البرنامج التعليمي: إنشاء تطبيق Apache Spark باستخدام IntelliJ باستخدام مساحة عمل Synapse
يوضح لك هذا البرنامج التعليمي كيفية استخدام Azure Toolkit للمكون الإضافي IntelliJ لتطوير تطبيقات Apache Spark، والتي تمت كتابتها في Scala، ثم إرسالها إلى تجمع Apache Spark بدون خادم مباشرةً من بيئة التطوير المتكاملة IntelliJ (IDE). يمكنك استخدام المكون الإضافي بعدة طرق:
- قم بتطوير وتقديم تطبيق Scala Spark على تجمع Spark.
- الوصول إلى موارد مجمعات Spark الخاصة بك.
- قم بتطوير وتشغيل تطبيق Scala Spark محليًا.
في هذا البرنامج التعليمي، تتعلم كيفية:
- استخدام Azure Toolkit للمكون الإضافي IntelliJ
- تطوير تطبيقات Apache Spark
- إرسال طلب إلى تجمعات Spark
المتطلبات الأساسية
إضافة Azure toolkit 3.27.0-2019.2 - التثبيت من مستودع IntelliJ Plugin
Scala Plugin - التثبيت من مستودع IntelliJ Plugin
الشرط التالي مخصص فقط لمستخدمي Windows:
أثناء تشغيل تطبيق Spark Scala المحلي على كمبيوتر Windows، قد تحصل على استثناء، كما هو موضح في SPARK-2356. يحدث الاستثناء لأن WinUtils.exe مفقود في Windows. لحل هذا الخطأ، قم بتنزيل WinUtils القابل للتنفيذ إلى موقع مثل C:\WinUtils\bin. ثم قم بإضافة متغير البيئة HADOOP_HOMEثم تعيين قيمة المتغير إلى C:\WinUtils.
إنشاء تطبيق Spark Scala لتجمع Spark
ابدأ تشغيل IntelliJ IDEA، وحدد "Create New Project" لفتح نافذة "New Project".
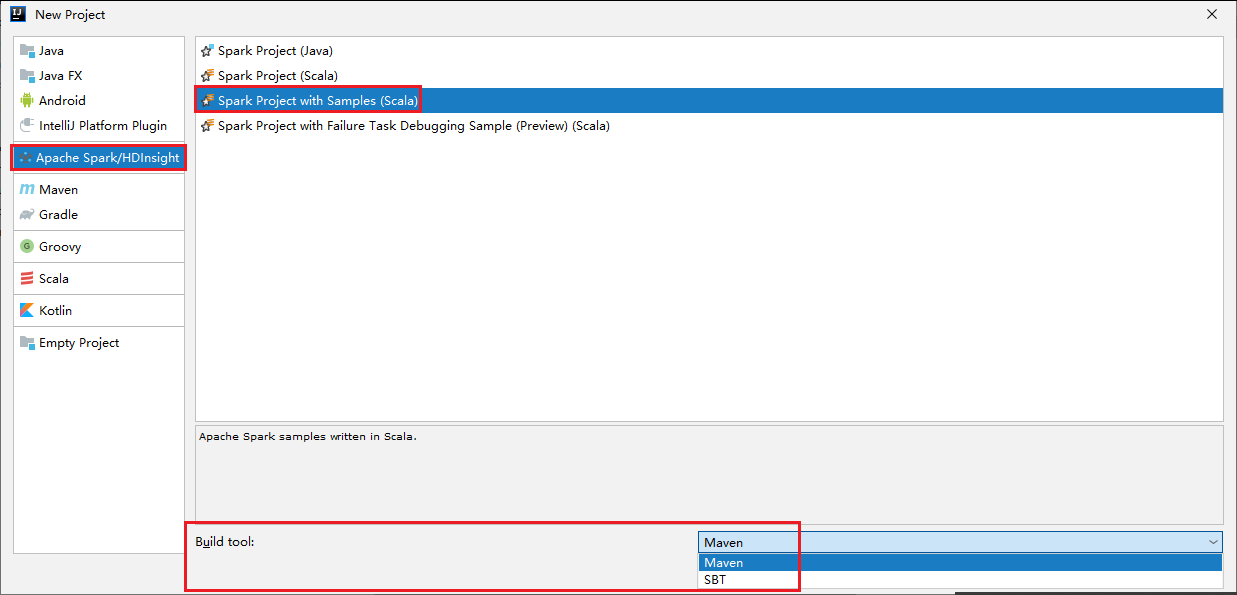
حدد Apache Spark/HDInsight من الجزء الأيمن.
حدد Spark Project with Samples (Scala) من النافذة الرئيسية.
من القائمة المنسدلة إنشاء أداة حدد أحد الأنواع التالية:
- Maven لدعم معالج إنشاء مشروع Scala.
- SBT لإدارة التبعيات والبناء لمشروع project.
حدد التالي.
