إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تعرف على كيفية استخدام Azure SDK ل .NET لإنشاء مسار إثراء الذكاء الاصطناعي لاستخراج المحتوى والتحويلات أثناء الفهرسة.
تضيف مجموعات المهارات معالجة الذكاء الاصطناعي إلى المحتوى الخام، ما يجعلها أكثر اتساقا وقابلية للبحث. بمجرد أن تعرف كيفية عمل مجموعات المهارات، يمكنك دعم مجموعة واسعة من التحويلات، من تحليل الصور إلى معالجة اللغة الطبيعية إلى المعالجة المخصصة التي تقدمها خارجيا.
في هذا البرنامج التعليمي، سوف تتعلّم:
- تعريف الكائنات في مسار الإثراء.
- بناء مجموعة مهارات. استدعاء التعرف البصري على الحروف والكشف عن اللغة والتعرف على الكيان واستخراج العبارة الرئيسية.
- تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية. إنشاء فهرس بحث وتحميله.
- تحقق من النتائج باستخدام البحث عن النص الكامل.
Overview
يستخدم هذا البرنامج التعليمي C# ومكتبة عميل Azure.Search.Documents لإنشاء مصدر بيانات وفهرس ومفهرس ومجموعة مهارات.
يقوم المفهرس بمحرك كل خطوة في المسار، بدءا من استخراج محتوى بيانات العينة (نص وصور غير منظمة) في حاوية كائن ثنائي كبير الحجم على Azure Storage.
بمجرد استخراج المحتوى، تنفذ مجموعة المهارات مهارات مضمنة من Microsoft للعثور على المعلومات واستخراجها. وتشمل هذه المهارات التعرف البصري على الحروف (OCR) على الصور، والكشف عن اللغة على النص، واستخراج العبارة الرئيسية، والتعرف على الكيان (المؤسسات). يتم إرسال المعلومات الجديدة التي تم إنشاؤها بواسطة مجموعة المهارات إلى الحقول في فهرس. بمجرد ملء الفهرس، يمكنك استخدام الحقول في الاستعلامات والوجهات وعوامل التصفية.
Prerequisites
حساب Azure مع اشتراك نشط. أنشئ حساباً مجاناً.
Note
يمكنك استخدام خدمة بحث مجانية لهذا البرنامج التعليمي. يحدد لك المستوى المجاني ثلاثة فهارس وثلاثة مفهرسات وثلاثة مصادر بيانات. ينشئ هذا البرنامج التعليمي واحدًا من كلٍّ منها. قبل البدء، تأكد من أن لديك مساحة في خدمتك لقبول الموارد الجديدة.
تحميل الملفات
قم بتنزيل ملف مضغوط لنموذج مستودع البيانات واستخرج المحتويات. تعرف على كيفية القيام بذلك.
تحميل نموذج البيانات إلى Azure Storage
في Azure Storage، قم بإنشاء حاوية جديدة وقم بتسميته أنواع المحتوى المختلط.
قم بتحميل نماذج ملفات البيانات.
احصل على سلسلة الاتصال تخزين بحيث يمكنك صياغة اتصال في Azure الذكاء الاصطناعي Search.
على اليسار، حدد Access keys.
انسخ سلسلة الاتصال للمفتاح واحد أو المفتاحين. يشبه سلسلة الاتصال المثال التالي:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
أدوات الصاهر
يتم دعم إثراء الذكاء الاصطناعي المدمج من خلال أدوات Foundry، بما في ذلك Azure Language وAzure Vision لمعالجة اللغة الطبيعية والصور. بالنسبة لأحمال العمل الصغيرة مثل هذا البرنامج التعليمي، يمكنك استخدام التخصيص المجاني ل 20 معاملة لكل مفهرس. للحصول على أعباء عمل أكبر، أرفق موردا من Microsoft Foundry إلى مجموعة مهارات للتسعير القياسي.
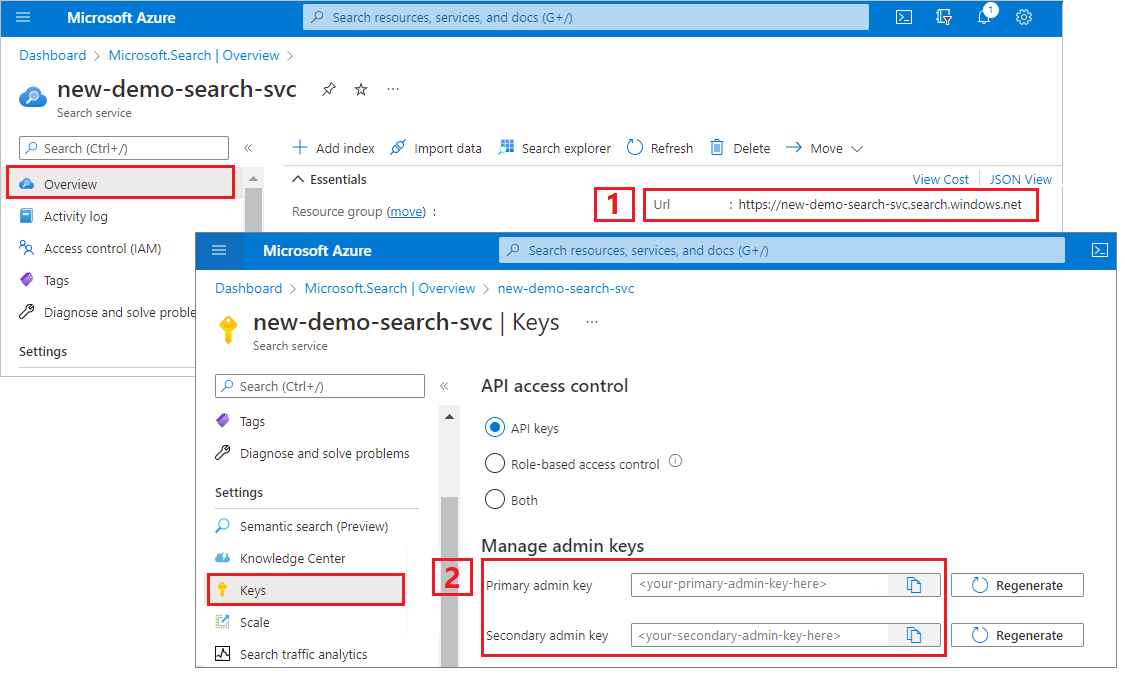
نسخ عنوان URL لخدمة البحث ومفتاح API
بالنسبة لهذا البرنامج التعليمي، تتطلب الاتصالات ب Azure الذكاء الاصطناعي Search نقطة نهاية ومفتاح API. يمكنك الحصول على هذه القيم من مدخل Microsoft Azure.
