إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Apache Spark إطار معالجة متوازٍ يدعم المعالجة داخل الذاكرة لتعزيز أداء تطبيقات تحليل البيانات الضخمة. يعد Apache Spark في Azure Synapse Analytics أحد تطبيقات Microsoft لـ Apache Spark في السحابة.
يوفر Azure Synapse الآن القدرة على إنشاء مجموعات Azure Synapse GPU ممكنة لتشغيل أعباء عمل Spark باستخدام مكتبات RAPIDS الأساسية التي تستخدم من قوة المعالجة المتوازية الهائلة لـ GPUs لتسريع المعالجة. يُمكّنك RAPIDS Accelerator لـ Apache Spark من تشغيل تطبيقاتك الحالية من Spark بدون أي تغيير في التعليمات البرمجية بمجرد تمكين إعداد التكوين، والذي يأتي على نحوٍ معدٍّ مسبقًا لمجموعة GPU ممكنة. يمكنك اختيار تشغيل/إيقاف تسريع GPU المستند إلى RAPIDS لأعباء عملك أو أجزاء منه عن طريق إعداد هذا التكوين:
spark.conf.set('spark.rapids.sql.enabled','true/false')
إشعار
تم الآن إهمال معاينة التجمعات الممكنة ل Azure Synapse GPU.
RAPIDS Accelerator لـ Apache Spark
مسرع Spark RAPIDS هو مكون إضافي يعمل من خلال تجاوز الخطة الفعلية لوظيفة Spark من خلال عمليات GPU المدعومة وتشغيل هذه العمليات على GPUs، وبالتالي تسريع المعالجة. هذه المكتبة حاليا في المعاينة، ولا تدعم كافة عمليات Spark (إليك قائمة بعوامل التشغيل المدعومة حاليا، ويجري الآن إضافة المزيد من الدعم بشكل مطرد من خلال الإصدارات الجديدة).
خيارات تكوين الكتلة
يدعم المكون الإضافي لـRAPIDS Accelerator فقط تعيينًا واحد إلى واحد بين GPUs والمنفذين. وهو ما يعني أن وظيفة Spark ستحتاج إلى طلب موارد المنفذ وبرنامج التشغيل التي يمكن استيعابها بواسطة موارد المجموعة (وفقا لعدد GPUs المتاح ونوى وحدة المعالجة المركزية). من أجل تلبية هذا الشرط وضمان الاستخدام الأمثل لجميع موارد المجموعة، سنحتاج إلى التكوين التالي من برامج التشغيل والمنفذين لتطبيق Spark والذي يتعين أن يعمل على مجموعات GPU الممكنة.
| حجم المجموعة | خيارات حجم برنامج التشغيل | برامج التشغيل الأساسية | ذاكرة برنامج التشغيل (GB) | النوى المنفذة | ذاكرة المنفذ (GB) | عدد المنفذين |
|---|---|---|---|---|---|---|
| GPU-Large | برنامج تشغيل صغير | 4 | 30 | 12 | 60 | عدد العقد في المجموعة |
| GPU-Large | برنامج تشغيل متوسط | 7 | 30 | 9 | 60 | عدد العقد في المجموعة |
| GPU-XLarge | برنامج تشغيل متوسط | 8 | 40 | 14 | 80 | 4 * عدد العقد في المجموعة |
| GPU-XLarge | برنامج تشغيل كبير | 12 | 40 | 13 | 80 | 4 * عدد العقد في المجموعة |
لن يُقبل أي عبء عمل لا يفي بأحد التكوينات أعلاه. يتم ذلك للتأكد من تشغيل مهام Spark باستخدام التكوين الأكثر كفاءةً وأداءً بالاستفادة من كافة الموارد المتوفرة على المجموعة.
يمكن للمستخدمين تعيين التكوين أعلاه من خلال أعباء العمل. بالنسبة لأجهزة الكمبيوتر المحمولة، يمكن للمستخدم استخدام %%configure الأمر السحري لتعيين أحد التكوينات أعلاه كما هو موضح أدناه.
على سبيل المثال، باستخدام تجمع كبير مع ثلاث عقد:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
تشغيل عينة من مهام Spark من خلال دفتر ملاحظات على تجمع Azure Synapse GPU المعجل
سيكون من الجيد أن تكون على دراية بالمفاهيم الأساسية لكيفية استخدام دفتر الملاحظات في Azure Synapse Analytics قبل المتابعة في هذا القسم. دعونا نسير من خلال الخطوات لتشغيل تطبيق Spark باستخدام تسريع وحدة معالجة الرسومات. يمكنك كتابة تطبيق Spark بجميع اللغات الأربعة المدعومة داخل Synapse وPySpark (Python) وSpark (Scala) و SparkSQL و.NET لـ Spark (C#).
إنشاء تجمع ممكن لوحدة معالجة الرسومات.
أنشئ دفتر الملاحظات وأرفقه بمجموعة GPU الممكنة التي أنشأتها في الخطوة الأولى.
عّين التكوينات كما هو موضح في المقطع السابق.
