Tutorial: indexación de blobs JSON anidados desde Azure Storage mediante REST
Azure AI Search puede indexar documentos y matrices JSON en Azure Blob Storage mediante un indexador que sabe cómo leer datos semiestructurados. Los datos semiestructurados contienen etiquetas o marcas que separan el contenido dentro de los datos. Dividen la diferencia entre datos no estructurados, que se deben indexar completamente, y datos estructurados formalmente que se ajustan a un modelo de datos, como un esquema de base de datos relacional que se pueden indexar por campo.
En este tutorial se muestra cómo indexar matrices JSON anidadas. Se usa un cliente REST y las API de REST de Search para realizar las tareas siguientes:
- Configuración de datos de ejemplo y configuración de un origen de datos de
azureblob - Creación de un índice de Azure AI Search que contenga contenido que permita búsquedas
- Crear y ejecutar un indexador para leer el contenedor y extraer contenido que permita búsquedas
- Buscar el índice que acaba de crear.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Visual Studio Code con un cliente REST.
Búsqueda de Azure AI. Cree un servicio de Búsqueda de Azure AI o busque uno existente en su suscripción actual.
Nota:
Puede usar un servicio gratuito para este tutorial. Un servicio de búsqueda gratuito tiene una limitación de tres índices, tres indexadores y tres orígenes de datos. En este tutorial se crea uno de cada uno. Antes de empezar, asegúrese de que haya espacio en el servicio para aceptar los nuevos recursos.
Descarga de archivos
Descargue un archivo ZIP del repositorio de datos de ejemplo y extraiga el contenido. Más información.
Los datos de ejemplo son un único archivo JSON que contiene una matriz JSON y 1521 elementos JSON anidados. Los datos de ejemplo se originan en Historial de rendimiento de la Filarmónica de NY en Kaggle. Se eligió un archivo JSON para permanecer bajo los límites de almacenamiento del nivel gratuito.
Este es el primer JSON anidado en el archivo. El resto del archivo incluye 1520 otros ejemplos de actuaciones de conciertos.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Carga de datos de ejemplo en Azure Storage
En Azure Storage, cree un contenedor y asígnele el nombre ny-philharmonic-free.
Obtenga una cadena de conexión de almacenamiento para poder formular una conexión en Azure AI Search.
A la izquierda, seleccione Teclas de acceso.
Copie la cadena de conexión para la clave uno o la clave dos. La cadena de conexión es parecida a la del ejemplo siguiente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
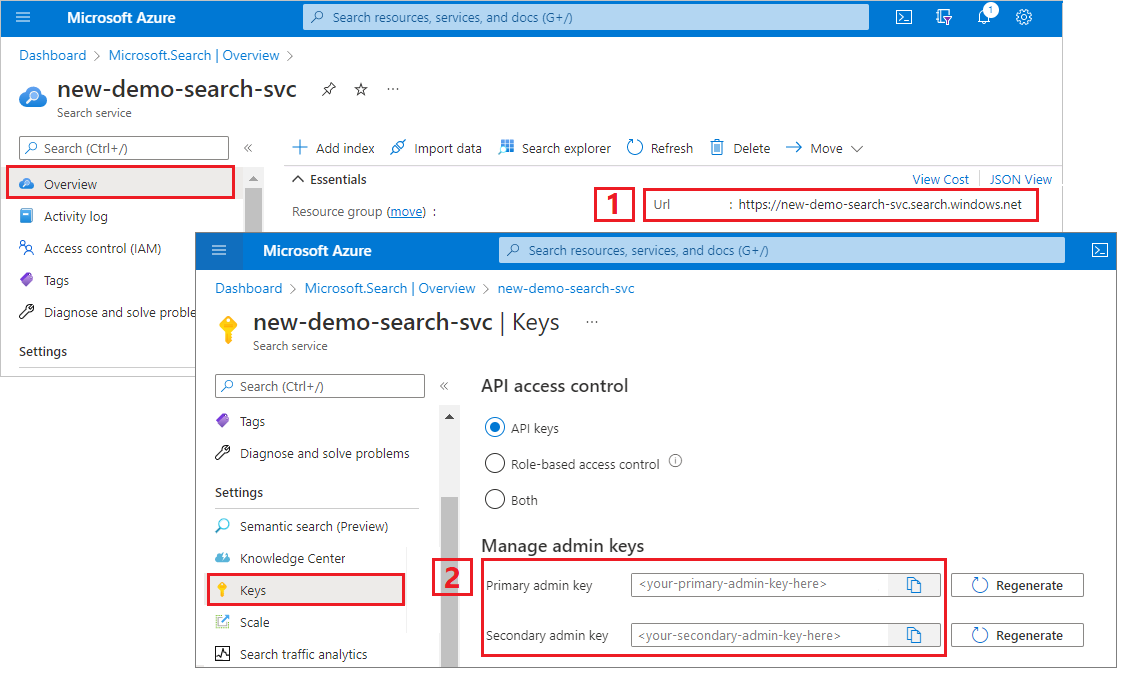
Copia de una dirección URL del servicio de búsqueda y una clave de API
Para este tutorial, las conexiones a la búsqueda de Azure AI requieren un punto de conexión y una clave de API. Puede obtener estos valores en Azure Portal.
