تبادل البيانات التفاعلية مع Apache Spark في Azure التعلم الآلي
يصبح تشابك البيانات إحدى أهم الخطوات في مشاريع التعلم الآلي. يوفر تكامل Azure التعلم الآلي، مع Azure Synapse Analytics، الوصول إلى تجمع Apache Spark - مدعوم من Azure Synapse - لتشابك البيانات التفاعلية باستخدام دفاتر ملاحظات Azure التعلم الآلي.
في هذه المقالة، ستتعلم كيفية إجراء تشابك البيانات باستخدام
- حساب Spark بلا خادم
- تجمع Synapse Spark المرفق
المتطلبات الأساسية
- اشتراك Azure؛ إذا لم يكن لديك اشتراك Azure، فبادر بإنشاء حساب مجاني قبل البدء.
- مساحة عمل للتعلم الآلي من Microsoft Azure. راجع إنشاء موارد مساحة العمل.
- حساب تخزين Azure Data Lake Storage (ADLS) Gen 2. راجع إنشاء حساب تخزين Azure Data Lake Storage (ADLS) Gen 2.
- (اختياري): Azure Key Vault. راجع إنشاء Azure Key Vault.
- (اختياري): كيان الخدمة. راجع إنشاء كيان خدمة.
- (اختياري): تجمع Synapse Spark مرفق في مساحة عمل Azure التعلم الآلي.
قبل بدء مهام تشابك البيانات، تعرف على عملية تخزين البيانات السرية
- مفتاح الوصول إلى حساب تخزين Azure Blob
- الرمز المميز لتوقيع الوصول المشترك (SAS)
- معلومات كيان خدمة Azure Data Lake Storage (ADLS) Gen 2
في Azure Key Vault. تحتاج أيضا إلى معرفة كيفية التعامل مع تعيينات الأدوار في حسابات تخزين Azure. تستعرض الأقسام التالية هذه المفاهيم. بعد ذلك، سنستكشف تفاصيل تشابك البيانات التفاعلية باستخدام تجمعات Spark في Azure التعلم الآلي Notebooks.
تلميح
للتعرف على تكوين تعيين دور حساب تخزين Azure، أو إذا قمت بالوصول إلى البيانات في حسابات التخزين الخاصة بك باستخدام مرور هوية المستخدم، راجع إضافة تعيينات الأدوار في حسابات تخزين Azure.
تبادل البيانات التفاعلية مع Apache Spark
يوفر Azure التعلم الآلي حساب Spark بلا خادم، وتجمع Synapse Spark المرفق، لتشابك البيانات التفاعلية مع Apache Spark في دفاتر ملاحظات Azure التعلم الآلي. لا يتطلب حساب Spark بلا خادم إنشاء موارد في مساحة عمل Azure Synapse. بدلا من ذلك، تصبح حوسبة Spark بدون خادم مدارة بالكامل متاحة مباشرة في دفاتر ملاحظات Azure التعلم الآلي. يعد استخدام حساب Spark بلا خادم هو أسهل نهج للوصول إلى مجموعة Spark في Azure التعلم الآلي.
حساب Spark بلا خادم في دفاتر ملاحظات Azure التعلم الآلي
يتوفر حساب Spark بلا خادم في دفاتر ملاحظات Azure التعلم الآلي بشكل افتراضي. للوصول إليه في دفتر ملاحظات، حدد Serverless Spark Compute ضمن Azure التعلم الآلي Serverless Spark من قائمة تحديد الحساب.
توفر واجهة مستخدم دفاتر الملاحظات أيضا خيارات لتكوين جلسة Spark، لحساب Spark بلا خادم. لتكوين جلسة Spark:
- حدد تكوين جلسة العمل في أعلى الشاشة.
- حدد إصدار Apache Spark من القائمة المنسدلة.
هام
وقت تشغيل Azure Synapse ل Apache Spark: الإعلانات
- وقت تشغيل Azure Synapse ل Apache Spark 3.2:
- تاريخ إعلان EOLA: 8 يوليو 2023
- تاريخ انتهاء الدعم: 8 يوليو 2024. بعد هذا التاريخ، سيتم تعطيل وقت التشغيل.
- للحصول على الدعم المستمر والأداء الأمثل، ننصحك بالترحيل إلى Apache Spark 3.3.
- وقت تشغيل Azure Synapse ل Apache Spark 3.2:
- حدد نوع المثيل من القائمة المنسدلة. أنواع المثيلات التالية مدعومة حاليا:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- أدخل قيمة مهلة جلسة Spark، بالدقائق.
- حدد ما إذا كنت تريد تخصيص المنفذين ديناميكيا
- حدد عدد المنفذين لجلسة Spark.
- حدد حجم المنفذ من القائمة المنسدلة.