في إطار المشروع الجديد وفر المعلومات التالية:
الخاصية الوصف اسم المشروع أدخل اسمًا. يستخدم هذا البرنامج التعليمي myApp.موقع المشروع أدخل الموقع المطلوب لحفظ المشروع. مشروع SDK قد يكون هذا الحقل فارغاً في أول استخدام لـ IDEA. حدد جديد... وانتقل إلى JDK. إصدار Spark يدمج معالج الإنشاء الإصدار المناسب لـSpark SDK و Scala SDK. هنا يمكنك اختيار إصدار Spark الذي تحتاجه. 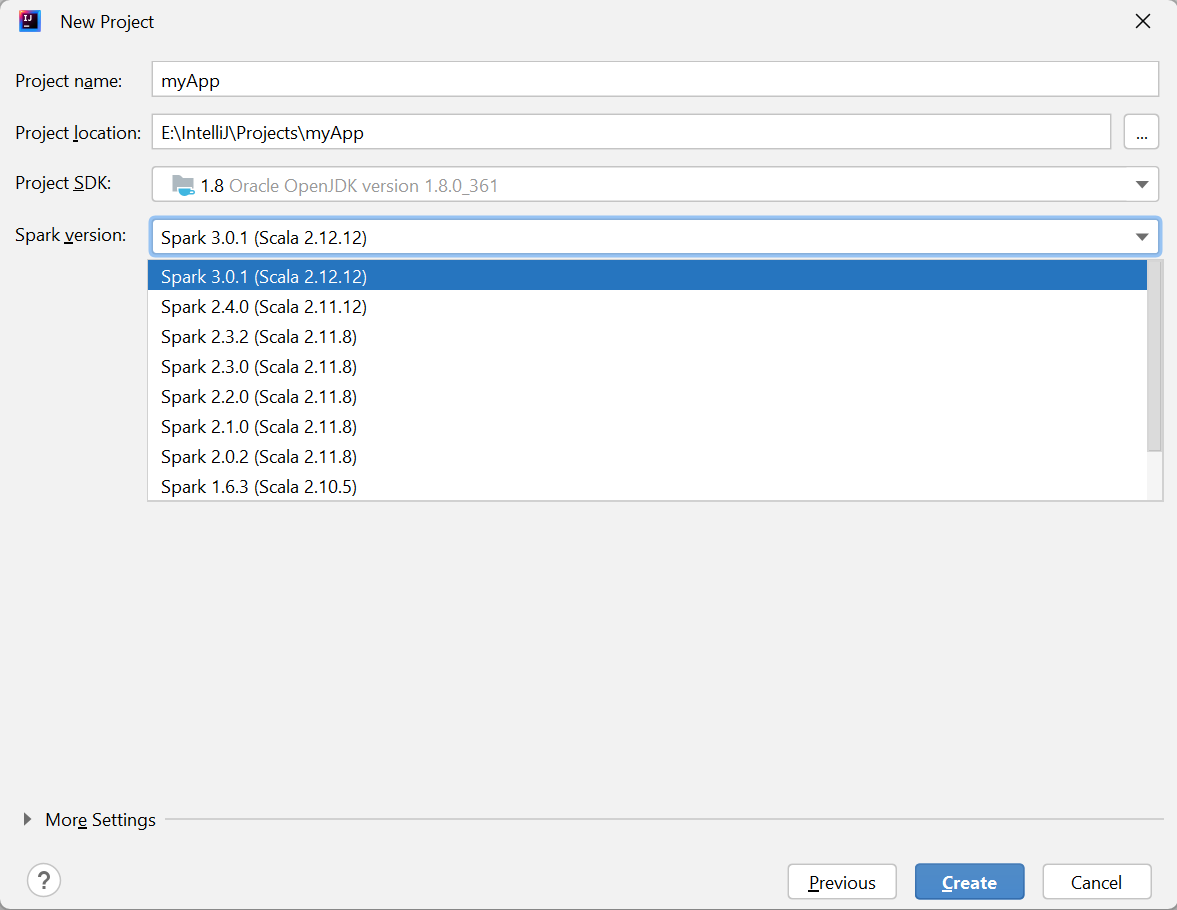
حدد إنهاء. قد يستغرق الأمر بضع دقائق قبل أن يصبح المشروع متاحًا.
يقوم مشروع Spark تلقائيًا بإنشاء أداة لك. لعرض الأداة، قم بإجراء التشغيل التالي:
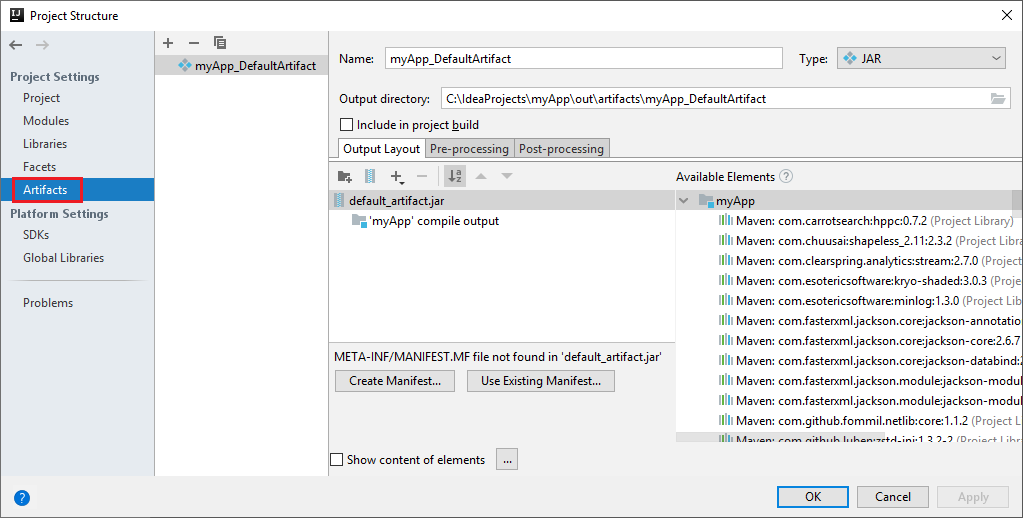
أ. من شريط القائمة، انتقل إلى >Project Structure....
