إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Note
مخازن المعرفة هي تخزين ثانوي موجود في Azure Storage وتحتوي على مخرجات مهارات البحث الذكاء الاصطناعي في Azure. هي منفصلة عن مصادر المعرفة وقواعد المعرفة التي تستخدم في سير عمل الاسترجاع الوكالتي .
مخزن المعرفة هو تخزين ثانوي للمحتوى الذكاء الاصطناعي الإثراء الذي تم إنشاؤه بواسطة مجموعة مهارات في Azure الذكاء الاصطناعي Search. في Azure الذكاء الاصطناعي Search، ترسل مهمة الفهرسة دائما الإخراج إلى فهرس بحث، ولكن إذا قمت بإرفاق مجموعة مهارات بمفهرس، يمكنك اختياريا أيضا إرسال الإخراج الذكاء الاصطناعي الإثراء إلى حاوية أو جدول في Azure Storage. يمكن استخدام مخزن المعرفة للتحليل المستقل أو معالجة انتقال البيانات من الخادم في سيناريوهات غير بحث مثل التنقيب المعرفي.
الإخراجان للفهرسة، فهرس البحث ومخزن المعرفة، هما منتجان حصريان للبنية الأساسية لبرنامج ربط العمليات التجارية نفسه. وهي مشتقة من نفس المدخلات وتحتوي على نفس البيانات، ولكن يتم تنظيم محتواها وتخزينها واستخدامها في تطبيقات مختلفة.

فعليا، مخزن المعرفة هو Azure Storage، إما Azure Table Storage، أو Azure Blob Storage، أو كليهما. يمكن لأي أداة أو عملية يمكنها الاتصال ب Azure Storage أن تستهلك محتويات مخزن المعرفة. لا يوجد دعم استعلام في Azure الذكاء الاصطناعي Search لاسترداد المحتوى من مخزن المعارف.
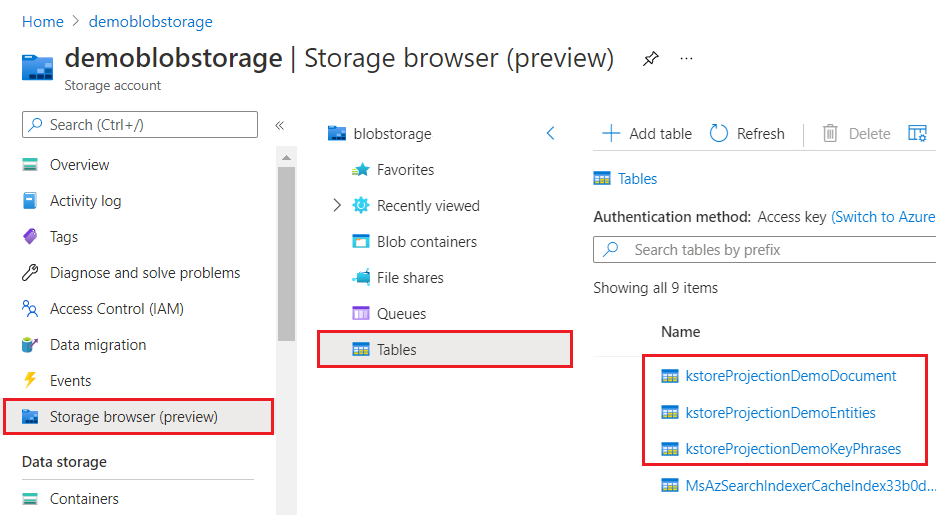
عند عرضه من خلال مدخل Microsoft Azure، يبدو مخزن المعرفة مثل أي مجموعة أخرى من الجداول أو الكائنات أو الملفات. تظهر لقطة الشاشة التالية مخزن معارف يتكون من ثلاثة جداول. يمكنك اعتماد اصطلاح تسمية، مثل kstore البادئة، للحفاظ على المحتوى الخاص بك معا.
فوائد مخزن المعرفة
تتمثل الفوائد الأساسية لمخزن المعرفة في ضعفين: الوصول المرن إلى المحتوى، والقدرة على تشكيل البيانات.
على عكس فهرس البحث الذي يمكن الوصول إليه فقط من خلال الاستعلامات في Azure الذكاء الاصطناعي Search، يمكن لأي أداة أو تطبيق أو عملية تدعم الاتصالات ب Azure Storage الوصول إلى مخزن المعلومات. تفتح هذه المرونة سيناريوهات جديدة لاستهلاك المحتوى الذي تم تحليله وإثراءه الذي تنتجه البنية الأساسية لبرنامج ربط العمليات التجارية للإثراء.