- حدد حجم برنامج التشغيل من القائمة المنسدلة.
- لاستخدام ملف Conda لتكوين جلسة Spark، حدد خانة الاختيار Upload conda file . ثم حدد استعراض، واختر ملف Conda مع تكوين جلسة Spark الذي تريده.
- أضف خصائص إعدادات التكوين، وقيم الإدخال في مربعي النص الخاصية والقيمة، وحدد إضافة.
- حدد تطبيق.
- حدد إيقاف الجلسة في النافذة المنبثقة تكوين جلسة عمل جديدة؟
تستمر تغييرات تكوين جلسة العمل وتصبح متاحة لجلسة دفتر ملاحظات أخرى بدأت باستخدام حساب Spark بلا خادم.
تلميح
إذا كنت تستخدم حزم Conda على مستوى جلسة العمل، يمكنك تحسين وقت البدء البارد لجلسة Spark إذا قمت بتعيين متغير spark.hadoop.aml.enable_cache التكوين إلى true. تبدأ جلسة العمل الباردة بحزم Conda على مستوى الجلسة عادة من 10 إلى 15 دقيقة عند بدء الجلسة لأول مرة. ومع ذلك، تبدأ جلسة العمل الباردة اللاحقة مع تعيين متغير التكوين إلى true عادة ما يستغرق من ثلاث إلى خمس دقائق.
استيراد البيانات وتشابكها من Azure Data Lake Storage (ADLS) Gen 2
يمكنك الوصول إلى البيانات المخزنة في حسابات تخزين Azure Data Lake Storage (ADLS) Gen 2 وتشابكها باستخدام abfss:// معرفات URI للبيانات باتباع إحدى آليتي الوصول إلى البيانات:
- مرور هوية المستخدم
- الوصول إلى البيانات المستندة إلى أساس الخدمة
تلميح
يتطلب تشابك البيانات مع حساب Spark بلا خادم، ومرور هوية المستخدم للوصول إلى البيانات في حساب تخزين Azure Data Lake Storage (ADLS) Gen 2، أصغر عدد من خطوات التكوين.
لبدء تشابك البيانات التفاعلية مع مرور هوية المستخدم:
تحقق من أن هوية المستخدم لديها تعيينات دور المساهم ومساهم بيانات Blob التخزين في حساب تخزين Azure Data Lake Storage (ADLS) Gen 2.
لاستخدام حساب Spark بلا خادم، حدد Serverless Spark Compute ضمن Azure التعلم الآلي Serverless Spark من قائمة تحديد الحساب.
لاستخدام تجمع Synapse Spark مرفق، حدد تجمع Synapse Spark مرفقا ضمن تجمعات Synapse Spark من قائمة تحديد الحساب .
يظهر نموذج التعليمات البرمجية لتشابك بيانات Titanic هذا استخدام URI للبيانات بالتنسيق
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>معpyspark.pandasوpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )إشعار
يستخدم
pyspark.pandasنموذج التعليمات البرمجية Python هذا . يدعم هذا فقط الإصدار 3.2 من وقت تشغيل Spark أو أحدث.
لتشابك البيانات عن طريق الوصول من خلال كيان الخدمة:
تحقق من أن كيان الخدمة لديه تعيينات دور المساهم وStorage Blob Data Contributorفي حساب تخزين Azure Data Lake Storage (ADLS) Gen 2.
إنشاء أسرار Azure Key Vault لمعرف المستأجر الأساسي للخدمة ومعرف العميل وقيم سر العميل.
حدد حساب Spark بلا خادم ضمن Azure التعلم الآلي Serverless Spark من قائمة تحديد الحساب، أو حدد تجمع Synapse Spark مرفقا ضمن تجمعات Synapse Spark من قائمة تحديد الحساب.
لتعيين معرف المستأجر الأساسي للخدمة، ومعرف العميل وسر العميل في التكوين، وتنفيذ نموذج التعليمات البرمجية التالي.
get_secret()يعتمد الاستدعاء في التعليمات البرمجية على اسم Azure Key Vault وأسماء أسرار Azure Key Vault التي تم إنشاؤها لمعرف المستأجر الأساسي للخدمة ومعرف العميل وسر العميل. قم بتعيين اسم/قيم الخاصية المقابلة هذه في التكوين:- خاصية معرف العميل:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - خاصية سر العميل:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - خاصية معرف المستأجر:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - قيمة معرف المستأجر:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- خاصية معرف العميل:
استيراد البيانات وتشابكها باستخدام URI للبيانات بتنسيق
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>كما هو موضح في نموذج التعليمات البرمجية، باستخدام بيانات Titanic.
