ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يتضمن نظام مجموعة HDInsight Spark تثبيت مكتبة Apache Spark. تتضمن كل نظام مجموعة HDInsight معلمات التكوين الافتراضية لجميع الخدمات المثبتة، بما في ذلك Spark. أحد الجوانب الرئيسية لإدارة نظام مجموعة HDInsight Apache Hadoop هو مراقبة حمل العمل، بما في ذلك "مهام Spark". لتشغيل مهام Spark بأفضل شكل، خذ بعين الاعتبار تكوين نظام المجموعة الفعلي عند تحديد التكوين المنطقي لنظام المجموعة.
يتضمن نظام المجموعة الافتراضي لـ HDInsight Apache Spark العقد التالية: ثلاث عقد Apache ZooKeeper وعقدتين رأسيتين وعقدة عامل واحدة أو أكثر:
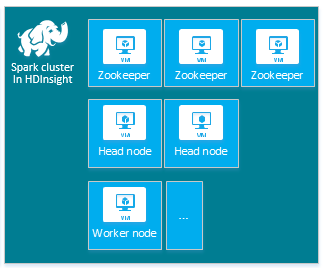
يمكن أن يؤثر عدد الأجهزة الظاهرية وأحجامها للعقد في نظام مجموعة HDInsight على تكوين Spark. غالباً ما تتطلب قيم تكوين HDInsight غير الافتراضية قيم تكوين Spark غير الافتراضية. عند إنشاء نظام المجموعة HDInsight Spark، يتم عرض أحجام الأجهزة الظاهرية المقترحة لكل مكون من المكونات. أحجام الجهاز الظاهري المحسّنة للذاكرة لـ Linux لـ Azure في الوقت الحالي D12 v2 أو أكبر.
إصدارات Apache Spark
استخدم أفضل إصدار Spark لنظام المجموعة. تتضمن خدمة HDInsight عدة إصدارات من كل من Spark وHDInsight نفسه. يتضمن كل إصدار من Spark مجموعة من إعدادات نظام المجموعة الافتراضية.
عند إنشاء نظام مجموعة جديد، هناك إصدارات Spark متعددة للاختيار من بينها. لمراجعة القائمة الكاملة، لمكونات والإصدارات HDInsight.
إشعار
قد يتغير الإصدار الافتراضي من Apache Spark في خدمة HDInsight دون إشعار. إذا كانت لديك تبعية إصدار توصي Microsoft بتحديد هذا الإصدار المحدد عند إنشاء أنظمة مجموعات باستخدام SDK.NET وAzure PowerShell وواجهة سطر الأوامر الكلاسيكية في Azure.
يشتمل Apache Spark على ثلاثة مواقع لتكوين النظام:
- تتحكم خصائص Spark في معظم معلمات التطبيق ويمكن تعيينها باستخدام عنصر
SparkConfأو من خلال خصائص نظام Java. - يمكن استخدام متغيرات البيئة لتعيين إعدادات لكل جهاز، مثل عنوان IP، من خلال البرنامج النصي
conf/spark-env.shعلى كل عقدة. - يمكن تكوين التسجيل من خلال
log4j.properties.
عند تحديد إصدار معين من Spark، يتضمن نظام المجموعة إعدادات التكوين الافتراضية. يمكنك تغيير قيم تكوين Spark الافتراضية باستخدام ملف تكوين Spark مخصص. إليك مثال موضح أدناه.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
المثال الموضح أعلاه يمنع العديد من القيم الافتراضية لخمس معلمات لتكوين Spark. هذه القيم هي برنامج ضغط الوسائط وفكها، والحجم الأدنى لتقسيم MapReduce في Apache Hadoop، وأحجام كتل parquet. وأيضاً، القيم الافتراضية لقسم Spark SQL وأحجام فتح الملفات. يتم اختيار تغييرات التكوين هذه لأن البيانات والمهام المقترنة (في هذا المثال، البيانات الجينومية) لها خصائص معينة. سيصبح أداء هذه الخصائص أفضل باستخدام إعدادات التكوين المخصصة هذه.
عرض إعدادات تكوين نظام المجموعة
تحقق من إعدادات تكوين نظام المجموعة HDInsight الحالي قبل القيام بتحسين الأداء على نظام المجموعة. قم بتشغيل لوحة معلومات HDInsight من مدخل Microsoft Azure بالنقر فوق ارتباط لوحة المعلومات في جزء نظام مجموعة Spark. قم بتسجيل الدخول باستخدام اسم المستخدم وكلمة المرور لمسؤول نظام المجموعة.
