¿Qué es Image Analysis?
El servicio Visión de Azure AI puede extraer una gran variedad de características visuales de sus imágenes. Por ejemplo, puede determinar si una imagen tiene contenido para adultos, buscar marcas u objetos específicos o buscar rostros humanos.
La versión más reciente de Image Analysis, la 4.0, que ya tiene disponibilidad general, tiene nuevas características, como el OCR sincrónico y la detección de personas. Recomendamos utilizar esta versión en adelante.
Puede usar Image Analysis en la aplicación mediante el uso de un SDK de biblioteca cliente o invocar la API REST directamente. Siga el inicio rápido para comenzar.
O puede probar las funcionalidades de Image Analysis de forma rápida y sencilla en el explorador mediante Vision Studio.
Esta documentación contiene los siguientes tipos de artículos:
- Los inicios rápidos son instrucciones paso a paso que permiten realizar llamadas al servicio y obtener los resultados en un breve período de tiempo.
- Las guías paso a paso contienen instrucciones para usar el servicio de maneras más específicas o personalizadas.
- Los artículos conceptuales proporcionan explicaciones detalladas de la funcionalidad y las características del servicio.
Para un enfoque más estructurado, siga un módulo de Training para Image Analysis.
Versiones de Image Analysis
Importante
Seleccione la versión de la API de Image Analysis que mejor se adapte a sus requisitos.
| Versión | Características disponibles | Recomendación |
|---|---|---|
| versión 4.0 | Leer texto, subtítulos, subtítulos densos, etiquetas, detección de objetos, clasificación de imágenes personalizadas/detección de objetos, personas, recorte inteligente | Mejores modelos; use la versión 4.0 si es compatible con su caso de uso. |
| versión 3.2 | Etiquetas, objetos, descripciones, marcas, caras, tipo de imagen, gama de colores, lugares emblemáticos, celebridades, contenido para adultos, recorte inteligente | Gama de características más amplia; use la versión 3.2 si su caso de uso aún no es compatible con la versión 4.0 |
Se recomienda usar la API de Image Analysis 4.0 si es compatible con su caso de uso. Use la versión 3.2 si su caso de uso aún no es compatible con la versión 4.0.
También deberá usar la versión 3.2 si quiere hacer subtítulos de imagen y el recurso de Vision está fuera de las regiones de Azure admitidas. La característica de título de imagen de Image Analysis 4.0 solo se admite en determinadas regiones de Azure. El subtitulado de imágenes de la versión 3.2 está disponible en todas las regiones de Visión de Azure AI. Consulte Disponibilidad de la región.
Analyze Image
Puede analizar imágenes para detectar y proporcionar información detallada acerca de las características y funciones visuales. Todas las características de esta tabla son proporcionadas por la API Analyze Image. Siga un inicio rápido para comenzar.
| Nombre | Descripción | Página Concepto |
|---|---|---|
| Personalización de modelos (solo en la versión preliminar v4.0, en desuso) | Puede crear y entrenar modelos personalizados para realizar la clasificación de imágenes o la detección de objetos. Traiga sus propias imágenes, etiquételas con etiquetas personalizadas e Image Analysis entrena un modelo personalizado para su caso de uso. | Personalización de modelos |
| Lectura de texto de imágenes (solo v4.0) | La versión preliminar 4.0 de Image Analysis ofrece la posibilidad de extraer texto legible de imágenes. En comparación con la API de lectura asincrónica Computer Vision 3.2, la nueva versión ofrece el conocido motor Read OCR en una API sincrónica unificada de rendimiento mejorado que facilita la obtención de OCR junto con otras conclusiones en una sola llamada API. | OCR para imágenes |
| Detección de personas en imágenes (solo v4.0) | La versión 4.0 de Image Analysis ofrece la capacidad de detectar personas que aparecen en imágenes. Se devuelven las coordenadas del rectángulo delimitador de cada persona detectada, junto con una puntuación de confianza. | Detección de personas |
| Subtitulado de imágenes | Genere una descripción de una imagen en lenguaje legible por cualquier persona, con frases completas. Los algoritmos de Computer Vision generan varios subtítulos en función de los objetos identificados en la imagen. El modelo de subtitulado de imágenes de la versión 4.0 es una implementación más avanzada y funciona con una gama más amplia de imágenes de entrada. Solo está disponible en determinadas regiones geográficas. Consulte Disponibilidad de la región. La versión 4.0 también permite usar descripción densa, que genera subtítulos detallados para objetos individuales que se encuentran en la imagen. La API devuelve las coordenadas del rectángulo delimitador (en píxeles) de cada objeto que se encuentra en la imagen, además de un título. Puede usar esta funcionalidad para generar descripciones de partes independientes de una imagen. 
