إدارة الموارد لمجموعة Apache Spark على Azure HDInsight
تعرّف على كيفية الوصول إلى الواجهات مثل Apache Ambari UI وApache Hadoop YARN UI وSpark History Server المرتبط بنظام المجموعة Apache Spark وكيفية ضبط تكوين نظام المجموعة للحصول على الأداء الأمثل.
فتح خادم Spark History
Spark History Server هو واجهة مستخدم الويب لتطبيقات Spark المكتملة والتشغيلية. إنه امتداد لواجهة Spark's Web UI. للحصول على معلومات كاملة، راجع خادم Spark History.
افتح Yarn UI
يمكنك استخدام YARN UI لمراقبة التطبيقات التي تعمل حالياً على مجموعة Spark.
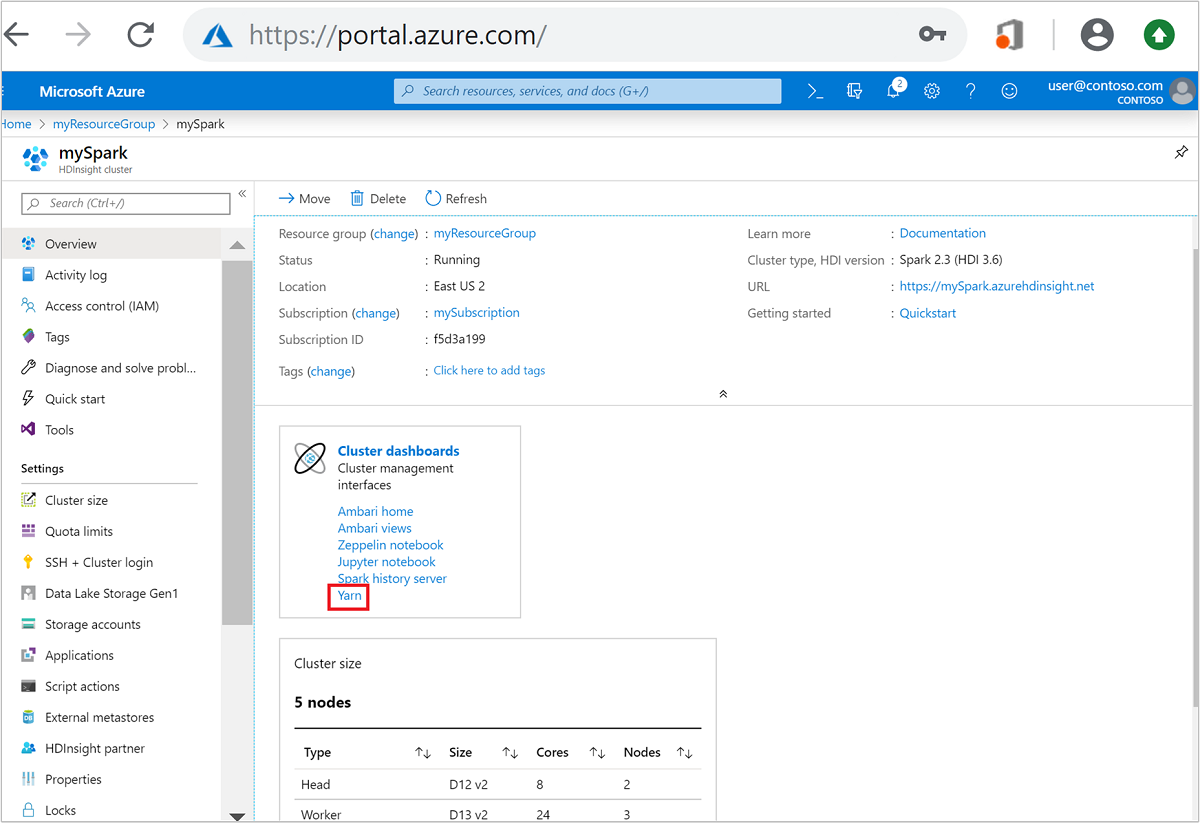
من مدخل Microsoft Azure، افتح مجموعة Spark. لمزيد من المعلومات، راجع قائمة وعرض المجموعات.
من لوحات معلومات المجموعة، حدد Yarn. عند المطالبة، أدخل بيانات اعتماد المسؤول لمجموعة Spark.
