المراقبة والتشخيص لـ Azure Service Fabric
توفر هذه المقالة نظرة عامة حول المراقبة والتشخيص لـ Azure Service Fabric. تعتبرالمراقبة والتشخيصات ضرورية لتطوير أحمال العمل واختبارها ونشرها في أي بيئة سحابية. على سبيل المثال، يمكنك تعقب كيفية استخدام تطبيقاتك، والإجراءات التي يتخذها النظام الأساسي لـ Service Fabric، واستخدام الموارد مع عدادات الأداء، والصحة العامة لمجموعتك. يمكنك استخدام هذه المعلومات لتشخيص المشكلات وتصحيحها ومنع حدوثها في المستقبل. ستشرح الأقسام القليلة التالية بإيجاز كل مجال من مجالات مراقبة Service Fabric للنظر في أحمال عمل الإنتاج.
إشعار
تم تحديث هذه المقالة مؤخرًا لاستخدام مصطلح سجلات مراقبة Azure بدلاً من تحليلات السجلات. لا تزال بيانات السجل مخزنة في مساحة عمل Log Analytics ولا يزال يتم جمعها وتحليلها بواسطة نفس خدمة Log Analytics. نحن نحدِّث المصطلحات لتعكس دور السجلات في Azure Monitorعلى نحوٍ أفضل. راجع تغييرات مصطلحات Azure Monitor للحصول على التفاصيل.
مراقبة التطبيق
تتعقب مراقبة التطبيق كيفية استخدام ميزات التطبيق ومكوناته. تريد مراقبة تطبيقاتك للتأكد من اكتشاف المشكلات التي تؤثر في المستخدمين. تقع مسؤولية مراقبة التطبيق على عاتق المستخدمين الذين يقومون بتطوير تطبيق وخدماته نظراً لتفرده من ناحية منطق تسلسل العمل لتطبيقك. يمكن أن تكون مراقبة تطبيقاتك مفيدة في السيناريوهات التالية:
- ما مقدار نسبة استخدام الشبكة التي يواجهها تطبيقي؟ - هل تحتاج إلى تغيير حجم خدماتك لتلبية طلبات المستخدمين أو معالجة ازدحام محتمل في تطبيقك؟
- هل استدعاءات خدمة إلى خدمة ناجحة ومتعقبة؟
- ما هي الإجراءات التي يتخذها مستخدمو تطبيقي؟ - يمكن أن يوجه جمع بيانات تتبع الاستخدام تطوير الميزات المستقبلية وتشخيص أفضل لأخطاء التطبيق
- هل يطرح تطبيقي استثناءات غير معالجة؟
- ماذا يحدث داخل الخدمات التي تعمل داخل حاويتي؟
الشيء العظيم الذي تقدمه مراقبة التطبيق هو تمكين المطورين من استخدام أي أدوات وإطار عمل يرغبون فيه لأنها متواجدة دائماً في سياق تطبيقك! يمكنك معرفة المزيد حول حل Azure لمراقبة التطبيق باستخدام Azure Monitor Application Insights في تحليل الأحداث باستخدام Application Insights. لدينا أيضاً برنامج تعليمي حول كيفية إعداد هذا لتطبيقات .NET. يتناول هذا البرنامج التعليمي كيفية تثبيت الأدوات المناسبة، ومثالاً على كتابة بيانات تتبع الاستخدام المخصصة في تطبيقك، وعرض تشخيصات التطبيق وبيانات تتبع الاستخدام في مدخل Microsoft Azure.
مراقبة النظام الأساسي (نظام المجموعة)
يتحكم المستخدم في بيانات تتبع الاستخدام التي تأتي من تطبيقه نظراً لأن المستخدم يكتب التعليمة البرمجية نفسها، ولكن ماذا عن التشخيصات من النظام الأساسي لـ Service Fabric؟ يتمثل أحد أهداف Service Fabric في الحفاظ على مرونة التطبيقات في مواجهة فشل الأجهزة. يتم تحقيق هذا الهدف من خلال قدرة خدمات النظام الأساسي على اكتشاف مشكلات البنية الأساسية وأحمال العمل سريعة تجاوز الفشل إلى العُقد الأخرى في المجموعة. ولكن في هذه الحالة بالذات، ماذا لو كانت خدمات النظام نفسها تواجه مشكلات؟ أو تم انتهاك قواعد وضع الخدمات أثناء محاولتها نشر حمل عمل أو نقله؟ يوفر Service Fabric تشخيصات لهذه الأمور وأكثر للتأكد من اطلاعك على النشاط الذي يحدث في مجموعتك. تتضمن بعض عينات سيناريوهات مراقبة نظام مجموعة ما يلي:
يوفر Service Fabric مجموعة شاملة من الأحداث غير التقليدية. يمكن الوصول إلى أحداث Service Fabric هذه من خلال EventStore أو القناة التشغيلية (قناة الحدث التي يعرضها النظام الأساسي).
