الأسئلة المتداولة حول التنبؤ في AutoML
ينطبق على: Python SDK azure-ai-ml v2 (الحالي)
Python SDK azure-ai-ml v2 (الحالي)
تجيب هذه المقالة على الأسئلة الشائعة حول التنبؤ في التعلم الآلي التلقائي (AutoML). للحصول على معلومات عامة حول منهجية التنبؤ في AutoML، راجع مقالة نظرة عامة على أساليب التنبؤ في AutoML .
كيف أعمل بدء إنشاء نماذج التنبؤ في AutoML؟
يمكنك البدء بقراءة مقالة إعداد AutoML لتدريب نموذج تنبؤ سلسلة زمنية. يمكنك أيضا العثور على أمثلة عملي في عدة دفاتر ملاحظات Jupyter:
- مثال على مشاركة الدراجة
- التنبؤ باستخدام التعلم العميق
- حل العديد من النماذج
- وصفات التنبؤ
- سيناريوهات التنبؤ المتقدمة
لماذا يكون AutoML بطيئا في بياناتي؟
نحن نعمل دائما على جعل AutoML أسرع وأكثر قابلية للتطوير. للعمل كمنصة تنبؤ عامة، يقوم AutoML بعمليات تحقق واسعة من صحة البيانات وهندسة الميزات المعقدة، ويبحث عن مساحة نموذج كبيرة. يمكن أن يتطلب هذا التعقيد الكثير من الوقت، اعتمادا على البيانات والتكوين.
أحد المصادر الشائعة لوقت التشغيل البطيء هو تدريب AutoML مع الإعدادات الافتراضية على البيانات التي تحتوي على العديد من السلاسل الزمنية. تتدرج تكلفة العديد من أساليب التنبؤ مع عدد السلاسل. على سبيل المثال، تدرب أساليب مثل التجانس الأسي والنبي نموذجا لكل سلسلة زمنية في بيانات التدريب.
تتدرج ميزة "العديد من النماذج" في AutoML إلى هذه السيناريوهات عن طريق توزيع مهام التدريب عبر مجموعة حساب. تم تطبيقه بنجاح على البيانات مع ملايين السلاسل الزمنية. لمزيد من المعلومات، راجع قسم مقالة العديد من النماذج . يمكنك أيضا قراءة نجاح العديد من النماذج على مجموعة بيانات منافسة رفيعة المستوى.
كيف يمكنني جعل AutoML أسرع؟
راجع لماذا يكون AutoML بطيئا في بياناتي؟ الإجابة لفهم سبب بطء AutoML في حالتك.
ضع في اعتبارك تغييرات التكوين التالية التي قد تؤدي إلى تسريع وظيفتك:
- حظر نماذج السلاسل الزمنية مثل ARIMA ونبي.
- قم بإيقاف تشغيل ميزات البحث عن الخلف مثل التأخر والنوافذ المتداولة.
- قلل:
- عدد الإصدارات التجريبية/التكرارات.
- مهلة الإصدار التجريبي/التكرار.
- مهلة التجربة.
- عدد الطيات عبر التحقق من الصحة.
- تأكد من تمكين الإنهاء المبكر.