أنشيء نموذج إطار بيانات عن طريق نسخ التعليمات البرمجية أدناه في الخلية الأولى من دفتر الملاحظات:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- الآن دعونا نفعل المجموع عن طريق الحصول على الحد الأقصى للراتب لكل معرف القسم وعرض النتيجة:
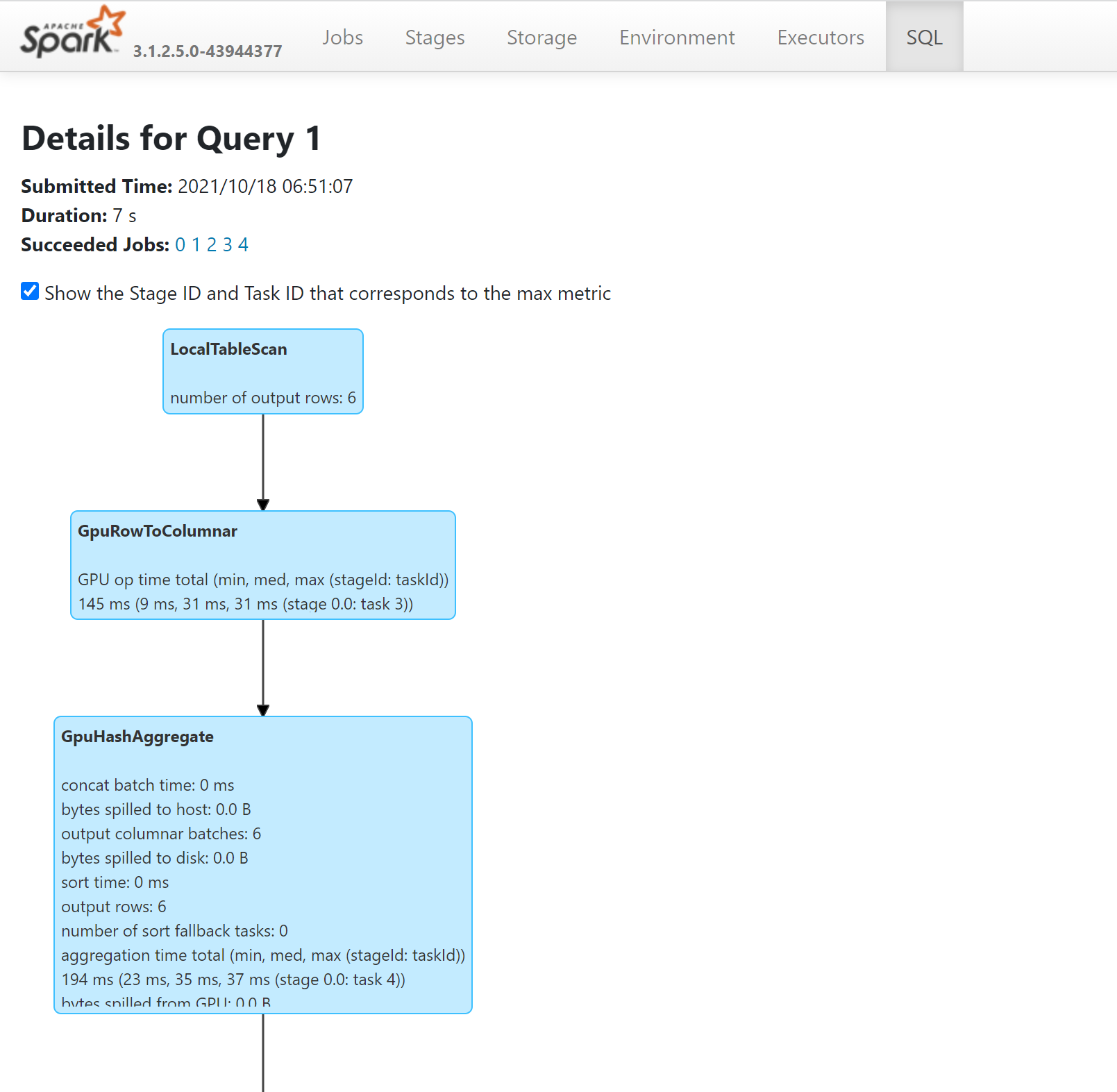
- يمكنك مشاهدة العمليات في الاستعلام الخاص بك التي تم تشغيلها على وحدات معالجة الرسومات من خلال النظر في خطة SQL من خلال Spark History Server:
كيفية ضبط تطبيقك لـ GPUs
يمكن لمعظم وظائف Spark رؤية أداءٍ محسنٍ من خلال ضبط إعدادات التكوين من الإعدادات الافتراضية، وينطبق الشيء نفسه على الوظائف التي تستفيد من المكون الإضافي لمسرع RAPIDS لـ Apache Spark.
الحصص النسبية وقيود الموارد في مجموعات Azure Synapse التي تدعم GPU
مستوى مساحة العمل
تأتي كل مساحة عمل في Azure Synapse مع حصة افتراضية قدرها 50 GPU vCores. لزيادة الحصة النسبية لذاكرة GPU الأساسية، يرجى إرسال طلب دعم من خلال مدخل Microsoft Azure.