Grupos de Apache Spark acelerados por GPU en Azure Synapse Analytics (versión preliminar)
Apache Spark es una plataforma de procesamiento paralelo que admite el procesamiento en memoria para mejorar el rendimiento de aplicaciones de análisis de macrodatos. Apache Spark en Azure Synapse Analytics es una de las implementaciones de Microsoft de Apache Spark en la nube.
Azure Synapse ahora ofrece la capacidad de crear grupos habilitados para GPU de Azure Synapse para ejecutar cargas de trabajo de Spark mediante bibliotecas de RAPIDS subyacentes que utilizan la enorme potencia de procesamiento paralelo de las GPU para acelerar el procesamiento. El acelerador RAPIDS para Apache Spark permite ejecutar las aplicaciones de Spark existentes sin ningún cambio de código mediante la habilitación de una opción de configuración, que viene preconfigurada para un grupo habilitado para GPU. Puede optar por activar o desactivar la aceleración de GPU basada en RAPIDS para la carga de trabajo, o partes de ella, estableciendo esta configuración:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Nota
Los grupos de Azure Synapse habilitados para GPU están actualmente en versión preliminar pública.
Advertencia
- La versión preliminar acelerada por GPU se limita al entorno de ejecución deApache Spark 3.2 (fin de soporte técnico anunciado). Final del soporte técnico anunciado para Azure Synapse Runtime para Apache Spark 3.2 se ha anunciado el 8 de julio de 2023. El final del soporte técnico anunciado en tiempo de ejecución no tendrá correcciones de errores y características. Las correcciones de seguridad se realizarán en función de la evaluación de riesgos. Este tiempo de ejecución y la versión preliminar acelerada de GPU correspondiente en Spark 3.2 se retirarán y deshabilitarán a partir del 8 de julio de 2024.
- La versión preliminar acelerada por GPU ahora no se admite en el entorno de ejecución de Azure Synapse 3.1 (no compatible). El 26 de enero de 2023 el entorno de ejecución de Azure Synapse para Apache Spark 3.1 ha alcanzado su fin de soporte técnico, por lo que a partir del 26 de enero de 2024 se interrumpirá el soporte técnico oficial y no se atenderán más incidencias de soporte técnico, correcciones de errores ni actualizaciones de seguridad después de esta fecha.
Acelerador RAPIDS para Apache Spark
El acelerador RAPIDS para Spark es un complemento que funciona invalidando el plan físico de un trabajo de Spark mediante operaciones de GPU admitidas y ejecutando esas operaciones en las GPU, lo que acelera el procesamiento. Esta biblioteca se encuentra actualmente en versión preliminar y no admite todas las operaciones de Spark (esta es una lista de los operadores que se admiten actualmente y se agregará más compatibilidad incrementalmente a través de nuevas versiones).
Opciones de configuración del clúster
El complemento Acelerador RAPIDS solo admite una asignación uno a uno entre GPU y ejecutores, lo que significa que un trabajo de Spark tendría que solicitar recursos de ejecutor y de controlador a los que los recursos del grupo puedan alojar (en función del número de núcleos de CPU y GPU disponibles). Para cumplir esta condición y garantizar el uso óptimo de todos los recursos del grupo, se requiere la siguiente configuración de los controladores y ejecutores en una aplicación de Spark que se ejecuta en grupos habilitados para GPU:
| Tamaño del grupo | Opciones de tamaño del controlador | Núcleos de controlador | Memoria del controlador (GB) | Núcleos del ejecutor | Memoria del ejecutor (GB) | Número de ejecutores |
|---|---|---|---|---|---|---|
| GPU grande | Controlador pequeño | 4 | 30 | 12 | 60 | Número de nodos en el grupo |
| GPU grande | Controlador medio | 7 | 30 | 9 | 60 | Número de nodos en el grupo |
| GPU extra grande | Controlador medio | 8 | 40 | 14 | 80 | 4 * Número de nodos en el grupo |
| GPU extra grande | Controlador grande | 12 | 40 | 13 | 80 | 4 * Número de nodos en el grupo |
No se aceptará ninguna carga de trabajo que no cumpla una de las configuraciones anteriores. Esto se hace para asegurarse de que los trabajos de Spark se ejecutan con la configuración más eficaz mediante todos los recursos disponibles en el grupo.
El usuario puede establecer la configuración anterior a través de su carga de trabajo. En el caso de los cuadernos, el usuario puede utilizar el comando magic %%configure para establecer una de las configuraciones anteriores, como se muestra a continuación.
Por ejemplo, mediante un grupo grande con tres nodos:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Ejecución de un trabajo de Spark de ejemplo a través de un cuaderno en un grupo acelerado por GPU de Azure Synapse
Sería conveniente conocer los conceptos básicos de cómo usar los cuadernos en Azure Synapse Analytics antes de continuar con esta sección. Vamos a seguir los pasos necesarios para ejecutar una aplicación de Spark que utiliza la aceleración de GPU. Puede escribir una aplicación Spark en los cuatro lenguajes admitidos en Synapse: PySpark (Python), Spark (Scala), SparkSQL y .NET para Spark (C#).
Cree un grupo habilitado para GPU.
Cree un cuaderno y adjúntelo al grupo habilitado para GPU que creó en el primer paso.