تظهر واجهة مستخدم الويب في Apache Ambari، مع لوحة معلومات من مقاييس استخدام موارد نظام المجموعة الرئيسية. تظهر لوحة معلومات Ambari لك تكوين Apache Spark، والخدمات المثبتة الأخرى. تتضمن لوحة المعلومات علامة تبويب محفوظات التكوين؛ حيث يمكنك عرض معلومات للخدمات المثبتة، بما في ذلك Spark.
للاطلاع على قيم التكوين لـ Apache Spark، حدد محفوظات التكوين، ثم حدد Spark2. حدد علامة التبويب تكوينات، ثم حدد الارتباطSpark (أو Spark2، حسب الإصدار) في قائمة الخدمات. تشاهد قائمة قيم التكوين لنظام المجموعة:
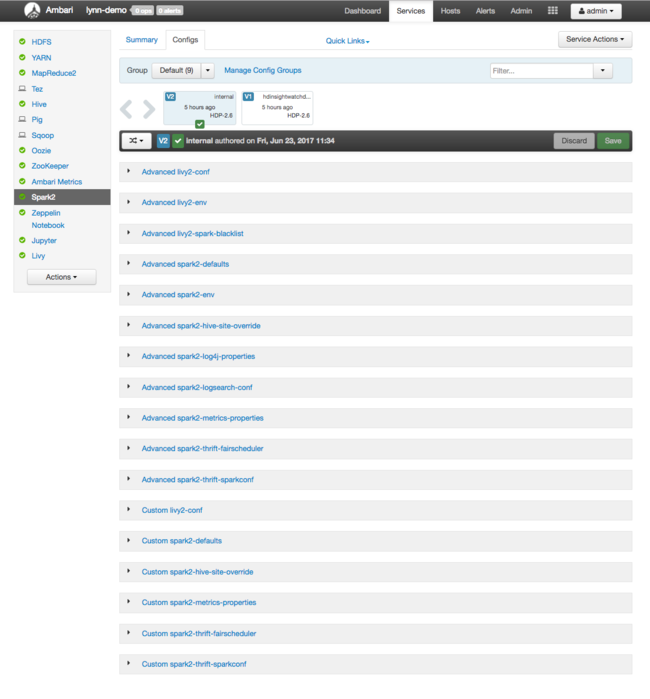
لرؤية قيم تكوين Spark الفردية وتغييرها، حدد أي ارتباط مع وضع "spark" في العنوان. تتضمن تكوينات Spark قيم التكوين المخصصة والمتقدمة في هذه الفئات:
- Custom Spark2-defaults
- Custom Spark2-metrics-properties
- Advanced Spark2-defaults
- Advanced Spark2-env
- Advanced spark2-hive-site-override
إذا أنشأت مجموعة غير افتراضية من قيم التكوين، فإن سجل التحديث يكون مرئياً. يمكن أن يكون سجل التكوين هذا مفيداً لمعرفة التكوين غير الافتراضي الذي يحتوي على الأداء الأمثل.
إشعار
لمشاهدة إعدادات تكوين نظام المجموعة Spark الشائعة، ولكن دون تغييرها، حدد علامة التبويب البيئة على واجهة واجهة مستخدم مهام Spark ذات المستوى الأعلى.
تكوين منفذي Spark
الرسم التخطيطي التالي يظهر عناصر Spark الرئيسية: برنامج التشغيل وسياق Spark المقترن به، ومدير نظام المجموعة وعقد العامل الخاصة بها التي تبلغ n. تتضمن كل عقدة عامل منفذاً وذاكرة تخزين مؤقت ومثيلات مهمة تبلغ n.
