إعداد AutoML لتدريب نموذج تنبؤ سلسلة زمنية باستخدام SDK وCLI
ينطبق على: ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
ملحق ML Azure CLI v2 (الحالي)Python SDK azure-ai-ml v2 (الحالي)
في هذه المقالة، ستتعلم كيفية إعداد AutoML للتنبؤ بالسلاسل الزمنية باستخدام Azure التعلم الآلي ML التلقائي في Azure التعلم الآلي Python SDK.
للقيام بذلك عليك ما يلي:
للحصول على تجربة تعليمات برمجية منخفضة، راجع البرنامج التعليمي: التنبؤ بالطلب باستخدام التعلم الآلي التلقائي للحصول على مثال للتنبؤ بالسلاسل الزمنية باستخدام التعلم الآلي التلقائي في استوديو التعلم الآلي من Microsoft Azure.
يستخدم AutoML نماذج التعلم الآلي القياسية جنبا إلى جنب مع نماذج السلاسل الزمنية المعروفة لإنشاء التنبؤات. يتضمن نهجنا معلومات تاريخية حول المتغير الهدف، والميزات التي يوفرها المستخدم في بيانات الإدخال، والميزات الهندسية تلقائيا. ثم تعمل خوارزميات البحث النموذجي للعثور على نموذج بأفضل دقة تنبؤية. لمزيد من التفاصيل، راجع مقالاتنا حول منهجية التنبؤ والبحث النموذجي.
المتطلبات الأساسية
بالنسبة لهذه المقالة، تحتاج إلى،
مساحة عمل للتعلم الآلي من Microsoft Azure. لإنشاء مساحة العمل، انظر إنشاء موارد مساحة العمل .
القدرة على تشغيل مهام تدريب AutoML. اتبع دليل الكيفية لإعداد AutoML للحصول على التفاصيل.
بيانات التدريب والتحقق من الصحة
يجب أن تحتوي بيانات الإدخال للتنبؤ التلقائي على سلسلة زمنية صالحة بتنسيق جدولي. يجب أن يكون لكل متغير عمود مطابق خاص به في جدول البيانات. يتطلب AutoML عمودين على الأقل: عمود وقت يمثل المحور الزمني والعمود الهدف وهو الكمية التي يجب التنبؤ بها. يمكن أن تعمل الأعمدة الأخرى كمتنبؤات. لمزيد من التفاصيل، راجع كيفية استخدام AutoML لبياناتك.
هام
عند تدريب نموذج للتنبؤ بالقيم المستقبلية، تأكد من إمكانية استخدام جميع الميزات المستخدمة في التدريب عند تشغيل التنبؤات للأفق المقصود.
على سبيل المثال، يمكن أن تؤدي إحدى ميزات سعر السهم الحالي إلى زيادة دقة التدريب بشكل كبير. ومع ذلك، إذا كنت تنوي التنبؤ بأفق طويل، فقد لا تتمكن من التنبؤ بدقة بقيم الأسهم المستقبلية المقابلة لنقاط السلسلة الزمنية المستقبلية، وقد تعاني دقة النموذج.
تتطلب مهام التنبؤ ب AutoML تمثيل بيانات التدريب كعنصر MLTable . يحدد MLTable مصدر بيانات وخطوات لتحميل البيانات. لمزيد من المعلومات وحالات الاستخدام، راجع دليل كيفية MLTable. كمثال بسيط، افترض أن بيانات التدريب الخاصة بك موجودة في ملف CSV في دليل محلي، ./train_data/timeseries_train.csv.
يمكنك إنشاء MLTable باستخدام mltable Python SDK كما في المثال التالي:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
تنشئ هذه التعليمة البرمجية ملفا جديدا، ./train_data/MLTableيحتوي على تنسيق الملف وإرشادات التحميل.