استيراد البيانات وتشابكها من تخزين Azure Blob
يمكنك الوصول إلى بيانات تخزين Azure Blob إما باستخدام مفتاح الوصول إلى حساب التخزين أو رمز توقيع الوصول المشترك (SAS). يجب تخزين بيانات الاعتماد هذه في Azure Key Vault كبيانات سرية، وتعيينها كخصائص في تكوين الجلسة.
لبدء تشابك البيانات التفاعلية:
في لوحة Azure التعلم الآلي studio اليسرى، حدد Notebooks.
حدد حساب Spark بلا خادم ضمن Azure التعلم الآلي Serverless Spark من قائمة تحديد الحساب، أو حدد تجمع Synapse Spark مرفقا ضمن تجمعات Synapse Spark من قائمة تحديد الحساب.
لتكوين مفتاح الوصول إلى حساب التخزين أو رمز توقيع الوصول المشترك (SAS) للوصول إلى البيانات في Azure التعلم الآلي Notebooks:
بالنسبة لمفتاح الوصول، قم بتعيين الخاصية
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netكما هو موضح في مقتطف التعليمات البرمجية هذا:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )بالنسبة إلى رمز SAS المميز، قم بتعيين الخاصية
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netكما هو موضح في مقتطف التعليمات البرمجية هذا:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )إشعار
get_secret()تتطلب المكالمات في قصاصات التعليمات البرمجية أعلاه اسم Azure Key Vault، وأسماء الأسرار التي تم إنشاؤها لمفتاح الوصول إلى حساب تخزين Azure Blob أو رمز SAS المميز
تنفيذ التعليمات البرمجية لتشابك البيانات في نفس دفتر الملاحظات. قم بتنسيق URI للبيانات ك
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>، على غرار ما يظهره مقتطف التعليمات البرمجية هذا:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )إشعار
يستخدم
pyspark.pandasنموذج التعليمات البرمجية Python هذا . يدعم هذا فقط الإصدار 3.2 من وقت تشغيل Spark أو أحدث.
استيراد البيانات وتشابكها من Azure التعلم الآلي Datastore
للوصول إلى البيانات من Azure التعلم الآلي Datastore، حدد مسارا إلى البيانات على مخزن البيانات بتنسيقazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA> URI. لتشابك البيانات من Azure التعلم الآلي Datastore في جلسة عمل دفاتر الملاحظات بشكل تفاعلي:
حدد حساب Spark بلا خادم ضمن Azure التعلم الآلي Serverless Spark من قائمة تحديد الحساب، أو حدد تجمع Synapse Spark مرفقا ضمن تجمعات Synapse Spark من قائمة تحديد الحساب.
يوضح نموذج التعليمات البرمجية هذا كيفية قراءة بيانات Titanic وتشابكها من Azure التعلم الآلي Datastore، باستخدام
azureml://URI لمخزن البيانات،pyspark.pandasوpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )إشعار
يستخدم
pyspark.pandasنموذج التعليمات البرمجية Python هذا . يدعم هذا فقط الإصدار 3.2 من وقت تشغيل Spark أو أحدث.
يمكن لمخازن بيانات Azure التعلم الآلي الوصول إلى البيانات باستخدام بيانات اعتماد حساب تخزين Azure
- مفتاح الوصول
- رمز SAS المميز
- أساس الخدمة
أو توفير وصول بيانات بدون بيانات اعتماد. اعتمادا على نوع مخزن البيانات ونوع حساب تخزين Azure الأساسي، حدد آلية مصادقة مناسبة لضمان الوصول إلى البيانات. يلخص هذا الجدول آليات المصادقة للوصول إلى البيانات في مخازن البيانات التعلم الآلي Azure:
| نوع حساب التخزين | الوصول إلى البيانات بدون بيانات اعتماد | آلية الوصول إلى البيانات | تعيينات الأدوار |
|---|---|---|---|
| Azure Blob | لا | مفتاح الوصول أو رمز SAS المميز | لا توجد حاجة لتعيينات الأدوار |
| Azure Blob | نعم | مرور هوية المستخدم* | يجب أن يكون لهوية المستخدم تعيينات دور مناسبة في حساب تخزين Azure Blob |
| Azure Data Lake Storage (ADLS) Gen 2 | لا | كيان الخدمة | يجب أن يكون لمدير الخدمة تعيينات دور مناسبة في حساب تخزين Azure Data Lake Storage (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen 2 | نعم | مرور هوية المستخدم | يجب أن يكون لهوية المستخدم تعيينات دور مناسبة في حساب تخزين Azure Data Lake Storage (ADLS) Gen 2 |
* يعمل مرور هوية المستخدم لمخازن البيانات الأقل بيانات الاعتماد التي تشير إلى حسابات تخزين Azure Blob، فقط إذا لم يتم تمكين الحذف المبدئي.