سجل الدخول إلى مدخل Microsoft Azure وحدد خدمة البحث.
من اللوحة اليسرى، اختر نظرة عامة وانسخ نقطة النهاية. يجب أن يكون بهذا الشكل:
https://my-service.search.windows.netمن اللوحة اليسرى، اخترمفاتيحالإعدادات> وانسخ مفتاح المسؤول للحصول على الصلاحيات الكاملة للخدمة. هناك مفتاحان مسؤولان قابلان للتبديل، مقدمان لاستمرارية العمل في حالة الحاجة إلى لفة واحدة. يمكنك استخدام أي من المفتاحين على طلبات الإضافة أو التعديل أو حذف الكائنات.
إعداد بيئتك
ابدأ بفتح Visual Studio وإنشاء مشروع تطبيق وحدة تحكم جديد.
تثبيت Azure.Search.Documents
يتكون Azure الذكاء الاصطناعي Search .NET SDK من مكتبة عميل تمكنك من إدارة الفهارس ومصادر البيانات والمفهرسات ومجموعات المهارات، بالإضافة إلى تحميل المستندات وإدارتها وتنفيذ الاستعلامات، كل ذلك دون الحاجة إلى التعامل مع تفاصيل HTTP وJSON. يتم توزيع مكتبة العميل هذه كحزمة NuGet.
لهذا المشروع، قم بتثبيت الإصدار 11 أو أحدث من Azure.Search.Documents وأحدث إصدار من Microsoft.Extensions.Configuration.
في Visual Studio، حدد Tools>NuGet Package Manager>Manage NuGet Packages for Solution...
استعرض بحثا عن Azure.Search.Document.
حدد أحدث إصدار ثم حدد تثبيت.
كرر الخطوات السابقة لتثبيت Microsoft.Extensions.ConfigurationوMicrosoft.Extensions.Configuration.Json.
إضافة معلومات اتصال الخدمة
انقر بزر الماوس الأيمن فوق مشروعك في مستكشف الحلول وحدد إضافة>عنصر جديد... .
قم بتسمية الملف
appsettings.jsonوحدد إضافة.قم بتضمين هذا الملف في دليل الإخراج.
- انقر بزر الماوس الأيمن فوق
appsettings.jsonوحدد Properties. - قم بتغيير قيمة Copy to Output Directory إلى Copy if newer.
- انقر بزر الماوس الأيمن فوق
انسخ JSON أدناه إلى ملف JSON الجديد.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
أضف معلومات خدمة البحث وحساب تخزين الكائن الثنائي كبير الحجم. تذكر أنه يمكنك الحصول على هذه المعلومات من خطوات توفير الخدمة المشار إليها في القسم السابق.
بالنسبة إلى SearchServiceUri، أدخل عنوان URL الكامل.
إضافة مساحات أسماء
في Program.cs، أضف مساحات الأسماء التالية.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
إنشاء عميل
إنشاء مثيل ل SearchIndexClient و ضمن SearchIndexerClientMain.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Note
يتصل العملاء بخدمة البحث الخاصة بك. لتجنب فتح عدد كبير جدا من الاتصالات، يجب محاولة مشاركة مثيل واحد في التطبيق الخاص بك إذا كان ذلك ممكنا. الأساليب هي مؤشر ترابط آمن لتمكين مثل هذه المشاركة.
إضافة وظيفة للخروج من البرنامج أثناء الفشل
يهدف هذا البرنامج التعليمي إلى مساعدتك على فهم كل خطوة من خطوات تدفق الفهرسة. إذا كانت هناك مشكلة حرجة تمنع البرنامج من إنشاء مصدر البيانات أو مجموعة المهارات أو الفهرس أو المفهرس، فسيخرج البرنامج رسالة الخطأ ويخرجها بحيث يمكن فهم المشكلة ومعالجتها.
أضف ExitProgram إلى Main لمعالجة السيناريوهات التي تتطلب إنهاء البرنامج.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية
في Azure الذكاء الاصطناعي Search، تحدث معالجة الذكاء الاصطناعي أثناء الفهرسة (أو استيعاب البيانات). ينشئ هذا الجزء من الإرشادات أربعة كائنات: مصدر البيانات، وتعريف الفهرس، ومجموعة المهارات، والمفهرس.
الخطوة 1: إنشاء مصدر بيانات
SearchIndexerClient يحتوي على DataSourceName خاصية يمكنك تعيينها إلى كائن SearchIndexerDataSourceConnection . يوفر هذا الكائن جميع الطرق التي تحتاجها لإنشاء مصادر بيانات Azure الذكاء الاصطناعي Search أو سردها أو تحديثها أو حذفها.