ب. من نافذة Project Structure، حدد Artifacts.
جـ. حدد Cancel بعد عرض الأداة.
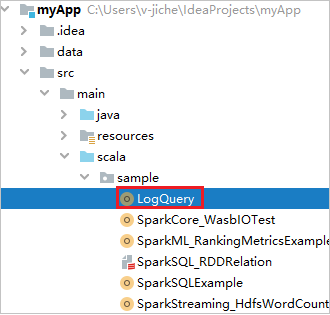
ابحث عن LogQuery في myApp>src>main>scala>sample>LogQuery. يستخدم هذا البرنامج التعليمي LogQuery للتشغيل.
الاتصال بتجمع Spark الخاص بك
سجل الدخول إلى اشتراك Azure للاتصال بتجمعات Spark.
تسجيل الدخول إلى اشتراك Azure الخاص بك
من شريط القوائم، انتقل إلى View>Tool Windows >Azure Explorer.
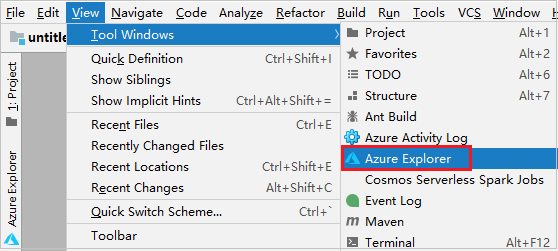
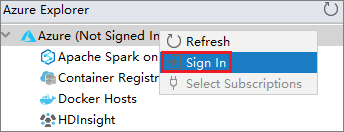
من مستكشف Azure، انقر بزر الماوس الأيمن فوق عقدة Azure، ثم حدد Sign In.
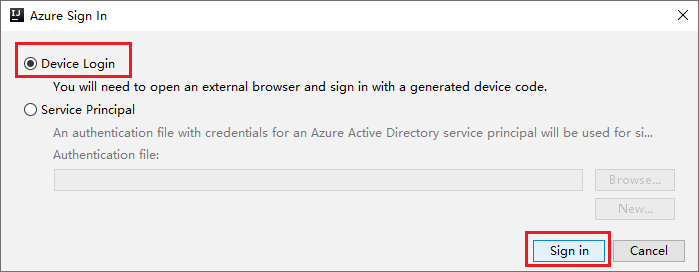
في مربع الحوار Azure Sign In، اختر Device Login،ثم حدد Sign in.
في مربع الحوار Azure Device Login، حددCopy&Open.
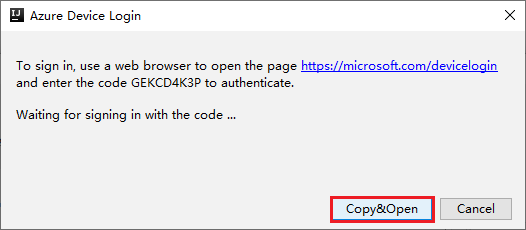
في واجهة المستعرض، قم بلصق التعليمات البرمجية، ثم حدد Next.
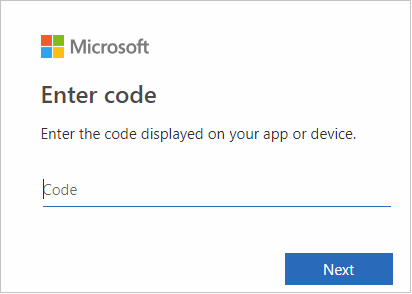
أدخل بيانات اعتماد Azure، ثم أغلق المستعرض.
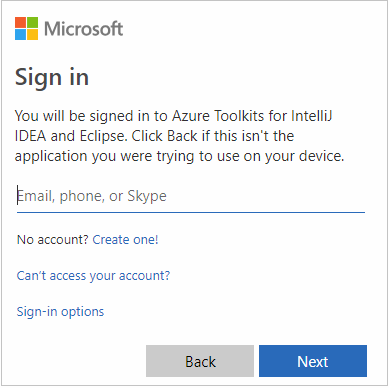
بعد تسجيل الدخول، يسرد مربع الحوار Select Subscriptions كافة اشتراكات Azure المقترنة ببيانات الاعتماد. حدد الاشتراك، ثم حدد Select.
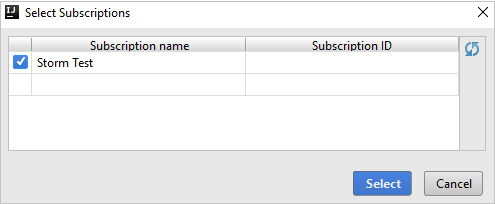
من Azure Explorer، قم بتوسيع Apache Spark على Synapse لعرض مساحات العمل الموجودة في اشتراكاتك.