قنوات أحداث Service Fabric - على Windows، تتوفر أحداث Service Fabric من موفر ETW واحد مع مجموعة من القنوات ذات الصلة
logLevelKeywordFiltersالمستخدمة للانتقاء بين قنوات التشغيل والبيانات والمراسلة - هذه هي الطريقة التي نفصل بها أحداث Service Fabric الصادرة ليتم تصفيتها حسب الحاجة. على نظام التشغيل Linux، تأتي أحداث Service Fabric من خلال LTTng، ويتم وضعها في جدول تخزين واحد، حيث يمكن تصفيتها حسب الحاجة. تحتوي هذه القنوات على أحداث مجمعة ومنظمة يمكن استخدامها لفهم حالة مجموعتك بشكل أفضل. يتم تمكين التشخيصات بشكل افتراضي في وقت إنشاء نظام المجموعة، والتي تنشئ جدول تخزين Azure حيث يتم إرسال الأحداث من هذه القنوات إليك للاستعلام عنها في المستقبل.EventStore - تُعد EventStore ميزة يقدمها النظام الأساسي وتوفر أحداث النظام الأساسي لـ Service Fabric المتوفرة في Service Fabric Explorer ومن خلال واجهة برمجة تطبيقات REST. يمكنك رؤية طريقة عرض لقطة لما يحدث في مجموعتك لكل كيان مثل العقدة والخدمة والتطبيق والاستعلام استنادًا إلى وقت الحدث. يمكنك أيضًا قراءة المزيد حول EventStore في نظرة عامة على EventStore.
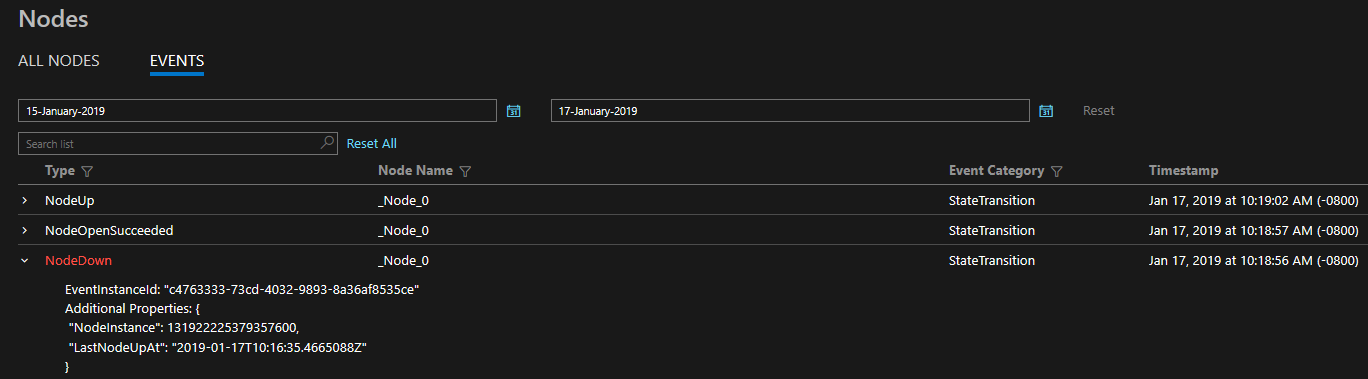
تُقدم التشخيصات في شكل مجموعة شاملة من الأحداث غير التقليدية. توضح أحداث Service Fabric هذه الإجراءات التي تقوم بها المنصة على كيانات مختلفة، مثل العقد، والتطبيقات، والخدمات، والأقسام، وما إلى ذلك. في السيناريو الأخير أعلاه، إذا كانت العقدة متوقفة عن التشغيل، فسيصدر النظام الأساسي حدثاً NodeDown، ويمكن إعلامك على الفور بواسطة أداة المراقبة التي تختارها. تتضمن الأمثلة الشائعة الأخرى ApplicationUpgradeRollbackStarted أو PartitionReconfigured أثناء تجاوز الفشل. تتوفر نفس الأحداث على مجموعات كل من Windows وLinux.