يمكنك الآن تعريف عنصر بيانات إدخال، وهو مطلوب لبدء مهمة تدريب، باستخدام Azure التعلم الآلي Python SDK كما يلي:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
يمكنك تحديد بيانات التحقق من الصحة بطريقة مماثلة، عن طريق إنشاء MLTable وتحديد إدخال بيانات التحقق من الصحة. بدلا من ذلك، إذا لم توفر بيانات التحقق من الصحة، يقوم AutoML تلقائيا بإنشاء تقسيمات التحقق من الصحة المتقاطعة من بيانات التدريب لاستخدامها في تحديد النموذج. راجع مقالتنا حول تحديد نموذج التنبؤ لمزيد من التفاصيل. راجع أيضا متطلبات طول بيانات التدريب للحصول على تفاصيل حول مقدار بيانات التدريب التي تحتاجها لتدريب نموذج التنبؤ بنجاح.
تعرف على المزيد حول كيفية تطبيق AutoML للتحقق المتقاطع لمنع التأقلم.
حساب لتشغيل التجربة
يستخدم AutoML Azure التعلم الآلي Compute، وهو مورد حساب مدار بالكامل، لتشغيل مهمة التدريب. في المثال التالي، يتم إنشاء نظام مجموعة حساب يسمى cpu-compute :
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()تكوين التجربة
يمكنك استخدام وظائف مصنع automl لتكوين مهام التنبؤ في Python SDK. يوضح المثال التالي كيفية إنشاء مهمة تنبؤ عن طريق تعيين المقياس الأساسي وتعيين حدود على تشغيل التدريب:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
التنبؤ بإعدادات المهمة
تحتوي مهام التنبؤ على العديد من الإعدادات الخاصة بالتنبؤ. وأبسط هذه الإعدادات هي اسم عمود الوقت في بيانات التدريب وأفق التنبؤ.
استخدم أساليب ForecastingJob لتكوين هذه الإعدادات:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
اسم عمود الوقت هو إعداد مطلوب ويجب تعيين أفق التنبؤ بشكل عام وفقا لسيناريو التنبؤ الخاص بك. إذا كانت بياناتك تحتوي على سلاسل زمنية متعددة، يمكنك تحديد أسماء أعمدة معرف السلسلة الزمنية. تحدد هذه الأعمدة، عند تجميعها، السلسلة الفردية. على سبيل المثال، افترض أن لديك بيانات تتكون من مبيعات كل ساعة من متاجر وعلامات تجارية مختلفة. يوضح النموذج التالي كيفية تعيين أعمدة معرف السلسلة الزمنية بافتراض أن البيانات تحتوي على أعمدة تسمى "store" و"brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
يحاول AutoML الكشف تلقائيا عن أعمدة معرف السلسلة الزمنية في بياناتك إذا لم يتم تحديد أي منها.
الإعدادات الأخرى اختيارية ومراجعتها في القسم التالي.
إعدادات مهمة التنبؤ الاختيارية
تتوفر التكوينات الاختيارية لمهام التنبؤ، مثل تمكين التعلم العميق وتحديد تجميع نافذة متجددة مستهدفة. تتوفر قائمة كاملة بالمعلمات في وثائق الوثائق المرجعية للتنبؤ.
إعدادات البحث في النموذج
هناك إعدادان اختياريان يتحكمان في مساحة النموذج حيث يبحث AutoML عن أفضل نموذج، allowed_training_algorithms و blocked_training_algorithms. لتقييد مساحة البحث بمجموعة معينة من فئات النموذج، استخدم المعلمة allowed_training_algorithms كما في النموذج التالي:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
في هذه الحالة، تبحث مهمة التنبؤ فقط عبر فئات نموذج التجانس الأسي والشبكة المرنة. لإزالة مجموعة معينة من فئات النموذج من مساحة البحث، استخدم blocked_training_algorithms كما في النموذج التالي:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
الآن، تبحث الوظيفة على جميع فئات النموذج باستثناء النبي. للحصول على قائمة بأسماء نماذج التنبؤ المقبولة في allowed_training_algorithms وblocked_training_algorithms، راجع الوثائق المرجعية لخصائص التدريب. إما، ولكن ليس كليهما، من allowed_training_algorithms blocked_training_algorithms و يمكن تطبيقهما على تشغيل التدريب.
تمكين التعلم العميق
يشحن AutoML مع نموذج شبكة عصبية عميقة مخصصة (DNN) يسمى TCNForecaster. هذا النموذج هو شبكة التفافية زمنية، أو TCN، تطبق أساليب مهمة التصوير الشائعة على نمذجة السلاسل الزمنية. وعلى وجه التحديد، تشكل الالتفافات "السببية" أحادية الأبعاد العمود الفقري للشبكة وتمكن النموذج من تعلم أنماط معقدة على مدى فترات طويلة في تاريخ التدريب. لمزيد من التفاصيل، راجع مقالة TCNForecaster.