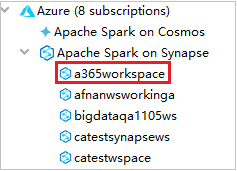
لعرض تجمعات Spark، يمكنك توسيع مساحة العمل بشكل أكبر.
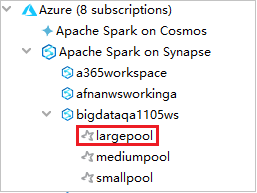
عن بُعد قم بتشغيل تطبيق Spark Scala على تجمع Spark
بعد إنشاء تطبيق Scala، يمكنك تشغيله عن بُعد.
افتح نافذة Run/Debug Configurations عن طريق تحديد الرمز.
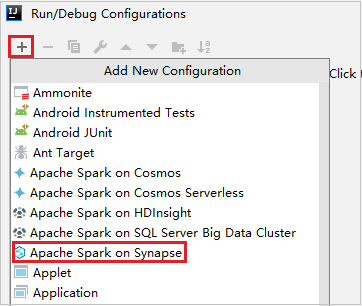
في نافذة الحوار Run/Debug Configurations، حدد +، ثم حدد Apache Spark على Synapse.
في نافذة Run/Debug Configurations، قم بتوفير القيم التالية ثم حدد OK:
الخاصية القيمة تجمعات Spark حدد تجمعات Spark التي تريد تشغيل التطبيق عليها. تحديد أداة للتقديم اترك الإعداد الافتراضي. اسم الفئة الرئيسية القيمة الافتراضية هي الفئة الرئيسية من الملف المحدد. يمكنك تغيير الفئة عن طريق تحديد القطع الناقص(...) واختيار فئة أخرى. تكوينات الوظيفة يمكنك تغيير المفتاح الافتراضي والقيم. لمزيد من المعلومات، راجع Apache Livy REST API. وسيطات سطر الأوامر يمكنك إدخال وسيطات مفصولة بمسافة للفئة الرئيسية إذا لزم الأمر. الجرار والملفات المشار إليها يمكنك إدخال مسارات الجرار المشار إليها والملفات إن وجدت. يمكنك أيضًا استعراض الملفات في نظام الملفات الظاهري Azure الذي يدعم حاليًا فقط نظام المجموعة ADLS