ما هو تكوين النمذجة الذي يجب أن أستخدمه؟
يدعم التنبؤ ب AutoML أربعة تكوينات أساسية:
| التكوين | السيناريو | المزايا | العيوب |
|---|---|---|---|
| AutoML الافتراضي | يوصى به إذا كانت مجموعة البيانات تحتوي على عدد صغير من السلاسل الزمنية التي لها سلوك تاريخي مشابه تقريبا. | - بسيط للتكوين من التعليمات البرمجية/SDK أو Azure التعلم الآلي studio. - يمكن أن يتعلم AutoML عبر سلاسل زمنية مختلفة لأن نماذج الانحدار تجمع جميع السلاسل معا في التدريب. لمزيد من المعلومات، راجع تجميع النماذج. |
- قد تكون نماذج الانحدار أقل دقة إذا كانت السلسلة الزمنية في بيانات التدريب لها سلوك متباين. - قد تستغرق نماذج السلاسل الزمنية وقتا طويلا للتدريب إذا كانت بيانات التدريب تحتوي على عدد كبير من السلاسل. لمزيد من المعلومات، راجع الإجابة لماذا يكون AutoML بطيئا في بياناتي؟ |
| AutoML مع التعلم العميق | يوصى به لمجموعات البيانات التي تتضمن أكثر من 1000 ملاحظة، وربما العديد من السلاسل الزمنية التي تعرض أنماطا معقدة. عند تمكينه، سيقوم AutoML بمسح نماذج الشبكة العصبية الالتفافية الزمنية (TCN) أثناء التدريب. لمزيد من المعلومات، راجع تمكين التعلم العميق. | - بسيط للتكوين من التعليمات البرمجية/SDK أو Azure التعلم الآلي studio. - فرص التعلم المشترك، لأن TCN تجمع البيانات عبر جميع السلاسل. - من المحتمل أن تكون دقة أعلى بسبب القدرة الكبيرة لنماذج الشبكة العصبية العميقة (DNN). لمزيد من المعلومات، راجع نماذج التنبؤ في AutoML. |
- يمكن أن يستغرق التدريب وقتا أطول بكثير بسبب تعقيد نماذج DNN. - من غير المرجح أن تستفيد السلسلة ذات الكميات الصغيرة من التاريخ من هذه النماذج. |
| العديد من النماذج | يوصى به إذا كنت بحاجة إلى تدريب وإدارة عدد كبير من نماذج التنبؤ بطريقة قابلة للتطوير. لمزيد من المعلومات، راجع قسم مقالة العديد من النماذج . | -قابله. - من المحتمل أن تكون دقة أعلى عندما يكون للسلسلة الزمنية سلوك متباين عن بعضها البعض. |
- لا تعلم عبر السلاسل الزمنية. - لا يمكنك تكوين أو تشغيل العديد من وظائف النماذج من Azure التعلم الآلي studio. تتوفر حاليا تجربة التعليمات البرمجية/SDK فقط. |
| سلسلة زمنية هرمية (HTS) | يوصى به إذا كانت السلسلة في بياناتك تحتوي على بنية هرمية متداخلة، وتحتاج إلى تدريب التنبؤات أو إجراءها على مستويات مجمعة من التسلسل الهرمي. لمزيد من المعلومات، راجع قسم مقالة التنبؤ بالتسلسل الزمني الهرمي. | - يمكن أن يقلل التدريب على المستويات المجمعة من الضوضاء في السلسلة الزمنية للعقدة الطرفية ويحتمل أن يؤدي إلى نماذج عالية الدقة. - يمكنك استرداد التنبؤات لأي مستوى من التسلسل الهرمي عن طريق تجميع التنبؤات أو فصلها عن مستوى التدريب. |
- تحتاج إلى توفير مستوى التجميع للتدريب. لا يحتوي AutoML حاليا على خوارزمية للعثور على المستوى الأمثل. |
إشعار
نوصي باستخدام عقد الحوسبة مع وحدات معالجة الرسومات عند تمكين التعلم العميق للاستفادة على أفضل نحو من سعة DNN العالية. يمكن أن يكون وقت التدريب أسرع بكثير بالمقارنة مع العقد مع وحدات المعالجة المركزية فقط. لمزيد من المعلومات، راجع مقالة أحجام الجهاز الظاهري المحسنة لوحدة معالجة الرسومات .
إشعار
تم تصميم HTS للمهام التي يكون فيها التدريب أو التنبؤ مطلوبا على مستويات مجمعة في التسلسل الهرمي. بالنسبة للبيانات الهرمية التي تتطلب التدريب والتنبؤ بالعقدة الطرفية فقط، استخدم العديد من النماذج بدلا من ذلك.
كيف يمكنني منع المكواة الزائدة وتسرب البيانات؟
يستخدم AutoML أفضل ممارسات التعلم الآلي، مثل تحديد النموذج الذي تم التحقق من صحته عبره، والتي تخفف من العديد من مشكلات الإفراط في الاحتواء. ومع ذلك، هناك مصادر محتملة أخرى للإفراط في الاحتواء:
تحتوي بيانات الإدخال على أعمدة ميزات مشتقة من الهدف باستخدام صيغة بسيطة. على سبيل المثال، يمكن أن تؤدي الميزة التي هي مضاعف دقيق للهدف إلى درجة تدريب مثالية تقريبا. ومع ذلك، من المحتمل ألا يتم تعميم النموذج على البيانات خارج العينة. ننصحك باستكشاف البيانات قبل تدريب النموذج وإسقاط الأعمدة التي "تسرب" المعلومات الهدف.