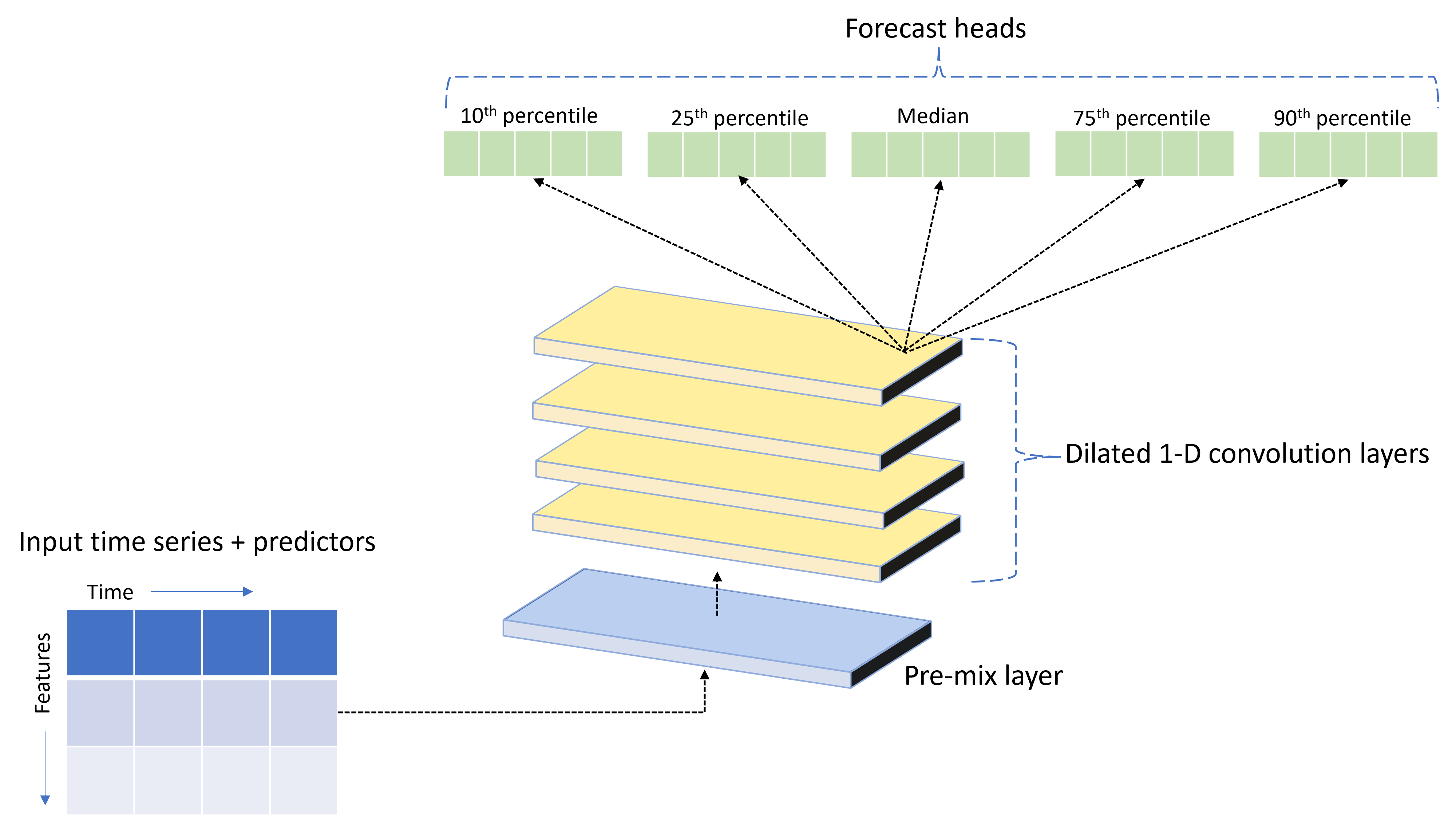
غالبا ما يحقق TCNForecaster دقة أعلى من نماذج السلاسل الزمنية القياسية عندما يكون هناك الآلاف أو أكثر من الملاحظات في تاريخ التدريب. ومع ذلك، يستغرق الأمر أيضا وقتا أطول لتدريب ومسح نماذج TCNForecaster بسبب قدرتها الأعلى.
