Премахване на дубликати във всяка таблица за обединяване на данни
Правилата за дедупликация стъпката на обединяване намира и премахва дублиращи се записи за клиент от таблица източник, така че всеки клиент да е представен от един ред във всяка таблица. Всяка таблица се дедуплицира отделно, като се използват правила за идентифициране на записите за даден клиент.
Правилата се обработват по ред. След като всички правила са изпълнени за всички записи в таблица, групите съвпадения, които споделят общ ред, се комбинират в една група за съвпадение.
Дефиниране на правила за дедубликация
Доброто правило идентифицира уникален клиент. Помислете за вашите данни. Може да е достатъчно да идентифицирате клиентите въз основа на поле като имейл. Въпреки това, ако искате да разграничите клиентите, които споделят имейл, може да изберете правило с две условия, съвпадение на имейл + собствено име. За повече информация вижте Най-добри практики за дедупликация.
На страницата Правила за дедупликация изберете таблица и изберете Добавяне на правило , за да дефинирате правилата за дедупликация.
Съвет
Ако сте обогатили таблици на ниво източник на данни, за да подобрите резултатите от обединяването, изберете Използване на обогатени таблици в горната част на страницата. За повече информация вижте Обогатяване за източници на данни.

В екрана Добавяне на правило въведете следната информация:
Изберете поле: Изберете от списъка с налични полета от таблицата, които искате да проверите за дубликати. Изберете полета, които вероятно са уникални за всеки отделен клиент. Например имейл адрес или комбинацията от име, град и телефонен номер.
Нормализиране: Изберете опции за нормализиране на колоната. Нормализирането засяга само стъпката на съвпадение и не променя данните.
- Числа: Преобразува Unicode символите, които представляват числа, в прости числа.
- Символи: Премахва символи и специални символи като !" #$%&'()*+,-./:;<=>?@[]^_'{|}~. Например, Head&Shoulder става HeadShoulder.
- Текст в малки букви: Преобразува главните букви в малки букви. "ВСИЧКИ главни букви и заглавие" стават "всички главни букви и главни букви".
- Тип (телефон, име, адрес, организация): Стандартизира имена, длъжности, телефонни номера и адреси.
- Unicode в ASCII: Преобразува Unicode знаците в техния ASCII буквен еквивалент. Например, удареното ề се преобразува в символа e.
- Празно пространство: Премахва всички интервали. Hello World става HelloWorld.
- Съпоставяне на псевдоними: Позволява ви да качите персонализиран списък с двойки низове, за да посочите низове, които винаги трябва да се считат за точно съвпадение.
- Персонализирано заобикаляне: Позволява ви да качите персонализиран списък с низове, за да посочите низове, които никога не трябва да се съвпадат.
Прецизност: Задайте нивото на прецизност. Прецизността се използва за точно съвпадение и размито съвпадение и определя колко близки трябва да бъдат два низа, за да се считат за съвпадение.
- Основен: Изберете от ниско (30%), средно (60%), високо (80%) и точно (100%). Изберете Точен , за да съпоставите само записи, които съвпадат на 100 процента.
- По избор: Задайте процент, който записите трябва да съвпадат. Системата съвпада само със записи, преминаващи този праг.
Име: Име на правилото.
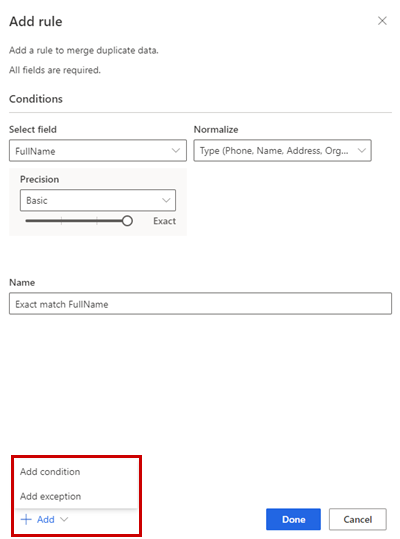
По желание изберете Добавяне>на условие за добавяне, за да добавите още условия към правилото. Условията са свързани с логически оператор И и по този начин се изпълняват само ако са изпълнени всички условия.
По желание, добавете>Добавяне на изключение , за да добавите изключения към правилото. Изключенията се използват за справяне с редки случаи на фалшиви положителни и фалшиви отрицателни резултати.
Изберете Готово , за да създадете правилото.
По желание добавете още правила.
Изберете таблица и след това Редактиране на предпочитанията за обединяване.
В екрана Предпочитания за обединяване:
Изберете една от трите опции, за да определите кой запис да запазите, ако бъде намерен дубликат:
- Най-запълнени: Идентифицира записа с най-много попълнени колони като запис на победител. Това е опцията за сливане по подразбиране.
- Най-скорошен: Идентифицира записа на победителя въз основа на най-скорошността. Изисква дата или числово поле за определяне на скоростта.
- Най-скорошен: Идентифицира записа на победителя въз основа на най-малката скорошност. Изисква дата или числово поле за определяне на скоростта.
Ако има равенство, записът на победителя е този с MAX(PK) или по-голямата стойност на първичния ключ.
По желание, за да дефинирате предпочитанията за обединяване на отделни колони на таблица, изберете Разширени в долната част на екрана. Например можете да изберете да запазите най-новия имейл И най-пълния адрес от различни записи. Разгънете таблицата, за да видите всичките й колони и определете коя опция да използвате за отделни колони. Ако изберете опция, базирана на актуалност, трябва също да зададете поле за дата/час, което определя актуалността.
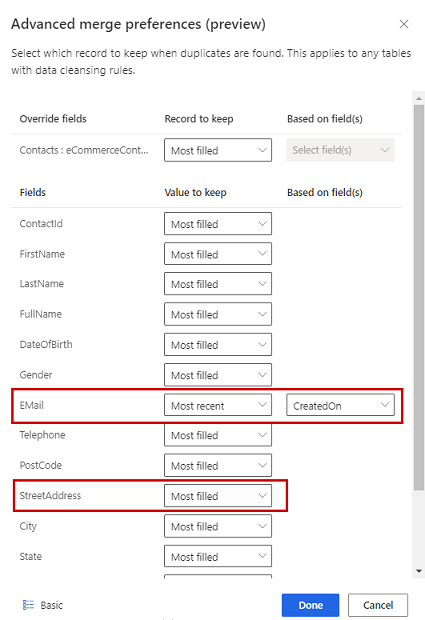
Изберете Готово , за да приложите предпочитанията си за обединяване.
След като дефинирате правилата за дедупликация и предпочитанията за обединяване, изберете Напред.
