Submit Spark jobs in Azure Machine Learning
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure Machine Learning supports standalone machine learning job submissions, and creation of machine learning pipelines that involve multiple machine learning workflow steps. Azure Machine Learning handles both standalone Spark job creation, and creation of reusable Spark components that Azure Machine Learning pipelines can use. In this article, you learn how to submit Spark jobs, with:
- Azure Machine Learning studio UI
- Azure Machine Learning CLI
- Azure Machine Learning SDK
For more information about Apache Spark in Azure Machine Learning concepts, visit this resource.
Prerequisites
APPLIES TO:
Azure CLI ml extension v2 (current)
- An Azure subscription; if you don't have an Azure subscription, create a free account before you begin.
- An Azure Machine Learning workspace. Visit Create workspace resources for more information.
- Create an Azure Machine Learning compute instance.
- Install the Azure Machine Learning CLI.
- (Optional): An attached Synapse Spark pool in the Azure Machine Learning workspace.
Note
- For more information about resource access while using Azure Machine Learning serverless Spark compute and attached Synapse Spark pool, visit Ensuring resource access for Spark jobs.
- Azure Machine Learning provides a shared quota pool, from which all users can access compute quota to perform testing for a limited time. When you use the serverless Spark compute, Azure Machine Learning allows you to access this shared quota for a short time.
Attach user assigned managed identity using CLI v2
- Create a YAML file that defines the user-assigned managed identity that should be attached to the workspace:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - With the
--fileparameter, use the YAML file in theaz ml workspace updatecommand to attach the user assigned managed identity:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Attach user assigned managed identity using ARMClient
- Install
ARMClient, a simple command line tool that invokes the Azure Resource Manager API. - Create a JSON file that defines the user-assigned managed identity that should be attached to the workspace:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - To attach the user-assigned managed identity to the workspace, execute the following command in the PowerShell prompt or the command prompt.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Note
- To ensure successful execution of the Spark job, assign the Contributor and Storage Blob Data Contributor roles, on the Azure storage account used for data input and output, to the identity that the Spark job uses
- Public Network Access should be enabled in Azure Synapse workspace to ensure successful execution of the Spark job using an attached Synapse Spark pool.
- In an Azure Synapse workspace that has a managed virtual network associated with it, if an attached Synapse Spark pool points to a Synapse Spark pool, you should configure a managed private endpoint to storage account, to ensure data access.
- Serverless Spark compute supports Azure Machine Learning managed virtual network. If a managed network is provisioned for the serverless Spark compute, the corresponding private endpoints for the storage account should also be provisioned to ensure data access.
Submit a standalone Spark job
After you make the necessary changes for Python script parameterization, you can use a Python script developed with interactive data wrangling to submit a batch job, to process a larger volume of data. You can submit a data wrangling batch job as a standalone Spark job.
A Spark job requires a Python script that takes arguments. You can modify the Python code originally developed from interactive data wrangling to develop that script. A sample Python script is shown here.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Note
This Python code sample uses pyspark.pandas. Only the Spark runtime version 3.2 or later supports this.
This script takes two arguments, which pass the path of input data and output folder, respectively:
--titanic_data--wrangled_data
APPLIES TO:
Azure CLI ml extension v2 (current)
To create a job, you can define a standalone Spark job as a YAML specification file, which you can use in the az ml job create command, with the --file parameter. Define these properties in the YAML file:
YAML properties in the Spark job specification
type- set tospark.code- defines the location of the folder that contains source code and scripts for this job.entry- defines the entry point for the job. It should cover one of these properties:file- defines the name of the Python script that serves as an entry point for the job.class_name- defines the name of the class that servers as an entry point for the job.
py_files- defines a list of.zip,.egg, or.pyfiles, to be placed in thePYTHONPATH, for successful execution of the job. This property is optional.jars- defines a list of.jarfiles to include on the Spark driver, and the executorCLASSPATH, for successful execution of the job. This property is optional.files- defines a list of files that should be copied to the working directory of each executor, for successful job execution. This property is optional.archives- defines a list of archives that should be extracted into the working directory of each executor, for successful job execution. This property is optional.conf- defines these Spark driver and executor properties:spark.driver.cores: the number of cores for the Spark driver.spark.driver.memory: allocated memory for the Spark driver, in gigabytes (GB).spark.executor.cores: the number of cores for the Spark executor.spark.executor.memory: the memory allocation for the Spark executor, in gigabytes (GB).spark.dynamicAllocation.enabled- whether or not executors should be dynamically allocated, as aTrueorFalsevalue.- If dynamic allocation of executors is enabled, define these properties:
spark.dynamicAllocation.minExecutors- the minimum number of Spark executors instances, for dynamic allocation.spark.dynamicAllocation.maxExecutors- the maximum number of Spark executors instances, for dynamic allocation.