تلميح
بدلاً من ذلك، يمكنك أيضاً تشغيل واجهة المستخدم YARN من واجهة المستخدم Ambari. من Ambari UI، انتقل إلى YARN>Quick Links>Active>واجهة مستخدم إدارة الموارد .
تحسين المجموعات لتطبيقات Spark
المعلمات الرئيسة الثلاثة التي يمكن استخدامها لتكوين Spark بناءً على متطلبات التطبيق هي spark.executor.instancesو spark.executor.coresو spark.executor.memory. المنفذ عملية يتم إطلاقها لتطبيق Spark. يتم تشغيله على العقدة العاملة وهو مسؤول عن تنفيذ مهام التطبيق. يتم حساب العدد الافتراضي للمنفذين وأحجام المنفذ لكل مجموعة بناءً على عدد العقد العاملة وحجم العقدة العاملة. يتم تخزين هذه المعلومات في spark-defaults.conf على عقد رأس نظام المجموعة.
يمكن تكوين معلمات التكوين الثلاثة على مستوى نظام المجموعة (لجميع التطبيقات التي تعمل على نظام المجموعة) أو يمكن تحديدها لكل تطبيق فردي أيضاً.
قم بتغيير المعلمات باستخدام Ambari UI
من واجهة مستخدم Ambari، انتقل إلى Spark 2>Configs>Custom spark2-defaults.
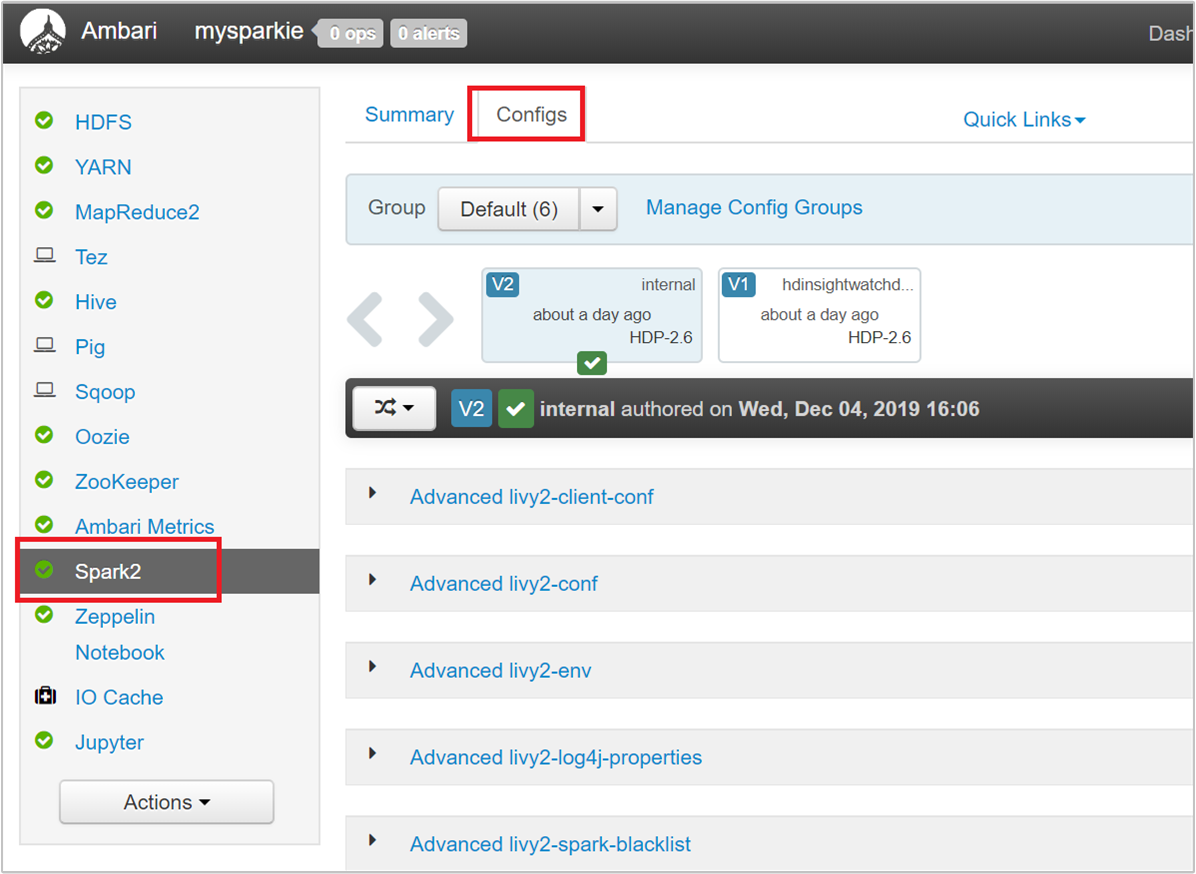
