Azure Storage أوAzure Data Lake Storage كحساب تخزين افتراضي، يتم أيضاً حفظ دفاتر الملاحظات في العقدة الرئيسية للمجموعة في /var/lib/jupyter.
متصفح مدعوم
يتم دعم دفاتر ملاحظات Jupyter على مجموعات Spark HDInsight فقط على Google Chrome.
الاقتراحات
النوى الجديدة في مرحلة التطور وسوف تنضج بمرور الوقت. لذلك يمكن أن تتغير واجهات برمجة التطبيقات مع نضوج هذه النوى. ونحن نقدر أي ملاحظات لديك أثناء استخدام هذه النوى الجديدة. التعليقات مفيدة في تشكيل الإصدار النهائي لهذه النواة. يمكنك ترك تعليقاتك / ملاحظاتك ضمن قسم التعليقات في الجزء السفلي من هذه المقالة.