Creación, desarrollo y mantenimiento de cuadernos de Synapse en Azure Synapse Analytics
Un cuaderno de Synapse es una interfaz web para crear archivos que contengan código activo, visualizaciones y texto narrativo. Los cuadernos son un buen lugar para validar ideas y aplicar experimentos rápidos para sacar conclusiones a partir de los datos. Los cuadernos también se usan ampliamente en la preparación de datos, la visualización de datos, el aprendizaje automático y otros escenarios de macrodatos.
Con un cuaderno de Synapse, puede hacer lo siguiente:
- Empezar a trabajar sin esfuerzo alguno de configuración.
- Mantener los datos protegidos con las características de seguridad empresarial integradas.
- Analizar datos en formatos sin procesar (CSV, TXT, JSON, etc.), formatos de archivos procesados (parquet, Delta Lake, ORC, etc.) y archivos de datos tabulares de SQL en Spark y SQL.
- Ser productivo con funcionalidades de creación mejoradas y visualización de datos integrada.
En este artículo se describe cómo usar cuadernos en Synapse Studio.
Creación de un cuaderno
Hay dos formas de crear un cuaderno. Puede crear un nuevo cuaderno o importar uno existente en un área de trabajo de Synapse desde el Explorador de objetos. Los cuadernos de Synapse reconocen los archivos IPYNB estándar de Jupyter Notebook.
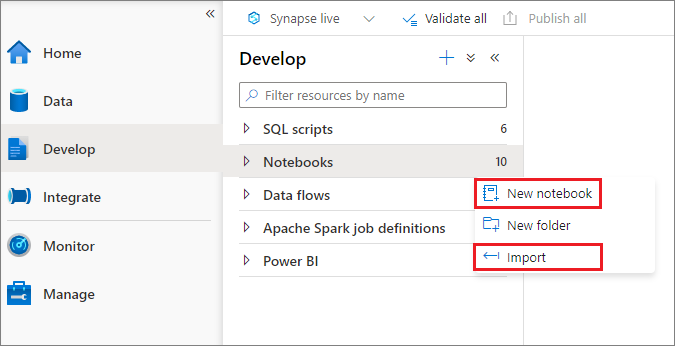
Desarrollo de cuadernos
Los cuadernos se componen de celdas, que son bloques individuales de código o texto que se pueden ejecutar de manera independiente o en grupo.
Proporcionamos operaciones enriquecidas para desarrollar cuadernos:
- Adición de una celda
- Definición del lenguaje principal
- Uso de varios lenguajes
- Uso de tablas temporales para hacer referencia a datos entre lenguajes
- IntelliSense de estilo IDE
- Fragmentos de código
- Formato de celdas de texto con botones de la barra de herramientas
- Deshacer/rehacer operación de celda
- Comentarios de celdas de código
- Movimiento de una celda
- Eliminación de una celda
- Contracción de una entrada de celda
- Contracción de una salida de celda
- Esquema del cuaderno
Nota:
En los cuadernos, se crea automáticamente SparkSession, que se almacena en una variable denominada spark. También hay una variable para SparkContext que se denomina sc. Los usuarios pueden acceder directamente a estas variables y no deben cambiar sus valores.
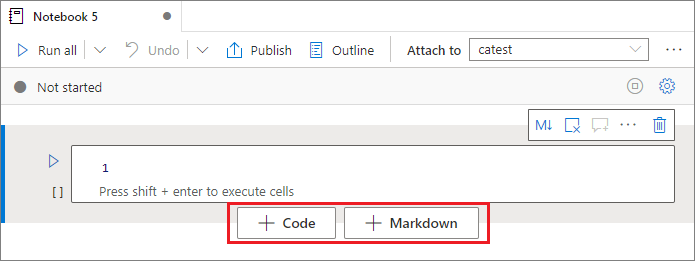
Adición de una celda
Hay varias maneras de agregar una nueva celda a un cuaderno.
Mantenga el puntero sobre el espacio entre dos celdas y seleccione Código o Markdown.
Use las teclas de método abreviado aznb en el modo de comando. Presione A para insertar una celda sobre la celda actual. Presione B para insertar una celda debajo de la celda actual.
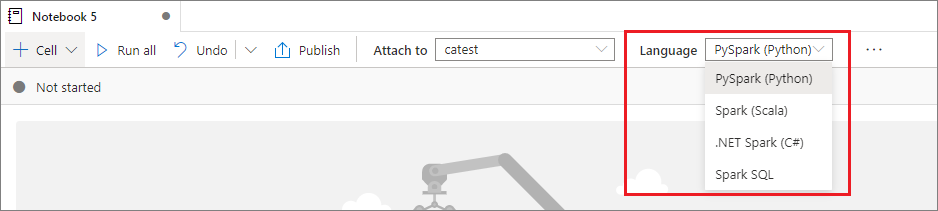
Definición del lenguaje principal
Los cuadernos de Synapse admiten cuatro lenguajes de Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Desde la lista desplegable de la barra de comandos superior, puede establecer el lenguaje principal para las nuevas celdas que se agreguen.
Uso de varios lenguajes
Para usar varios lenguajes en un cuaderno, puede especificar el comando magic de lenguaje correcto al principio de una celda. En la tabla siguiente se enumeran los comandos magic para cambiar el lenguaje de las celdas.
| Comando magic | Idioma | Descripción |
|---|---|---|
| %%pyspark | Python | Ejecute una consulta de Python en SparkContext. |
| %%spark | Scala | Ejecute una consulta de Scala en SparkContext. |
| %%sql | SparkSQL | Ejecute una consulta de SparkSQL en SparkContext. |
| %%csharp | .NET para Spark C# | Ejecute una consulta de .NET para Spark C# en Spark Context. |
| %%sparkr | R | Ejecute una consulta de R en SparkContext. |
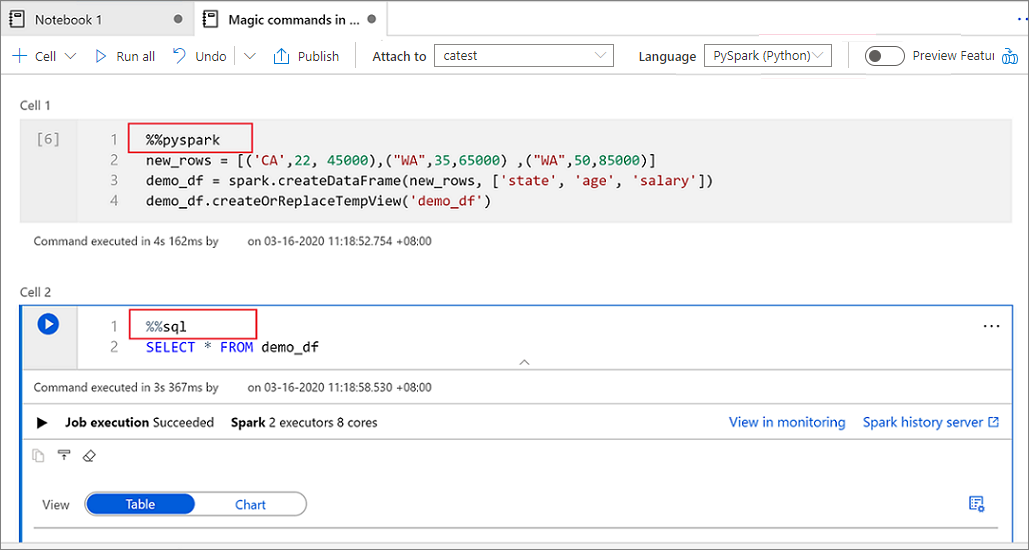
La imagen siguiente es un ejemplo de cómo se puede escribir una consulta de PySpark con el comando magic %%pyspark o una consulta de SparkSQL con el comando magic %%sql en un cuaderno de Spark (Scala) . Tenga en cuenta que el lenguaje principal del cuaderno está establecido en pySpark.