القيم الافتراضية جيدة لتشغيل أربعة تطبيقات Spark بشكل متزامن على نظام المجموعة. يمكنك تغيير هذه القيم من واجهة المستخدم، كما هو موضح في لقطة الشاشة التالية:
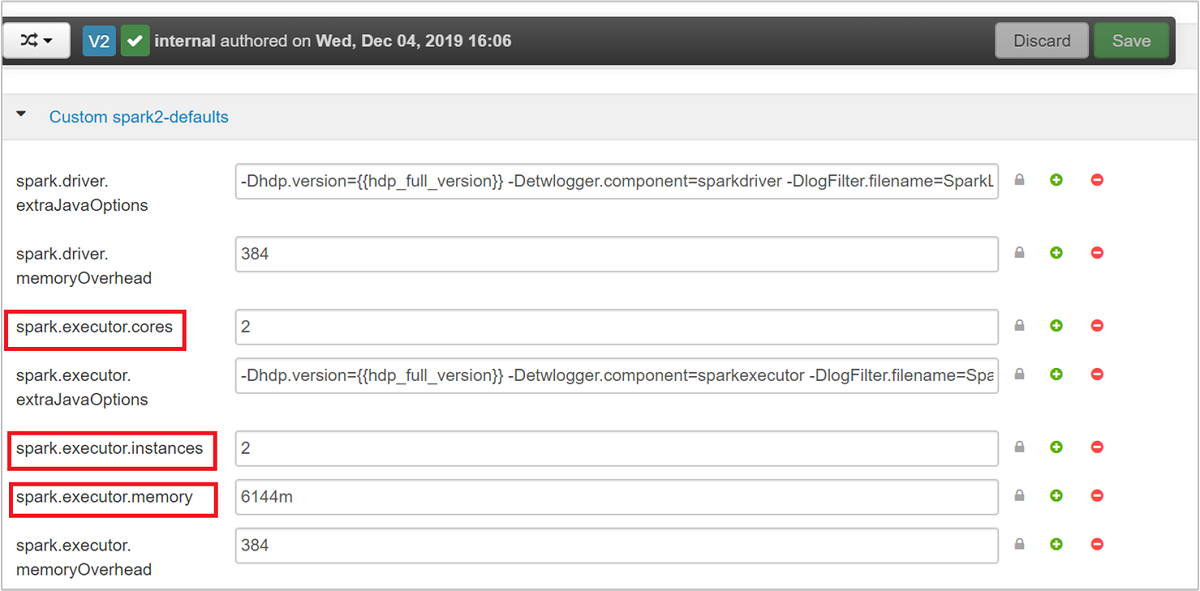
حدد Save لحفظ تغييرات التكوين. في الجزء العلوي من الصفحة، ستتم مطالبتك بإعادة تشغيل جميع الخدمات المتأثرة. حدد إعادة التشغيل.
قم بتغيير المعلمات لتطبيق قيد التشغيل في Jupyter Notebook
بالنسبة للتطبيقات التي تعمل في Jupyter Notebook، يمكنك استخدام السحر %%configure لإجراء تغييرات التكوين. من الناحية المثالية، يجب إجراء مثل هذه التغييرات في بداية التطبيق، قبل تشغيل خلية التعليمات البرمجية الأولى. يضمن القيام بذلك تطبيق التكوين على جلسة Livy، عند إنشائها. إذا كنت تريد تغيير التكوين في مرحلة لاحقة في التطبيق، فيجب عليك استخدام المعلمة -f. ومع ذلك، من خلال القيام بذلك، يتم فقد كل تقدم في التطبيق.
يوضح القصاصة البرمجية التالية كيفية تغيير التكوين لتطبيق يعمل في Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
يجب أن يتم تمرير معلمات التكوين كسلسلة JSON ويجب أن تكون في السطر التالي بعد السحرية، كما هو موضح في عمود المثال.
