نظرة عامة على Apache Spark Streaming
يوفر البثApache Spark معالجة دفق البيانات على مجموعات HDInsight Spark. مع ضمان معالجة أي حدث إدخال مرة واحدة بالضبط، حتى في حالة حدوث فشل في العقدة. تعد Spark Stream مهمة طويلة الأمد تتلقى بيانات الإدخال من مجموعة متنوعة من المصادر، بما في ذلك مراكز الأحداث. أيضاً: Azure IoT Hub أو Apache Kafka أو Apache Flume أو Twitter أو ZeroMQأو مقابس TCP الخام أو من مراقبة أنظمة ملفات Apache Hadoop YARN. على عكس العملية التي تعتمد على الحدث فقط، يقوم Spark Stream بدفع بيانات الإدخال إلى نوافذ زمنية. مثل شريحة مدتها ثانيتان، ثم يقوم بتحويل كل دفعة من البيانات باستخدام عمليات الخريطة وتقليلها وضمها واستخراجها. يقوم Spark Stream بعد ذلك بكتابة البيانات المحولة إلى أنظمة الملفات وقواعد البيانات ولوحات المعلومات ووحدة التحكم.
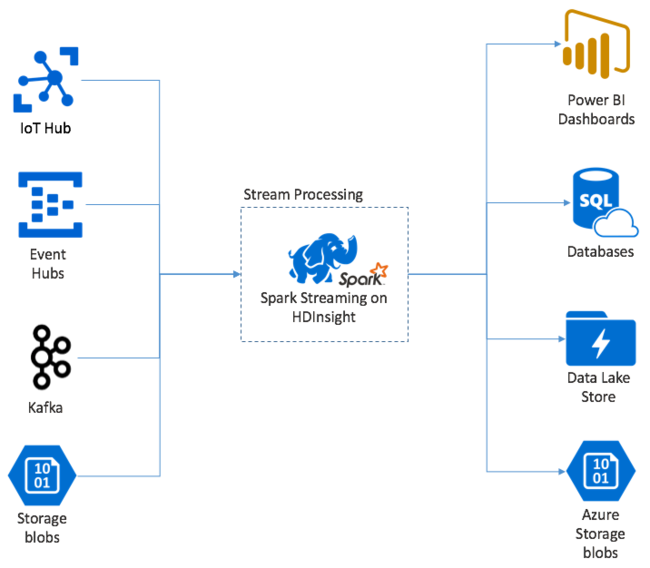
يجب أن تنتظر تطبيقات Spark Streaming جزءاً من الثانية لتجميع كلٍّ micro-batch من الأحداث قبل إرسال تلك الدفعة للمعالجة. في المقابل، فإن التطبيق القائم على الحدث يعالج كل حدث مباشرة. عادة ما يكون زمن انتقال Spark Streaming أقل من بضع ثوان. فوائد نهج الدفعات الدقيقة هي معالجة البيانات بكفاءة أكبر والحسابات التجميعية الأبسط.
نقدم لكم DStream
يمثل Spark Streaming دفقاً مستمراً للبيانات الواردة باستخدام دفق منفصل يسمى DStream. يمكن إنشاء DStream من مصادر الإدخال مثل مراكز الأحداث أو Kafka. أو عن طريق تطبيق التحويلات على DStream آخر.
يوفر DStream طبقة من التجريد أعلى بيانات الحدث الأولية.
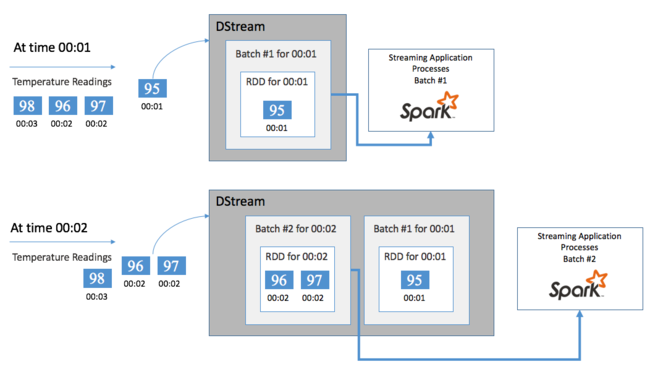
ابدأ بحدث واحد، قل قراءة درجة الحرارة من منظم حرارة متصل. عندما يصل هذا الحدث إلى تطبيق Spark Streaming الخاص بك، يتم تخزين الحدث بطريقة موثوق فيها، حيث يتم نسخه على عُقد متعددة. يضمن هذا التسامح مع الخطأ أن فشل أي عقدة واحدة لن يؤدي إلى فقدان الحدث الخاص بك. يستخدم Spark core بنية بيانات توزع البيانات عبر عُقد متعددة في الكتلة. حيث تحتفظ كل عقدة بشكل عام ببياناتها الخاصة في الذاكرة للحصول على أفضل أداء. تُسمى بنية البيانات هذه مجموعة البيانات الموزعة المرنة (RDD).