تستخدم بيانات التدريب ميزات غير معروفة في المستقبل، حتى أفق التنبؤ. تفترض نماذج انحدار AutoML حاليا أن جميع الميزات معروفة لأفق التنبؤ. ننصحك باستكشاف بياناتك قبل التدريب وإزالة أي أعمدة ميزات معروفة تاريخيا فقط.
هناك اختلافات هيكلية كبيرة (تغييرات النظام) بين أجزاء التدريب أو التحقق من الصحة أو الاختبار من البيانات. على سبيل المثال، ضع في اعتبارك تأثير جائحة كوفيد-19 عند الطلب على أي خير تقريبا خلال عامي 2020 و2021. هذا مثال كلاسيكي لتغيير النظام. الإفراط في الاحتواء بسبب تغيير النظام هو المشكلة الأكثر تحديا التي يجب معالجتها لأنها تعتمد على السيناريو بدرجة كبيرة ويمكن أن تتطلب معرفة عميقة لتحديدها.
كخط دفاع أول، حاول حجز 10 إلى 20 بالمائة من إجمالي المحفوظات لبيانات التحقق من الصحة أو بيانات التحقق المشترك. لا يمكن دائما حجز هذا المقدار من بيانات التحقق من الصحة إذا كان سجل التدريب قصيرا، ولكنه من أفضل الممارسات. لمزيد من المعلومات، راجع بيانات التدريب والتحقق من الصحة.
ماذا يعني إذا كانت وظيفتي التدريبية تحقق درجات تحقق مثالية؟
من الممكن رؤية درجات مثالية عند عرض مقاييس التحقق من الصحة من وظيفة تدريبية. تعني النتيجة المثالية أن التنبؤ والعمل الفعلي في مجموعة التحقق من الصحة هي نفسها أو تقريبا نفسها. على سبيل المثال، لديك خطأ تربيعي متوسط الجذر يساوي 0.0 أو درجة R2 من 1.0.
تشير درجة التحقق المثالية عادة إلى أن النموذج مفرط في الاحتواء بشدة، على الأرجح بسبب تسرب البيانات. أفضل مسار للعمل هو فحص البيانات بحثا عن التسربات وإفلات الأعمدة التي تسبب التسرب.
ماذا لو لم تكن بيانات السلسلة الزمنية الخاصة بي تحتوي على ملاحظات متباعدة بانتظام؟
تتطلب نماذج التنبؤ الخاصة ب AutoML أن تقوم بيانات التدريب بتباعد الملاحظات بانتظام فيما يتعلق بالتقويم. ويشمل هذا المطلب حالات مثل الملاحظات الشهرية أو السنوية حيث يمكن أن يختلف عدد الأيام بين الملاحظات. قد لا تفي البيانات المعتمدة على الوقت بهذا المطلب في حالتين:
تحتوي البيانات على تكرار محدد جيدا، ولكن الملاحظات المفقودة تخلق فجوات في السلسلة. في هذه الحالة، سيحاول AutoML الكشف عن التكرار، وملء الملاحظات الجديدة للثغرات، وتسجيل قيم الهدف والميزات المفقودة. اختياريا، يمكن للمستخدم تكوين أساليب الإسناد عبر إعدادات SDK أو من خلال واجهة مستخدم الويب. لمزيد من المعلومات، راجع الميزات المخصصة.
لا تحتوي البيانات على تكرار محدد جيدا. أي أن المدة بين الملاحظات لا تحتوي على نمط مميز. بيانات المعاملات، مثل تلك من نظام نقطة المبيعات، هي أحد الأمثلة. في هذه الحالة، يمكنك تعيين AutoML لتجميع بياناتك إلى تكرار مختار. يمكنك اختيار التردد العادي الذي يناسب البيانات وأهداف النمذجة على أفضل نحو. لمزيد من المعلومات، راجع تجميع البيانات.
كيف أعمل اختيار المقياس الأساسي؟
المقياس الأساسي مهم لأن قيمته على بيانات التحقق من الصحة تحدد أفضل نموذج أثناء المسح والاختيار. عادة ما يكون متوسط الخطأ التربيعي للجذر العادي (NRMSE) والخطأ المطلق للمتوسط العادي (NMAE) أفضل الخيارات للمقياس الأساسي في مهام التنبؤ.