- If dynamic allocation of executors is disabled, define this property:
spark.executor.instances- the number of Spark executor instances.
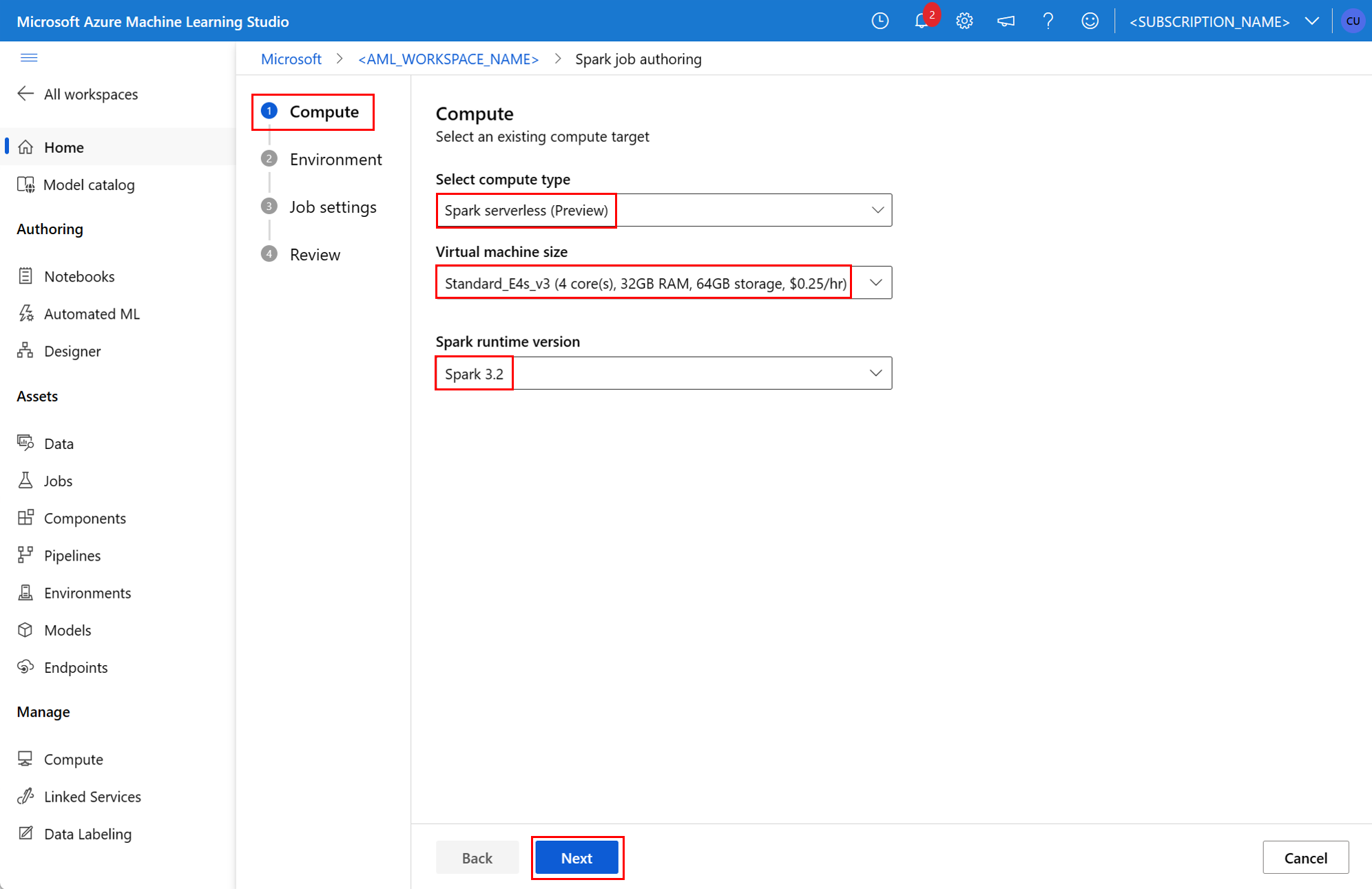
environment- an Azure Machine Learning environment to run the job.args- the command line arguments that should be passed to the job entry point Python script. Review the YAML specification file provided here for an example.resources- this property defines the resources to be used by an Azure Machine Learning serverless Spark compute. It uses the following properties:instance_type- the compute instance type to be used for Spark pool. The following instance types are currently supported:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- defines the Spark runtime version. The following Spark runtime versions are currently supported:3.33.4Important
Azure Synapse Runtime for Apache Spark: Announcements
- Azure Synapse Runtime for Apache Spark 3.3:
- EOLA Announcement Date: July 12, 2024
- End of Support Date: March 31, 2025. After this date, the runtime will be disabled.