Uso de tablas temporales para hacer referencia a datos entre lenguajes
No puede hacer referencia a datos o variables directamente entre distintos lenguajes en un cuaderno de Synapse. En Spark, se puede hacer referencia a una tabla temporal entre lenguajes. Este es un ejemplo de cómo leer un DataFrame de Scala en PySpark y SparkSQL mediante una tabla temporal de Spark como solución alternativa.
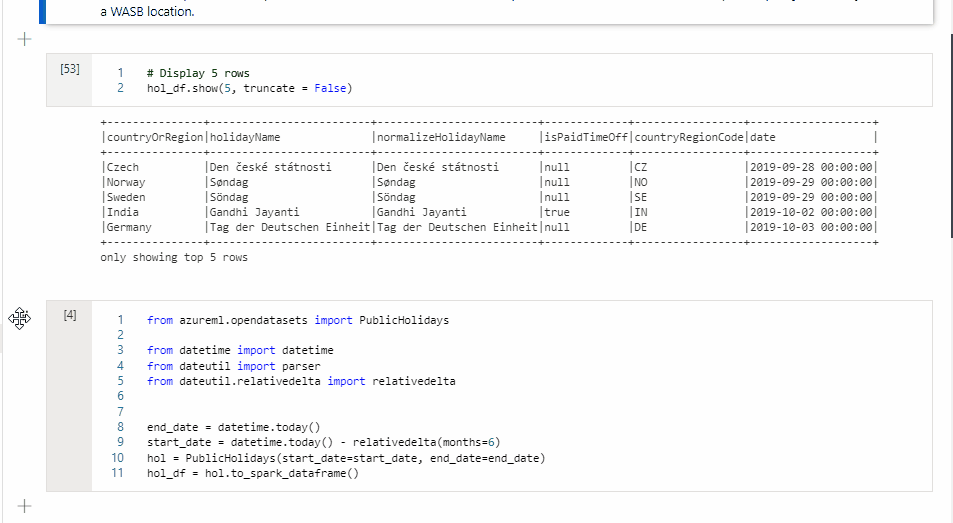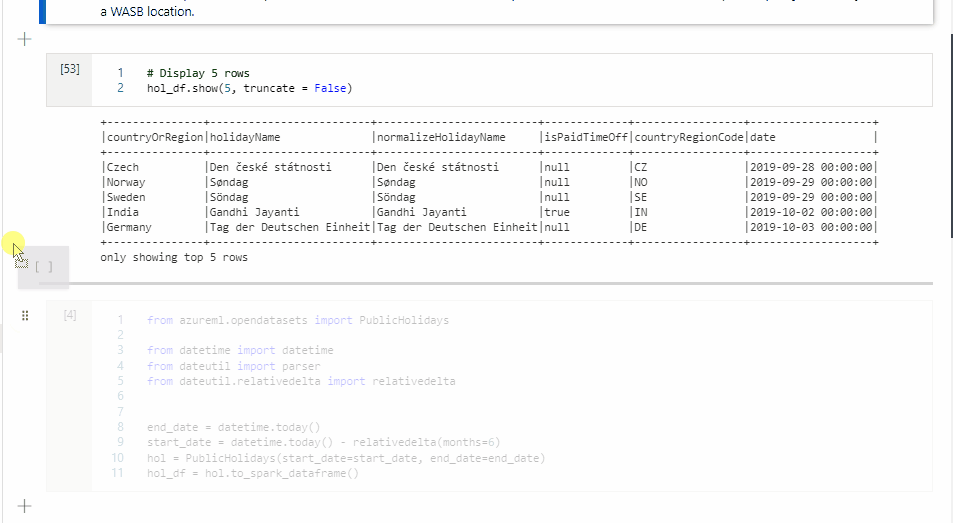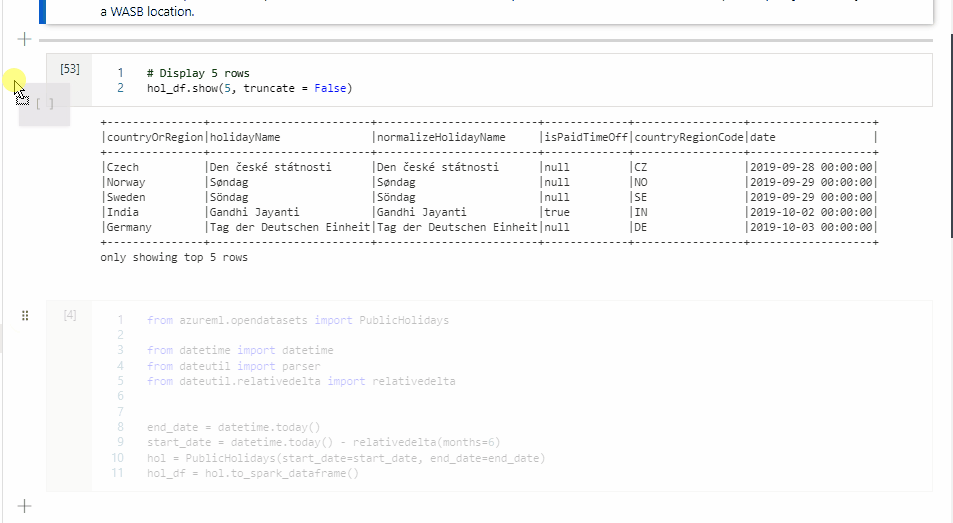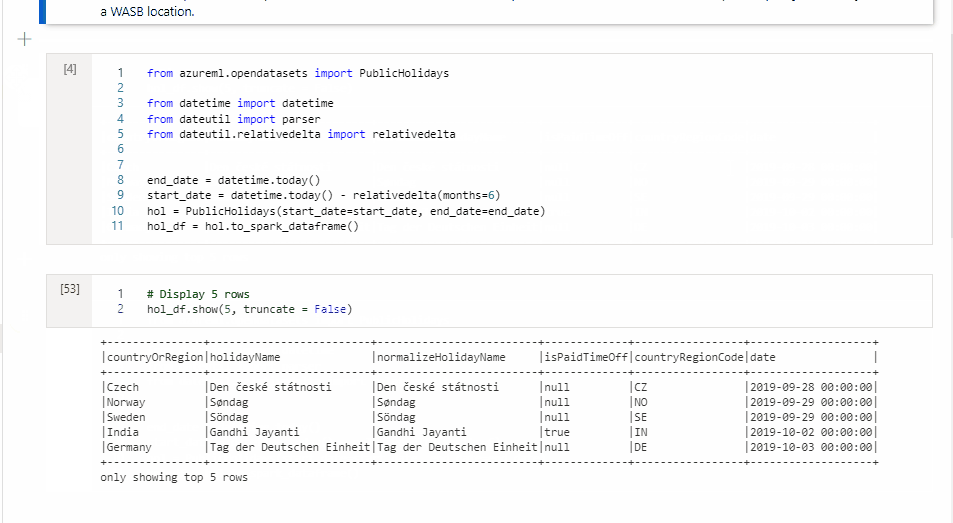
En la celda 1, lea un DataFrame de un conector de grupo de SQL mediante Scala y cree una tabla temporal.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )En la celda 2, consulte los datos mediante Spark SQL.