Gen2. لمزيدٍ من المعلومات: تكوين Apache Spark و كيفية تحميل الموارد إلى نظام المجموعة. تخزين تحميل الوظيفة قم بالتوسيع للكشف عن خيارات إضافية. نوع التخزين حدد Use Azure Blob للتحميل أو Use cluster default storage account للتحميل من القائمة المنسدلة. حساب التخزين أدخل حساب التخزين الخاص بك. مفتاح التخزين أدخل مفتاح التخزين. حاوية التخزين حدد حاوية التخزين من القائمة المنسدلة بمجرد إدخال حساب التخزينومفتاح التخزين. 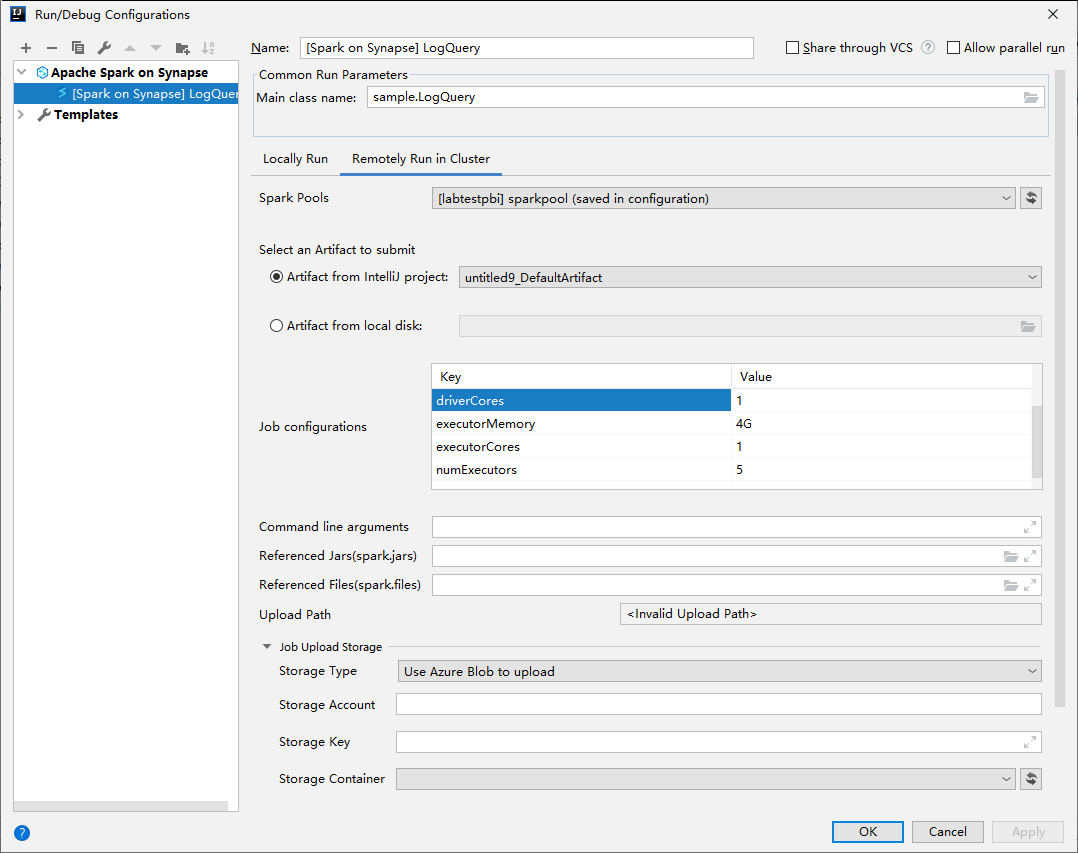
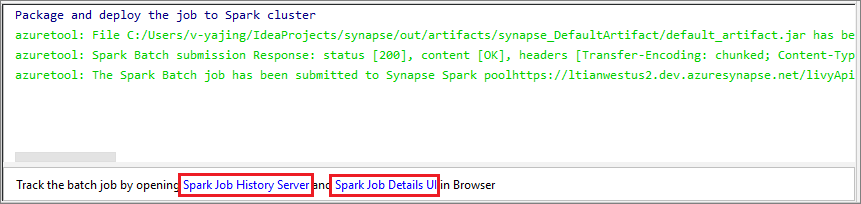
حدد زر SparkJobRun لإرسال المشروع إلى تجمع Apache Spark المحدد. تعرض علامة التبويب Remote Spark Job in Cluster تقدم تنفيذ المهمة في الأسفل. يمكنك إيقاف التطبيق عن طريق تحديد الزر الأحمر.

تشغيل/تصحيح تطبيقات Apache Spark المحلية
يمكنك اتباع الإرشادات أدناه لإعداد التشغيل المحلي والتصحيح المحلي لوظيفة Apache Spark.
السيناريو 1: قم بالتشغيل المحلي
افتح مربع الحوار Run/Debug Configurations، حدد علامة الجمع ( + ). ثم حدد خيار Apache Spark on Synapse. أدخل معلومات عن الاسمواسم الفئة الرئيسية لحفظها.
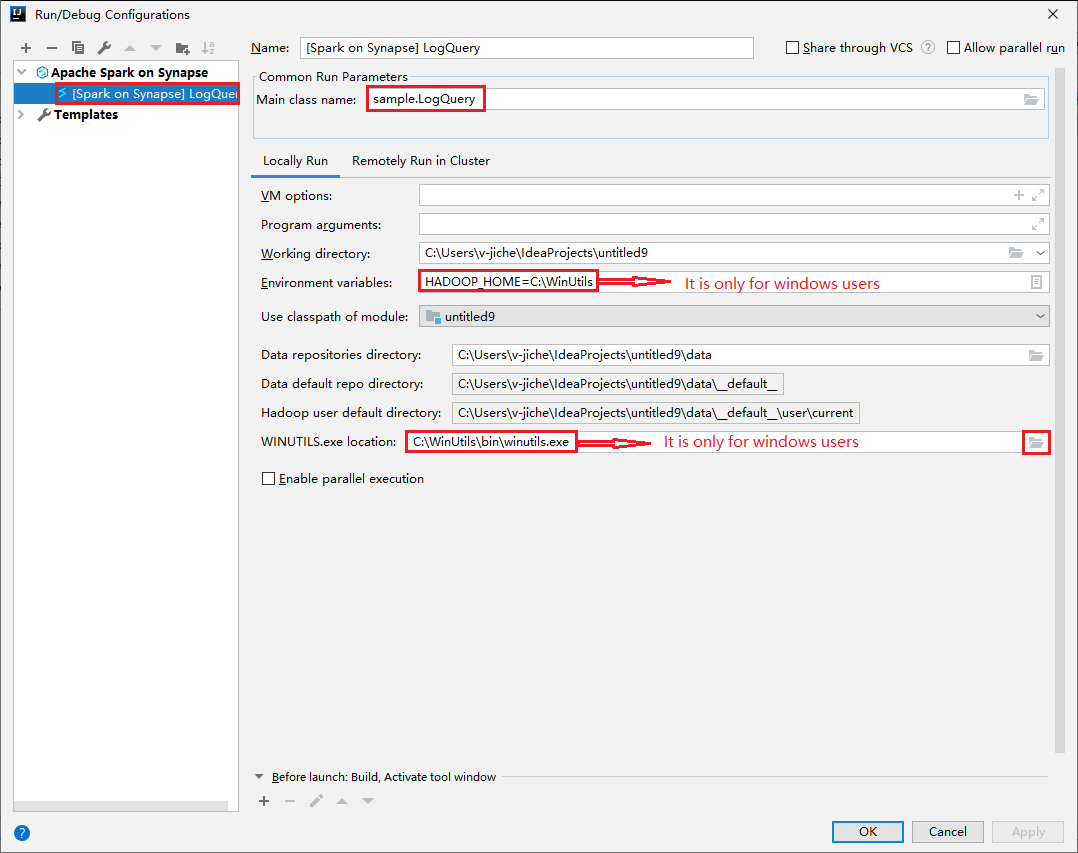
- متغيرات البيئة وموقع WinUtils.exe مخصصة فقط لمستخدمي windows.