إنشاء مثيل جديد SearchIndexerDataSourceConnection عن طريق استدعاء indexerClient.CreateOrUpdateDataSourceConnection(dataSource). تنشئ التعليمات البرمجية التالية مصدر بيانات من النوع AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("mixed-content-type"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
لطلب ناجح، يقوم الأسلوب بإرجاع مصدر البيانات الذي تم إنشاؤه. إذا كانت هناك مشكلة في الطلب، مثل معلمة غير صالحة، فإن الأسلوب يطرح استثناء.
أضف الآن سطرا Main لاستدعاء الدالة CreateOrUpdateDataSource التي أضفتها للتو.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
إنشاء الحل وتشغيله. نظرا لأن هذا هو طلبك الأول، تحقق من مدخل Microsoft Azure لتأكيد إنشاء مصدر البيانات في Azure الذكاء الاصطناعي Search. في صفحة نظرة عامة على خدمة البحث، تحقق من أن قائمة مصادر البيانات تحتوي على عنصر جديد. قد تحتاج إلى الانتظار بضع دقائق حتى يتم تحديث صفحة مدخل Microsoft Azure.
 مصادر البيانات في مدخل Microsoft Azure
مصادر البيانات في مدخل Microsoft Azure
الخطوة 2: إنشاء مجموعة مهارات
في هذا القسم، يمكنك تحديد مجموعة من خطوات الإثراء التي تريد تطبيقها على بياناتك. وتسمى كل خطوة إثراء مهارة ومجموعة من خطوات الإثراء، ومجموعة المهارات. يستخدم هذا البرنامج التعليمي المهارات المضمنة لمجموعة المهارات:
التعرف البصري على الأحرف للتعرف على النص المطبوع والمكتوب بخط اليد في ملفات الصور.
دمج النص لدمج النص من مجموعة من الحقول في حقل "محتوى مدمج" واحد.
الكشف عن اللغة لتحديد لغة المحتوى.
التعرف على الكيان لاستخراج أسماء المؤسسات من المحتوى في حاوية الكائن الثنائي كبير الحجم.
تقسيم النص لتقسيم المحتوى الكبير إلى أجزاء أصغر قبل استدعاء مهارة استخراج العبارة الرئيسية ومهارة التعرف على الكيان. يقبل استخراج العبارة الرئيسية والتعرف على الكيان مدخلات من 50000 حرف أو أقل. يحتاج عددٌ قليلٌ من عينات الملفات إلى تقسيمها لتلائم هذا الحد.
استخراج العبارة الرئيسية لسحب أهم العبارات الرئيسية.
أثناء المعالجة الأولية، يكسر Azure الذكاء الاصطناعي Search كل مستند لاستخراج المحتوى من تنسيقات ملفات مختلفة. يتم وضع النص المنشأ في الملف المصدر في حقل تم content إنشاؤه، واحد لكل مستند. على هذا النحو، قم بتعيين الإدخال لاستخدام "/document/content" هذا النص. يتم وضع محتوى الصورة في حقل تم normalized_images إنشاؤه، محدد في مجموعة مهارات ك /document/normalized_images/*.
يمكن تعيين المخرجات إلى فهرس، أو استخدامها كمدخل لمهارة انتقال البيانات من الخادم، أو كليهما كما هو الحال مع تعليمة اللغة البرمجية. في الفهرس، يكون رمز اللغة مفيداً للتصفية. كمدخل، يتم استخدام تعليمة اللغة البرمجية بواسطة مهارات تحليل النص لإبلاغ القواعد اللغوية حول تقسيم الكلمات.
لمزيد من المعلومات عن أساسيات مجموعة المهارات، راجع كيف تعرف مجموعة مهارات.
مهارة التعرف البصري على الحروف (OCR)
يستخرج OcrSkill النص من الصور. تفترض هذه المهارة وجود حقل normalized_images. لإنشاء هذا الحقل، في وقت لاحق في البرنامج التعليمي، قمنا بتعيين "imageAction" التكوين في تعريف المفهرس إلى "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
دمج المهارة
في هذا القسم، يمكنك إنشاء MergeSkill الذي يدمج حقل محتوى المستند مع النص الذي تم إنتاجه بواسطة مهارة التعرف البصري على الحروف.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
مهارة الكشف عن اللغة
LanguageDetectionSkill يكتشف لغة نص الإدخال ويبلغ عن رمز لغة واحد لكل مستند يتم إرساله على الطلب. نستخدم إخراج مهارة الكشف عن اللغة كجزء من الإدخال إلى مهارة تقسيم النص .
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
مهارة تقسيم النصوص
يقسم النص أدناه SplitSkill حسب الصفحات ويحد من طول الصفحة إلى 4000 حرف كما يتم قياسه بواسطة String.Length. تحاول الخوارزمية تقسيم النص إلى أجزاء في الحجم على الأكثر maximumPageLength . في هذه الحالة، تقوم الخوارزمية بقصارى جهدها لكسر الجملة على حد الجملة، لذلك قد يكون حجم المجموعة أقل قليلا من maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
مهارة التعرف على الكيان
تم تعيين هذا EntityRecognitionSkill المثيل للتعرف على نوع organizationالفئة .
EntityRecognitionSkill يمكن أيضا التعرف على أنواع person الفئات وlocation.