%%sql SELECT * FROM mydataframetableEn la celda 3, use los datos de PySpark.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IntelliSense de estilo IDE
Los cuadernos de Synapse se integran en el editor Monaco para incluir la funcionalidad IntelliSense de estilo IDE en el editor de celdas. El resaltado de la sintaxis, el marcador de errores y la finalización automática de código le ayudan a escribir código y a identificar problemas más rápido.
Las características de IntelliSense tienen distintos niveles de madurez para distintos lenguajes. Use la siguiente tabla para ver lo que se admite.
| Lenguajes | Resaltado de sintaxis | Creador de errores de sintaxis | Finalización de código de sintaxis | Finalización de código de sintaxis | Finalización de código de funciones del sistema | Finalización de código de funciones del usuario | Sangría inteligente | Plegado de código |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Sí | Sí | Sí | Sí | Sí | Sí | Sí | Sí |
| Spark (Scala) | Sí | Sí | Sí | Sí | Sí | Sí | - | Sí |
| SparkSQL | Sí | Sí | Sí | Sí | Sí | - | - | - |
| .NET para Spark ( C# ) | Sí | Sí | Sí | Sí | Sí | Sí | Sí | Sí |
Nota
Se necesita una sesión activa de Spark para beneficiarse de la finalización de código variable, la finalización del código de funciones del sistema y la finalización de código de funciones del usuario para .NET para Spark (C#).
Fragmentos de código
Los cuadernos de Synapse proporcionan fragmentos de código que facilitan la introducción de patrones de código utilizados habitualmente, como la configuración de la sesión de Spark, la lectura de datos como dataframes de Spark o la creación de gráficos con matplotlib.
Los fragmentos de código aparecen en teclas de método abreviado de IntelliSense estilo IDE combinados con otras sugerencias. El contenido de los fragmentos de código se alinea con el lenguaje de las celdas de código. Para ver los fragmentos de código disponibles, escriba snippet o cualquier palabra clave que aparezca en el título del fragmento de código en el editor de celdas de código. Por ejemplo, si escribe read, puede ver la lista de fragmentos de código para leer datos de varios orígenes de datos.

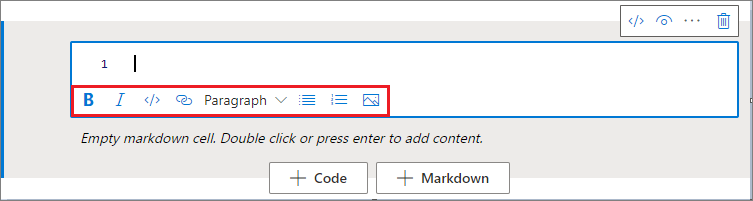
Formato de celdas de texto con botones de la barra de herramientas
Puede usar los botones de formato en la barra de herramientas de celdas de texto para completar acciones comunes de marcado. Incluye texto en negrita, texto en cursiva, párrafos o encabezados mediante un desplegable, inserción de código, inserción de listas sin ordenar, inserción de listas ordenadas, inserción de hipervínculos e inserción de imágenes desde direcciones URL.
Deshacer/rehacer operación de celda
Seleccione el botón Deshacer / Rehacero presione Z / Ctrl+Z para revocar las operaciones de celda más recientes. Ahora puede deshacer/rehacer hasta las 10 operaciones de celda históricas más recientes.

Operaciones de deshacer celda admitidas:
- Insertar o eliminar celda: Puede revocar las operaciones de eliminación si selecciona Deshacer. El contenido del texto se conservará junto con la celda.
- Reordenar celda.
- Alternar parámetros.
- Convertir entre la celda Code y la celda Markdown.
Nota
Las operaciones de texto en celda y las operaciones de comentario de celdas de código no se pueden deshacer. Ahora puede deshacer/rehacer hasta las 10 operaciones de celda históricas más recientes.
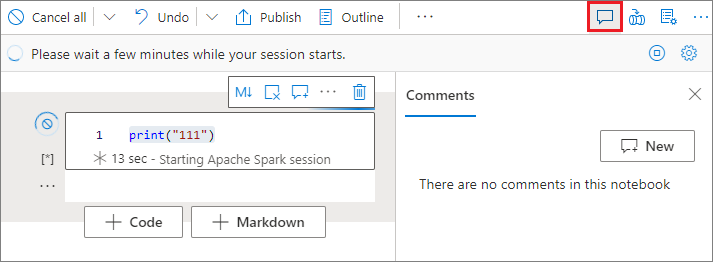
Comentarios de celdas de código
Seleccione el botón Comentarios de la barra de herramientas del cuaderno para abrir el panel de Comentarios.
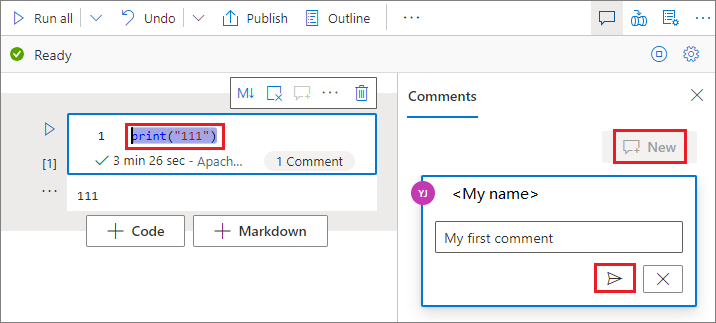
Seleccione código en la celda de código, haga clic en Nuevo en el panel Comentarios, agregue comentarios y, a continuación, haga clic en el botón Publicar comentario para guardar.
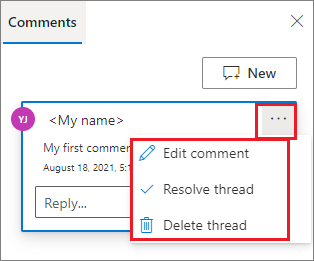
Puede realizar Editar comentario,Resolver subproceso o Eliminar subproceso haciendo clic en el botón Más además del comentario.
Movimiento de una celda
Haga clic en la parte izquierda de una celda y arrástrela hasta la posición deseada.
Eliminación de una celda
Para eliminar una celda, seleccione el botón Eliminar en la parte derecha de la celda.
También puede utilizar las teclas de método abreviado en el modo de comando. Presione Mayús+D para eliminar la celda actual.
Contracción de una entrada de celda
Seleccione los puntos suspensivos de Más comandos (...) en la barra de herramientas de la celda y en Hide input (Ocultar entrada) para contraer la entrada de la celda actual. Para expandirla, seleccione Show input (Mostrar entrada) mientras la celda está contraída.
Contracción de una salida de celda
Seleccione los puntos suspensivos de Más comandos (...) en la barra de herramientas de la celda y en Hide output (Ocultar salida) para contraer la salida de la celda actual. Para expandirla, seleccione Show output (Mostrar salida) mientras la salida de la celda está oculta.
Esquema del cuaderno
En Esquema (tabla de contenido) se presenta el primer encabezado de cualquier celda de Markdown en una ventana de la barra lateral para permitir la navegación rápida. La barra lateral Esquemas es redimensionable y contraíble para ajustarse a la pantalla de la mejor manera posible. Puede seleccionar el botón Esquema de la barra de comandos del cuaderno para abrir u ocultar la barra lateral.