يمثل كل RDD الأحداث التي تم جمعها خلال إطار زمني محدد من قِبل المستخدم يُسمى الفاصل الزمني للدفعة. مع انقضاء كل فاصل زمني دفعي، يتم إنتاج RDD جديد يحتوي على جميع البيانات من هذا الفاصل الزمني. يتم تجميع مجموعة RDD المستمرة في DStream. على سبيل المثال، إذا كان الفاصل الزمني الدفعي ثانية واحدة طويلة، فسيُطلق DStream دفعة كل ثانية تحتوي على RDD واحد يحتوي على جميع البيانات المُستوعبة أثناء تلك الثانية. عند معالجة DStream، يظهر حدث درجة الحرارة في إحدى هذه الدفعات. يقوم تطبيق Spark Streaming بمعالجة الدفعات التي تحتوي على الأحداث ويعمل في النهاية على البيانات المخزنة في كل RDD.
هيكل تطبيق Spark Streaming
تطبيق Spark Streaming هو تطبيق يعمل لفترة طويلة يتلقى البيانات من مصادر الإدخال. يطبق عمليات التحويل لمعالجة البيانات، ثم يدفع البيانات إلى وجهة واحدة أو أكثر. يحتوي هيكل تطبيق Spark Streaming على جزء ثابت وجزء ديناميكي. يحدد الجزء الثابت من أين تأتي البيانات، وما هي المعالجة التي يجب القيام بها على البيانات. وإلى أين يجب أن تذهب النتائج. يقوم الجزء الديناميكي بتشغيل التطبيق إلى أجل غير مسمى، في انتظار إشارة التوقف.
على سبيل المثال، يتلقى التطبيق البسيط التالي سطراً من النص عبر مقبس TCP ويحسب عدد المرات التي تظهر فيها كل كلمة.
حدد التطبيق
يتضمن تعريف منطق التطبيق أربع خطوات:
- قم بإنشاء StreamingContext.
- قم بإنشاء DStream من StreamingContext.
- تطبيق التحويلات على DStream.
- إخراج النتائج.
هذا التعريف ثابت، ولا تتم معالجة أية بيانات حتى تقوم بتشغيل التطبيق.
قم بإنشاء StreamingContext
قم بإنشاء StreamingContext من SparkContext الذي يشير إلى المجموعة الخاصة بك. عند إنشاء StreamingContext، فإنك تحدد حجم الدُفعة بالثواني، على سبيل المثال:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
قم بإنشاء DStream
باستخدام مثيل StreamingContext، قم بإنشاء إدخال DStream لمصدر الإدخال الخاص بك. في هذه الحالة، يراقب التطبيق ظهور الملفات الجديدة في وحدة التخزين المرفقة الافتراضية.
val lines = ssc.textFileStream("/uploads/Test/")
تطبيق التحويلات
يمكنك تنفيذ المعالجة من خلال تطبيق التحويلات على DStream. يتلقى هذا التطبيق سطراً واحداً من النص في المرة الواحدة من الملف، ويقسم كل سطر إلى كلمات. ثم يستخدم نمط تقليل الخريطة لحساب عدد مرات ظهور كل كلمة.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
نتائج الإخراج
دفع نتائج التحويل إلى أنظمة الوجهة من خلال تطبيق عمليات الإخراج. في هذه الحالة، تتم طباعة نتيجة كل عملية تشغيل خلال الحساب في إخراج وحدة التحكم.
wordCounts.print()
شغّل التطبيق
قم ببدء تشغيل تطبيق البث وتشغيله حتى يتم استلام إشارة الإنهاء.
ssc.start()
ssc.awaitTermination()
للحصول على تفاصيل حول Spark Stream API، راجع دليل برمجة دفق Apache Spark.