لاحظ أنه تم تعيين حقل "السياق" إلى "/document/pages/*" بعلامة نجمية، ما يعني أن خطوة الإثراء يتم استدعاؤها لكل صفحة ضمن "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
// Specify the V3 version of the EntityRecognitionSkill
var skillVersion = EntityRecognitionSkill.SkillVersion.V3;
var entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings, skillVersion)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
مهارة استخراج العبارة الرئيسية
مثل المثيل EntityRecognitionSkill الذي تم إنشاؤه للتو، KeyPhraseExtractionSkill يتم استدعاء لكل صفحة من صفحات المستند.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
بناء وإنشاء مجموعة المهارات
SearchIndexerSkillset بناء باستخدام المهارات التي أنشأتها.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Foundry Tools was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
أضف الأسطر التالية إلى Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
الخطوة 3: إنشاء فهرس
في هذا القسم، يمكنك تعريف مخطط الفهرس عن طريق تحديد الحقول التي يجب تضمينها في الفهرس القابل للبحث، وسمات البحث لكل حقل. تحتوي الحقول على نوع ويمكن أن تأخذ سمات تحدد كيفية استخدام الحقل (قابل للبحث والفرز وما إلى ذلك). أسماء الحقول في فهرس غير مطلوبة لمطابقة أسماء الحقول في المصدر بشكل متطابق. في خطوة لاحقة، يمكنك إضافة تعيينات الحقول في مفهرس لتوصيل حقول وجهة المصدر. لهذه الخطوة، حدد الفهرس باستخدام اصطلاحات تسمية الحقول ذات الصلة بتطبيق البحث الخاص بك.
يستخدم هذا التمرين الحقول وأنواع الحقول التالية:
| أسماء الحقول | أنواع الحقول |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
قائمة<Edm.String> |
organizations |
قائمة<Edm.String> |
إنشاء فئة DemoIndex
يتم تعريف حقول هذا الفهرس باستخدام فئة نموذج. تحتوي كل خاصية من خصائص فئة النموذج على سمات تحدد السلوكيات المتعلقة بالبحث لحقل الفهرس المقابل.
سنضيف فئة النموذج إلى ملف C# جديد. حدد بزر الماوس الأيمن في مشروعك وحدد إضافة>عنصر جديد...، وحدد "فئة" وقم بتسمية الملف DemoIndex.cs، ثم حدد إضافة.
تأكد من الإشارة إلى أنك تريد استخدام أنواع من Azure.Search.Documents.Indexes مساحات الأسماء و System.Text.Json.Serialization .
أضف تعريف فئة النموذج أدناه إلى DemoIndex.cs وقم بتضمينه في نفس مساحة الاسم حيث تقوم بإنشاء الفهرس.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
الآن بعد أن قمت بتعريف فئة نموذج، يمكنك إنشاء Program.cs تعريف فهرس بسهولة إلى حد ما. سيكون demoindexاسم هذا الفهرس هو . إذا كان الفهرس موجودا بالفعل بهذا الاسم، يتم حذفه.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
أثناء الاختبار، قد تجد أنك تحاول إنشاء الفهرس أكثر من مرة. لهذا السبب، تحقق لمعرفة ما إذا كان الفهرس الذي أنت على وشك إنشائه موجودا بالفعل قبل محاولة إنشائه.
أضف الأسطر التالية إلى Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
أضف العبارة التالية باستخدام لحل المرجع غير المبهم.
using Index = Azure.Search.Documents.Indexes.Models;
لمعرفة المزيد حول مفاهيم الفهرس، راجع إنشاء فهرس (REST API).
4 - إنشاء وتشغيل المفهرس
لقد قمت حتى الآن بإنشاء مصدر بيانات ومجموعة مهارات وفهرس. تصبح هذه المكونات الثلاثة جزءا من مفهرس يجمع كل قطعة معا في عملية واحدة متعددة المراحل. لربط هذه معا في مفهرس، يجب تحديد تعيينات الحقول.
تتم معالجة fieldMappings قبل مجموعة المهارات، وتعيين حقول المصدر من مصدر البيانات إلى الحقول المستهدفة في فهرس. إذا كانت أسماء الحقول وأنواعها هي نفسها في كلا الطرفين، فلا يلزم التعيين.
تتم معالجة outputFieldMappings بعد مجموعة المهارات، مع الإشارة إلى sourceFieldNames غير الموجودة حتى ينشئها تكسير المستند أو إثراءه. targetFieldName هو حقل في فهرس.
بالإضافة إلى ربط المدخلات بالمخرجات، يمكنك أيضا استخدام تعيينات الحقول لتسوية بنيات البيانات. لمزيد من المعلومات، راجع كيفية تعيين الحقول التي تم إثراؤها إلى فهرس قابل للبحث.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
أضف الأسطر التالية إلى Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
توقع أن تستغرق معالجة المفهرس بعض الوقت لإكمالها. على الرغم من أن مجموعة البيانات صغيرة، إلا أن المهارات التحليلية تتطلب عمليات حسابية مكثفة. بعض المهارات، مثل تحليل الصور، طويلة الأمد.
Tip
يؤدي إنشاء مفهرس إلى استدعاء التدفق. إذا كانت هناك مشاكل في الوصول إلى البيانات، أو تعيين المدخلات والمخرجات، أو ترتيب العمليات، فإنها تظهر في هذه المرحلة.
استكشاف إنشاء المفهرس
تعين "maxFailedItems" التعليمات البرمجية إلى -1، الذي يوجه محرك الفهرسة لتجاهل الأخطاء أثناء استيراد البيانات. هذا مفيد لأن هناك عدد قليل جدا من المستندات في مصدر بيانات العرض التوضيحي. بالنسبة لمصدر بيانات أكبر، يمكنك تعيين القيمة إلى أكبر من 0.
لاحظ "dataToExtract" أيضا تعيين إلى "contentAndMetadata". تخبر هذه العبارة المفهرس باستخراج المحتوى تلقائيا من تنسيقات ملفات مختلفة بالإضافة إلى بيانات التعريف المتعلقة بكل ملف.