يمكنك تمكين TCNForecaster في AutoML عن طريق تعيين العلامة enable_dnn_training في تكوين التدريب كما يلي:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
بشكل افتراضي، يقتصر تدريب TCNForecaster على عقدة حساب واحدة و GPU واحدة، إذا كانت متوفرة، لكل إصدار تجريبي للنموذج. بالنسبة لسيناريوهات البيانات الكبيرة، نوصي بتوزيع كل إصدار تجريبي من TCNForecaster على عدة ذاكرات أساسية/وحدات معالجة الرسومات والعقد. راجع قسم مقالة التدريب الموزعة للحصول على مزيد من المعلومات وعينات التعليمات البرمجية.
لتمكين DNN لتجربة AutoML التي تم إنشاؤها في استوديو التعلم الآلي من Microsoft Azure، راجع إعدادات نوع المهمة في طريقة استخدام واجهة مستخدم الاستوديو.
إشعار
- عند تمكين DNN للتجارب التي تم إنشاؤها باستخدام SDK، يتم تعطيل أفضل تفسيرات النموذج.
- دعم DNN للتنبؤ في التعلم الآلي التلقائي غير مدعوم للتشغيلات التي بدأت في Databricks.
- يوصى بأنواع حوسبة GPU عند تمكين تدريب DNN
ميزات النوافذ المتدرجة والمتأخرة
غالبا ما تكون القيم الحديثة للهدف ميزات مؤثرة في نموذج التنبؤ. وفقا لذلك، يمكن ل AutoML إنشاء ميزات تجميع نافذة متدرجة ومفصلة زمنيا لتحسين دقة النموذج.
ضع في اعتبارك سيناريو التنبؤ بالطلب على الطاقة حيث تتوفر بيانات الطقس والطلب التاريخي. يعرض الجدول هندسة الميزات الناتجة التي تحدث عند تطبيق تجميع النوافذ على مدار الساعات الثلاث الأخيرة. يتم إنشاء أعمدة الحد الأدنى والحد الأقصى والمجموع على نافذة منزلقة مكونة من ثلاث ساعات استنادا إلى الإعدادات المحددة. على سبيل المثال، بالنسبة إلى الملاحظة الصالحة في 8 سبتمبر 2017 الساعة 4:00 صباحا، يتم حساب القيم القصوى والحد الأدنى والمجموع باستخدام قيم الطلب ل 8 سبتمبر 2017 من الساعة 1:00 صباحا إلى 3:00 صباحا. تنتقل هذه النافذة المكونة من ثلاث ساعات لتعبئة البيانات للصفوف المتبقية. لمزيد من التفاصيل والأمثلة، راجع مقالة ميزة التأخر.

يمكنك تمكين ميزات تجميع النوافذ المتداولة والتأجيل للهدف عن طريق تعيين حجم النافذة المتداولة، والذي كان ثلاثة في المثال السابق، وأوامر التأخير التي تريد إنشاؤها. يمكنك أيضا تمكين التأخر في الميزات باستخدام feature_lags الإعداد. في النموذج التالي، قمنا بتعيين كل هذه الإعدادات إلى auto بحيث يحدد AutoML الإعدادات تلقائيا عن طريق تحليل بنية الارتباط لبياناتك:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
معالجة السلاسل القصيرة
يعتبر التعلم الآلي التلقائي سلسلة زمنية سلسلة قصيرة إذا لم تكن هناك نقاط بيانات كافية لإجراء مراحل التدريب والتحقق من صحة تطوير النموذج. راجع متطلبات طول بيانات التدريب لمزيد من التفاصيل حول متطلبات الطول.