نموذج التطبيق التالي مستقل بذاته، لذا يمكنك تشغيله داخل Jupyter Notebook. يقوم هذا المثال بإنشاء مصدر بيانات وهمي في فئة DummySource يُنتج قيمة العداد والوقت الحالي بالمللي ثانية كل خمس ثوانٍ. يحتوي عنصر StreamingContext الجديد على فاصل زمني للدفعات يبلغ 30 ثانية. في كل مرة يتم فيها إنشاء دفعة، يفحص التطبيق المتدفق RDD المنتج. ثم يحول RDD إلى Spark DataFrame، ويقوم بإنشاء جدول مؤقت فوق DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
انتظر حوالي 30 ثانية بعد بدء التطبيق أعلاه. بعد ذلك، يمكنك الاستعلام عن DataFrame بشكل دوري لمعرفة المجموعة الحالية من القيم الموجودة في الدفعة، على سبيل المثال باستخدام استعلام SQL هذا:
%%sql
SELECT * FROM demo_numbers
الناتج المُخرَج يشبه الناتج التالي:
| قيمة | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
هناك ست قيم، حيث يقوم DummySource بإنشاء قيمة كل 5 ثوانٍ ويقوم التطبيق بإرسال دفعة كل 30 ثانية.
النوافذ المنزلقة
لإجراء عمليات حسابية مجمعة على DStream خلال فترة زمنية معينة، على سبيل المثال للحصول على متوسط درجة الحرارة خلال ثانيتين أخيرتين، استخدم عمليات sliding window المضمنة في Spark Streaming. تحتوي النافذة المنزلقة على مدة (طول النافذة) والفاصل الزمني الذي يتم خلاله تقييم محتويات النافذة (فاصل الشريحة).
يمكن أن تتداخل النوافذ المنزلقة، على سبيل المثال، يمكنك تحديد نافذة بطول ثانيتين، والتي تنزلق كل ثانية واحدة. يعني هذا الإجراء أنه في كل مرة تقوم فيها بحساب التجميع، ستشمل النافذة بيانات من آخر ثانية من النافذة السابقة. وأي بيانات جديدة في الثانية التالية.
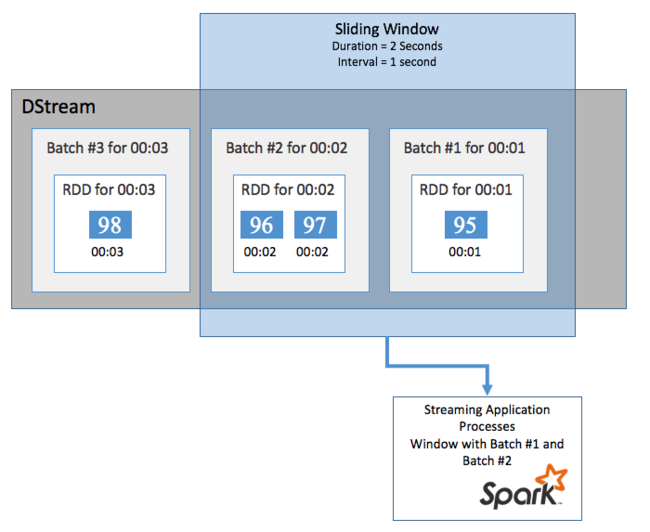
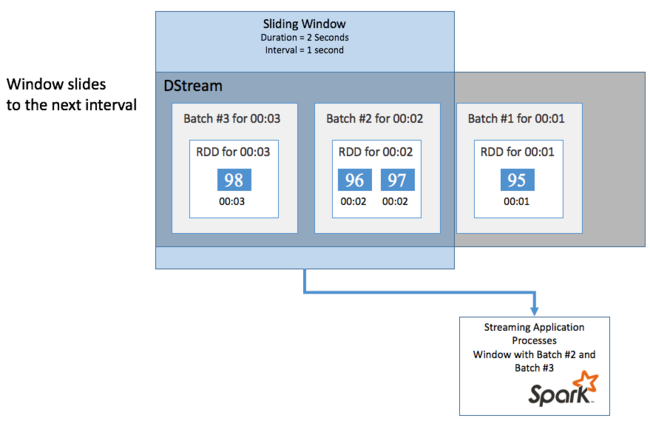
يقوم المثال التالي بتحديث التعليمة البرمجية الذي يستخدم DummySource، لتجميع الدُفعات في نافذة بمدة دقيقة واحدة وشريحة مدتها دقيقة واحدة.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
بعد الدقيقة الأولى، هناك 12 إدخالاً - ستة إدخالات من كل دفعة من الدُفعتين اللتين تم جمعهما في النافذة.