عند استخراج المحتوى، يمكنك تعيين imageAction لاستخراج النص من الصور الموجودة في مصدر البيانات. تعين "imageAction" على التكوين، جنبا إلى جنب مع مهارة التعرف البصري على "generateNormalizedImages" الحروف ومهارة دمج النصوص، تخبر المفهرس باستخراج النص من الصور (على سبيل المثال، كلمة "إيقاف" من علامة توقف حركة المرور)، وتضمينه كجزء من حقل المحتوى. ينطبق هذا السلوك على الصور المضمنة في المستندات (فكر في صورة داخل ملف PDF)، بالإضافة إلى الصور الموجودة في مصدر البيانات، على سبيل المثال ملف JPG.
مراقبة الفهرسة
بمجرد تعريف المفهرس، يتم تشغيله تلقائيا عند إرسال الطلب. اعتمادا على المهارات التي حددتها، قد تستغرق الفهرسة وقتا أطول مما تتوقع. لمعرفة ما إذا كان المفهرس لا يزال قيد التشغيل، استخدم GetStatus الأسلوب .
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo يمثل الحالة الحالية ومحفوظات التنفيذ للمفهرس.
التحذيرات شائعة مع بعض مجموعات الملفات والمهارة المصدر ولا تشير دائما إلى وجود مشكلة. في هذا البرنامج التعليمي، تكون التحذيرات حميدة (على سبيل المثال، لا توجد مدخلات نصية من ملفات JPEG).
أضف الأسطر التالية إلى Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Search
في تطبيقات وحدة تحكم البرنامج التعليمي للبحث في Azure الذكاء الاصطناعي، نضيف عادة تأخيرا لمدة ثانيتين قبل تشغيل الاستعلامات التي ترجع النتائج، ولكن نظرا لأن الإثراء يستغرق عدة دقائق حتى يكتمل، فسنغلق تطبيق وحدة التحكم ونستخدم نهجا آخر بدلا من ذلك.
الخيار الأسهل هو مستكشف البحث في مدخل Microsoft Azure. يمكنك أولا تشغيل استعلام فارغ يقوم بإرجاع كافة المستندات، أو بحث أكثر استهدافا يقوم بإرجاع محتوى حقل جديد تم إنشاؤه بواسطة البنية الأساسية لبرنامج ربط العمليات التجارية.
في مدخل Microsoft Azure، في صفحات خدمة البحث، قم بتوسيعفهارس إدارة >البحث.
البحث
demoindexفي القائمة. يجب أن تحتوي على 14 مستندا. إذا كان عدد المستندات صفرا، فإن المفهرس إما لا يزال قيد التشغيل أو لم يتم تحديث الصفحة بعد.حدد
demoindex. Search Explorer هي علامة التبويب الأولى.يمكن البحث في المحتوى بمجرد تحميل المستند الأول. للتحقق من وجود المحتوى، قم بتشغيل استعلام غير محدد بالنقر فوق بحث. يقوم هذا الاستعلام بإرجاع جميع المستندات المفهرسة حاليا، مما يمنحك فكرة عما يحتويه الفهرس.
للحصول على نتائج أكثر قابلية للإدارة، قم بالتبديل إلى طريقة عرض JSON وقم بتعيين المعلمات لتحديد الحقول:
{ "search": "*", "count": true, "select": "id, languageCode, organizations" }
إعادة تعيين وإعادة تشغيل
في المراحل التجريبية المبكرة من التطوير، يتمثل النهج الأكثر عملية لتكرار التصميم في حذف الكائنات من Azure الذكاء الاصطناعي Search والسماح للتعليمات البرمجية بإعادة إنشائها. أسماء الموارد فريدة. يتيح لك حذف كائن إعادة إنشائه باستخدام نفس الاسم.
يتحقق نموذج التعليمات البرمجية لهذا البرنامج التعليمي من الكائنات الموجودة ويحذفها بحيث يمكنك إعادة تشغيل التعليمات البرمجية الخاصة بك. يمكنك أيضا استخدام مدخل Microsoft Azure لحذف الفهارس والمفهرسات ومصادر البيانات ومجموعات المهارات.
Takeaways
أظهر هذا البرنامج التعليمي الخطوات الأساسية لبناء مسار فهرسة مثري من خلال إنشاء أجزاء مكونة: مصدر بيانات ومجموعة مهارات وفهرس ومفهرس.
تم إدخال المهارات المضمنة، جنبا إلى جنب مع تعريف مجموعة المهارات وميكانيكا مهارات التسلسل معا من خلال المدخلات والمخرجات. كما تعلمت أنه outputFieldMappings في تعريف المفهرس مطلوب لتوجيه القيم التي تم إثراؤها من البنية الأساسية لبرنامج ربط العمليات التجارية إلى فهرس قابل للبحث على azure الذكاء الاصطناعي خدمة البحث.
وأخيرًا، تعلمت كيفية اختبار النتائج وإعادة ضبط النظام لمزيد من التكرارات. لقد تعلمت أن إصدار الاستعلامات مقابل الفهرس يُرجع المخرجات التي جرى إنشاؤها بواسطة تدفق الفهرسة الذي جرى إثراؤه. كما تعلمت كيفية التحقق من حالة المفهرس، والعناصر التي يجب حذفها قبل إعادة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
تنظيف الموارد
عندما تعمل في اشتراكك الخاص، في نهاية المشروع، من المستحسن إزالة الموارد التي لم تعد بحاجة إليها. الموارد المتبقية قيد التشغيل يمكن أن تكلفك المال. يمكنك حذف الموارد بشكل فردي أو حذف مجموعة الموارد لحذف تشكيلة الموارد بأكملها.
يمكنك العثور على الموارد وإدارتها في مدخل Microsoft Azure، باستخدام الارتباط All resources أو Resource groups في جزء التنقل الأيسر.
الخطوات التالية
الآن بعد أن أصبحت على دراية بجميع الكائنات في مسار إثراء الذكاء الاصطناعي، دعنا نلقي نظرة فاحصة على تعريفات مجموعة المهارات والمهارات الفردية.