يحتوي AutoML على العديد من الإجراءات التي يمكن أن يتخذها للسلسلة القصيرة. هذه الإجراءات قابلة للتكوين باستخدام short_series_handling_config الإعداد . القيمة الافتراضية هي "تلقائي". يصف الجدول التالي الإعدادات:
| الإعدادات | الوصف |
|---|---|
auto |
القيمة الافتراضية لمعالجة السلاسل القصيرة. - إذا كانت جميع السلاسل قصيرة، فبادر بلوحة البيانات. - إذا لم تكن جميع السلاسل قصيرة، فقم بإفلات السلسلة القصيرة. |
pad |
في حالة short_series_handling_config = pad، فإن التعلم الآلي المؤتمت يضيف قيماً عشوائية إلى كل سلسلة قصيرة تم العثور عليها. يسرد ما يلي أنواع الأعمدة وما تتم إضافتها به: - أعمدة الكائنات مع NaNs - أعمدة رقمية مع 0 - أعمدة منطقية/منطقية مع False - تتم إضافة العمود الهدف بضوضاء بيضاء. |
drop |
إذا short_series_handling_config = drop، فإن التعلم الآلي المؤتمت يسقط السلسلة القصيرة، ولن يتم استخدامه للتدريب أو التنبؤ. التوقعات لهذه السلسلة سترجع NaN's. |
None |
لم تتم إضافة أي سلسلة أو إسقاطها |
في المثال التالي، قمنا بتعيين معالجة السلسلة القصيرة بحيث تتم إضافة جميع السلاسل القصيرة إلى الحد الأدنى للطول:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
تحذير
قد يؤثر ترك المساحة على دقة النموذج الناتج، لأننا نقدم بيانات اصطناعية لتجنب فشل التدريب. إذا كانت العديد من السلاسل قصيرة، فقد ترى أيضًا بعض التأثير في نتائج التفسير
تكرار تجميع البيانات المستهدفة
استخدم خيارات التكرار وتجميع البيانات لتجنب حالات الفشل الناجمة عن البيانات غير المنتظمة. تكون بياناتك غير منتظمة إذا لم تتبع إيقاعا معينا في الوقت المناسب، مثل كل ساعة أو يوميا. تعد بيانات نقطة البيع مثالا جيدا على البيانات غير المنتظمة. في هذه الحالات، يمكن ل AutoML تجميع بياناتك إلى التردد المطلوب ثم إنشاء نموذج تنبؤ من التجميعات.
تحتاج إلى تعيين frequency الإعدادات و target_aggregate_function للتعامل مع البيانات غير المنتظمة. يقبل إعداد التردد سلاسل Pandas DateOffset كإدخال. القيم المدعومة لدالة التجميع هي:
| الوظيفة | الوصف |
|---|---|
sum |
مجموع القيم الهدف |
mean |
متوسط أو معدل القيم المستهدفة |
min |
الحد الأدنى لقيمة الهدف |
max |
الحد الأقصى لقيمة الهدف |
- يتم تجميع قيم العمود الهدف وفقا للعملية المحددة. عادة ما يكون المجموع مناسبا لمعظم السيناريوهات.
- يتم تجميع أعمدة التنبؤ الرقمي في البيانات الخاصة بك حسب المجموع، والمتوسط، والحد الأدنى للقيمة، والقيمة القصوى. ونتيجة لذلك، ينشئ التعلم الآلي التلقائي أعمدة جديدة لاحقة باسم دالة التجميع ويطبق العملية التجميعية المحددة.
- بالنسبة لأعمدة التنبؤ الفئوية، يتم تجميع البيانات حسب الوضع، وهي الفئة الأكثر بروزا في النافذة.
- يتم تجميع أعمدة متنبأ التاريخ حسب الحد الأدنى للقيمة والحد الأقصى للقيمة ووضعها.