يتم إرسال الأحداث من خلال قنوات قياسية على كل من Windows وLinux، ويمكن قراءتها بواسطة أي أداة مراقبة تدعم هذا. حل Azure Monitor هو سجلات Azure Monitor. لا تتردد في قراءة المزيد حول تكامل سجلات Azure Monitor الذي يتضمن لوحة معلومات تشغيلية مخصصة لمجموعتك وبعض نماذج الاستعلامات التي يمكنك من خلالها إنشاء تنبيهات. يتوفر المزيد من مفاهيم مراقبة المجموعات في الحدث على مستوى النظام الأساسي وإنشاء السجلات.
مراقبة السلامة
يتضمن النظام الأساسي لـ Service Fabric نموذجاً صحياً يوفر تقارير صحية قابلة للتوسيع لحالة الكيانات في نظام المجموعة. لكل عقدة، أو تطبيق، أو خدمة، أو قسم، أو نسخة متماثلة، أو مثيل حالة صحية قابلة للتحديث باستمرار. يمكن أن تكون الحالة الصحية إما "OK"، أو "Warning"، أو "Error". فكر في أحداث Service Fabric كأفعال تقوم بها المجموعة لكيانات مختلفة، وفكر في الصحة كصفة لكل كيان. في كل مرة تنتقل فيها صحة كيان معين، سيتم أيضاً إصدار حدث. وبهذه الطريقة، يمكنك إعداد الاستعلامات والتنبيهات للأحداث الصحية في أداة المراقبة التي تختارها، تماماً مثل أي حدث آخر.
وبالإضافة إلى ذلك، نسمح للمستخدمين بتجاوز صحة الكيانات. إذا كان تطبيقك يمر بترقية ولديك اختبارات تحقق من الصحة فاشلة، فيمكنك الكتابة إلى Service Fabric Health باستخدام واجهة برمجة تطبيقات Health للإشارة إلى أن تطبيقك لم يعد سليماً، وستقوم Service Fabric تلقائياً بالتراجع عن الترقية! لمعرفة المزيد عن النموذج الصحي، راجع مقدمة مراقبة صحة Service Fabric
هيئات المراقبة
بشكل عام، هيئة الرقابة هي خدمة منفصلة تراقب الصحة والحمل عبر الخدمات، ونقاط نهاية أدوات اختبار الاتصال، وتبلغ عن الأحداث الصحية غير المتوقعة في المجموعة. يمكن أن يساعد ذلك في منع أخطاء قد لا تُكتشف استناداً إلى أداء خدمة واحدة فقط. تعد هيئات المراقبة أيضاً مكاناً جيداً لاستضافة التعليمة البرمجية التي تنفذ إجراءات علاجية لا تتطلب تفاعل المستخدم، مثل تنظيف ملفات السجل في التخزين على فترات زمنية معينة. إذا كنت تريد خدمة هيئة مراقبة SF مفتوحة المصدر مُنفذة بالكامل وتتضمن نموذجاً سهل الاستخدام لقابلية توسيع هيئة المراقبة ويمكن تشغيلها في كل من أنظمة مجموعات Windows وLinux، فراجع مشروع FabricObserver. FabricObserver هو برنامج جاهز للإنتاج. نحن نشجعك على توزيع FabricObserver في أنظمة مجموعات الاختبار والإنتاج الخاصة بك وتوسيعه لتلبية احتياجاتك إما من خلال نموذج المكون الإضافي الخاص بالبرنامج أو عن طريق تفريعه وكتابة مراقبيك المضمنين. النهج الأول (المكونات الإضافية) هو النهج الموصى به.
مراقبة البنية الأساسية (الأداء)
الآن بعد أن قمنا بتغطية التشخيصات في تطبيقك والنظام الأساسي، كيف نعرف أن الأجهزة تعمل كما هو متوقع؟ تُعد مراقبة البنية التحتية الأساسية جزءاً أساسياً من فهم حالة مجموعتك واستخدام الموارد. يعتمد قياس أداء النظام على العديد من العوامل التي يمكن أن تكون ذاتية اعتماداً على أحمال العمل الخاصة بك. عادة ما تُقاس هذه العوامل من خلال عدادات الأداء. يمكن أن تأتي عدادات الأداء هذه من مجموعة متنوعة من المصادر، بما في ذلك نظام التشغيل، أو إطار عمل .NET، أو النظام الأساسي لـ Service Fabric نفسه. بعض السيناريوهات التي ستكون مفيدة فيها هي:
- هل أستخدم جهازي بكفاءة؟ هل تريد استخدام الأجهزة الخاصة بك بنسبة 90٪ CPU أو 10% CPU. يكون هذا مفيداً عند تحجيم مجموعتك، أو تحسين عمليات التطبيق الخاص بك.