قم بتغيير المعلمات لتطبيق تم إرساله باستخدام إرسال شرارة
الأمر التالي هو مثال على كيفية تغيير معلمات التكوين لتطبيق دُفعي تم إرساله باستخدام spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
قم بتغيير المعلمات لتطبيق تم إرساله باستخدام cURL
الأمر التالي هو مثال على كيفية تغيير معلمات التكوين لتطبيق دفعي تم إرساله باستخدام cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
إشعار
انسخ ملف JAR إلى حساب تخزين نظام المجموعة الخاص بك. لا تقم بنسخ ملف JAR مباشرة إلى العقدة الرئيسة.
قم بتغيير هذه المعلمات على خادم Spark Thrift
يوفر Spark Thrift Server وصول JDBC / ODBC إلى مجموعة Spark ويستخدم لخدمة استعلامات Spark SQL. أدوات مثل Power BI وTableau وما إلى ذلك، استخدم بروتوكول ODBC للتواصل مع Spark Thrift Server لتنفيذ استعلامات Spark SQL كتطبيق Spark. عند إنشاء مجموعة Spark، يتم بدء تشغيل مثيلين من Spark Thrift Server، واحدة على كل عقدة رئيسة. يظهر كل خادم Spark Thrift كتطبيق Spark في واجهة مستخدم YARN.
يستخدم Spark Thrift Server تخصيص Spark الديناميكي للمنفذ وبالتالي لا يتم استخدام spark.executor.instances. بدلاً من ذلك، يستخدم Spark Thrift Server spark.dynamicAllocation.maxExecutors وspark.dynamicAllocation.minExecutors لتحديد عدد المنفذ. يتم استخدام معلمات التكوين spark.executor.coresو spark.executor.memory لتعديل حجم المنفذ. يمكنك تغيير هذه المعلمات كما هو موضح في الخطوات التالية:
قم بتوسيع فئة Advanced spark2-thrift-sparkconf لتحديث المعلمات
spark.dynamicAllocation.maxExecutorsوspark.dynamicAllocation.minExecutors.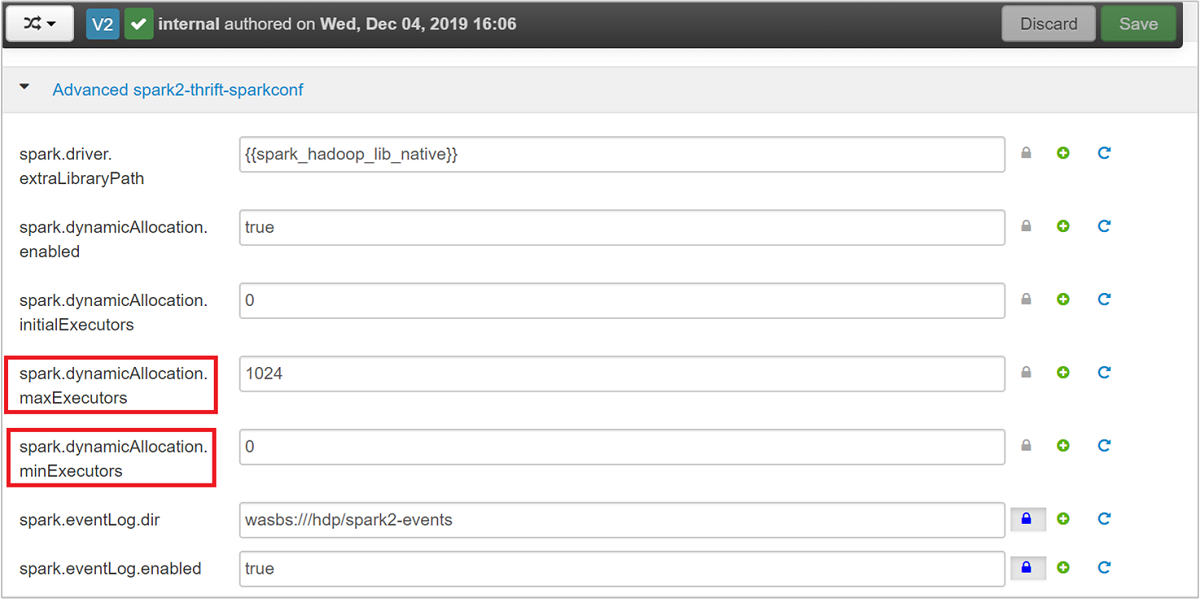
قم بتوسيع فئة custom spark2-thrift-sparkconf لتحديث المعلمات
spark.executor.coresوspark.executor.memory.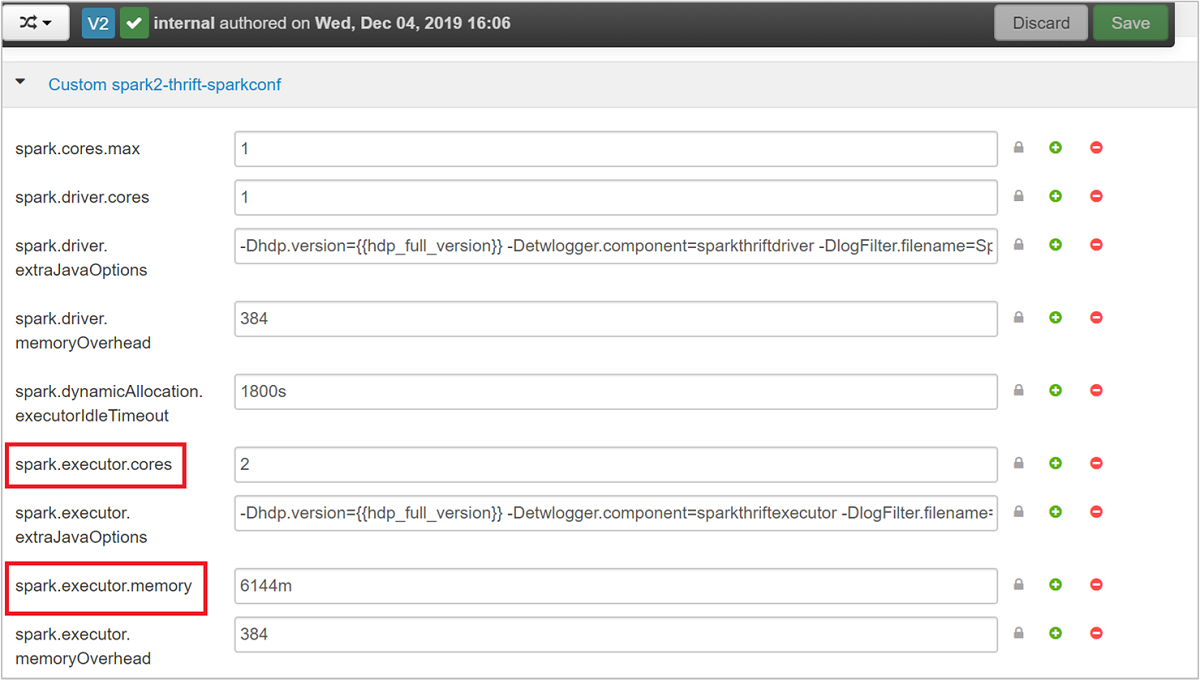
قم بتغيير ذاكرة برنامج تشغيل خادم Spark Thrift
تم تكوين ذاكرة برنامج تشغيل Spark Thrift Server إلى 25٪ من حجم ذاكرة الوصول العشوائي للعقدة الرئيسة، بشرط أن يكون الحجم الإجمالي لذاكرة الوصول العشوائي للعقدة الرئيسة أكبر من 14 غيغابايت. يمكنك استخدام Ambari UI لتغيير تكوين ذاكرة برنامج التشغيل، كما هو موضح في لقطة الشاشة التالية:
من Ambari UI، انتقل إلى Spark2>Configs>Advanced spark2-env. ثم قم بتوفير قيمة spark_thrift_cmd_opts.
استعادة موارد مجموعة Spark
بسبب التخصيص الديناميكي لـ Spark، فإن الموارد الوحيدة التي يستهلكها خادم التوفير هي موارد رئيسة للتطبيقين. لاستعادة هذه الموارد، يجب إيقاف تشغيل خدمات خادم Thrift على نظام المجموعة.
من Ambari UI، من الجزء الأيمن، حدد Spark2.
في الصفحة التالية، حدد Spark 2 Thrift Servers.