للاختيار بينهما، لاحظ أن NRMSE يعاقب القيم الخارجية في بيانات التدريب أكثر من NMAE لأنه يستخدم مربع الخطأ. قد يكون NMAE خيارا أفضل إذا كنت تريد أن يكون النموذج أقل حساسية لل القيم الخارجية. لمزيد من المعلومات، راجع مقاييس الانحدار والتنبؤ.
إشعار
لا نوصي باستخدام درجة R2 أو R2 كمقياس أساسي للتنبؤ.
إشعار
لا يدعم AutoML الوظائف المخصصة أو التي يوفرها المستخدم للمقياس الأساسي. يجب اختيار أحد المقاييس الأساسية المعرفة مسبقا التي يدعمها AutoML.
كيف يمكنني تحسين دقة النموذج الخاص بي؟
- تأكد من أنك تقوم بتكوين AutoML بأفضل طريقة لبياناتك. لمزيد من المعلومات، راجع الإجابة ما هو تكوين النمذجة الذي يجب استخدامه؟
- راجع دفتر ملاحظات وصفات التنبؤ للحصول على أدلة خطوة بخطوة حول كيفية إنشاء نماذج التنبؤ وتحسينها.
- تقييم النموذج باستخدام الاختبارات الخلفية عبر عدة دورات تنبؤ. يعطي هذا الإجراء تقديرا أكثر قوة لخطأ التنبؤ ويمنحك أساسا لقياس التحسينات مقابله. على سبيل المثال، راجع دفتر ملاحظات الاختبار الخلفي.
- إذا كانت البيانات صاخبة، ففكر في تجميعها إلى تردد خبيف لزيادة نسبة الإشارة إلى الضوضاء. لمزيد من المعلومات، راجع التكرار وتجميع البيانات الهدف.
- أضف ميزات جديدة يمكن أن تساعد في التنبؤ بالهدف. يمكن أن تساعد الخبرة في الموضوع بشكل كبير عند اختيار بيانات التدريب.
- قارن قيم المقاييس للتحقق من الصحة واختبارها، وحدد ما إذا كان النموذج المحدد أقل من احتواء البيانات أو يبالغ في تجهيزها. يمكن أن ترشدك هذه المعرفة إلى تكوين تدريب أفضل. على سبيل المثال، قد تحدد أنك بحاجة إلى استخدام المزيد من طيات التحقق من الصحة المتقاطعة استجابة للإفراط في الاحتواء.
هل سيحدد AutoML دائما نفس النموذج الأفضل من نفس بيانات التدريب والتكوين؟
عملية البحث عن نموذج AutoML ليست حتمية، لذلك لا تحدد دائما نفس النموذج من نفس البيانات والتكوين.
كيف أعمل إصلاح خطأ نفاد الذاكرة؟
هناك نوعان من أخطاء الذاكرة:
- ذاكرة الوصول العشوائي خارج الذاكرة
- نفاد ذاكرة القرص
أولا، تأكد من تكوين AutoML بأفضل طريقة لبياناتك. لمزيد من المعلومات، راجع الإجابة ما هو تكوين النمذجة الذي يجب استخدامه؟
بالنسبة لإعدادات AutoML الافتراضية، يمكنك إصلاح أخطاء ذاكرة الوصول العشوائي خارج الذاكرة باستخدام عقد الحوسبة مع المزيد من ذاكرة الوصول العشوائي. القاعدة العامة هي أن مقدار ذاكرة الوصول العشوائي المجانية يجب أن يكون أكبر 10 مرات على الأقل من حجم البيانات الأولية لتشغيل AutoML مع الإعدادات الافتراضية.
يمكنك حل أخطاء نفاد الذاكرة على القرص عن طريق حذف مجموعة الحوسبة وإنشاء مجموعة جديدة.
ما هي سيناريوهات التنبؤ المتقدمة التي يدعمها AutoML؟
يدعم AutoML سيناريوهات التنبؤ المتقدمة التالية:
- التنبؤات الكمية
- تقييم النموذج القوي عبر التنبؤات المتداولة
- التنبؤ خارج أفق التنبؤ
- التنبؤ عندما تكون هناك فجوة في الوقت بين فترات التدريب والتنبؤ
للحصول على أمثلة وتفاصيل، راجع دفتر الملاحظات للاطلاع على سيناريوهات التنبؤ المتقدمة.