- For continued support and optimal performance, we advise migrating to Apache Spark 3.4.
- Azure Synapse Runtime for Apache Spark 3.3:
This is an example YAML file:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- this property defines the name of an attached Synapse Spark pool, as shown in this example:compute: mysparkpoolinputs- this property defines inputs for the Spark job. Inputs for a Spark job can be either a literal value, or data stored in a file or folder.- A literal value can be a number, a boolean value, or a string. Some examples are shown here:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Data stored in a file or folder should be defined using these properties:
type- set this property touri_file, oruri_folder, for input data contained in a file or a folder respectively.path- the URI of the input data, such asazureml://,abfss://, orwasbs://.mode- set this property todirect. This sample shows the definition of a job input, which can be referred to as$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- A literal value can be a number, a boolean value, or a string. Some examples are shown here:
outputs- this property defines the Spark job outputs. Outputs for a Spark job can be written to either a file or a folder location, which is defined using the following three properties:type- you can set this property touri_fileoruri_folder, to write output data to a file or a folder respectively.path- this property defines the output location URI, such asazureml://,abfss://, orwasbs://.mode- set this property todirect. This sample shows the definition of a job output, which you can refer to as${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- this optional property defines the identity used to submit this job. It can haveuser_identityandmanagedvalues. If the YAML specification doesn't define an identity, the Spark job uses the default identity.
Standalone Spark job
This example YAML specification shows a standalone Spark job. It uses an Azure Machine Learning serverless Spark compute:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Note
To use an attached Synapse Spark pool, define the compute property in the sample YAML specification file shown earlier, instead of the resources property.
You can use the YAML files shown earlier in the az ml job create command, with the --file parameter, to create a standalone Spark job as shown:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
You can execute the above command from:
- terminal of an Azure Machine Learning compute instance.
- a Visual Studio Code terminal, connected to an Azure Machine Learning compute instance.
- your local computer that has Azure Machine Learning CLI installed.
Spark component in a pipeline job
A Spark component offers the flexibility to use the same component in multiple Azure Machine Learning pipelines, as a pipeline step.
APPLIES TO:
Azure CLI ml extension v2 (current)
The YAML syntax for a Spark component resembles the YAML syntax for Spark job specification in most ways. These properties are defined differently in the Spark component YAML specification:
name- the name of the Spark component.version- the version of the Spark component.display_name- the name of the Spark component to display in the UI and elsewhere.description- the description of the Spark component.inputs- this property resembles theinputsproperty described in YAML syntax for Spark job specification, except that it doesn't define thepathproperty. This code snippet shows an example of the Spark componentinputsproperty:inputs: titanic_data: type: uri_file mode: directoutputs- this property resembles theoutputsproperty described in YAML syntax for Spark job specification, except that it doesn't define thepathproperty. This code snippet shows an example of the Spark componentoutputsproperty:outputs: wrangled_data: type: uri_folder mode: direct
Note
A Spark component does not define the identity, compute or resources properties. The pipeline YAML specification file defines these properties.
This YAML specification file provides an example of a Spark component:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
You can use The Spark component defined in the above YAML specification file in an Azure Machine Learning pipeline job. Visit the pipeline job YAML schema resource to learn more about the YAML syntax that defines a pipeline job. This example shows a YAML specification file for a pipeline job, with a Spark component, and an Azure Machine Learning serverless Spark compute:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Note
To use an attached Synapse Spark pool, define the compute property in the sample YAML specification file shown above, instead of resources property.
You can use the YAML specification file seen above in the az ml job create command, using the --file parameter, to create a pipeline job as shown:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
You can execute the above command from:
- the terminal of an Azure Machine Learning compute instance.
- the terminal of Visual Studio Code connected to an Azure Machine Learning compute instance.
- your local computer that has Azure Machine Learning CLI installed.
Troubleshooting Spark jobs
To troubleshoot a Spark job, you can access the logs generated for that job in Azure Machine Learning studio. To view the logs for a Spark job:
- Navigate to Jobs from the left panel in the Azure Machine Learning studio UI
- Select the All jobs tab
- Select the Display name value for the job
- On the job details page, select the Output + logs tab
- In the file explorer, expand the logs folder, and then expand the azureml folder
- Access the Spark job logs inside the driver and library manager folders
Note
To troubleshoot Spark jobs created during interactive data wrangling in a notebook session, select Job details near the top right corner of the notebook UI. A Spark jobs from an interactive notebook session is created under the experiment name notebook-runs.