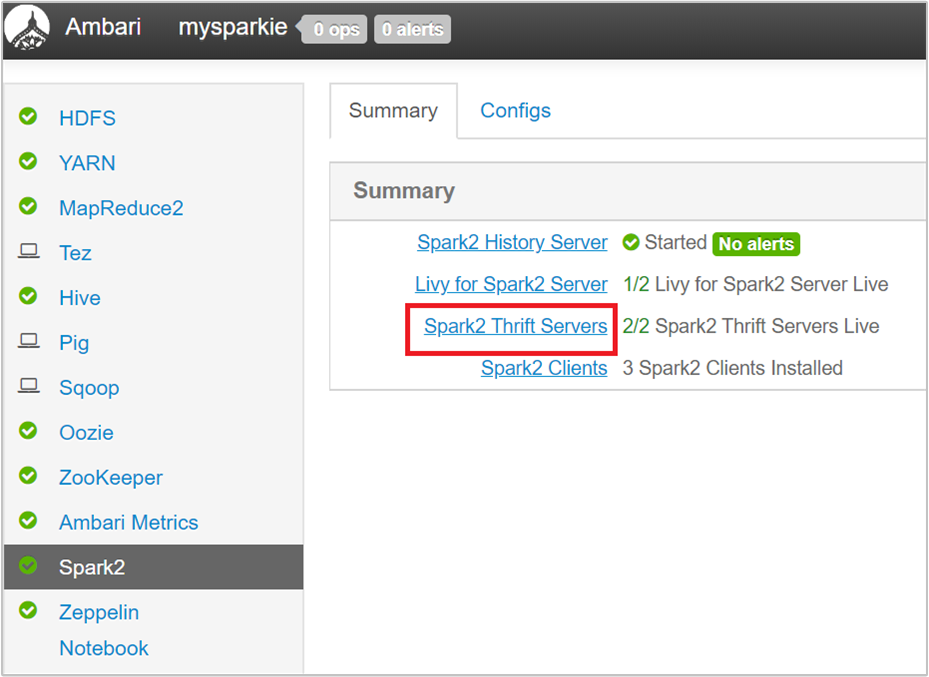
يجب أن تشاهد عقدتي الرأس اللتين يعمل عليها Spark 2 Thrift Server. حدد أحد العناوين الرئيسة.
تسرد الصفحة التالية جميع الخدمات التي تعمل على هذه العقدة الرئيسة. من القائمة، حدد زر القائمة المنسدلة بجوار Spark 2 Thrift Server، ثم حدد Stop.
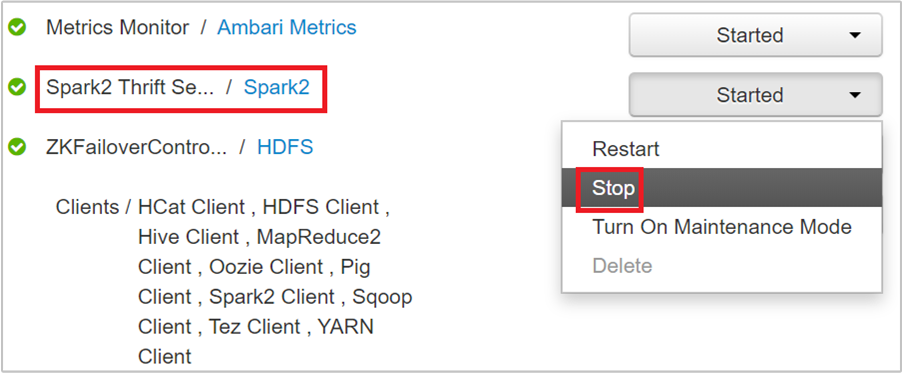
كرر هذه الخطوات على العقدة الرئيسة الأخرى أيضاً.
أعد تشغيل خدمة Jupyter
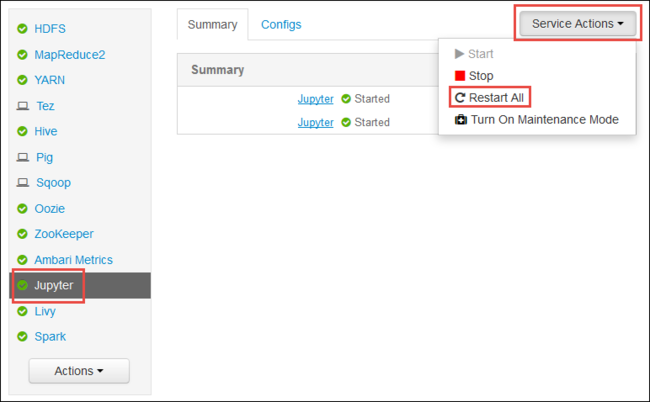
قم بتشغيل Ambari Web UI كما هو موضح في بداية المقالة. من جزء التنقل الأيمن، حدد Jupyter، وحدد Service Actions، ثم حدد Restart All. يؤدي هذا إلى بدء خدمة Jupyter على جميع العُقد الرئيسة.