تعرف على كيفية استدعاء واجهات برمجة تطبيقات REST التي تنشئ مسار إثراء الذكاء الاصطناعي لاستخراج المحتوى والتحويلات أثناء الفهرسة.
تضيف مجموعات المهارات معالجة الذكاء الاصطناعي إلى المحتوى الخام، ما يجعلها أكثر اتساقا وقابلية للبحث. بمجرد أن تعرف كيفية عمل مجموعات المهارات، يمكنك دعم مجموعة واسعة من التحويلات، من تحليل الصور إلى معالجة اللغة الطبيعية إلى المعالجة المخصصة التي تقدمها خارجيا.
في هذا البرنامج التعليمي، سوف تتعلّم:
- تعريف الكائنات في مسار الإثراء.
- بناء مجموعة مهارات. استدعاء التعرف البصري على الحروف والكشف عن اللغة والتعرف على الكيان واستخراج العبارة الرئيسية.
- تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية. إنشاء فهرس بحث وتحميله.
- تحقق من النتائج باستخدام البحث عن النص الكامل.
Overview
يستخدم هذا البرنامج التعليمي عميل REST وAzure الذكاء الاصطناعي Search REST APIs لإنشاء مصدر بيانات وفهرس ومفهرس ومجموعة مهارات.
يقوم المفهرس بمحرك كل خطوة في المسار، بدءا من استخراج محتوى بيانات العينة (نص وصور غير منظمة) في حاوية كائن ثنائي كبير الحجم على Azure Storage.
بمجرد استخراج المحتوى، تنفذ مجموعة المهارات مهارات مضمنة من Microsoft للعثور على المعلومات واستخراجها. وتشمل هذه المهارات التعرف البصري على الحروف (OCR) على الصور، والكشف عن اللغة على النص، واستخراج العبارة الرئيسية، والتعرف على الكيان (المؤسسات). يتم إرسال المعلومات الجديدة التي تم إنشاؤها بواسطة مجموعة المهارات إلى الحقول في فهرس. بمجرد ملء الفهرس، يمكنك استخدام الحقول في الاستعلامات والوجهات وعوامل التصفية.
Prerequisites
حساب Azure مع اشتراك نشط. أنشئ حساباً مجاناً.
Visual Studio Code مع عميل REST
Note
يمكنك استخدام خدمة بحث مجانية لهذا البرنامج التعليمي. يحدد لك المستوى المجاني ثلاثة فهارس وثلاثة مفهرسات وثلاثة مصادر بيانات. ينشئ هذا البرنامج التعليمي واحدًا من كلٍّ منها. قبل البدء، تأكد من أن لديك مساحة في خدمتك لقبول الموارد الجديدة.
تحميل الملفات
قم بتنزيل ملف مضغوط لنموذج مستودع البيانات واستخرج المحتويات. تعرف على كيفية القيام بذلك.
تحميل نموذج البيانات إلى Azure Storage
في Azure Storage، قم بإنشاء حاوية جديدة وسمها cog-search-demo.
تحميل ملفات البيانات النموذجية.
احصل على سلسلة الاتصال تخزين بحيث يمكنك صياغة اتصال في Azure الذكاء الاصطناعي Search.
على اليسار، حدد Access keys.
انسخ سلسلة الاتصال للمفتاح واحد أو المفتاحين. يشبه سلسلة الاتصال المثال التالي:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
أدوات الصاهر
يتم دعم إثراء الذكاء الاصطناعي المدمج من خلال أدوات Foundry، بما في ذلك Azure Language وAzure Vision لمعالجة اللغة الطبيعية والصور. بالنسبة لأحمال العمل الصغيرة مثل هذا البرنامج التعليمي، يمكنك استخدام التخصيص المجاني لعشرين معاملة لكل مفهرس. للحصول على أعباء عمل أكبر، أرفق موردا من Microsoft Foundry إلى مجموعة مهارات للتسعير القياسي.
نسخ عنوان URL لخدمة البحث ومفتاح API
بالنسبة لهذا البرنامج التعليمي، تتطلب الاتصالات ب Azure الذكاء الاصطناعي Search نقطة نهاية ومفتاح API. يمكنك الحصول على هذه القيم من مدخل Microsoft Azure.
سجل الدخول إلى مدخل Microsoft Azure وحدد خدمة البحث.
من اللوحة اليسرى، اختر نظرة عامة وانسخ نقطة النهاية. يجب أن يكون بهذا الشكل:
https://my-service.search.windows.netمن اللوحة اليسرى، اخترمفاتيحالإعدادات> وانسخ مفتاح المسؤول للحصول على الصلاحيات الكاملة للخدمة. هناك مفتاحان مسؤولان قابلان للتبديل، مقدمان لاستمرارية العمل في حالة الحاجة إلى لفة واحدة. يمكنك استخدام أي من المفتاحين على طلبات الإضافة أو التعديل أو حذف الكائنات.
إعداد ملف REST
ابدأ تشغيل Visual Studio Code وافتح ملف skillset-tutorial.rest . راجع التشغيل السريع: البحث عن النص الكامل إذا كنت بحاجة إلى مساعدة مع عميل REST.
توفير قيم للمتغيرات: نقطة نهاية خدمة البحث، ومفتاح واجهة برمجة تطبيقات مسؤول خدمة البحث، واسم الفهرس، سلسلة الاتصال إلى حساب Azure Storage، واسم حاوية كائن ثنائي كبير الحجم.
إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية
الإثراء الذكاء الاصطناعي يعتمد على المفهرس. ينشئ هذا الجزء من الإرشادات أربعة كائنات: مصدر البيانات، وتعريف الفهرس، ومجموعة المهارات، والمفهرس.