|
Generación de subtitulado de imágenes (v3.2) (v4.0) |
| Detección de objetos | La detección de objetos es similar al etiquetado, pero la API devuelve las coordenadas del rectángulo delimitador para cada etiqueta aplicada. Por ejemplo, si una imagen contiene un perro, un gato y una persona, la operación de detección muestra estos objetos junto con sus coordenadas en la imagen. Puede usar esta funcionalidad para procesar más las relaciones entre los objetos de una imagen. También permite saber cuando hay varias instancias de la misma etiqueta en una imagen. 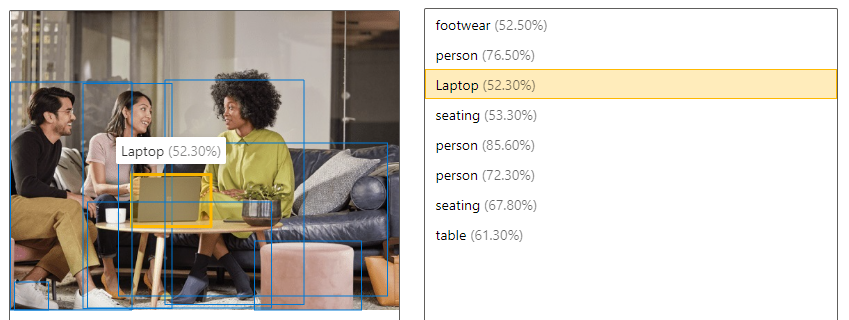
|
Detección de objetos (v3.2) (v4.0) |
| Etiquetar características visuales | Identifique y etiquete las características visuales de una imagen a partir de un conjunto de miles de objetos, seres vivos, paisajes y acciones reconocibles. Cuando las etiquetas son ambiguas o no muy comunes, la respuesta de la API contiene “indicaciones” para aclarar el contexto de la etiqueta. El etiquetado no se limita al sujeto principal, como una persona en primer plano, sino que también incluye el entorno (interior o exterior), muebles, herramientas, plantas, animales, accesorios, gadgets, etc.
|
Etiquetado de características visuales (v3.2) (v4.0) |
| Obtención del área de interés/recorte inteligente | Analice el contenido de una imagen para devolver las coordenadas del área de interés que coincida con una relación de aspecto especificada. Computer Vision devuelve las coordenadas del rectángulo delimitador de la región, por lo que la aplicación que realiza la llamada puede modificar la imagen original según sea necesario. El modelo de recorte inteligente de la versión 4.0 es una implementación más avanzada y funciona con una gama más amplia de imágenes de entrada. Solo está disponible en determinadas regiones geográficas. Consulte Disponibilidad de la región. |
Generación de miniaturas (v3.2) (versión preliminar v4.0) |
| Detección de marcas (solo v3.2) | Identifique las marcas comerciales en imágenes o vídeos desde una base de datos de miles de logotipos globales. Puede usar esta característica, por ejemplo, para detectar qué marcas son más populares en medios sociales o más frecuentes en la ubicación de los productos multimedia. | Detección de marcas |
| Clasificación de imágenes (solo v3.2) | Identifique y clasifique toda una imagen mediante una taxonomía de categoría con jerarquías hereditarias de elementos primarios y secundarios. Las categorías se pueden usar solas o con nuestros nuevos modelos de etiquetado. Actualmente, el inglés es el único idioma que se admite para etiquetar y clasificar imágenes. |
Clasificar una imagen |
| Detección de caras (solo v3.2) | Detecte caras en una imagen y proporcione información acerca de ellas. Visión de Azure AI devuelve las coordenadas, el rectángulo, el sexo y la edad de los rostros que detecta. También puede usar la instancia de Face API dedicada para estos fines. Esta API proporciona un análisis más detallado, como la identificación facial y la detección de poses. |
Detección de caras |
| Detección de tipos de imagen (solo v3.2) | Detecte las características de una imagen, como por ejemplo, si una imagen es un dibujo lineal o la probabilidad de que sea una imagen prediseñada. | Detectar tipos de imagen |
| Detección de contenido específico del dominio (solo v3.2) | Use los modelos de dominio para detectar e identificar el contenido específico del dominio en una imagen, como celebridades y monumentos. Por ejemplo, si una imagen contiene personas, Visión de Azure AI puede usar un modelo de dominio para celebridades para determinar si las personas que se han detectado en la imagen son famosos conocidos. | Detectar contenido específico del dominio |
| Detección de la combinación de colores (solo v3.2) | Analice el uso del color en una imagen. Visión de Azure AI puede determinar si una imagen está en blanco y negro o en color, y en las imágenes de color, identificar los colores dominantes y de énfasis. | Detectar la combinación de colores |
| Moderación del contenido de las imágenes (solo v3.2) | Puede usar Visión de Azure AI para detectar contenido para adultos en una imagen y devolver puntuaciones de confianza en las distintas clasificaciones. El umbral para el etiquetado de contenido se puede establecer en una escala deslizante, con el fin de que pueda ajustarlo a sus preferencias. | Detección de contenido para adultos |
Reconocimiento de productos (solo en la versión preliminar v4.0, en desuso)
Importante
Esta característica ya está en desuso. El 10 de enero de 2025, se retirará la vista previa de la API Azure AI Image Analysis 4.0 de clasificación de imágenes personalizada, detección de objetos personalizada y reconocimiento de productos. Después de esta fecha, se producirá un error en las llamadas API a estos servicios.