- متغيرات البيئة: يمكن اكتشاف متغير بيئة النظام تلقائيًا إذا كنت قد قمت بتعيينه من قبل ولا داعي للإضافة يدويًا.
- WinUtils.exe الموقع: يمكنك تحديد موقع WinUtils عن طريق تحديد رمز المجلد على اليمين.
ثم حدد زر التشغيل المحلي.

بمجرد الانتهاء من التشغيل المحلي، إذا كان البرنامج النصي يتضمن الإخراج، يمكنك التحقق من ملف الإخراج من البيانات>الافتراضية.
السيناريو 2: إجراء التصحيح المحلي
افتح البرنامج النصي LogQuery تعيين نقاط التوقف.
حدد رمز التصحيح المحلي للقيام بتصحيح الأخطاء المحلي.

الوصول إلى مساحة عمل Synapse وإدارتها
يمكنك إجراء عمليات مختلفة في Azure Explorer داخل Azure Toolkit لـ IntelliJ. من شريط القوائم، انتقل إلى View>Tool Windows >Azure Explorer.
إطلاق مساحة عمل
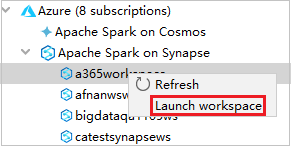
من مستكشف Azure، انتقل إلى Apache Spark on Synapse،ثم قم بتوسيعه.
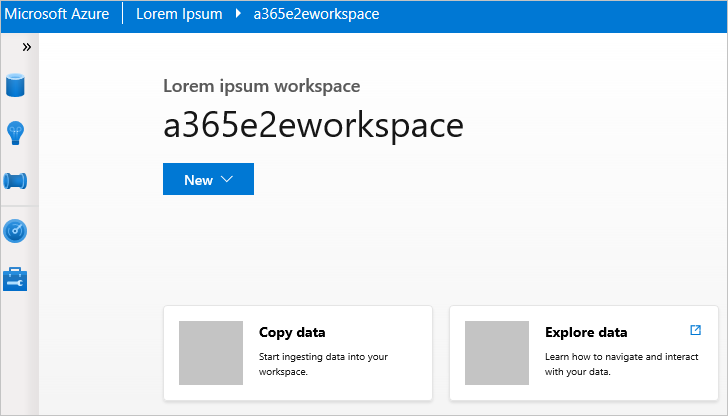
انقر بزر الماوس الأيمن فوق مساحة عمل، ثم حدد Launch workspace، وسيتم فتح موقع ويب.
وحدة تحكم Spark
يمكنك تشغيل وحدة التحكم المحلية Spark (Scala) أو تشغيل وحدة تحكم جلسة العمل التفاعلية Spark Livy (Scala).
وحدة Spark المحلية (Scala)
تأكد من استيفاء شرط WINUTILS.EXE الأساسي.
من شريط القوائم، انتقل إلى Run>Edit Configurations....
من نافذة Run/Debug Configurations، في الجزء الأيسر، انتقل إلى Apache Spark on Synapse>[Spark on Synapse] myApp.
من الإطار الرئيسي، حدد علامة التبويب Locally Run.
قم بتوفير القيم التالية، ثم حدد OK:
الخاصية القيمة متغيرات البيئة تأكد من صحة قيمة HADOOP_HOME. موقع WINUTILS.exe تأكد من صحة المسار. 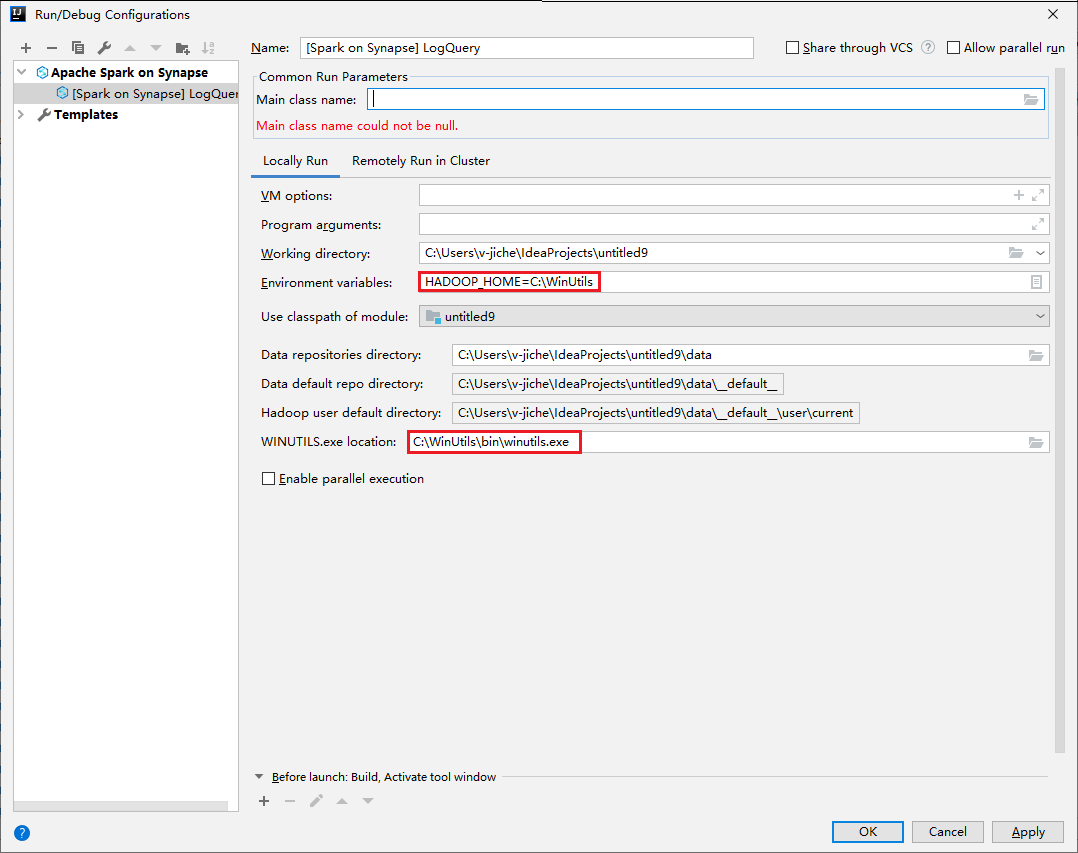
من Project، انتقل إلى myApp>src>الرئيسية>scala>myApp.