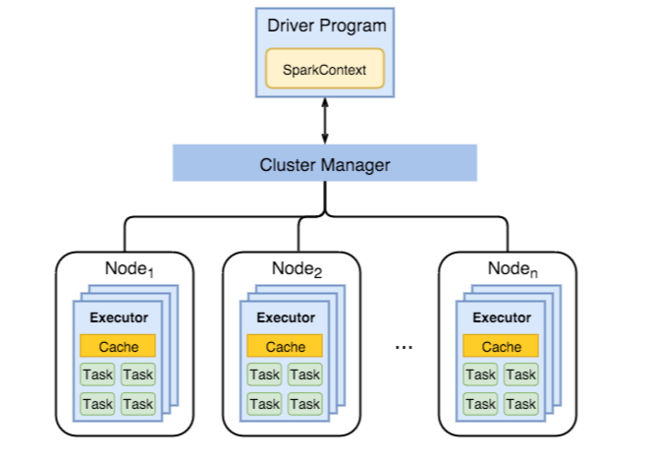
تستخدم مهام Spark موارد العاملين، ولا سيما الذاكرة، لذلك من الشائع ضبط قيم تكوين Spark لمنفذي عقدة العامل.
المعلمات الرئيسة الثلاثة التي يمكن استخدامها لتكوين Spark بناءً على متطلبات التطبيق هي spark.executor.instances وspark.executor.cores وspark.executor.memory. المنفذ عملية يتم إطلاقها لتطبيق Spark. يعمل المنفذ على عقدة العامل وهو مسؤول عن مهام التطبيق. يحدد عدد عقد العامل وحجم عقدة العامل عدد المنفذين وأحجام المنفذين. يتم تخزين هذه المعلومات في spark-defaults.conf على عقد رأس نظام المجموعة. يمكنك تحرير هذه القيم في نظام مجموعة قيد التشغيل عن طريق تحديد Custom spark-defaults في واجهة المستخدم الويب في Ambari. بعد إجراء تغييرات، تتم مطالبتك من قبل واجهة المستخدم بإعادة تشغيل جميع الخدمات المتأثرة.
إشعار
يمكن تكوين معلمات التكوين الثلاثة هذه على مستوى نظام المجموعة (لجميع التطبيقات التي تعمل على نظام المجموعة) كما يتم تحديدها لكل تطبيق على حدة.
مصدر آخر للمعلومات عن الموارد المستخدمة من قبل منفذي Spark هو واجهة مستخدم تطبيق Spark. في واجهة المستخدم، يعرضالمنفذون طرق عرض الملخص والتفاصيل للتكوين والموارد المستهلكة. حدد ما إذا كان سيتم تغيير قيم المنفذين لنظام المجموعة بأكمله أو مجموعة معينة من عمليات تنفيذ المهام.
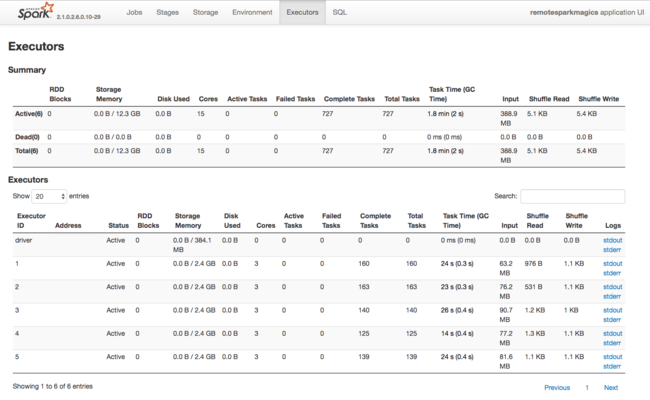
أو يمكنك استخدام واجهة برمجة تطبيقات REST في Ambari للتحقق برمجياً من إعدادات تكوين HDInsight ونظام مجموعة Spark. يتوفر مزيد من المعلومات في مرجع واجهة برمجة تطبيقات REST في Apache Ambari على GitHub.
وفقاً لحمل العمل Spark، قد تحدد أن تكوين Spark غير افتراضي يوفر تنفيذ مهام Spark محسنة أكثر. يكون عليك إجراء اختبار المعيار باستخدام عينات من أحمال العمل للتحقق من صحة أي تكوينات نظام مجموعة غير افتراضية. بعض المعلمات الشائعة التي قد تفكر في ضبطها:
| المعلمة | الوصف |
|---|---|
| --num-executors | لتعيين عدد المنفذين. |
| --executor-cores | تعيين عدد الذاكرات الأساسية لكل منفذ. نوصي باستخدام المنفذين متوسطي الحجم، حيث تستهلك العمليات الأخرى أيضاً جزءاً من الذاكرة المتوفرة. |
| --executor-memory | للتحكم في حجم الذاكرة (حجم كومة الذاكرة المؤقتة) لكل منفذ على Apache Hadoop YARN، وستحتاج إلى ترك بعض الذاكرة لتنفيذ الأحمال الإضافية. |
فيما يلي مثال لعقدتي عاملين بقيم تكوين مختلفة:

تعرض القائمة التالية معلمات ذاكرة منفذ Spark الرئيسية.