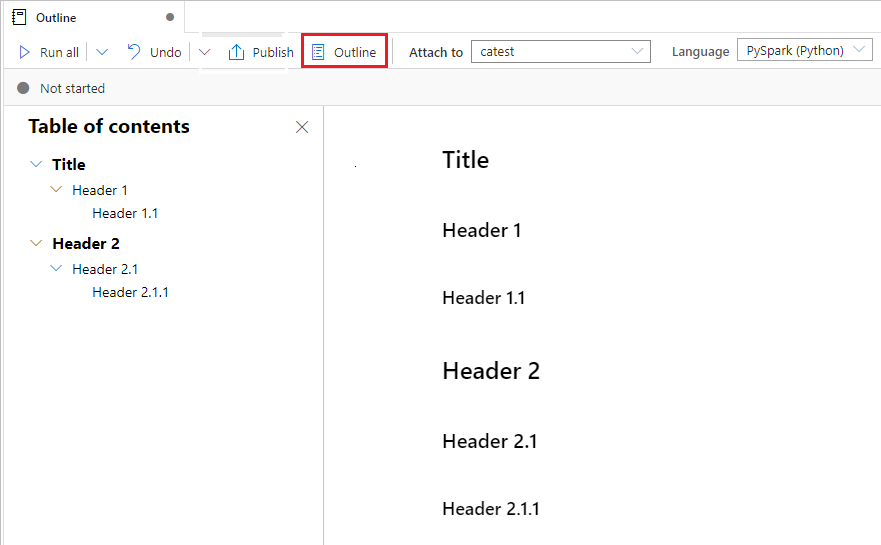
Ejecución de cuadernos
Puede ejecutar las celdas de código en el cuaderno individualmente o todas a la vez. El estado y el progreso de cada celda se representan en el cuaderno.
Ejecución de una celda
Hay varias maneras de ejecutar el código de una celda.
Mantenga el puntero sobre la celda que desea ejecutar y seleccione el botón Ejecutar celda o presione CTRL+Entrar.

Utilice las teclas de método abreviado en el modo de comando. Presione Mayús+Entrar para ejecutar la celda actual y seleccionar la celda a continuación. Presione Mayús+Entrar para ejecutar la celda actual e insertar una nueva celda a continuación.
Ejecución de todas las celdas
Seleccione el botón Ejecutar todo para ejecutar todas las celdas del cuaderno actual en secuencia.

Ejecución de todas las celdas encima o debajo
Expanda la lista desplegable en el botón Ejecutar todo y, a continuación, seleccione Run cells above (Ejecutar las celdas encima) para ejecutar todas las celdas situadas encima de la actual en secuencia. Seleccione Run cells below (Ejecutar las celdas debajo) para ejecutar todas las celdas situadas debajo de la actual en secuencia.
Cancelación de todas las celdas en ejecución
Seleccione el botón Cancelar todo para cancelar las celdas en ejecución o las celdas que esperan en la cola.

Referencia del cuaderno
Puede usar el comando magic %run <notebook path> para hacer referencia a otro cuaderno en el contexto del cuaderno actual. Todas las variables definidas en el cuaderno de referencia están disponibles en el cuaderno actual. El comando magic %run admite llamadas anidadas pero no admite llamadas recursivas. Recibirá una excepción si la profundidad de la instrucción es superior a cinco.
Ejemplo: %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
La referencia del cuaderno funciona tanto en modo interactivo como en la canalización de Synapse.
Nota
%runEl comando actualmente solo admite pasar una ruta de acceso absoluta o un nombre de cuaderno solo como parámetro, no se admite la ruta de acceso relativa.%runActualmente, command solo admite 4 tipos de valor de parámetro:int,float,bool,string, no se admite la operación de reemplazo de variables.- Los cuadernos a los que se hace referencia deben publicarse. Debe publicar los cuadernos para hacer referencia a ellos a menos que se habilite Hacer referencia a cuaderno sin publicar. Synapse Studio no reconoce los cuadernos no publicados desde el repositorio de Git.
- Los cuadernos a los que se hace referencia no admiten la instrucción de que la profundidad es mayor que cinco.
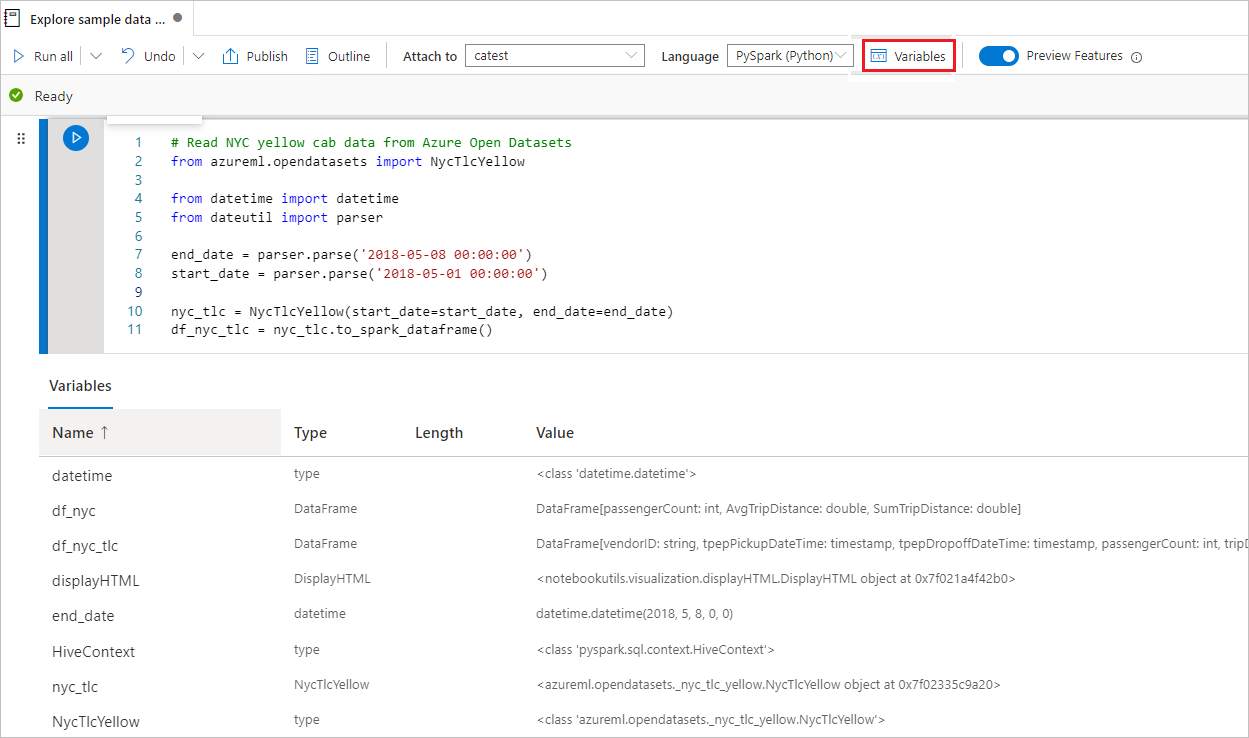
Explorador de variables
El cuaderno de Synapse ahora incluye un explorador de variables integrado para que pueda ver la lista de nombres, tipos, longitudes y valores de las variables en la sesión de Spark actual para las celdas de PySpark (Python). Se mostrarán automáticamente más variables a medida que se definan en las celdas de código. Al hacer clic en cada encabezado de columna se ordenarán las variables de la tabla.
Puede seleccionar el botón Variables de la barra de comandos del cuaderno para abrir u ocultar el explorador de variables.
Nota
El explorador de variables solo admite Python.
Indicador de estado de la celda
Debajo de la celda se muestra un estado de ejecución detallado de la celda para ayudarle a ver su progreso actual. Una vez que se complete la ejecución de la celda, aparecerá un resumen de la ejecución con la duración total y la hora de finalización; este resumen se mantendrá allí para futuras referencias.