من شريط القوائم، انتقل إلى Tools>Spark console>Run Spark Local Console(Scala).
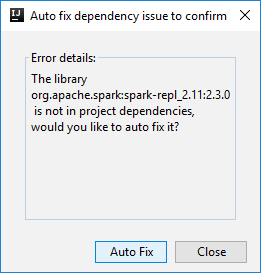
ثم قد يتم عرض مربعي حوار لسؤالك عما إذا كنت تريد إصلاح التبعيات تلقائيًا. إذا كان الأمر كذلك، حدد Auto Fix.
يجب أن تبدو وحدة التحكم مشابهة للصورة أدناه. في نوع إطار وحدة التحكم
sc.appName، ثم اضغط ctrl+Enter. سيتم عرض النتيجة. يمكنك إيقاف وحدة التحكم المحلية عن طريق تحديد الزر الأحمر.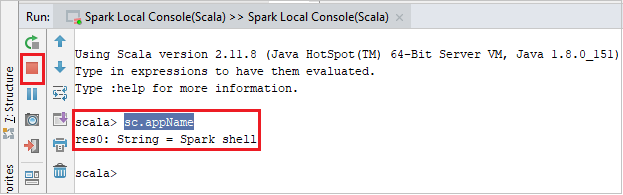
وحدة التحكم في الجلسة التفاعلية Spark Livy (Scala)
يتم دعمه فقط على IntelliJ 2018.2 و2018.3.
من شريط القوائم، انتقل إلى Run>Edit Configurations....
من نافذة Run/Debug Configurations، في الجزء الأيسر، انتقل إلى Apache Spark on Synapse>[Spark on Synapse] myApp.
من الإطار الرئيسي، حدد علامة التبويب Remotely Run in Cluster.
قم بتوفير القيم التالية، ثم حدد OK:
الخاصية القيمة اسم الفئة الرئيسية حدد اسم الفئة الرئيسية. تجمعات Spark حدد تجمعات Spark التي تريد تشغيل التطبيق عليها. 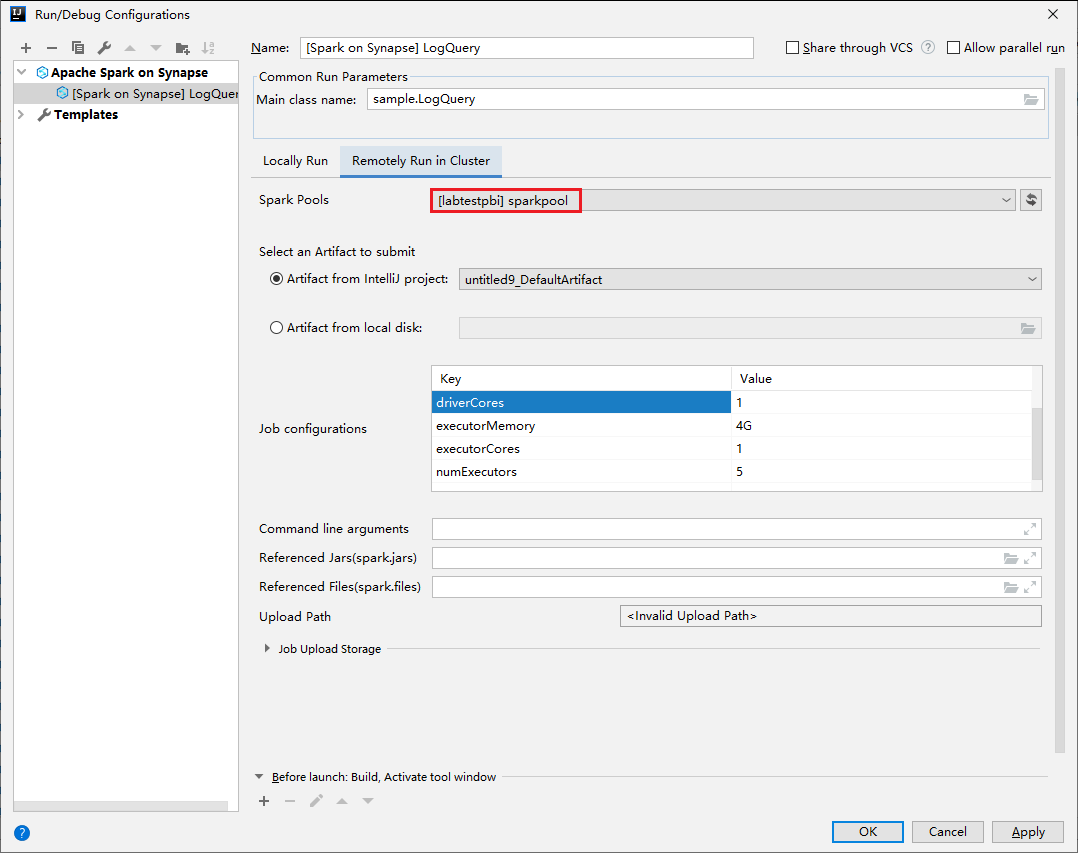
من Project، انتقل إلى myApp>src>الرئيسية>scala>myApp.