| قيمة | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
تتضمن وظائف النافذة المنزلقة المتوفرة في نافذة Spark Streaming API وcountByWindow وRedByWindow وcountByValueAndWindow. للحصول على تفاصيل حول هذه الوظائف، راجع التحويلات على DStreams.
التحقق
لتوفير المرونة والتسامح مع الخطأ، يعتمد Spark Streaming على نقاط التفتيش لضمان استمرار معالجة التدفق دون انقطاع، حتى في مواجهة حالات فشل العقدة. يُنشئ Spark نقاط فحص للتخزين الدائم (تخزين Azure أو تخزين بحيرة البيانات). تخزن نقاط التحقق هذه بيانات التعريف للتطبيق المتدفق مثل التكوين والعمليات التي يحددها التطبيق. أيضاً، أي دفعات تم وضعها في قائمة الانتظار ولكن لم تتم معالجتها بعد. في بعض الأحيان، ستشمل نقاط التفتيش أيضاً حفظ البيانات في RDDs لإعادة بناء حالة البيانات بسرعة أكبر مما هو موجود في RDDs التي تديرها Spark.
توزيع تطبيقات Spark Streaming
تقوم عادةً بإنشاء تطبيق Spark Streaming محلياً في ملف JAR. ثم توزيعه على Spark على HDInsight عن طريق نسخ ملف JAR إلى وحدة التخزين المرفقة الافتراضية. يمكنك بدء تطبيقك باستخدام واجهات برمجة تطبيقات LIVY REST المتاحة من مجموعتك باستخدام عملية POST. يتضمن نص POST مستند JSON الذي يوفر المسار إلى JAR الخاص بك. واسم الفئة التي تحدد طريقتها الرئيسة تطبيق الدفق وتشغله، واختيارياً متطلبات الموارد للوظيفة (مثل عدد المنفذين والذاكرة والنوى). أيضاً، أي إعدادات تكوين يتطلبها رمز التطبيق الخاص بك.
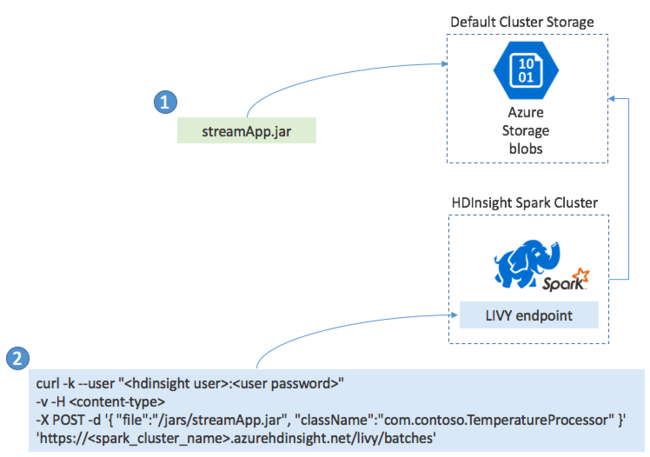
يمكن أيضاً التحقق من حالة جميع التطبيقات من خلال طلب GET مقابل نقطة نهاية LIVY. أخيراً، يمكنك إنهاء تطبيق قيد التشغيل عن طريق إصدار طلب DELETE مقابل نقطة نهاية LIVY. للحصول على تفاصيل حول LIVY API، راجع المهام عن بُعد باستخدام Apache LIVY