Inicie sesión en Azure Portal, vaya a la página Información general del servicio de búsqueda y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
Configuración del archivo REST
Inicie Visual Studio Code y cree un nuevo archivo
Proporcione valores para las variables usadas en la solicitud:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREGuarde el archivo mediante una extensión de archivo
.resto.http.
Consulte Inicio rápido: Búsqueda de texto mediante REST si necesita ayuda con el cliente REST.
Creación de un origen de datos
Crear origen de datos (REST) crea una conexión de origen de datos que especifica qué datos se van a indexar.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envíe la solicitud. La respuesta debería tener este aspecto:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Creación de un índice
Crear índice (REST) crea un índice de búsqueda en el servicio de búsqueda. Un índice especifica todos los parámetros y sus atributos.
Para JSON anidado, los campos de índice deben ser idénticos a los campos de origen. Actualmente, Búsqueda de Azure AI no admite asignaciones de campos a JSON anidados. Por este motivo, los nombres de campo y los tipos de datos deben coincidir completamente. El índice siguiente se alinea con los elementos JSON del contenido sin procesar.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Puntos clave:
No se pueden usar asignaciones de campos para conciliar las diferencias en los nombres de campo o los tipos de datos. Este esquema de índice está diseñado para reflejar el contenido sin procesar.
JSON anidado se modela como
Collection(Edm.ComplextType). En el contenido sin procesar, hay varios conciertos para cada temporada y varias obras para cada concierto. Para dar cabida a esta estructura, use colecciones para tipos complejos.En el contenido sin procesar,
DateyTimeson cadenas, por lo que los tipos de datos correspondientes del índice también son cadenas.
Creación y ejecución de un indexador
Crear indexador crea un indexador en el servicio de búsqueda. Un indexador se conecta al origen de datos, carga e indexa datos y, opcionalmente, proporciona una programación para automatizar la actualización de datos.
La configuración del indexador incluye el modo de análisis de jsonArray y un documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Puntos clave:
El archivo de contenido sin procesar contiene una matriz JSON (
"programs") con 1526 estructuras JSON anidadas. EstablezcaparsingModeenjsonArraypara indicar al indexador que cada blob contiene una matriz JSON. Dado que el JSON anidado inicia un nivel hacia abajo, establezcadocumentRooten/programs.El indexador se ejecuta durante varios minutos. Espere a que se complete la ejecución del indexador antes de ejecutar cualquier consulta.
Ejecutar consultas
Puede empezar a realizar búsquedas en cuanto se cargue el primer documento.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envíe la solicitud. Se trata de una consulta de búsqueda de texto completo no especificada que devuelve todos los campos marcados como recuperables en el índice, junto con un recuento de documentos. La respuesta debería tener este aspecto:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Agregue un parámetro search para buscar en una cadena. Agregue un parámetro select para limitar los resultados a menos campos. Agregue un filter para restringir aún más la búsqueda.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
Se devuelven dos documentos en la respuesta.
En el caso de los filtros, también es posible usar operadores lógicos (and, or y not) y operadores de comparación (eq, ne, gt, lt, ge y le). La comparación de cadenas distingue mayúsculas de minúsculas. Para obtener más información y ejemplos, vea crear una consulta.
Nota:
El parámetro $filter solo funciona con los campos que se marcaron como filtrables al crear el índice.
Restablecer y volver a ejecutar
Los indexadores se pueden restablecer, borrar el historial de ejecución, lo que permite una nueva ejecución completa. Las siguientes solicitudes GET son para el restablecimiento, seguidas de la repetición de la ejecución.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede usar el portal para eliminar los índices, indexadores y orígenes de datos.
Pasos siguientes
Ahora que está familiarizado con los aspectos básicos de la indexación de blobs de Azure, podemos abordar en detalle la configuración del indexador para blobs JSON en Azure Storage.