Indicador de progreso de Spark
Un cuaderno de Synapse se basa únicamente en Spark. Las celdas de código se ejecutan en el grupo de Apache Spark sin servidor de manera remota. Aparece un indicador de progreso del trabajo de Spark con una barra de progreso en tiempo real que le ayudará a entender el estado de ejecución del trabajo. El número de tareas por cada trabajo o etapa ayuda a identificar el nivel paralelo del trabajo de Spark. También puede profundizar en la interfaz de usuario de Spark de un trabajo o fase específicos a través de la selección del vínculo del nombre del trabajo o de la fase.
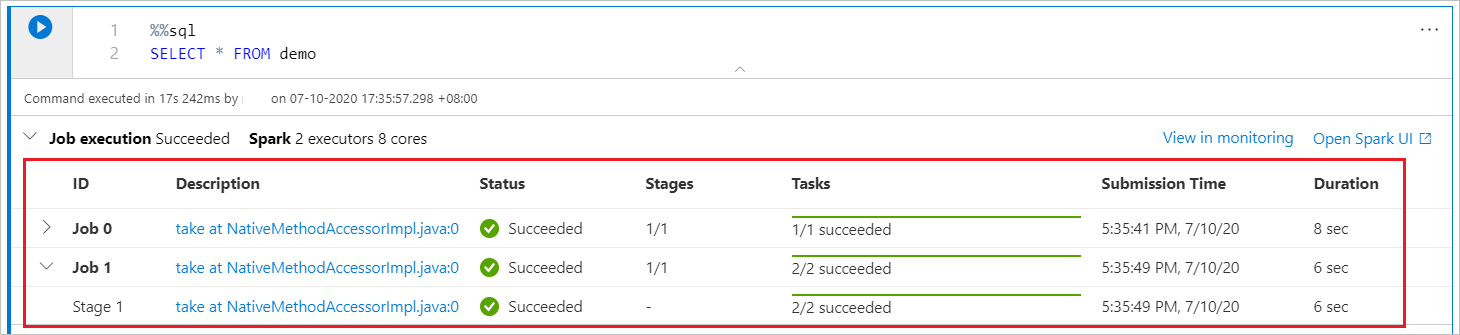
Configuración de la sesión de Spark
Puede especificar la duración del tiempo de espera, el número y el tamaño de los ejecutores que se van a dar a la sesión actual de Spark en Configure session (Configurar sesión). Reinicie la sesión de Spark para que surtan efecto los cambios de configuración. Se borran todas las variables del cuaderno almacenadas en la memoria caché.
También puede crear una configuración a partir de la configuración de Apache Spark o seleccionar una configuración existente. Para más información, consulte Administración de la configuración de Apache Spark.

Comando magic de configuración de la sesión de Spark
También puede especificar la configuración de la sesión de Spark a través de un comando magic %%configure. La sesión de Spark debe reiniciarse para que la configuración surta efecto. Se recomienda ejecutar el comando %%configure al principio del cuaderno. Recuerde que este es un ejemplo; para obtener una lista completa de parámetros válidos puede consultar https://github.com/cloudera/livy#request-body.
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Nota
- Se recomienda que "DriverMemory" y "ExecutorMemory" establezcan el mismo valor en %%configure, así como "driverCores" y "executorCores".
- Puede usar %%configure en canalizaciones de Synapse, pero si no se establece en la primera celda de código, se producirá un error en la ejecución de la canalización debido a que no se puede reiniciar la sesión.
- El elemento %%configure utilizado en mssparkutils.notebook.run se va a omitir, pero utilizado en %run, el cuaderno seguirá ejecutándose.
- Las propiedades de configuración de Spark estándar se deben usar en el cuerpo "conf". No se admite la referencia de primer nivel para las propiedades de configuración de Spark.
- Algunas propiedades especiales de Spark, como "spark.driver.cores", "spark.executor.cores", "spark.driver.memory", "spark.executor.memory" y "spark.executor.instances", no tendrán efecto en el cuerpo "conf".
Configuración de sesión parametrizada desde la canalización
La configuración de sesión parametrizada permite reemplazar el valor de %%configure magic por los parámetros de ejecución de la canalización (actividad del cuaderno). Al preparar la celda de código %%configure, puede invalidar los valores predeterminados (también configurables, 4 y "2000" en el ejemplo siguiente) con un objeto como este:
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
El cuaderno usa el valor predeterminado si ejecuta un cuaderno directamente en modo interactivo o no se proporciona ningún parámetro que coincida con "activityParameterName" desde la actividad del cuaderno de la canalización.
Durante el modo de ejecución de la canalización, puede configurar las opciones de la actividad del cuaderno de la canalización como se indica a continuación: 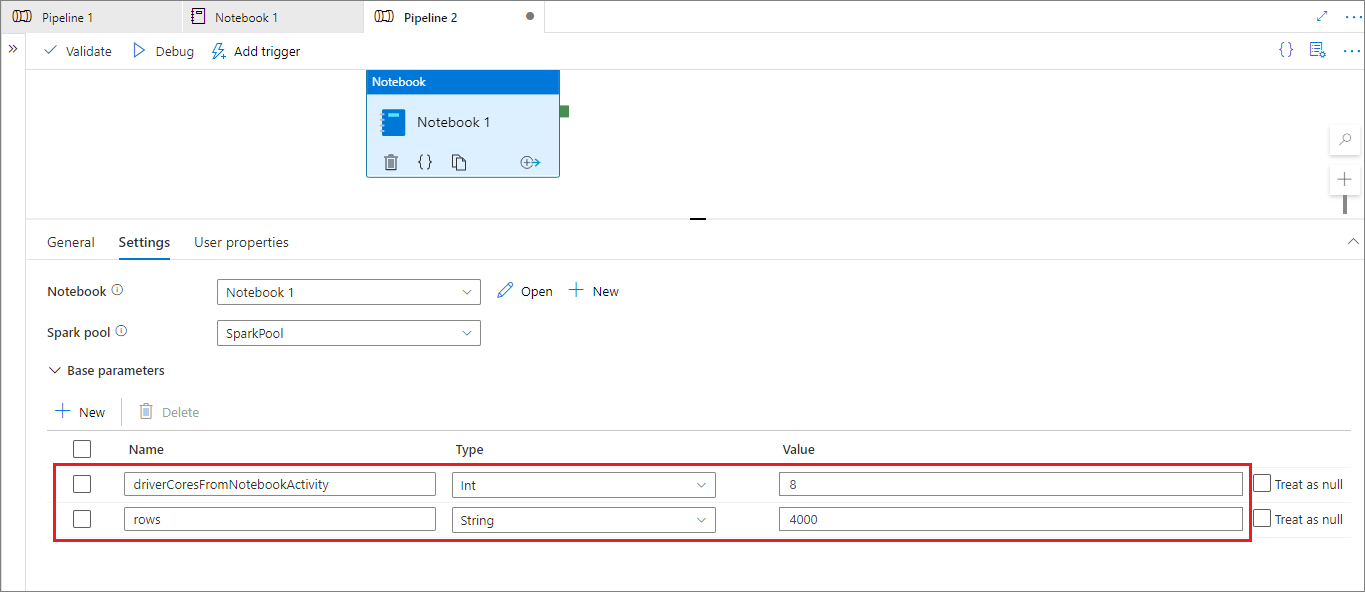
Si desea cambiar la configuración de sesión, el nombre de los parámetros de la actividad del cuaderno de la canalización debe ser igual que el valor de activityParameterName en el cuaderno. Al ejecutar esta canalización, en este ejemplo driverCores de %%configure se reemplazará por 8 y livy.rsc.sql.num-rows se reemplazará por 4000.