الخطوة 1: إنشاء مصدر بيانات
اتصل بإنشاء مصدر بيانات لتعيين سلسلة الاتصال إلى حاوية Blob التي تحتوي على ملفات البيانات النموذجية.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
الخطوة 2: إنشاء مجموعة مهارات
اتصل ب Create Skillset لتحديد خطوات الإثراء التي يتم تطبيقها على المحتوى الخاص بك. يتم تنفيذ المهارات بالتوازي ما لم يكن هناك تبعية.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
النقاط الرئيسية:
يحدد نص الطلب المهارات المضمنة التالية:
Skill Description التعرف البصري على الحروف يتعرف على النصوص والأرقام في ملفات الصور. دمج النص إنشاء "محتوى مدمج" يعيد دمج المحتوى المفصول مسبقا، وهو مفيد للمستندات التي تحتوي على صور مضمنة (PDF و DOCX وما إلى ذلك). يتم فصل الصور والنصوص أثناء مرحلة تكسير المستند. تعيد مهارة الدمج دمجها عن طريق إدراج أي نص أو تسميات توضيحية للصور أو علامات تم التعرف عليها تم إنشاؤها أثناء الإثراء في نفس الموقع الذي تم استخراج الصورة منه في المستند. عندما تعمل مع محتوى مدمج في مجموعة مهارات، تكون هذه العقدة شاملة لجميع النصوص في المستند، بما في ذلك مستندات النص فقط التي لا تخضع أبدا ل OCR أو تحليل الصور. كشف اللغة يكتشف اللغة ويخرج إما اسم لغة أو تعليمة برمجية. في مجموعات البيانات متعددة اللغات، يمكن أن يكون حقل اللغة مفيدا لعوامل التصفية. التعرف على الكيان استخراج أسماء الأشخاص والمؤسسات والمواقع من المحتوى المدمج. تقسيم النص تقسيم المحتوى المدمج الكبير إلى أجزاء أصغر قبل استدعاء مهارة استخراج العبارة الرئيسية. يقبل استخراج العبارة الرئيسية إدخالات من 50000 حرفٍ أو أقل. يحتاج عددٌ قليلٌ من عينات الملفات إلى تقسيمها لتلائم هذا الحد. مهارة استخراج العبارة الرئيسية سحب العبارات الرئيسية العليا. يتم تنفيذ كل مهارة على محتوى المستند. أثناء المعالجة، يشق Azure الذكاء الاصطناعي Search كل مستند لقراءة المحتوى من تنسيقات ملفات مختلفة. يُوضع النص الذي أُنشئ في الملف المصدر في حقل
contentالمُنشأ، واحدٌ لكل مستند. على هذا النحو، يصبح الإدخال"/document/content".لاستخراج العبارة الرئيسية، لأننا نستخدم مهارة تقسيم النص لتقسيم الملفات الكبيرة إلى صفحات، فإن سياق مهارة استخراج العبارة الرئيسية هو
"document/pages/*"(لكل صفحة في المستند) بدلا من"/document/content".
Note
يمكن تعيين المخرجات إلى فهرس، أو استخدامها كمدخل لمهارة انتقال البيانات من الخادم، أو كليهما كما هو الحال مع تعليمة اللغة البرمجية. في الفهرس، يكون رمز اللغة مفيداً للتصفية. لمزيد من المعلومات عن أساسيات مجموعة المهارات، راجع كيف تعرف مجموعة مهارات.
الخطوة 3: إنشاء فهرس
استدعاء إنشاء فهرس لتوفير المخطط المستخدم لإنشاء فهارس مقلوبة وبنيات أخرى في Azure الذكاء الاصطناعي Search.
أكبر مكون من الفهرس هو مجموعة الحقول، حيث يحدد نوع البيانات والسمات المحتوى والسلوك في Azure الذكاء الاصطناعي Search. تأكد من أن لديك حقولا للإخراج الذي تم إنشاؤه حديثا.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
4 - إنشاء وتشغيل المفهرس
اتصل بإنشاء مفهرس لدفع البنية الأساسية لبرنامج ربط العمليات التجارية. المكونات الثلاثة التي قمت بإنشائها حتى الآن (مصدر البيانات، ومجموعة المهارات، والفهرس) هي مدخلات إلى مفهرس. إنشاء المفهرس على Azure الذكاء الاصطناعي Search هو الحدث الذي يضع المسار بأكمله قيد الحركة.
قد يستغرق هذا الأمر عدة دقائق ليكتمل. على الرغم من أن مجموعة البيانات صغيرة، إلا أن المهارات التحليلية تتطلب عمليات حسابية مكثفة.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
النقاط الرئيسية:
يتضمن نص الطلب مراجع إلى الكائنات السابقة وخصائص التكوين المطلوبة لمعالجة الصور ونوعين من تعيينات الحقول.