Establezca las configuraciones como se explicó en la sección anterior.
Cree un dataframe de ejemplo, para lo que debe copiar el código siguiente en la primera celda del cuaderno:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- Ahora vamos a hacer un agregado obteniendo el sueldo máximo por identificador de departamento y a mostrar el resultado:
- Para ver las operaciones de la consulta que se ejecutaron en GPU, consulte el plan de SQL a través del servidor de historial de Spark:
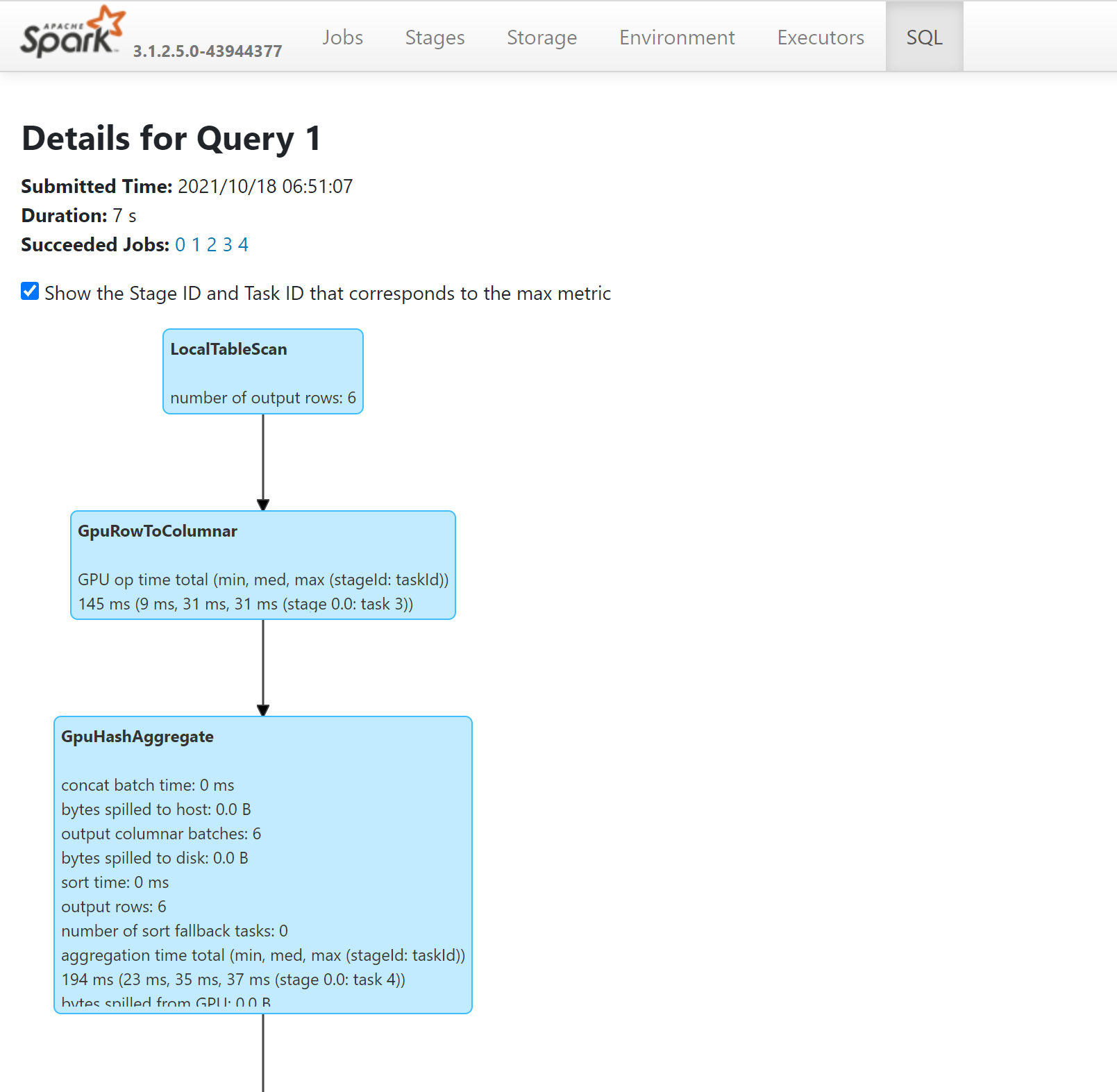
Ajuste de una aplicación para las GPU
En la mayoría de los trabajos de Spark, el rendimiento puede mejorar si se ajusta su configuración cambiando los valores predeterminados, y lo mismo se aplica a los trabajos que aprovechan el complemento del acelerador RAPIDS para Apache Spark.
Cuotas y restricciones de recursos en los grupos habilitados para GPU de Azure Synapse
Nivel de área de trabajo
Cada área de trabajo de Azure Synapse incluye una cuota predeterminada de 50 núcleos virtuales de GPU. Para aumentar la cuota de núcleos de GPU, envíe una solicitud de soporte técnico a través de Azure Portal.
Pasos siguientes
Comentaris
Properament: al llarg del 2024 eliminarem gradualment GitHub Issues com a mecanisme de retroalimentació del contingut i el substituirem per un nou sistema de retroalimentació. Per obtenir més informació, consulteu: https://aka.ms/ContentUserFeedback.
Envieu i consulteu els comentaris de