Nota
Si se produce un error en la ejecución de la canalización debido al uso de este nuevo comando magic %%configure, puede comprobar más información del error mediante la ejecución de la celda magic %%configure en el modo interactivo del cuaderno.
Traslado de los datos a un cuaderno
Puede cargar datos desde Azure Blob Storage, Azure Data Lake Store Gen2 y el grupo de SQL, tal como se muestra en los ejemplos de código siguientes.
Lectura de un archivo CSV desde Azure Data Lake Store Gen2 como DataFrame de Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Lectura de un archivo CSV desde Azure Blob Storage como DataFrame de Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Lectura de datos desde la cuenta de almacenamiento principal
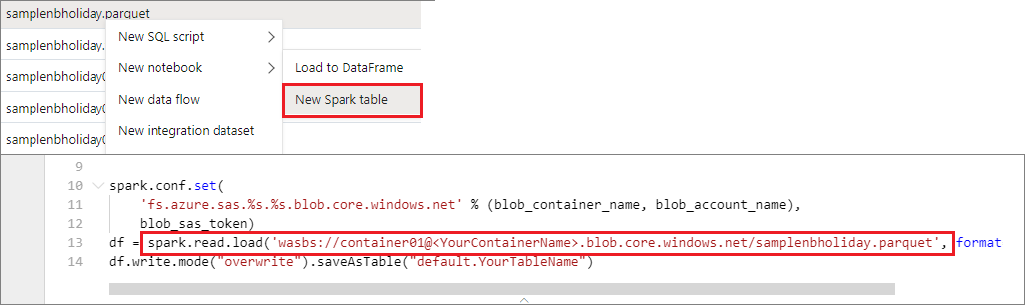
Puede tener acceso directamente a los datos de la cuenta de almacenamiento principal. No hay necesidad de proporcionar las claves secretas. En Explorador de datos, haga clic con el botón derecho en un archivo y seleccione Nuevo cuaderno para ver un nuevo cuaderno con el extractor de datos generado automáticamente.
Widgets de IPython
Los widgets son objetos de Python con eventos que tienen una representación en el explorador, a menudo, como un control deslizante, un cuadro de texto, etc. Los widgets de IPython solo funcionan en el entorno de Python; aún no se admiten en otros lenguajes (por ejemplo, Scala, SQL, C#).
Para usar el widget de IPython
Primero debe importar el módulo
ipywidgetspara usar el marco del widget de Jupyter.import ipywidgets as widgetsPuede usar la función
displayde nivel superior para representar un widget, o dejar una expresión de tipo widget en la última línea de celda de código.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderEjecute la celda y el widget se mostrará en el área de salida.
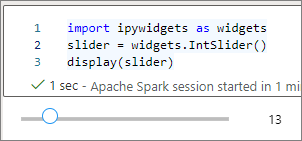
Puede usar varias llamadas de
display()para representar la misma instancia de widget varias veces, pero permanecerán sincronizadas entre sí.slider = widgets.IntSlider() display(slider) display(slider)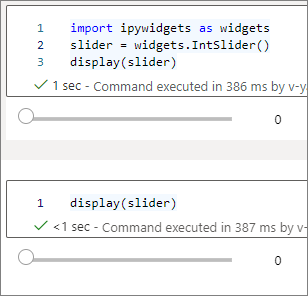
Para representar dos widgets independientes entre sí, cree dos instancias de widget:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
Widgets admitidos
| Tipo de widgets | Widgets |
|---|---|
| Widgets numéricos | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Widgets booleanos | ToggleButton, Checkbox, Valid |
| Widgets de selección | Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Widgets de cadena | Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Widgets de reproducción (animación) | Date picker, Color picker, Controller |
| Widgets de contenedor/diseño | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Limitaciones conocidas
Los widgets siguientes aún no se admiten, puede seguir la solución alternativa correspondiente como se indica a continuación:
Funcionalidad Solución alternativa Widget OutputPuede usar la función print()en su lugar para escribir texto en stdout.widgets.jslink()Puede usar la función widgets.link()para vincular dos widgets similares.Widget FileUploadTodavía no se admite. La función
displayglobal proporcionada por Synapse no admite la visualización de varios widgets en una llamada (es decir,display(a, b)), que es diferente de la funcióndisplayde IPython.Si cierra un cuaderno que contiene el widget de IPython, no podrá verlo ni interactuar con él hasta que vuelva a ejecutar la celda correspondiente.
Guardado de cuadernos
Puede guardar un único cuaderno o todos los cuadernos en el área de trabajo.
Para guardar los cambios realizados en un solo cuaderno, seleccione el botón Publicar en la barra de comandos del cuaderno.

Para guardar todos los cuadernos en el área de trabajo, seleccione el botón Publicar todo en la barra de comandos del área de trabajo.

En las propiedades del cuaderno, puede configurar si incluir la salida de la celda al guardar.
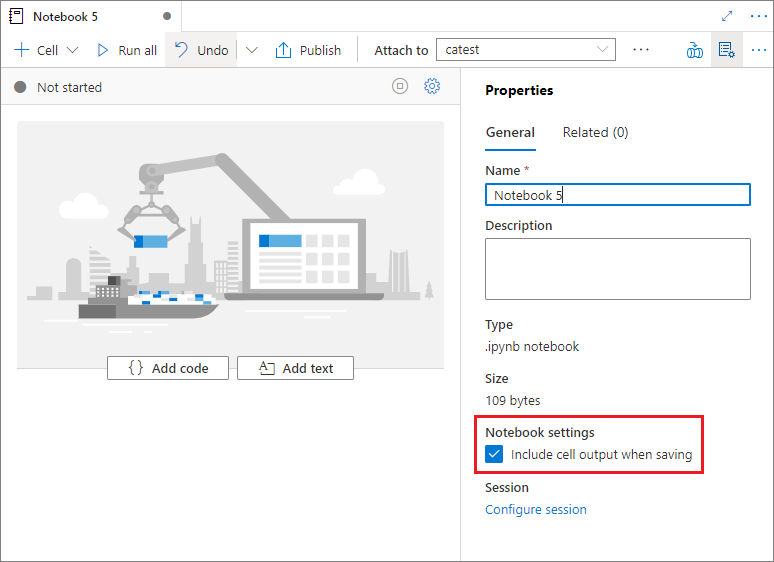
Comandos magic
Puede usar los comandos magic de Jupyter que ya conoce en los cuadernos de Synapse. Revise la lista siguiente para ver los comandos magic disponibles actualmente. Indíquenos sus casos de uso en GitHub para que podamos seguir generando más comandos magic para satisfacer sus necesidades.
Nota
Solo se admiten los comandos magic siguientes en una canalización de Synapse: %%pyspark, %%spark, %%csharp, %%sql.
Comandos magic de línea disponibles: %lsmagic, %time, %timeit, %history, %run, %load
Comandos magic de celda disponibles: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Referencia a un cuaderno no publicado
Hacer referencia a un cuaderno no publicado es útil cuando se quiere depurar "localmente". Al habilitar esta característica, la ejecución de cuadernos captura el contenido actual de la caché web. Si ejecuta una celda que incluye una instrucción de cuadernos de referencia, se hace referencia a los cuadernos que se presentan en el explorador de cuadernos actual en lugar de a las versiones guardadas en el clúster, lo que significa que otros cuadernos pueden hacer referencia inmediatamente a los cambios en el editor de cuadernos sin tener que publicarse (modo directo) o confirmarse (modo Git). Al aprovechar este enfoque, puede evitar fácilmente que las bibliotecas comunes se desvíen durante el proceso de desarrollo o depuración.