يعين المثال التالي التكرار إلى كل ساعة ودالة التجميع إلى الجمع:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
إعدادات مخصصة للتحقق من الصحة المشترك
هناك إعدادان قابلان للتخصيص يتحكمان في التحقق المتقاطع لوظائف التنبؤ: عدد الطيات، n_cross_validationsوحجم الخطوة الذي يحدد إزاحة الوقت بين الطيات، cv_step_size. راجع تحديد نموذج التنبؤ لمزيد من المعلومات حول معنى هذه المعلمات. بشكل افتراضي، يقوم AutoML بتعيين كلا الإعدادين تلقائيا استنادا إلى خصائص بياناتك، ولكن قد يرغب المستخدمون المتقدمون في تعيينهما يدويا. على سبيل المثال، افترض أن لديك بيانات مبيعات يومية وتريد أن يتكون إعداد التحقق من الصحة من خمسة طيات مع إزاحة سبعة أيام بين الطيات المجاورة. يوضح نموذج التعليمات البرمجية التالي كيفية تعيين هذه:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
تمييز مخصص
بشكل افتراضي، يقوم AutoML بزيادة بيانات التدريب بميزات هندسية لزيادة دقة النماذج. راجع هندسة الميزات التلقائية لمزيد من المعلومات. يمكن تخصيص بعض خطوات المعالجة المسبقة باستخدام تكوين التمييز لمهمة التنبؤ.
توجد التخصيصات المدعومة للتنبؤ في الجدول التالي:
| التخصيص | الوصف | الخيارات |
|---|---|---|
| تحديث الغرض من العمود | تجاوز نوع الميزة المكتشف تلقائياً للعمود المحدد. | "فئوي"، "التاريخ والوقت"، "رقمي" |
| تحديث معلمة المحول | تحديث المعلمات الخاصة بالوصف المحدد. | {"strategy": "constant", "fill_value": <value>}، ، {"strategy": "median"}{"strategy": "ffill"} |
على سبيل المثال، افترض أن لديك سيناريو طلب البيع بالتجزئة حيث تتضمن البيانات الأسعار وعلامة "عند البيع" ونوع المنتج. يوضح النموذج التالي كيف يمكنك تعيين الأنواع المخصصة وعناصر الإسناد لهذه الميزات:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
إذا كنت تستخدم استوديو التعلم الآلي من Azure لتجربتك، فشاهد كيفية تخصيص التمييز في الاستوديو.
إرسال مهمة تنبؤ
بعد تكوين جميع الإعدادات، يمكنك تشغيل مهمة التنبؤ كما يلي:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
بمجرد إرسال المهمة، سيوفر AutoML موارد الحوسبة، ويطبق التمييز وخطوات الإعداد الأخرى على بيانات الإدخال، ثم يبدأ في مسح نماذج التنبؤ. لمزيد من التفاصيل، راجع مقالاتنا حول منهجية التنبؤ والبحث النموذجي.
تنظيم التدريب والاستدلال والتقييم باستخدام المكونات والتدفقات
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يجري توفير إصدار المعاينة هذا دون اتفاقية على مستوى الخدمة، ولا نوصي باستخدامه لأحمال عمل الإنتاج. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة.
لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
من المحتمل أن يتطلب سير عمل التعلم الآلي أكثر من مجرد التدريب. الاستدلال، أو استرداد تنبؤات النموذج على البيانات الأحدث، وتقييم دقة النموذج على مجموعة اختبار مع قيم مستهدفة معروفة هي مهام شائعة أخرى يمكنك تنظيمها في AzureML جنبا إلى جنب مع مهام التدريب. لدعم مهام الاستدلال والتقييم، يوفر AzureML مكونات، وهي أجزاء قائمة بذاتها من التعليمات البرمجية تقوم بخطوة واحدة في مسار AzureML.
في المثال التالي، نقوم باسترداد التعليمات البرمجية للمكون من سجل عميل:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
بعد ذلك، نقوم بتعريف وظيفة المصنع التي تنشئ البنية الأساسية لبرنامج ربط العمليات التجارية للتدريب والاستدلال والحساب القياسي. راجع قسم تكوين التدريب للحصول على مزيد من التفاصيل حول إعدادات التدريب.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
الآن، نحدد مدخلات بيانات التدريب والاختبار بافتراض أنها موجودة في المجلدات المحلية، ./train_data و ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
وأخيرا، نقوم بإنشاء البنية الأساسية لبرنامج ربط العمليات التجارية، وتعيين حسابها الافتراضي وإرسال المهمة:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
بمجرد الإرسال، يقوم المسار بتشغيل تدريب AutoML واستدلال التقييم المتداول والحساب المتري بالتسلسل. يمكنك مراقبة وفحص التشغيل في واجهة مستخدم الاستوديو. عند الانتهاء من التشغيل، يمكن تنزيل التنبؤات المتداولة ومقاييس التقييم إلى دليل العمل المحلي:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
بعد ذلك، يمكنك العثور على نتائج المقاييس في ./named-outputs/metrics_results/evaluationResult/metrics.json والتنبؤات، بتنسيق خطوط JSON، في ./named-outputs/rolling_fcst_result/inference_output_file.