| المعلمة | الوصف |
|---|---|
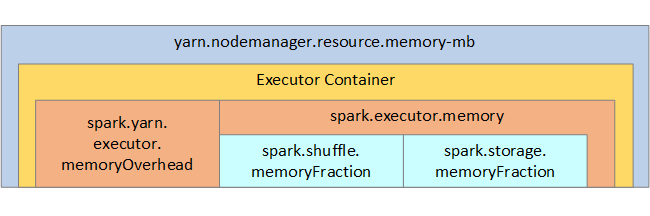
| spark.executor.memory | لتحديد إجمالي مقدار الذاكرة المتوفرة للمنفذ. |
| spark.storage.memoryFraction | (الافتراضي ~60%) لتحديد مقدار الذاكرة المتوفرة لتخزين RDDs المستمرة. |
| spark.shuffle.memoryFraction | (الافتراضي ~20%) لتحديد مقدار الذاكرة المخصصة للتشغيل العشوائي. |
| spark.storage.unrollFraction وspark.storage.safetyFraction | (يبلغ مجموعها ~30 ٪ من إجمالي الذاكرة) -- تستخدم هذه القيم داخلياً من قبل Spark وينبغي عدم تغييرها. |
YARN يتحكم في الحد الأقصى لمجموع الذاكرة المستخدمة من قبل الحاويات على كل عقدة Spark. يوضح الرسم التخطيطي التالي العلاقات لكل عقدة بين عناصر تكوين YARN وعناصر Spark.
تغيير معلمات تطبيق قيد التشغيل فيJupyter Notebook
تتضمن أنظمة مجموعة Spark في HDInsight عدداً من المكونات بشكل افتراضي. يتضمن كل من هذه المكونات قيم التكوين الافتراضية، والتي يمكن تجاوزها حسب الحاجة.
| المكون | الوصف |
|---|---|
| Spark Core | Spark Core، وSpark SQL، وواجهات برمجة تطبيقات دفق بيانات Spark، وGraphX، وApache Spark MLlib. |
| Anaconda | مدير الحزمة ل python. |
| Apache Livy | واجهة برمجة تطبيقات REST في Apache Spark، المستخدم لإرسال مهام بعيدة إلى نظام مجموعة HDInsight Spark. |
| دفاتر Jupyter ودفاتر Apache Zeppelin | واجهة مستخدم تفاعلية قائمة على مستعرض متفاعل للتفاعل مع نظام مجموعة Spark. |
| برنامج تشغيل ODBC | لربط أنظمة مجموعة Spark في HDInsight إلى أدوات المعلومات المهنية (BI) مثل Microsoft Power BI وTableau. |
بالنسبة للتطبيقات التي تعمل في Jupyter Notebook، يمكنك استخدام الأمر %%configure لإجراء تغييرات التكوين من داخل الدفتر نفسه. سيتم تطبيق تغييرات التكوين هذه على مهام Spark التي يتم تشغيلها من مثيل دفتر الملاحظات. نفذ هذه التغييرات في بداية التطبيق، قبل تشغيل الخلية البرمجية الأولى. يتم تطبيق التكوين المتغير على جلسة عمل Livy عند إنشائها.
إشعار
لتغيير التكوين في مرحلة لاحقة في التطبيق، استخدم معلمة -f (فرض). ولكن سيتم فقد كل تقدم في التطبيق.
التعليمة البرمجية أدناه توضح كيفية تغيير التكوين لتطبيق قيد التشغيل في Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
الخاتمة
راقب إعدادات التكوين الأساسية لضمان تشغيل مهام Spark بطريقة قابلة للتنبؤ وذات أداء جيد. تساعد هذه الإعدادات في تحديد تكوين كتلة Spark الأفضل لأحمال العمل. ستحتاج أيضاً إلى مراقبة تنفيذ عمليات تنفيذ مهام Spark طويلة الأمد أو المستهلكة للموارد. تتمحور التحديات الأشهر حول ضغط الذاكرة من التكوينات غير الصحيحة، مثل المنفذين بحجم غير صحيح. أيضاً، العمليات طويلة الأمد والمهام التي تؤدي إلى العمليات الديكارتية.