Puede habilitar el cuaderno sin publicar de Referencia desde el panel Propiedades:
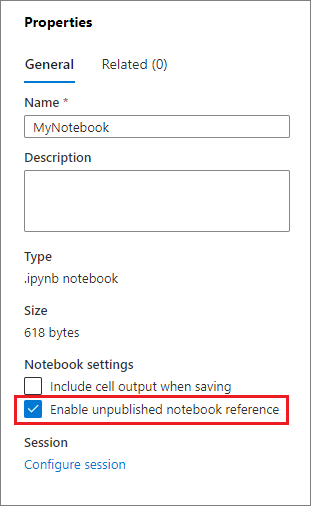
Para la comparación de distintos casos, consulte la tabla siguiente:
Observe que %run y mssparkutils.notebook.run tienen el mismo comportamiento aquí. Aquí se usa %run como ejemplo.
| Caso | Disable | Habilitar |
|---|---|---|
| Modo directo | ||
- Nb1 (publicado) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución de la versión publicada de Nb1 |
- Nb1 (nuevo) %run Nb1 |
Error | Ejecución del nuevo Nb1 |
- Nb1 (publicado previamente, editado) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución de la versión editada de Nb1 |
| Modo Git | ||
- Nb1 (publicado) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución de la versión publicada de Nb1 |
- Nb1 (nuevo) %run Nb1 |
Error | Ejecución del nuevo Nb1 |
- Nb1 (no publicado, confirmado) %run Nb1 |
Error | Ejecución de Nb1 confirmado |
- Nb1 (publicado previamente, confirmado) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución de la versión confirmada de Nb1 |
- Nb1 (publicado anteriormente, nuevo en la rama actual) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución del nuevo Nb1 |
- Nb1 (no publicado, confirmado previamente, editado) %run Nb1 |
Error | Ejecución de la versión editada de Nb1 |
- Nb1 (publicado y confirmado previamente, editado) %run Nb1 |
Ejecución de la versión publicada de Nb1 | Ejecución de la versión editada de Nb1 |
Conclusión
- Si está deshabilitado, se ejecuta siempre la versión publicada.
- Si está habilitada, la ejecución de referencia siempre adoptará la versión actual del cuaderno que puede ver en la experiencia de usuario del cuaderno.
Administración de sesiones activas
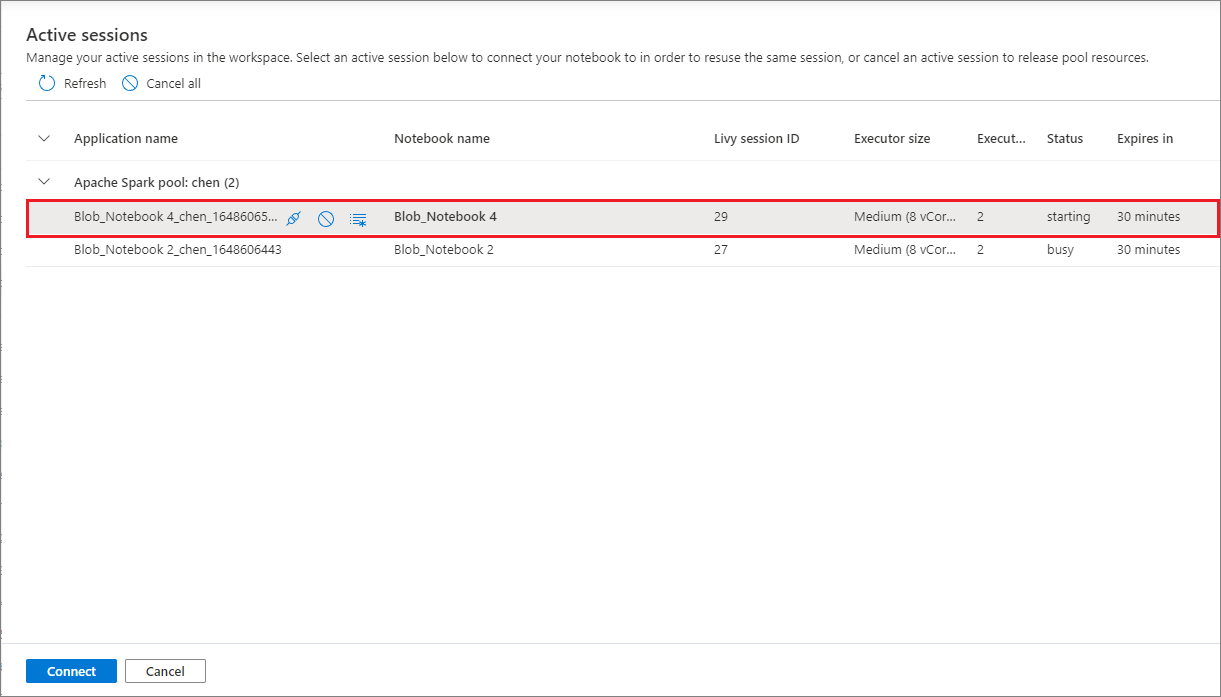
Ahora puede reutilizar las sesiones de los cuadernos cómodamente sin tener que iniciar otras nuevas. Ahora el cuaderno de Synapse admite la administración de las sesiones activas. En la lista Administrar sesiones, verá todas las sesiones del área de trabajo actual que haya iniciado desde el cuaderno.
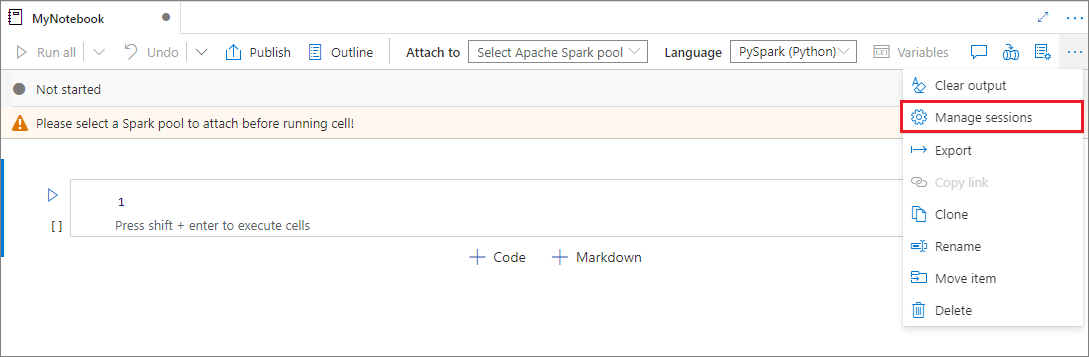
En la lista Sesiones activas, verá la información de la sesión y el cuaderno correspondiente que en ese momento está asociado a la sesión. Puede operar Desasociar con el cuaderno, Detener la sesión y Ver en supervisión desde aquí. Es más, puede conectar fácilmente el cuaderno seleccionado a una sesión activa de la lista iniciada desde otro cuaderno; la sesión se desasociará del cuaderno anterior (si no está inactiva) para luego asociarse al actual.
Registro de Python en Notebook
Puede encontrar registros de Python y establecer diferentes niveles de registro y formatos siguiendo el siguiente código de ejemplo:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Visualización del historial de comandos de entrada
Synapse Notebook admite el comando mágico %history para imprimir el historial de comandos de entrada que se ejecutó en la sesión actual, comparando con el comando estándar de Jupyter Ipython que el %history funciona para varios lenguajes de contexto en el cuaderno.