لمزيد من التفاصيل حول التقييم المتداول، راجع مقالة تقييم نموذج التنبؤ.
التنبؤ على نطاق واسع: العديد من النماذج
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يجري توفير إصدار المعاينة هذا دون اتفاقية على مستوى الخدمة، ولا نوصي باستخدامه لأحمال عمل الإنتاج. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة.
لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
تمكنك العديد من مكونات النماذج في AutoML من تدريب ملايين النماذج وإدارتها بالتوازي. لمزيد من المعلومات حول العديد من مفاهيم النماذج، راجع قسم مقالة العديد من النماذج.
تكوين تدريب العديد من النماذج
يقبل مكون التدريب على العديد من النماذج ملف تكوين تنسيق YAML لإعدادات تدريب AutoML. يطبق المكون هذه الإعدادات على كل مثيل AutoML يقوم بتشغيله. يحتوي ملف YAML هذا على نفس مواصفات وظيفة التنبؤ بالإضافة إلى معلمات partition_column_names إضافية و allow_multi_partitions.
| المعلمة | الوصف |
|---|---|
| partition_column_names | أسماء الأعمدة في البيانات التي، عند تجميعها، تحدد أقسام البيانات. يطلق مكون تدريب النماذج المتعددة مهمة تدريب مستقلة على كل قسم. |
| allow_multi_partitions | علامة اختيارية تسمح بتدريب نموذج واحد لكل قسم عندما يحتوي كل قسم على أكثر من سلسلة زمنية فريدة. القيمة الافتراضية هي False. |
يوفر النموذج التالي قالب تكوين:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
في الأمثلة اللاحقة، نفترض أن التكوين مخزن في المسار، ./automl_settings_mm.yml.
مسار العديد من النماذج
بعد ذلك، نحدد وظيفة المصنع التي تنشئ مسارات لتنسيق العديد من النماذج التدريب والاستدلال والحساب القياسي. معلمات دالة المصنع هذه مفصلة في الجدول التالي:
يوضح النموذج التالي أسلوب المصنع لإنشاء العديد من نماذج التدريب وخطوط أنابيب تقييم النموذج:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
الآن، نقوم بإنشاء البنية الأساسية لبرنامج ربط العمليات التجارية عبر وظيفة المصنع، بافتراض أن بيانات التدريب والاختبار موجودة في المجلدات المحلية، و./data/test، ./data/train على التوالي. وأخيرا، قمنا بتعيين الحساب الافتراضي وإرسال المهمة كما في العينة التالية:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
بعد انتهاء المهمة، يمكن تنزيل مقاييس التقييم محليا باستخدام نفس الإجراء كما هو الحال في مسار تشغيل التدريب الفردي.
راجع أيضا التنبؤ بالطلب مع دفتر ملاحظات العديد من النماذج للحصول على مثال أكثر تفصيلا.
إشعار
تقسم العديد من مكونات التدريب والاستدلال النماذج بياناتك بشكل مشروط وفقا للإعداد partition_column_names بحيث يكون كل قسم في ملفه الخاص. يمكن أن تكون هذه العملية بطيئة جدا أو تفشل عندما تكون البيانات كبيرة جدا. في هذه الحالة، نوصي بتقسيم بياناتك يدويا قبل تشغيل العديد من نماذج التدريب أو الاستدلال.
التنبؤ على نطاق واسع: سلسلة زمنية هرمية
هام
تُعد هذه الميزة قيد الإصدار الأولي العام في الوقت الحالي. يجري توفير إصدار المعاينة هذا دون اتفاقية على مستوى الخدمة، ولا نوصي باستخدامه لأحمال عمل الإنتاج. بعض الميزات ربما لا تكون مدعمة أو بها بعض القدرات المقيدة.
لمزيد من المعلومات، راجع شروط الاستخدام التكميلية لمعاينات Microsoft Azure.