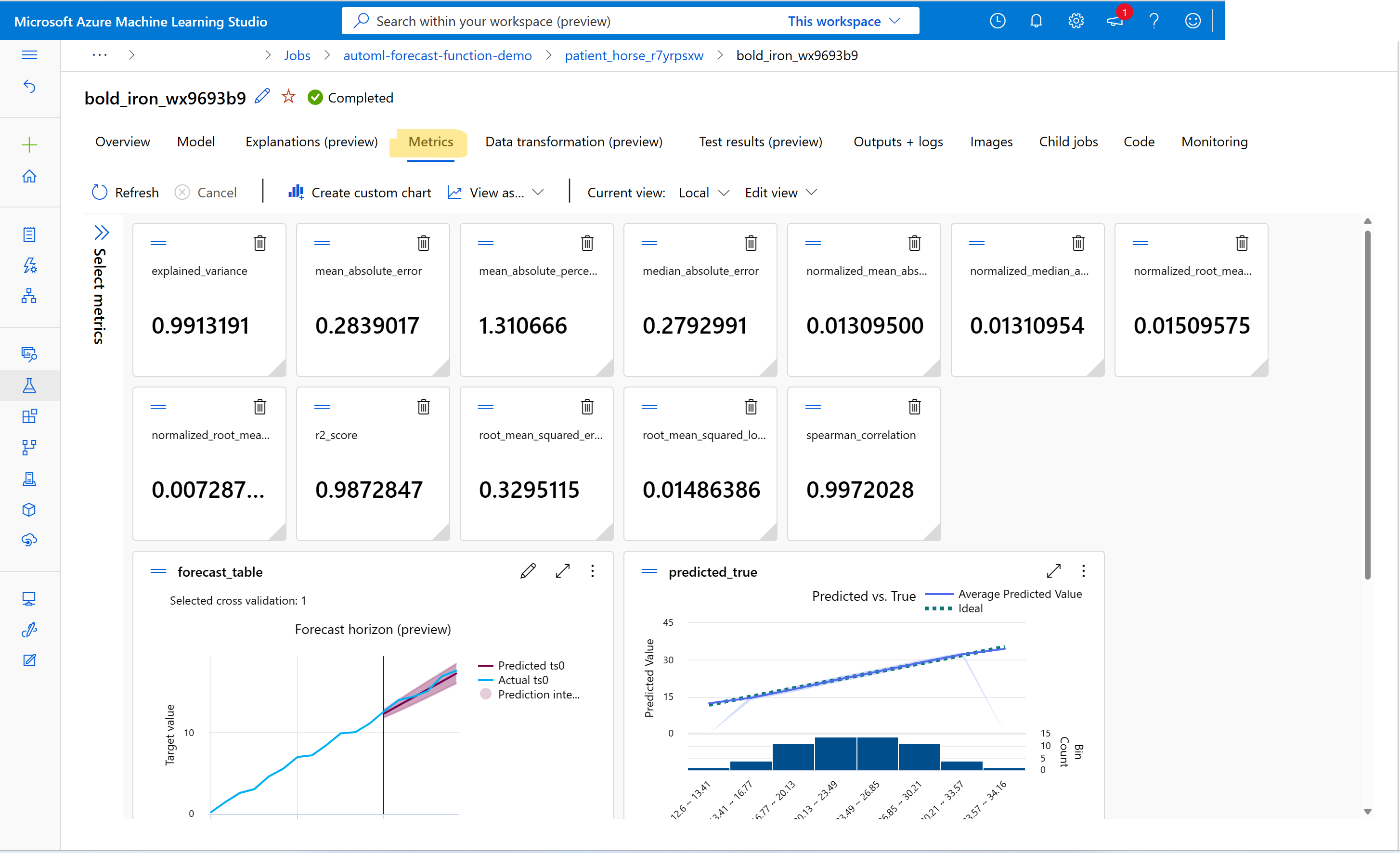
كيف أعمل عرض المقاييس من التنبؤ بمهام التدريب؟
للعثور على قيم قياس التدريب والتحقق من الصحة، راجع عرض معلومات حول الوظائف أو التشغيل في الاستوديو. يمكنك عرض مقاييس لأي نموذج تنبؤ تم تدريبه في AutoML بالانتقال إلى نموذج من واجهة مستخدم وظيفة AutoML في الاستوديو وتحديد علامة التبويب Metrics .