%history [-n] [range [range ...]]
Opciones:
- -n: número de ejecución de impresión.
Donde el rango puede ser:
- N: imprime el código de la celda ejecutada número N.
- M-N: imprime el código desde la celda ejecutada número M a la celda ejecutada número N.
Ejemplo:
- Imprime el historial de entrada de la primera a la segunda celda ejecutada:
%history -n 1-2
Integración de un cuaderno
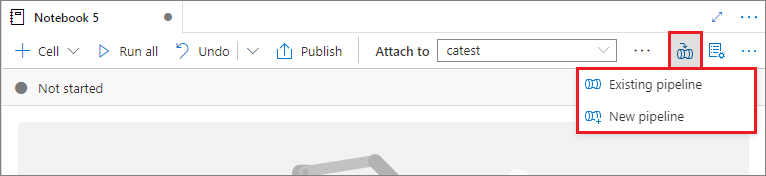
Adición de un cuaderno a una canalización
Seleccione el botón Agregar a la canalización en la esquina superior derecha para agregar un cuaderno a una canalización existente o crear una canalización.
Designación de una celda de parámetros
Para parametrizar el cuaderno, seleccione los puntos suspensivos (...) para obtener acceso a más comandos en la barra de herramientas de la celda. A continuación, seleccione Toggle parameter cell (Alternar celda de parámetros) para designar la celda como la celda de parámetros.
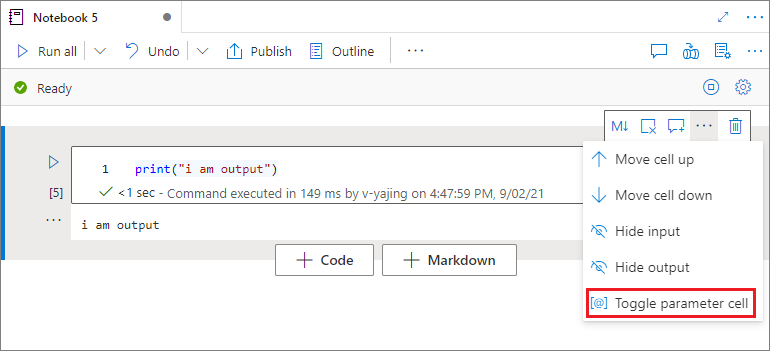
Azure Data Factory busca la celda de parámetros y la trata como valores predeterminados para los parámetros que se pasan en tiempo de ejecución. El motor de ejecución agregará una nueva celda debajo de la celda de parámetros con parámetros de entrada para sobrescribir los valores predeterminados.
Asignación de valores de parámetros de una canalización
Una vez que haya creado un cuaderno con parámetros, podrá ejecutarlo desde una canalización con la actividad de cuadernos de Synapse. Después de agregar la actividad al lienzo de la canalización, podrá establecer los valores de los parámetros en la sección Parámetros base de la pestaña Configuración.
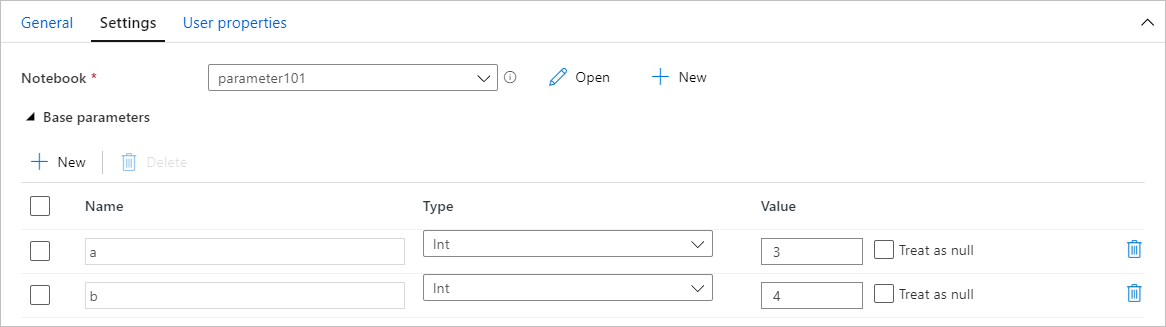
Al asignar valores de parámetros, puede usar el lenguaje de expresiones de canalización o las variables del sistema.
Teclas de método abreviado
De forma similar a los cuadernos de Jupyter Notebook, los cuadernos de Synapse tienen una interfaz de usuario modal. El teclado realiza diferentes acciones en función del modo en que se encuentre la celda del cuaderno. Los cuadernos de Synapse admiten los dos modos siguientes para una celda de código determinada: modo de comando y modo de edición.
Una celda se encuentra en modo de comando cuando no hay ningún cursor de texto que le pida que escriba. Cuando una celda está en modo de comando, puede editar el cuaderno en su conjunto, pero no escribir en celdas individuales. Para ingresar al modo de comando, presione
ESCo use el mouse para seleccionar fuera del área del editor de una celda.
El modo de edición se indica mediante un cursor de texto que le pide que escriba en el área del editor. Cuando una celda se encuentra en modo de edición, puede escribir en la celda. Para ingresar al modo de edición, presione
Entero use el mouse para seleccionar en el área del editor de una celda.
Teclas de método abreviado en el modo de comando
| Acción | Métodos abreviados de teclado de los cuadernos de Synapse |
|---|---|
| Ejecutar la celda actual y seleccionar la que está a continuación | Mayús+Entrar |
| Ejecutar la celda actual e insertar una a continuación | Alt+Entrar |
| Ejecutar celda actual | Ctrl+Entrar |
| Seleccionar la celda anterior | Arriba |
| Seleccionar la celda siguiente | Bajar |
| Seleccionar celda anterior | K |
| Seleccionar celda siguiente | J |
| Insertar una celda encima | A |
| Insertar una celda debajo | B |
| Eliminar celdas seleccionadas | Mayús+D |
| Cambiar al modo de edición | Escriba |
Teclas de método abreviado en el modo de edición
Con los siguientes métodos abreviados de teclado, puede desplazarse y ejecutar código más fácilmente en los cuadernos de Synapse cuando esté en modo de edición.
| Acción | Métodos abreviados de teclado de los cuadernos de Synapse |
|---|---|
| Subir el cursor | Arriba |
| Bajar el cursor | Bajar |
| Deshacer | CTRL+Z |
| Rehacer | CTRL+Y |
| Comentar y quitar comentario | CTRL+/ |
| Eliminar palabra anterior | CTRL+Retroceso |
| Eliminar palabra posterior | CTRL+Supr |
| Ir al inicio de la celda | CTRL+Inicio |
| Ir al final de la celda | CTRL+Fin |
| Ir una palabra a la izquierda | CTRL+Izquierda |
| Ir una palabra a la derecha | CTRL+Derecha |
| Seleccionar todo | CTRL+A |
| Aplicar sangría | Ctrl +] |
| Desaplicar sangría | CTRL+[ |
| Cambiar al modo de comando | Esc |
Pasos siguientes
- Consulte los cuadernos de ejemplo de Synapse
- Inicio rápido: Creación de un grupo de Apache Spark en Azure Synapse Analytics mediante herramientas web
- Qué es Apache Spark en Azure Synapse Analytics
- Uso de .NET para Apache Spark con Azure Synapse Analytics
- Documentación de .NET para Apache Spark
- Azure Synapse Analytics
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de