تمكنك مكونات السلسلة الزمنية الهرمية (HTS) في AutoML من تدريب عدد كبير من النماذج على البيانات ذات البنية الهرمية. لمزيد من المعلومات، راجع قسم مقالة HTS.
تكوين تدريب HTS
يقبل مكون تدريب HTS ملف تكوين تنسيق YAML لإعدادات تدريب AutoML. يطبق المكون هذه الإعدادات على كل مثيل AutoML يقوم بتشغيله. يحتوي ملف YAML هذا على نفس مواصفات وظيفة التنبؤ بالإضافة إلى معلمات إضافية تتعلق بمعلومات التسلسل الهرمي:
| المعلمة | الوصف |
|---|---|
| hierarchy_column_names | قائمة بأسماء الأعمدة في البيانات التي تحدد البنية الهرمية للبيانات. يحدد ترتيب الأعمدة في هذه القائمة مستويات التسلسل الهرمي؛ تقل درجة التجميع مع فهرس القائمة. أي أن العمود الأخير في القائمة يعرف مستوى الكائن الطرفي (الأكثر تصنيفا) للتسلسل الهرمي. |
| hierarchy_training_level | مستوى التسلسل الهرمي لاستخدامه في تدريب نموذج التنبؤ. |
يوضح ما يلي تكوين عينة:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
في الأمثلة اللاحقة، نفترض أن التكوين مخزن في المسار، ./automl_settings_hts.yml.
البنية الأساسية لبرنامج ربط العمليات التجارية ل HTS
بعد ذلك، نحدد وظيفة المصنع التي تنشئ مسارات لتنسيق تدريب HTS والاستدلال والحساب القياسي. معلمات دالة المصنع هذه مفصلة في الجدول التالي:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
الآن، نقوم بإنشاء البنية الأساسية لبرنامج ربط العمليات التجارية عبر وظيفة المصنع، بافتراض أن بيانات التدريب والاختبار موجودة في المجلدات المحلية، و./data/test، ./data/train على التوالي. وأخيرا، قمنا بتعيين الحساب الافتراضي وإرسال المهمة كما في العينة التالية:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
بعد انتهاء المهمة، يمكن تنزيل مقاييس التقييم محليا باستخدام نفس الإجراء كما هو الحال في مسار تشغيل التدريب الفردي.
راجع أيضا التنبؤ بالطلب مع دفتر ملاحظات التسلسل الزمني الهرمي للحصول على مثال أكثر تفصيلا.
إشعار
تقسم مكونات التدريب والاستدلال HTS بياناتك بشكل مشروط وفقا للإعداد hierarchy_column_names بحيث يكون كل قسم في ملفه الخاص. يمكن أن تكون هذه العملية بطيئة جدا أو تفشل عندما تكون البيانات كبيرة جدا. في هذه الحالة، نوصي بتقسيم بياناتك يدويا قبل تشغيل تدريب أو استدلال HTS.
التنبؤ على نطاق واسع: تدريب DNN موزع
- لمعرفة كيفية عمل التدريب الموزع لمهام التنبؤ، راجع مقالة التنبؤ على نطاق واسع.
- راجع قسم إعداد التدريب الموزع للبيانات الجدولية لعينات التعليمات البرمجية.
مثال دفاتر الملاحظات
راجع نماذج دفاتر الملاحظات للتنبؤ للحصول على أمثلة تعليمات برمجية مفصلة لتكوين التنبؤ المتقدم بما في ذلك:
- أمثلة على مسارات التنبؤ بالطلب
- نماذج التعلم العميق
- الكشف عن العطلات وتميازها
- التكوين اليدوي لميزات تجميع النوافذ المتدرجة والتأخر
الخطوات التالية
- تعرف على المزيد حول كيفية توزيع نموذج التعلم الآلي إلى نقطة نهاية عبر الإنترنت.
- تعرف على قابلية التفسير: تفسيرات النموذج في التعلم الآلي المؤتمت (إصدار أولي).
- تعرف على كيفية إنشاء AutoML لنماذج التنبؤ.
- تعرف على التنبؤ على نطاق واسع.
- تعرف على كيفية تكوين AutoML لسيناريوهات التنبؤ المختلفة.
- تعرف على استدلال وتقييم نماذج التنبؤ.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