من شريط القوائم، انتقل إلى Tools>Spark console>Run Spark Livy Interactive Session Console(Scala).
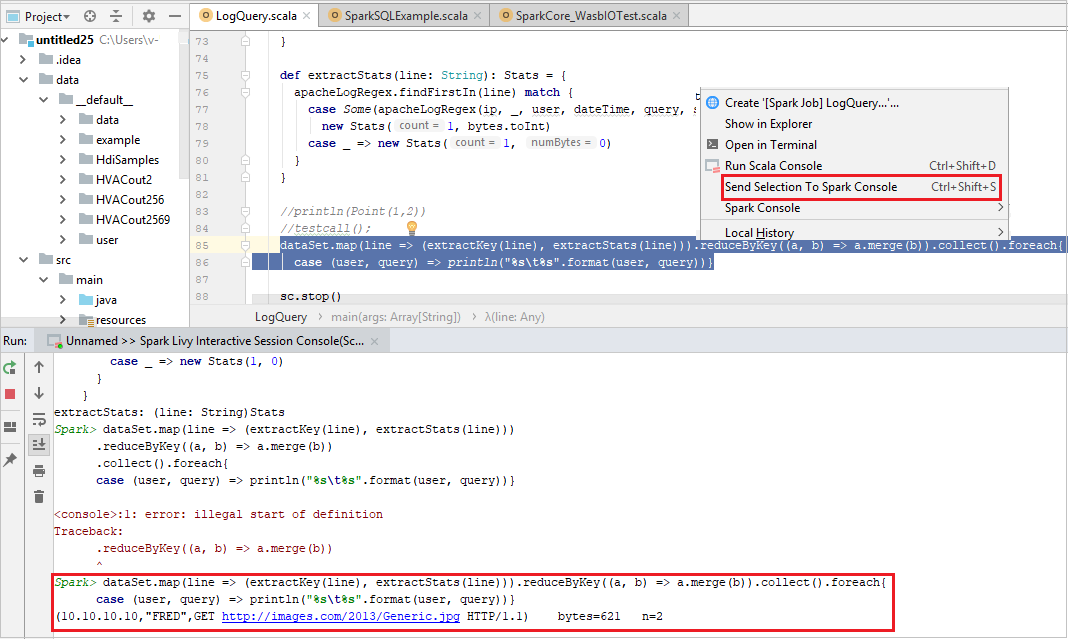
يجب أن تبدو وحدة التحكم مشابهة للصورة أدناه. في نوع إطار وحدة التحكم
sc.appName، ثم اضغط ctrl+Enter. سيتم عرض النتيجة. يمكنك إيقاف وحدة التحكم المحلية عن طريق تحديد الزر الأحمر.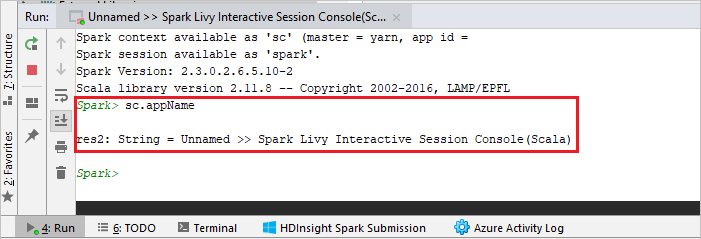
إرسال التحديد إلى وحدة تحكم Spark
قد ترغب في رؤية نتيجة البرنامج النصي عن طريق إرسال بعض التعليمات البرمجية إلى وحدة التحكم المحلية أو وحدة التحكم Livy Interactive Session Console(Scala). للقيام بذلك، يمكنك تمييز بعض التعليمات البرمجية في ملف Scala، ثم النقر بزر الماوس الأيمن فوق Send Selection To Spark console. سيتم إرسال الرمز المحدد إلى وحدة التحكم وتنتهي. سيتم عرض النتيجة بعد التعليمات البرمجية في وحدة التحكم. ستتحقق وحدة التحكم من الأخطاء الموجودة.