تحسين استخدام الذاكرة لـ Apache Spark
تتناول هذه المقالة كيفية تحسين إدارة ذاكرة نظام مجموعة Apache Spark للحصول على أفضل أداء على Azure HDInsight.
يعمل Spark بوضع البيانات في الذاكرة. لذلك تعد إدارة موارد الذاكرة جانبًا رئيسيًا لتحسين تنفيذ وظائف Spark. توجد العديد من التقنيات التي يمكنك تطبيقها لاستخدام ذاكرة نظام المجموعة بكفاءة.
- تُفضل أقسام البيانات الأصغر حجمًا والحساب لحجم البيانات وأنواعها وتوزيعها في استراتيجية التقسيم لديك.
- ضع في اعتبارك الأحدث والأكثر كفاءة
Kryo data serialization، بدلاً من تسلسل Java الافتراضي. - يفضل باستخدام YARN لأنه يفصل
spark-submitبالدُفعة. - مراقبة وضبط إعدادات تكوين Spark.
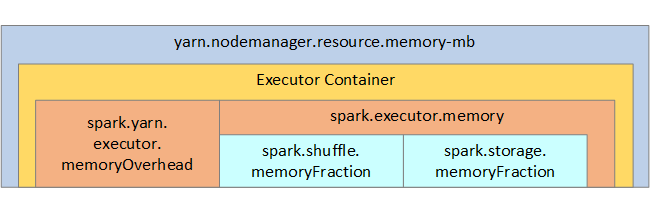
لاطلاعكم، يتم عرض بنية ذاكرة Spark وبعض معلمات الذاكرة المنفذ للمفاتيح في الصورة التالية.
إذا كنت تستخدم Apache Hadoop YARN، ثم تتحكم YARN بالذاكرة المستخدمة من قبل جميع الحاويات على كل عقد Spark. يوضح الرسم التخطيطي التالي الكائنات الرئيسية وعلاقاتها.
لمعالجة رسائل 'نفاد الذاكرة'، جرب ما يلي:
- راجع DAG Management Shuffles. تقليل بواسطة التقليل من جانب الخريطة، ما قبل تقسيم و (أو تجميع) لبيانات المصدر، وزيادة الخلط المفرد، وتقليل كمية البيانات المرسلة.
- يُفضل
ReduceByKeyبحد الذاكرة الثابتة الخاص بهGroupByKey، الذي يوفر التجميعات والنوافذ والوظائف الأخرى التي لديها حد ذاكرة غير محدود. - يُفضل
TreeReduceالذي يقوم بمزيد من العمل على المنفذين أو الأقسام، إلىReduceالذي يقوم بكل العمل على المشغل. - استخدام DataFrames بدلاً من عناصر RDD بالمستوى الأدنى.
- إنشاء ComplexTypes التي تغلف الإجراءات، مثل "Top N" أو التجميعات المختلفة أو عمليات النوافذ.
للحصول على خطوات إضافية لاستكشاف الأخطاء وإصلاحها، راجع استثناءات OutOfMemoryError لـ Apache Spark في Azure HDInsight.