مراقبة الموارد
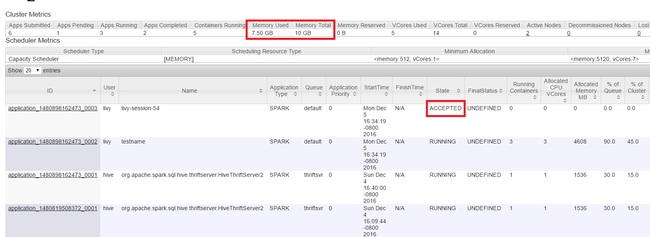
قم بتشغيل Yarn UI كما هو موضح في بداية المقالة. في جدول مقاييس المجموعة أعلى الشاشة، تحقق من قيم أعمدة Memory Used وMemory Total. إذا كانت القيمتان قريبتين، فقد لا تكون هناك موارد كافية لبدء التطبيق التالي. الأمر نفسه ينطبق على أعمدة VCores المستخدمة وVCores Total. أيضاً، في العرض الرئيس، إذا كان هناك تطبيق بقي في الحالة ACCEPTED ولم ينتقل إلى الحالة RUNNING أو FAILED، فقد يكون هذا أيضاً إشارة إلى أنه لا تحصل على موارد كافية للبدء.
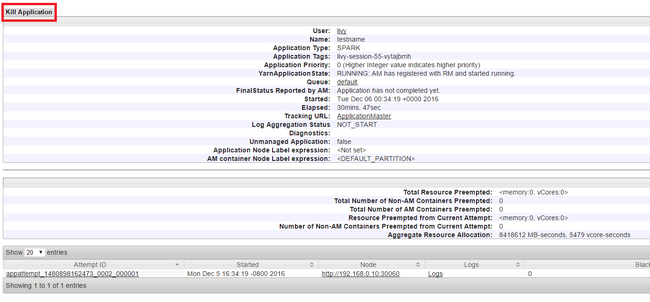
اقتل التطبيقات قيد التشغيل
في Yarn UI، من اللوحة اليسرى، حدد Running. من قائمة التطبيقات قيد التشغيل، حدد التطبيق المراد إيقاف تشغيله وحدد ID.
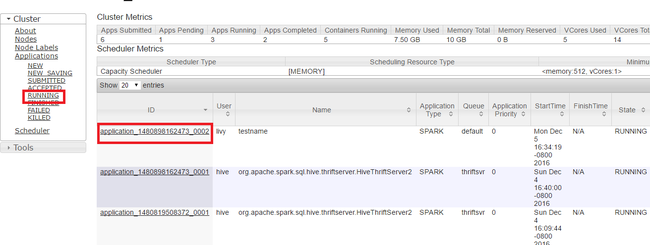
حدد Kill Application في الزاوية العلوية اليمنى، ثم حدد OK.
(راجع أيضًا )
لمحللي البيانات
- Apache Spark مع التعلم الآلي: استخدام Spark في HDInsight لتحليل درجة حرارة المبنى باستخدام بيانات HVAC
- Apache Spark مع التعلم الآلي: استخدم Spark في HDInsight للتنبؤ بنتائج فحص الأغذية
- تحليل سجل موقع الويب باستخدام Apache Spark في HDInsight
- تحليل بيانات قياس البيانات عن بُعد لتطبيق Application Insight باستخدام Apache Spark في HDInsight
لمطوري Apache سبارك
- إنشاء تطبيق مستقل باستخدام Scala
- شغل الوظائف عن بعد على مجموعة Apache Spark باستخدام Apache Livy
- استخدم HDInsight Tools Plugin لـ IntelliJ IDEA لإنشاء وإرسال تطبيقات Spark Scala
- استخدم HDInsight Tools Plugin لـ IntelliJ IDEA لتصحيح أخطاء تطبيقات Apache Spark عن بُعد
- استخدام دفاتر ملاحظات Apache Zeppelin مع نظام مجموعة Apache Spark على HDInsight
- تتوفر Kernels لـ Jupyter Notebook في مجموعة Apache Spark لـ HDInsight
- استخدام الحزم الخارجية مع دفاتر ملاحظات Jupyter
- تثبيت Jupyter على جهاز الكمبيوتر الخاص بك، والاتصال بنظام مجموعة HDInsight Spark