كيف أعمل حالات فشل تصحيح الأخطاء في التنبؤ بمهام التدريب؟
إذا فشلت مهمة التنبؤ ب AutoML، يمكن أن تساعدك رسالة خطأ على واجهة مستخدم الاستوديو في تشخيص المشكلة وإصلاحها. أفضل مصدر للمعلومات حول الفشل بعد رسالة الخطأ هو سجل برنامج التشغيل للوظيفة. للحصول على إرشادات حول العثور على سجلات برامج التشغيل، راجع عرض المهام/تشغيل المعلومات باستخدام MLflow.
إشعار
بالنسبة لوظيفة العديد من النماذج أو HTS، يكون التدريب عادة على مجموعات الحوسبة متعددة العقد. سجلات هذه الوظائف موجودة لكل عنوان IP عقدة. في هذه الحالة، تحتاج إلى البحث عن سجلات الأخطاء في كل عقدة. سجلات الخطأ، جنبا إلى جنب مع سجلات برنامج التشغيل، موجودة في المجلد user_logs لكل عنوان IP للعقدة.
كيف أعمل نشر نموذج من التنبؤ بوظائف التدريب؟
يمكنك نشر نموذج من التنبؤ بمهام التدريب بأي من الطرق التالية:
- نقطة النهاية عبر الإنترنت: تحقق من ملف تسجيل النقاط المستخدم في النشر، أو حدد علامة التبويب Test في صفحة نقطة النهاية في الاستوديو، لفهم بنية الإدخال التي يتوقعها التوزيع. راجع دفتر الملاحظات هذا للحصول على مثال. لمزيد من المعلومات حول النشر عبر الإنترنت، راجع نشر نموذج AutoML إلى نقطة نهاية عبر الإنترنت.
- نقطة نهاية الدفعة: يتطلب منك أسلوب النشر هذا تطوير برنامج نصي مخصص لتسجيل النقاط. راجع دفتر الملاحظات هذا للحصول على مثال. لمزيد من المعلومات حول نشر الدفعات، راجع استخدام نقاط نهاية الدفعة لتسجيل النقاط في الدفعات.
بالنسبة إلى عمليات نشر واجهة المستخدم، نشجعك على استخدام أي من هذين الخيارين:
- نقطة النهاية في الوقت الحقيقي
- نقطة نهاية الدفعة
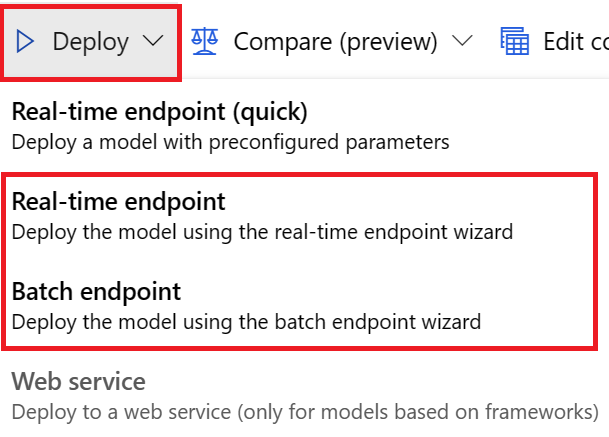
لا تستخدم الخيار الأول، نقطة النهاية في الوقت الحقيقي (سريع).
إشعار
اعتبارا من الآن، لا ندعم نشر نموذج MLflow من التنبؤ بمهام التدريب عبر SDK أو CLI أو واجهة المستخدم. ستتلقى أخطاء إذا حاولت ذلك.
ما هي مساحة العمل أو البيئة أو التجربة أو مثيل الحساب أو هدف الحساب؟
إذا لم تكن على دراية بمفاهيم Azure التعلم الآلي، فابدأ بمقالات ما هي Azure التعلم الآلي؟ وما هي مساحة عمل Azure التعلم الآلي؟
الخطوات التالية
- تعرف على المزيد حول كيفية إعداد AutoML لتدريب نموذج تنبؤ السلسلة الزمنية.
- تعرف على ميزات التقويم للتنبؤ بالسلاسل الزمنية في AutoML.
- تعرف على كيفية استخدام AutoML للتعلم الآلي لإنشاء نماذج التنبؤ.
- تعرف على توقعات AutoML للميزات المتخلفة.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