Para mantener un funcionamiento sin problemas de los modelos, realice la transición a Custom Vision de Azure AI, que ahora está disponible con carácter general. Custom Vision ofrece una funcionalidad similar a estas características de retirada.
Las API de Product Recognition permiten analizar fotos de estantes de una tienda. Puede detectar la presencia o ausencia de productos y obtener las coordenadas del rectángulo delimitador. Úselo en combinación con la personalización del modelo para entrenar un modelo para identificar los productos específicos. También puede comparar los resultados de Product Recognition con el documento de planograma de la tienda.
Inserciones multimodales (solo v4.0)
Las API de inserción multimodal permiten la vectorización de imágenes y consultas de texto. Convierten imágenes en coordenadas en un espacio vectorial multidimensional. A continuación, las consultas de texto entrantes también se pueden convertir en vectores y las imágenes se pueden comparar con el texto en función de la proximidad semántica. Esto permite al usuario buscar en un conjunto de imágenes mediante texto, sin necesidad de usar etiquetas de imagen u otros metadatos. La proximidad semántica suele producir mejores resultados en la búsqueda.
La API 2024-02-01 incluye un modelo multilingüe que admite la búsqueda de texto en 102 idiomas. El modelo de solo inglés original sigue disponible, pero no se puede combinar con el nuevo modelo en el mismo índice de búsqueda. Si ha vectorizado texto e imágenes con el modelo de solo inglés, estos vectores no serán compatibles con vectores de imagen y texto multilingües.
Estas API solo están disponibles en determinadas regiones geográficas. Consulte Disponibilidad de la región.
Eliminación del fondo (solo v4.0 preliminar)
Importante
Esta característica ya está en desuso. El 10 de enero de 2025, se retirará la API de segmentos de Análisis de imágenes de Azure AI 4.0 y el servicio de eliminación en segundo plano. Todas las solicitudes a este servicio producirán un error después de esta fecha.
Para mantener un funcionamiento sin problemas de los modelos, instale el modelo de Florence 2 de código abierto y use su característica Región a segmentación, que permite una operación similar de eliminación del fondo.
Image Analysis 4.0 (versión preliminar) ofrece la posibilidad de quitar el fondo de una imagen. Esta característica puede generar una imagen del objeto en primer plano detectado con un fondo transparente o una imagen alfa mate de escala de grises que muestra la opacidad del objeto de primer plano detectado.
| Imagen original | Con fondo quitado | Alfa mate |
|---|---|---|

|

|

|
Límites de servicio
Requisitos de entrada
Image Analysis funciona con imágenes que cumplen los requisitos siguientes:
- La imagen debe presentarse en formato JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF o MPO.
- El tamaño de archivo de la imagen debe ser inferior a 20 megabytes (MB).
- Las dimensiones de la imagen deben estar entre 50 x 50 píxeles y 16 000 x 16 000 píxeles
Sugerencia
Los requisitos de entrada para las inserciones multimodales son diferentes y se enumeran en Inserciones multimodales
Compatibilidad con idiomas
Hay diferentes características de análisis de imágenes disponibles en diferentes idiomas. Consulte la página Compatibilidad con idiomas.
Disponibilidad regional
Para usar las API de análisis de imágenes, debe crear el recurso de Azure AI Vision en una región admitida. Las características de Análisis de imágenes están disponibles en las siguientes regiones:
| Region | Analyze Image (menos 4.0 Subtítulos) |
Analyze Image (incluidos los títulos 4.0) |
Product Recognition | Inserciones multimodales | Eliminación del fondo |
|---|---|---|---|---|---|
| Este de EE. UU. | ✅ | ✅ | ✅ | ✅ | ✅ |
| Oeste de EE. UU. | ✅ | ✅ | ✅ | ✅ | |
| Oeste de EE. UU. 2 | ✅ | ✅ | ✅ | ||
| Centro de Francia | ✅ | ✅ | ✅ | ✅ | |
| Norte de Europa | ✅ | ✅ | ✅ | ✅ | |
| Oeste de Europa | ✅ | ✅ | ✅ | ✅ | |
| Centro de Suecia | ✅ | ✅ | |||
| Norte de Suiza | ✅ | ✅ | |||
| Este de Australia | ✅ | ✅ | |||
| Sudeste de Asia | ✅ | ✅ | ✅ | ✅ | |
| Este de Asia | ✅ | ✅ | |||
| Centro de Corea del Sur | ✅ | ✅ | ✅ | ✅ | |
| Japón Oriental | ✅ | ✅ |
Seguridad y privacidad de datos
Al igual que sucede con todas las instancias de servicios de Azure AI, los desarrolladores que usan el servicio Visión de Azure AI deben estar al tanto de las directivas de Microsoft sobre los datos de clientes. Para más información, consulte la página de servicios de Azure AI en Microsoft Trust Center.
Pasos siguientes
Para empezar a usar Image Analysis, siga la guía de inicio rápido del lenguaje de desarrollo y la versión de API que prefiera: