Nota
L'accés a aquesta pàgina requereix autorització. Pots provar d'iniciar sessió o canviar de directori.
L'accés a aquesta pàgina requereix autorització. Pots provar de canviar directoris.
En esta página se proporciona información general sobre las herramientas y enfoques para exportar datos y configuración desde el área de trabajo de Azure Databricks. Puede exportar recursos del área de trabajo para requisitos de cumplimiento, portabilidad de datos, propósitos de copia de seguridad o migración del área de trabajo.
Información general
Las áreas de trabajo de Azure Databricks contienen una variedad de recursos, como la configuración del área de trabajo, las tablas administradas, los objetos ai y ML, y los datos almacenados en el almacenamiento en la nube. Cuando necesite exportar datos del área de trabajo, puede usar una combinación de herramientas y API integradas para extraer estos recursos sistemáticamente.
Entre las razones comunes para exportar datos del área de trabajo se incluyen:
- Requisitos de cumplimiento: cumplir las obligaciones de portabilidad de datos en virtud de normativas como RGPD y CCPA.
- Copia de seguridad y recuperación ante desastres: creación de copias de recursos críticos del área de trabajo para la continuidad empresarial.
- Migración del área de trabajo: traslado de recursos entre áreas de trabajo o proveedores de nube.
- Auditar y archivar: conservación de registros históricos de la configuración y los datos del área de trabajo.
Planeamiento de la exportación
Antes de empezar a exportar datos del área de trabajo, cree un inventario de los recursos que necesita para exportar y comprender las dependencias entre ellos.
Descripción de los recursos del área de trabajo
El área de trabajo de Azure Databricks contiene varias categorías de recursos que puede exportar:
- Configuración del área de trabajo: cuadernos, carpetas, repositorios, secretos, usuarios, grupos, listas de control de acceso (ACL), configuraciones de clúster y definiciones de trabajo.
- Recursos de datos: tablas administradas, bases de datos, archivos del sistema de archivos de Databricks y datos almacenados en el almacenamiento en la nube.
- Recursos de proceso: configuraciones de clúster, directivas y definiciones de grupo de instancias.
- Recursos de IA y ML: experimentos de MLflow, ejecuciones, modelos, tablas del Almacén de características, índices de búsqueda vectorial y modelos de catálogo de Unity.
- Objetos de catálogo de Unity: configuración de metastore, catálogos, esquemas, tablas, volúmenes y permisos.
Ámbito de la exportación
Cree una lista de comprobación de recursos para exportar en función de sus requisitos. Tenga en cuenta estas preguntas:
- ¿Necesita exportar todos los recursos o solo categorías específicas?
- ¿Hay requisitos de cumplimiento o seguridad que dictan qué recursos debe exportar?
- ¿Necesita conservar las relaciones entre los recursos (por ejemplo, los trabajos que hacen referencia a cuadernos)?
- ¿Necesita volver a crear la configuración del área de trabajo en otro entorno?
Planear el ámbito de exportación le ayuda a elegir las herramientas adecuadas y a evitar que falten dependencias críticas.
Exportación de la configuración del área de trabajo
El exportador de Terraform es la herramienta principal para exportar la configuración del área de trabajo. Genera archivos de configuración de Terraform que representan los recursos del área de trabajo como código.
Utilice el exportador de Terraform
El exportador de Terraform está integrado en el proveedor de Terraform de Azure Databricks y genera archivos de configuración de Terraform para los recursos del área de trabajo, incluidos cuadernos, trabajos, clústeres, usuarios, grupos, secretos y listas de control de acceso. El exportador debe ejecutarse por separado para cada área de trabajo. Consulte el proveedor de Terraform de Databricks.
Requisitos previos:
- Terraform instalado en tu máquina
- Autenticación de Azure Databricks configurada
- Privilegios de administrador en el área de trabajo que desea exportar
Para exportar recursos del área de trabajo:
Revise el vídeo de uso de ejemplo para ver un tutorial del exportador.
Descargue e instale el proveedor de Terraform con la herramienta exportadora:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipConfigure las variables de entorno de autenticación para el área de trabajo:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenEjecute el exportador para generar archivos de configuración de Terraform:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsOpciones comunes del exportador:
-
-listing: especifique los tipos de recursos que se van a exportar (separados por comas) -
-services: alternativa a la lista para filtrar recursos -
-directory: directorio de salida para archivos generados.tf -
-incremental: ejecutar en modo incremental para migraciones por etapas
-
Revise los archivos generados
.tfen el directorio de salida. El exportador crea un archivo para cada tipo de recurso.
Nota:
El exportador de Terraform se centra en la configuración y los metadatos del área de trabajo. No exporta los datos reales almacenados en tablas ni en el sistema de archivos de Databricks. Debe exportar datos por separado mediante los enfoques descritos en las secciones siguientes.
Exportación de tipos de recursos específicos
En el caso de los activos que no están totalmente cubiertos por el exportador de Terraform, use estos enfoques:
- Cuadernos: descargue cuadernos individualmente desde la interfaz de usuario del área de trabajo o use workspace API para exportar cuadernos mediante programación. Consulte Administración de objetos del área de trabajo.
- Secretos: los secretos no se pueden exportar directamente por motivos de seguridad. Debe recrear manualmente los secretos en el entorno de destino. Documentar nombres y ámbitos de secretos para referencia.
- Objetos MLflow: Use la herramienta Mlflow-Export-Import para exportar experimentos, ejecuciones y modelos. Consulte la sección Activos de ML a continuación.
Exportación de datos
Los datos del cliente normalmente residen en el almacenamiento de la cuenta en la nube, no en Azure Databricks. No es necesario exportar datos que ya están en el almacenamiento en la nube. Sin embargo, debe exportar datos almacenados en ubicaciones administradas por Azure Databricks.
Exportación de tablas administradas
Aunque las tablas administradas residen en el almacenamiento en la nube, se almacenan en una jerarquía basada en UUID que puede ser difícil de analizar. Puede usar el DEEP CLONE comando para volver a escribir tablas administradas como tablas externas en una ubicación especificada, lo que facilita su trabajo.
Comandos de ejemplo DEEP CLONE :
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Para obtener un script completo para clonar todas las tablas de una lista de catálogos, consulte el siguiente script de ejemplo.
Exportación del almacenamiento predeterminado de Databricks
En el caso de las áreas de trabajo sin servidor, Azure Databricks ofrece almacenamiento predeterminado, que es una solución de almacenamiento totalmente administrada dentro de la cuenta de Azure Databricks. Los datos del almacenamiento predeterminado deben exportarse a contenedores de almacenamiento propiedad del cliente antes de la eliminación o retirada del área de trabajo. Para obtener más información sobre las áreas de trabajo sin servidor, consulte Creación de un área de trabajo sin servidor.
Para las tablas del almacenamiento predeterminado, use DEEP CLONE para escribir datos en un contenedor de almacenamiento propiedad del cliente. Para volúmenes y archivos arbitrarios, siga los mismos patrones descritos en la sección exportación raíz de DBFS siguiente.
Exportación de la raíz del sistema de archivos de Databricks
La raíz del sistema de archivos de Databricks es la ubicación de almacenamiento heredada en la cuenta de almacenamiento de su área de trabajo que puede contener activos propiedad del cliente, cargas de usuario, scripts de inicio, bibliotecas y tablas. Aunque la raíz del sistema de archivos de Databricks es un patrón de almacenamiento en desuso, es posible que las áreas de trabajo heredadas todavía tengan datos almacenados en esta ubicación que se deben exportar. Para obtener más información sobre la arquitectura de almacenamiento del área de trabajo, consulte Almacenamiento del área de trabajo.
Exportación de la raíz del sistema de archivos de Databricks:
Dado que los cubos raíz en Azure son privados, no puede usar herramientas nativas de Azure como azcopy mover datos entre cuentas de almacenamiento. En su lugar, use dbutils fs cp y Delta DEEP CLONE en Azure Databricks. Esto puede tardar mucho tiempo en ejecutarse, en función del volumen de datos.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Para las tablas del almacenamiento raíz del sistema de archivos de Databricks, use DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Importante
La exportación de grandes volúmenes de datos desde el almacenamiento en la nube puede suponer importantes costos de transferencia y almacenamiento de datos. Revise los precios del proveedor de nube antes de iniciar exportaciones grandes.
Desafíos comunes de exportación
Secretos:
Los secretos no se pueden exportar directamente por motivos de seguridad. Cuando se usa el exportador de Terraform con la -export-secrets opción , el exportador genera una variable en vars.tf con el mismo nombre que el secreto. Debe actualizar manualmente este archivo con los valores de secreto reales o ejecutar el exportador de Terraform con la -export-secrets opción (solo para secretos administrados por Azure Databricks).
Azure Databricks recomienda usar un almacén de secretos respaldado por Azure Key Vault.
Exportación de recursos de inteligencia artificial y aprendizaje automático
Algunos recursos de inteligencia artificial y aprendizaje automático requieren diferentes herramientas y enfoques para la exportación. Los modelos del Catálogo de Unity se exportan como parte del exportador de Terraform.
Objetos MLflow
MLflow no está cubierto por el exportador de Terraform debido a brechas en la API y dificultad con la serialización. Para exportar experimentos, ejecuciones, modelos y artefactos de MLflow, use la herramienta mlflow-export-import . Esta herramienta de código abierto proporciona cobertura semicompleta de la migración de MLflow.
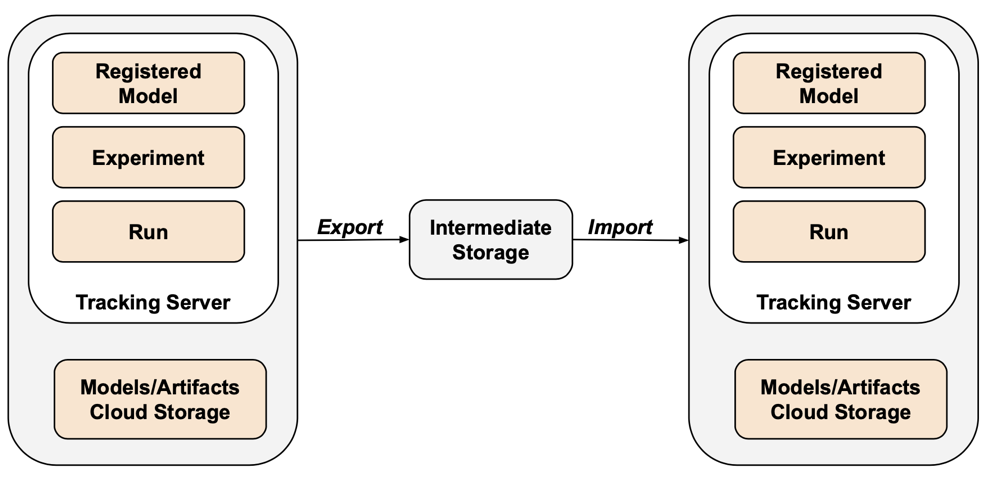
En escenarios de solo exportación, puede almacenar todos los recursos de MLflow dentro de un cubo propiedad del cliente sin necesidad de realizar el paso de importación. Para obtener más información sobre la administración de MLflow, consulte Administración del ciclo de vida del modelo en el catálogo de Unity.
Almacén de características y búsqueda de vectores
Índices de búsqueda vectorial: los índices de búsqueda vectorial no están en el ámbito de los procedimientos de exportación de datos de la UE. Si desea exportarlos, deben escribirse en una tabla estándar y luego exportarse mediante DEEP CLONE.