- هل يمكنني التنبؤ بمشكلات البنية الأساسية بشكل استباقي؟ - تسبق العديد من المشكلات تغييرات مفاجئة (انخفاضات) في الأداء؛ ولذلك يمكنك استخدام عدادات الأداء مثل إدخال/إخراج الشبكة واستخدام وحدة المعالجة المركزية للتنبؤ بالمشكلات وتشخيصها بشكل استباقي.
يمكن العثور على قائمة بعدادات الأداء التي يجب جمعها على مستوى البنية الأساسية في مقاييس الأداء.
يوفر Service Fabric أيضاً مجموعة من عدادات الأداء لنماذج برمجة الخدمات والجهات الفاعلة الموثوقة. إذا كنت تستخدم أياً من هذين النموذجين، فيمكن لعدادات الأداء هذه الحصول على معلومات للتأكد من أن المستخدمين يقومون بالتشغيل والإيقاف بشكل صحيح، أو أن التعامل مع طلبات الخدمة الموثوقة الخاصة بك يتم بسرعة كافية. لمزيد من المعلومات، راجع المراقبة من أجل خدمة موثوقة عن بعد ومراقبة الأداء للمستخدمين الموثوقين.
حل Azure Monitor لجمعها هو سجلات Azure Monitor تماماً مثل مراقبة مستوى النظام الأساسي. يجب عليك استخدام عامل Log Analytics لجمع عدادات الأداء المناسبة، وعرضها في سجلات Azure Monitor.
الإعداد الموصى به
الآن بعد أن تجاوزنا كل مجال من مجالات المراقبة وسيناريوهات الأمثلة، إليك ملخصاً لأدوات مراقبة Azure والإعداد اللازم لمراقبة جميع المجالات أعلاه.
- مراقبة التطبيق باستخدام Application Insights
- مراقبة نظام مجموعة باستخدام سجلات Diagnostics Agent وسجلات Azure Monitor
- مراقبة البنية الأساسية باستخدام سجلات Azure Monitor
يمكنك أيضاً استخدام وتعديل نموذج قالب ARM الموجود هنا لأتمتة توزيع جميع الموارد والوكلاء الضروريين.
حلول التسجيل الأخرى
على الرغم من أن الحلين اللذين أوصينا بهما، سجلات Azure Monitor وApplication Insights قد تم دمجهما في التكامل مع Service Fabric، إلا أن العديد من الأحداث تتم كتابتها من خلال موفري ETW وهي قابلة للتوسيع مع حلول التسجيل الأخرى. يجب عليك أيضاً النظر في Elastic Stack (خاصة إذا كنت تفكر في تشغيل مجموعة في بيئة غير متصلة بالإنترنت) أو Dynatrace أو أي نظام أساسي آخر تفضله. لدينا قائمة بالشركاء المتكاملين المتاحين هنا.
يجب أن تتضمن النقاط الرئيسية لأي نظام أساسي تختاره مدى ارتياحك لواجهة المستخدم، وقدرات الاستعلام، والتصورات المخصصة ولوحات المعلومات المتاحة، والأدوات الإضافية التي توفرها لتحسين تجربة المراقبة.
الخطوات التالية
- لبدء استخدام أدوات تطبيقاتك، راجع إنشاء الأحداث والسجلات على مستوى التطبيق.
- اتبع الخطوات اللازمة لإعداد Application Insights للتطبيق الخاص بك عن طريق مراقبة وتشخيص تطبيق ASP.NET Core على Service Fabric.
- تعرف على المزيد حول مراقبة النظام الأساسي والأحداث التي يوفرها لك Service Fabric على إنشاء حدث وسجل على مستوى النظام الأساسي.
- تكوين تكامل سجلات Azure Monitor مع Service Fabric: إعداد سجلات Azure Monitor لنظام مجموعة
- تعرف على كيفية إعداد سجلات Azure Monitor لمراقبة الحاويات - المراقبة والتشخيصات لحاويات Windows في Azure Service Fabric.
- راجع أمثلة على مشكلات التشخيص وحلولها باستخدام Service Fabric في تشخيص السيناريوهات الشائعة
- تحقق من منتجات التشخيص الأخرى التي تتكامل مع Service Fabric في شركاء تشخيصات Service Fabric
- تعرف على توصيات المراقبة العامة لموارد Azure - أفضل الممارسات - المراقبة والتشخيص.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