"fieldMappings"تتم معالجتها قبل مجموعة المهارات، وإرسال المحتوى من مصدر البيانات إلى الحقول المستهدفة في فهرس. يمكنك استخدام تعيينات الحقول لإرسال محتوى موجود وغير معدل إلى الفهرس. إذا كانت أسماء الحقول وأنواعها هي نفسها في كلا الطرفين، فلا يلزم التعيين."outputFieldMappings"هي للحاول التي تم إنشاؤها بواسطة المهارات، بعد تنفيذ مجموعة المهارات. لا توجد المراجع إلىsourceFieldNameفيoutputFieldMappingsحتى إنشاؤها بواسطة اكتشاف المستندات أو الإثراء.targetFieldNameهو حقل في فهرس، معرف في مخطط الفهرس."maxFailedItems"تم تعيين المعلمة إلى -1، والتي ترشد محرك الفهرسة إلى تجاهل الأخطاء أثناء استيراد البيانات. هذا مقبول لأن هناك عددًا قليلًا جدًا من الوثائق في مصدر البيانات التجريبي. بالنسبة لمصدر بيانات أكبر، يمكنك تعيين القيمة إلى أكبر من 0."dataToExtract":"contentAndMetadata"تخبر العبارة المفهرس باستخراج القيم تلقائيا من خاصية محتوى الكائن الثنائي كبير الحجم وبيانات التعريف لكل كائن.imageActionتخبر المعلمة المفهرس باستخراج النص من الصور الموجودة في مصدر البيانات. إن"imageAction":"generateNormalizedImages"التكوين، جنبًا إلى جنب مع مهارة OCR ومهارة دمج النص، تخبر المفهرس باستخراج النص من الصور (على سبيل المثال، كلمة "إيقاف" من علامة توقف نسبة استخدام الشبكة)، وتضمينها باعتبارها جزءًا من حقل المحتوى. ينطبق هذا السلوك على كل من الصور المضمنة (فكر في صورة داخل PDF) وملفات الصور المستقلة، على سبيل المثال ملف JPG.
Note
يؤدي إنشاء مفهرس إلى استدعاء التدفق. إذا كانت هناك مشاكل في الوصول إلى البيانات، أو تعيين المدخلات والمخرجات، أو ترتيب العمليات، فإنها تظهر في هذه المرحلة. لإعادة تشغيل التدفق مع تغييرات الرمز أو البرنامج النصي، قد تحتاج إلى إسقاط الكائنات أولا. لمزيد من المعلومات، راجع إعادة تعيين وإعادة تشغيل.
مراقبة الفهرسة
تبدأ الفهرسة والإثراء بمجرد إرسال طلب إنشاء مفهرس. اعتمادا على تعقيد مجموعة المهارات والعمليات، يمكن أن تستغرق الفهرسة بعض الوقت.
لمعرفة ما إذا كان المفهرس لا يزال قيد التشغيل، اتصل ب Get Indexer Status للتحقق من حالة المفهرس.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
النقاط الرئيسية:
التحذيرات شائعة في بعض السيناريوهات ولا تشير دائما إلى وجود مشكلة. على سبيل المثال، إذا كانت حاوية كائن ثنائي كبير الحجم تتضمن ملفات صور، ولا يتعامل المسار مع الصور، فستتلقى تحذيرا يفيد بأنه لم تتم معالجة الصور.
في هذه العينة، يوجد ملف PNG لا يحتوي على نص. تفشل جميع المهارات الخمسة المستندة إلى النص (الكشف عن اللغة، والتعرف على الكيان للمواقع، والمؤسسات، والأشخاص، واستخراج العبارة الرئيسية) في التنفيذ على هذا الملف. يظهر الإعلام الناتج في محفوظات التنفيذ.
التحقق من النتائج
الآن بعد أن قمت بإنشاء فهرس يحتوي على محتوى تم إنشاؤه الذكاء الاصطناعي، اتصل بمستندات البحث لتشغيل بعض الاستعلامات للاطلاع على النتائج.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
يمكن أن تساعدك عوامل التصفية على تضييق نطاق النتائج إلى العناصر المهمة:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
توضح هذه الاستعلامات بعض الطرق التي يمكنك من خلالها استخدام بناء جملة الاستعلام وعوامل التصفية على الحقول الجديدة التي تم إنشاؤها بواسطة Azure الذكاء الاصطناعي Search. لمزيد من أمثلة الاستعلام، راجع الأمثلة فيSearch Documents REST API، وأمثلة استعلام بناء الجملة البسيطة، وأمثلة استعلام Full Lucene.
إعادة تعيين وإعادة تشغيل
أثناء المراحل المبكرة من التطوير، يكون التكرار عبر التصميم شائعا. تساعد إعادة التعيين وإعادة التشغيل في التكرار.
Takeaways
يوضح هذا البرنامج التعليمي الخطوات الأساسية لاستخدام واجهات برمجة تطبيقات REST لإنشاء مسار إثراء الذكاء الاصطناعي: مصدر بيانات ومجموعة مهارات وفهرس ومفهرس.
تم إدخال المهارات المضمنة، جنبا إلى جنب مع تعريف مجموعة المهارات الذي يوضح آليات مهارات التسلسل معا من خلال المدخلات والمخرجات. كما تعلمت أنه outputFieldMappings في تعريف المفهرس مطلوب لتوجيه القيم التي تم إثراؤها من البنية الأساسية لبرنامج ربط العمليات التجارية إلى فهرس قابل للبحث على azure الذكاء الاصطناعي خدمة البحث.
وأخيرًا، تعلمت كيفية اختبار النتائج وإعادة ضبط النظام لمزيد من التكرارات. لقد تعلمت أن إصدار الاستعلامات مقابل الفهرس يُرجع المخرجات التي جرى إنشاؤها بواسطة تدفق الفهرسة الذي جرى إثراؤه.
تنظيف الموارد
عندما تعمل في اشتراكك الخاص، في نهاية المشروع، من المستحسن إزالة الموارد التي لم تعد بحاجة إليها. الموارد المتبقية قيد التشغيل يمكن أن تكلفك المال. يمكنك حذف الموارد بشكل فردي أو حذف مجموعة الموارد لحذف تشكيلة الموارد بأكملها.
يمكنك العثور على الموارد وإدارتها في مدخل Microsoft Azure، باستخدام الارتباط All resources أو Resource groups في جزء التنقل الأيسر.
الخطوات التالية
الآن بعد أن أصبحت على دراية بجميع الكائنات في مسار إثراء الذكاء الاصطناعي، ألق نظرة فاحصة على تعريفات مجموعة المهارات والمهارات الفردية.