Tablas del Almacén de características: el Almacén de características debe tratarse de forma similar a los índices de búsqueda vectorial. Con SQL, seleccione los datos pertinentes y escríbalos en una tabla estándar y, a continuación, exporte mediante DEEP CLONE.
Validar los datos exportados
Después de exportar los datos del área de trabajo, compruebe que los trabajos, los usuarios, los cuadernos y otros recursos se exportaron correctamente antes de retirar el entorno anterior. Use la lista de comprobación que creó durante la fase de ámbito y planeación para comprobar que todo lo que esperaba exportar se exportó correctamente.
Lista de comprobación
Use esta lista de comprobación para comprobar la exportación:
- Archivos de configuración generados: los archivos de configuración de Terraform se crean para todos los recursos de área de trabajo necesarios.
- Cuadernos exportados: todos los cuadernos se exportan con su contenido y metadatos intactos.
- Tablas clonadas: las tablas administradas se clonan correctamente en la ubicación de exportación.
- Archivos de datos copiados: los datos de almacenamiento en la nube se copian completamente sin errores.
- Objetos de MLflow exportados: los experimentos, las ejecuciones y los modelos se exportan con sus artefactos.
- Permisos documentados: las listas de control de acceso y los permisos se capturan en la configuración de Terraform.
- Dependencias identificadas: las relaciones entre los recursos (por ejemplo, los trabajos que hacen referencia a cuadernos) se conservan en la exportación.
Procedimientos recomendados posteriores a la exportación
Las pruebas de validación y aceptación se controlan en gran medida por sus requisitos y pueden variar ampliamente. Sin embargo, se aplican estos procedimientos recomendados generales:
- Definir un entorno de pruebas: cree un entorno de pruebas de trabajos o cuadernos que validen que los secretos, los datos, los montajes, los conectores y otras dependencias funcionan correctamente en el entorno exportado.
- Comience con entornos de desarrollo: si se mueve de forma escalonada, comience con el entorno de desarrollo y progrese hasta el entorno de producción. Esto expone los principales problemas al principio y evita impactos en la producción.
- Aprovechar las carpetas de Git: Cuando sea posible, use carpetas de Git ya que están en un repositorio de Git externo. Esto evita la exportación manual y garantiza que el código sea idéntico en todos los entornos.
- Documente el proceso de exportación: registre las herramientas usadas, los comandos ejecutados y los problemas detectados.
- Proteger los datos exportados: asegúrese de que los datos exportados se almacenan de forma segura con los controles de acceso adecuados, especialmente si contiene información confidencial o de identificación personal.
- Mantener el cumplimiento: si se exporta con fines de cumplimiento, compruebe que la exportación cumple los requisitos normativos y las directivas de retención.
Ejemplos de scripts y automatización
Puede automatizar las exportaciones de áreas de trabajo mediante scripts y trabajos programados.
Script de exportación de clonación profunda
El script siguiente exporta tablas administradas del catálogo de Unity mediante DEEP CLONE. Este código debe ejecutarse en el área de trabajo de origen para exportar un catálogo determinado a un cubo intermedio. Actualice las catalogs_to_copy variables y dest_bucket .
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Consideraciones sobre automatización
Al automatizar las exportaciones:
- Uso de trabajos programados: cree trabajos de Azure Databricks que ejecuten scripts de exportación según una programación normal.
- Supervisar trabajos de exportación: configure alertas para notificarle si las exportaciones producen un error o tardan más de lo esperado.
- Administración de credenciales: almacene las credenciales de almacenamiento en la nube y los tokens de API de forma segura mediante secretos de Azure Databricks. Consulte Administración de secretos.
- Exportaciones de versiones: Use marcas de tiempo o números de versión en las rutas de exportación para conservar las exportaciones históricas.
- Limpiar exportaciones antiguas: implemente directivas de retención para eliminar exportaciones antiguas y administrar los costos de almacenamiento.
- Exportaciones incrementales: para áreas de trabajo grandes, considere la posibilidad de implementar exportaciones incrementales que solo exportan datos modificados desde la última exportación.