يمكن أيضا استخدام نفس مجموعة المهارات التي تثري البيانات لتشكيل البيانات. تعمل بعض الأدوات مثل Power BI بشكل أفضل مع الجداول، بينما قد يتطلب حمل عمل علم البيانات بنية بيانات معقدة بتنسيق كائن ثنائي كبير الحجم. تمنحك إضافة مهارة Shaper إلى مجموعة مهارات التحكم في شكل بياناتك. يمكنك بعد ذلك تمرير هذه الأشكال إلى الإسقاطات، إما الجداول أو الكائنات الثنائية كبيرة الحجم، لإنشاء بنيات بيانات فعلية تتوافق مع الاستخدام المقصود للبيانات.
يشرح الفيديو التالي كل من هذه الفوائد وأكثر من ذلك.
تعريف مخزن المعرفة
يتم تعريف مخزن المعرفة داخل تعريف مجموعة المهارات ويحتوي على مكونين:
سلسلة الاتصال إلى Azure Storage
الإسقاطات التي تحدد ما إذا كان مخزن المعرفة يتكون من جداول أو عناصر أو ملفات. عنصر الإسقاطات هو صفيف. يمكنك إنشاء مجموعات متعددة من مجموعات ملفات كائن الجدول داخل مخزن معارف واحد.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
يحدد نوع الإسقاط الذي تحدده في هذه البنية نوع التخزين المستخدم من قبل مخزن المعارف، ولكن ليس بنيته. الحقول في الجداول والكائنات والملفات يتم تحديدها بواسطة مخرجات مهارات Shaper إذا كنت تنشئ مخزن المعرفة بشكل برمجي، أو بواسطة معالج استيراد البيانات إذا كنت تستخدم بوابة Azure.
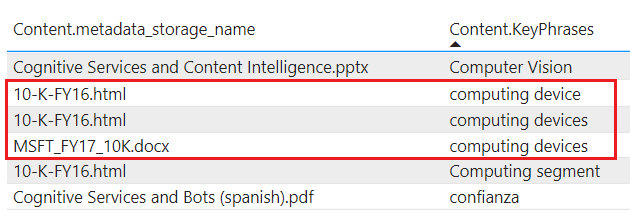
tablesمحتوى المشروع الذي تم إثرائه في Table Storage. حدد إسقاط الجدول عندما تحتاج إلى بنيات تقارير جدولية للمدخلات إلى الأدوات التحليلية أو التصدير كإطارات بيانات إلى مخازن البيانات الأخرى. يمكنك تحديد متعددtablesداخل نفس مجموعة الإسقاط للحصول على مجموعة فرعية أو مقطع عرضي من المستندات التي تم إثراؤها. ضمن نفس مجموعة الإسقاط، يتم الاحتفاظ بعلاقات الجدول بحيث يمكنك العمل معها جميعا.لا يتم تجميع المحتوى المتوقع أو تسويته. تعرض لقطة الشاشة التالية جدولا تم فرزه حسب العبارة الرئيسية، مع الإشارة إلى المستند الأصل في العمود المجاور. على النقيض من استيعاب البيانات أثناء الفهرسة، لا يوجد تحليل لغوي أو تجميع للمحتوى. تعتبر أشكال الجمع والاختلافات في الغلاف مثيلات فريدة.
objectsمستند JSON للمشروع في تخزين Blob. التمثيل المادي لobjectهو بنية JSON هرمية تمثل مستندا غنيا.filesملفات صور المشروع في تخزين Blob. هيfileصورة مستخرجة من مستند، يتم نقلها سليمة إلى تخزين Blob. على الرغم من أنه يسمى "ملفات"، إلا أنه يظهر في Blob Storage، وليس تخزين الملفات.
إنشاء مخزناً للمعارف
استخدم بوابة Azure، أو واجهات برمجة التطبيقات REST، أو حزمة Azure SDK لإنشاء مخزن معرفة. جميع الطرق تتطلب Azure Storage، ومجموعة مهارات، وفهرس. نظرا لأن الفهرسات تتطلب فهرس بحث، يجب عليك أيضا تقديم تعريف للفهرس.
توفر واجهات برمجة التطبيقات وSDKs من REST تحكما كاملا في الإسقاطات: الجداول، الكائنات، والملفات. ينشئ بوابة Azure مخزن معرفة تلقائيا كجزء من سير عمل RAG متعدد الوسائط، والذي يقتصر على إسقاط الملفات للصور المستخرجة.
يقوم معالج استيراد البيانات بإنشاء مخزن معرفة فقط لسيناريو RAG متعدد الوسائط. للبدء، راجع Quickstart: البحث متعدد الوسائط في بوابة Azure.
الاتصال بالتطب التطبيقات
بمجرد وجود محتوى تم إثرائه في التخزين، يمكن استخدام أي أداة أو تقنية تتصل ب Azure Storage لاستكشاف المحتويات أو تحليلها أو استهلاكها. القائمة التالية هي بداية:
مستكشف التخزين أو مستعرض التخزين في مدخل Microsoft Azure لعرض بنية المستند المثري والمحتوى. ضع في اعتبارك هذا كأداة أساسية لعرض محتويات مخزن المعرفة.
Power BI لإعداد التقارير والتحليل.
Azure Data Factory لمزيد من المعالجة.
دورة حياة المحتوى
في كل مرة تقوم فيها بتشغيل المفهرس ومجموعة المهارات، يتم تحديث مخزن المعرفة إذا تغيرت مجموعة المهارات أو بيانات المصدر الأساسية. يتم نشر أي تغييرات يتم التقاطها بواسطة المفهرس من خلال عملية الإثراء إلى الإسقاطات في مخزن المعلومات، ما يضمن أن البيانات المتوقعة هي تمثيل حالي للمحتوى في مصدر البيانات الأصلي.
Note
بينما يمكنك تحرير البيانات في الإسقاطات، سيتم الكتابة فوق أي عمليات تحرير على استدعاء المسار التالي، على افتراض تحديث المستند في بيانات المصدر.
التغييرات في بيانات المصدر
بالنسبة لمصادر البيانات التي تدعم تعقب التغييرات، سيقوم المفهرس بمعالجة المستندات الجديدة والمتغيرة، وتجاوز المستندات الموجودة التي تمت معالجتها بالفعل. تختلف معلومات الطابع الزمني حسب مصدر البيانات، ولكن في حاوية كائن ثنائي كبير الحجم، يبحث المفهرس في lastmodified التاريخ لتحديد الكائنات الثنائية كبيرة الحجم التي يجب استيعابها.
التغييرات في مجموعة المهارات
إذا كنت تقوم بإجراء تغييرات على مجموعة المهارات، يجب تمكين التخزين المؤقت للمستندات التي تم إثراؤها لإعادة استخدام عمليات الإثراء الموجودة حيثما أمكن ذلك.
بدون التخزين المؤقت التزايدي، سيقوم المفهرس دائما بمعالجة المستندات بترتيب علامة المياه العالية، دون الرجوع إلى الخلف. بالنسبة للكائنات الثنائية كبيرة الحجم، سيقوم المفهرس بمعالجة الكائنات الثنائية كبيرة الحجم التي تم فرزها حسب lastModified، بغض النظر عن أي تغييرات على إعدادات المفهرس أو مجموعة المهارات. إذا قمت بتغيير مجموعة مهارات، فلن يتم تحديث المستندات التي تمت معالجتها مسبقا لتعكس مجموعة المهارات الجديدة. ستستخدم المستندات التي تمت معالجتها بعد تغيير مجموعة المهارات مجموعة المهارات الجديدة، مما يؤدي إلى أن تكون مستندات الفهرس مزيجا من مجموعات المهارات القديمة والجديدة.
مع التخزين المؤقت التزايدي، وبعد تحديث مجموعة المهارات، سيعيد المفهرس استخدام أي إثراء لا يتأثر بتغيير مجموعة المهارات. يتم سحب عمليات الإثراء الأولية من ذاكرة التخزين المؤقت، وكذلك أي عمليات إثراء مستقلة ومعزولة عن المهارة التي تم تغييرها.
Deletions
على الرغم من أن المفهرس يقوم بإنشاء وتحديث البنيات والمحتوى في Azure Storage، فإنه لا يحذفها. تستمر الإسقاطات في الوجود حتى عند حذف المفهرس أو مجموعة المهارات. بصفتك مالك حساب التخزين، يجب حذف إسقاط إذا لم تعد هناك حاجة إليه.
الخطوات التالية
يوفر مخزن المعرفة استمرار المستندات التي تم إثراؤها، وهي مفيدة عند تصميم مجموعة مهارات، أو إنشاء بنيات ومحتوى جديد للاستهلاك من قبل أي تطبيقات عميل قادرة على الوصول إلى حساب Azure Storage.
أبسط طريقة لإنشاء مستندات مثرية برمجيا هي من خلال واجهات برمجة تطبيقات REST.