الوصول إلى البيانات على مشاركة الملف الافتراضية
يتم تحميل مشاركة الملف الافتراضية على كل من حساب Spark بلا خادم وتجمعات Synapse Spark المرفقة.
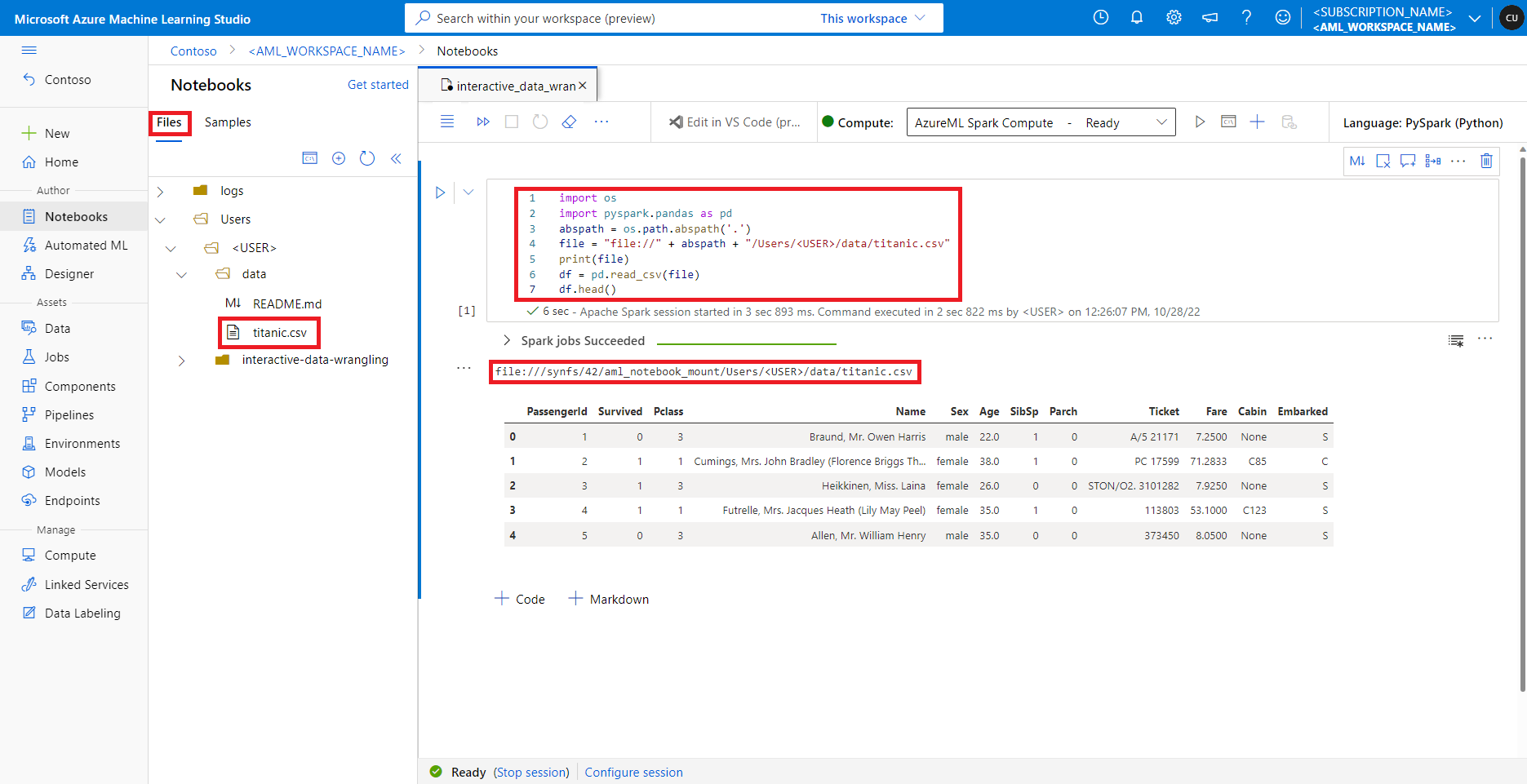
في Azure التعلم الآلي studio، يتم عرض الملفات الموجودة في مشاركة الملف الافتراضية في شجرة الدليل ضمن علامة التبويب ملفات. يمكن للتعليمات البرمجية لدفتر الملاحظات الوصول مباشرة إلى الملفات المخزنة في مشاركة الملف هذه مع file:// البروتوكول، إلى جانب المسار المطلق للملف، دون مزيد من التكوينات. توضح هذه القصاصة البرمجية كيفية الوصول إلى ملف مخزن على مشاركة الملف الافتراضية:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
إشعار
يستخدم pyspark.pandasنموذج التعليمات البرمجية Python هذا . يدعم هذا فقط الإصدار 3.2 من وقت تشغيل Spark أو أحدث.