Zjistitelné typy kritických bodů výkonu dotazů ve službě Azure SQL Database
Platí pro:![]() Azure SQL Database
Azure SQL Database
Při pokusu o řešení kritického bodu výkonu nejprve zjistěte, jestli kritický bod nastává, když je dotaz spuštěný nebo čekající. Podle zjištěného výsledku se bude lišit i řešení. Následující diagram vám pomůže pochopit faktory, které můžou způsobit problém související se spuštěním nebo problém související s čekáním. Problémy a řešení související s jednotlivými typy problémů jsou popsány v tomto článku.
K detekci těchto typů kritických bodů výkonu můžete použít zobrazení dynamické správy služby Intelligent Insights nebo SQL Server.
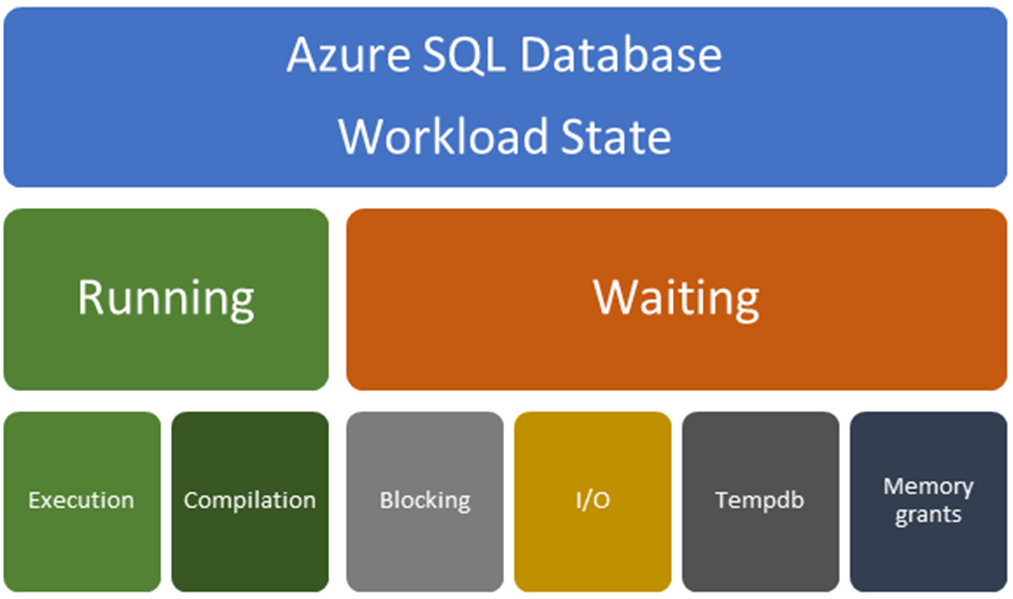
Problémy související se spuštěním: Problémy související se spuštěním obvykle souvisejí s problémy kompilace, což vede k neoptimálnímu plánu dotazů nebo problémům se spuštěním souvisejícím s nedostatečnými nebo nadměrně nevyuživovanými prostředky. Problémy související s čekáním: Problémy související s čekáním obecně souvisejí s:
- Zámky (blokování)
- I/O
- Kolize související s
tempdbvyužitím - Čekání na přidělení paměti
Tento článek se zabývá službou Azure SQL Database, viz také zjistitelné typy kritických bodů výkonu dotazů ve službě Azure SQL Managed Instance.
Problémy kompilace, které vedou k neoptimálnímu plánu dotazů
Neoptimální plán vygenerovaný optimalizátorem dotazů SQL může být příčinou pomalého výkonu dotazů. Optimalizátor dotazů SQL může vytvořit neoptimální plán z důvodu chybějícího indexu, zastaralé statistiky, nesprávného odhadu počtu zpracovávaných řádků nebo nepřesného odhadu požadované paměti. Pokud víte, že se dotaz spustil rychleji v minulosti nebo v jiné databázi, porovnejte skutečné plány provádění a zjistěte, jestli se liší.
Pomocí jedné z těchto metod identifikujte všechny chybějící indexy:
- Používejte Intelligent Insights.
- Projděte si doporučení v nástroji Database Advisor pro izolované databáze a databáze ve fondu ve službě Azure SQL Database. Můžete také povolit možnosti automatického ladění pro ladění indexů pro Azure SQL Database.
- Chybějící indexy v zobrazení dynamické správy a plánech provádění dotazů V tomto článku se dozvíte, jak zjišťovat a ladit neclusterované indexy pomocí chybějících požadavků indexu.
Pokuste se aktualizovat statistiky nebo znovu sestavit indexy , abyste získali lepší plán. Povolte automatickou opravu plánu, abyste tyto problémy automaticky zmírňovali.
Jako pokročilý krok řešení potíží použijte nápovědy úložiště dotazů k použití nápovědy k dotazům pomocí úložiště dotazů, aniž byste museli provádět změny kódu.
Tento příklad ladění a nápovědy dotazu ukazuje dopad neoptimálního plánu dotazu z důvodu parametrizovaného dotazu, zjištění této podmínky a použití nápovědy k vyřešení dotazu.
Zkuste změnit úroveň kompatibility databáze a implementovat inteligentní zpracování dotazů. Optimalizátor dotazů SQL může vygenerovat jiný plán dotazů v závislosti na úrovni kompatibility pro vaši databázi. Vyšší úrovně kompatibility poskytují inteligentnější možnosti zpracování dotazů.
- Další informace o zpracování dotazů naleznete v tématu Průvodce architekturou zpracování dotazů.
- Pokud chcete změnit úrovně kompatibility databáze a přečíst si další informace o rozdílech mezi úrovněmi kompatibility, přečtěte si téma ALTER DATABASE.
- Další informace o odhadu kardinality najdete v tématu Odhad kardinality.
Řešení dotazů pomocí neoptimálních plánů spouštění dotazů
V následujících částech se dozvíte, jak vyřešit dotazy pomocí neoptimálního plánu provádění dotazů.
Dotazy s problémy s plánem citlivým na parametry (PSP)
K problému s plánem citlivým na parametry (PSP) dochází, když optimalizátor dotazů vygeneruje plán provádění dotazu, který je optimální pouze pro konkrétní hodnotu parametru (nebo sadu hodnot) a plán uložený v mezipaměti není optimální pro hodnoty parametrů, které se používají při po sobě jdoucích spuštěních. Plány, které nejsou optimální, pak můžou způsobit problémy s výkonem dotazů a snížit celkovou propustnost úloh.
Další informace o zpracování parametrů a zpracování dotazů najdete v průvodci architekturou zpracování dotazů.
Několik alternativních řešení může zmírnit problémy s PSP. Každé alternativní řešení má přidružené kompromisy a nevýhody:
- Nová funkce představená s SQL Serverem 2022 (16.x) je optimalizace plánu citlivého na parametry, která se snaží zmírnit většinu neoptimálních plánů dotazů způsobených citlivostí parametrů. Tato možnost je povolená s úrovní kompatibility databáze 160 ve službě Azure SQL Database.
- Při každém spuštění dotazu použijte nápovědu k dotazu RECOMPILE . Toto alternativní řešení obchoduje s časem kompilace a zvýšením využití procesoru za lepší kvalitu plánu. Tato
RECOMPILEmožnost často není možná u úloh, které vyžadují vysokou propustnost. - Pomocí nápovědy dotazu OPTION (OPTIMIZE FOR...) můžete přepsat skutečnou hodnotu parametru typickou hodnotou parametru, která vytvoří plán, který je dostatečný pro většinu možností hodnot parametrů. Tato možnost vyžaduje dobré porozumění optimálním hodnotám parametrů a přidruženým charakteristikám plánu.
- Pomocí nápovědy dotazu OPTION (OPTIMIZE FOR UNKNOWN) přepište skutečnou hodnotu parametru a místo toho použijte průměr vektoru hustoty. Můžete to také provést zachycením příchozích hodnot parametrů v místních proměnných a následným použitím místních proměnných v predikátech namísto použití samotných parametrů. Pro tuto opravu musí být průměrná hustota dostatečně dobrá.
- Pomocí nápovědy k dotazu DISABLE_PARAMETER_SNIFFING úplně zakažte zašifrování parametrů.
- Nápovědu k dotazu KEEPFIXEDPLAN použijte k zabránění rekompilace v mezipaměti. Toto alternativní řešení předpokládá, že dostatečný společný plán je ten, který už je v mezipaměti. Automatické aktualizace statistik můžete také zakázat, aby se snížila pravděpodobnost vyřazení dobrého plánu a zkompiluje se nový chybný plán.
- Vynuťte plán explicitním použitím nápovědy dotazu USE PLAN přepsáním dotazu a přidáním nápovědy do textu dotazu. Nebo můžete nastavit konkrétní plán pomocí úložiště dotazů nebo povolením automatického ladění.
- Nahraďte jeden postup vnořenou sadou procedur, které lze použít na základě podmíněné logiky a přidružených hodnot parametrů.
- Vytvořte alternativy dynamického provádění řetězců k definici statické procedury.
Pokud chcete použít nápovědu k dotazům, upravte dotaz nebo použijte nápovědu k použití nápovědy , aniž byste museli provádět změny kódu.
Další informace o řešení problémů s PSP naleznete v těchto blogových příspěvcích:
Aktivita kompilace způsobená nesprávnou parametrizací
Pokud dotaz obsahuje literály, databázový stroj příkaz automaticky parametrizuje nebo uživatel explicitně parametrizuje příkaz, aby snížil počet kompilací. Vysoký počet kompilací dotazu, který používá stejný vzor, ale různé literálové hodnoty, může vést k vysokému využití procesoru. Podobně platí, že pokud dotaz, který stále obsahuje literály, parametrizujete pouze částečně, databázový stroj ho dále neparametrizuje.
Tady je příklad částečně parametrizovaného dotazu:
SELECT *
FROM t1 JOIN t2 ON t1.c1 = t2.c1
WHERE t1.c1 = @p1 AND t2.c2 = '961C3970-0E54-4E8E-82B6-5545BE897F8F';
V tomto příkladu přebírá @p1řetězec t1.c1 GUID jako literál, ale t2.c2 nadále přebírá identifikátor GUID. Pokud v tomto případě změníte hodnotu pro c2, dotaz se považuje za jiný dotaz a dojde k nové kompilaci. Chcete-li snížit kompilace v tomto příkladu, byste také parametrizovali identifikátor GUID.
Následující dotaz ukazuje počet dotazů podle hodnoty hash dotazu, abyste zjistili, jestli je dotaz správně parametrizovaný:
SELECT TOP 10
q.query_hash
, count (distinct p.query_id ) AS number_of_distinct_query_ids
, min(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
AND query_parameterization_type_desc IN ('User', 'None')
GROUP BY q.query_hash
ORDER BY count (distinct p.query_id) DESC;
Faktory ovlivňující změny plánu dotazů
Rekompilace plánu spuštění dotazu může mít za následek vygenerovaný plán dotazu, který se liší od původního plánu uloženého v mezipaměti. Existující původní plán se může automaticky znovu zkompilovat z různých důvodů:
- Na změny ve schématu odkazuje dotaz.
- Na změny dat v tabulkách odkazuje dotaz.
- Změnily se možnosti kontextu dotazu.
Zkompilovaný plán může být vysunut z mezipaměti z různých důvodů, například:
- Instance se restartuje
- Změny konfigurace v oboru databáze
- Zatížení paměti
- Explicitní žádosti o vymazání mezipaměti
Pokud použijete nápovědu k rekompilu, plán se neuloží do mezipaměti.
Rekompilace (nebo čerstvá kompilace po vyřazení mezipaměti) může vést k vytvoření plánu provádění dotazu, který je stejný jako původní. Pokud se plán změní z předchozího nebo původního plánu, jsou pravděpodobně následující vysvětlení:
Změna fyzického návrhu: Nově vytvořené indexy například efektivněji pokrývají požadavky dotazu. Nové indexy se můžou použít při nové kompilaci, pokud se optimalizátor dotazů rozhodne, že použití tohoto nového indexu je optimální než použití datové struktury, která byla původně vybrána pro první verzi provádění dotazu. Jakékoli fyzické změny odkazovaných objektů můžou mít za následek novou volbu plánu v době kompilace.
Rozdíly mezi prostředky serveru: Pokud se plán v jednom systému liší od plánu v jiném systému, může dostupnost prostředků, například počet dostupných procesorů, ovlivnit, který plán se vygeneruje. Pokud má například jeden systém více procesorů, může být zvolen paralelní plán. Další informace o paralelismu ve službě Azure SQL Database najdete v tématu Konfigurace maximálního stupně paralelismu (MAXDOP) ve službě Azure SQL Database.
Různé statistiky: Statistiky spojené s odkazovanými objekty se mohly změnit nebo se můžou výrazně lišit od statistik původního systému. Pokud dojde ke změně statistiky a rekompilace, optimalizátor dotazů použije statistiky začínající při změně. Distribuce a četnosti revidovaných statistik se mohou lišit od distribucí dat původní kompilace. Tyto změny se používají k vytvoření odhadů kardinality. (Odhady kardinality jsou počet řádků, které se mají projít stromem logického dotazu.) Změny odhadů kardinality můžou vést k výběru různých fyzických operátorů a přidružených objednávek operací. I menší změny statistiky můžou vést ke změně plánu provádění dotazů.
Změna úrovně kompatibility databáze nebo verze estimátoru kardinality: Změny na úrovni kompatibility databáze můžou povolit nové strategie a funkce, které můžou vést k jinému plánu provádění dotazů. Mimo úroveň kompatibility databáze můžou zakázané nebo povolené příznaky trasování 4199 nebo změněný stav QUERY_OPTIMIZER_HOTFIXES konfigurace v rozsahu databáze ovlivnit také možnosti plánu spouštění dotazů v době kompilace. Příznak trasování 9481 (vynucení starší verze CE) a 2312 (vynucení výchozího CE) také ovlivní plán.
Problémy s limity prostředků
Nízký výkon dotazů nesouvisejí s neoptimálními plány dotazů a chybějícími indexy obecně souvisí s nedostatečnými nebo nadměrně nevyuživovanými prostředky. Pokud je plán dotazu optimální, může dotaz (a databáze) dosáhnout limitů prostředků pro databázi nebo elastický fond. Příkladem může být nadbytečná propustnost zápisu protokolu pro úroveň služby.
Zjištění problémů s prostředky pomocí webu Azure Portal: Pokud chcete zjistit, jestli se jedná o omezení prostředků, projděte si monitorování prostředků služby SQL Database. Informace o jednoúčelových databázích a elastických fondech najdete v doporučeních k výkonu nástroje Database Advisor a Query Performance Insights.
Zjišťování limitů prostředků pomocí Intelligent Insights
Zjišťování problémů s prostředky pomocí zobrazení dynamické správy:
- Sys.dm_db_resource_stats zobrazení dynamické správy vrátí procesor, vstupně-výstupní operace a spotřebu paměti pro databázi. Jeden řádek existuje pro každý 15sekundový interval, i když v databázi není žádná aktivita. Historická data se uchovávají po dobu jedné hodiny.
- Zobrazení dynamické správy sys.resource_stats vrací data o využití procesoru a úložišti pro Azure SQL Database. Data se shromažďují a agregují v pětiminutových intervalech.
- Mnoho jednotlivých dotazů, které kumulativní spotřebovávají vysoké využití procesoru
Pokud problém identifikujete jako nedostatečný prostředek, můžete upgradovat prostředky, abyste zvýšili kapacitu databáze, aby absorbovaly požadavky na procesor. Další informace najdete v tématu Škálování prostředků izolované databáze ve službě Azure SQL Database a škálování prostředků elastického fondu ve službě Azure SQL Database.
Problémy s výkonem způsobené zvýšeným objemem úloh
Zvýšení provozu aplikací a objemu úloh může způsobit zvýšené využití procesoru. Při správné diagnostice tohoto problému ale musíte být opatrní. Když se zobrazí problém s vysokým využitím procesoru, odpovězte na tyto otázky a zjistěte, jestli je zvýšení způsobené změnami svazku úloh:
Jsou dotazy z aplikace příčinou problému s vysokým využitím procesoru?
U dotazů s nejvyšším využitím procesoru, které můžete identifikovat:
- Bylo ke stejnému dotazu přidružených více plánů provádění? Pokud ano, proč?
- U dotazů se stejným plánem provádění byly doby provádění konzistentní? Zvýšil se počet spuštění? Pokud ano, zvýšení zatížení pravděpodobně způsobuje problémy s výkonem.
Pokud se plán spouštění dotazů nespustí jinak, ale využití procesoru se zvýšilo spolu s počtem spuštění, problém s výkonem pravděpodobně souvisí se zvýšením zatížení.
Není vždy snadné identifikovat změnu objemu úloh, která řídí problém s procesorem. Zvažte tyto faktory:
Změněné využití prostředků: Představte si například scénář, kdy se využití procesoru po delší dobu zvýšilo na 80 procent. Samotné využití procesoru neznamená, že se změnil objem úloh. Regrese v plánu provádění dotazů a změny v distribuci dat můžou také přispět k většímu využití prostředků, i když aplikace provádí stejnou úlohu.
Vzhled nového dotazu: Aplikace může v různých časech řídit novou sadu dotazů.
Zvýšení nebo snížení počtu požadavků: Tento scénář je nejobvyklejší mírou úlohy. Počet dotazů neodpovídá vždy většímu využití prostředků. Tato metrika je ale stále významným signálem za předpokladu, že se nezmění jiné faktory.
Využijte Intelligent Insights ke zjišťování nárůstů úloh a plánování regresí.
- Paralelismus: Nadměrný paralelismus může zhoršit další souběžný výkon úloh tím, že zmírní jiné dotazy na prostředky procesoru a pracovních vláken. Další informace o paralelismu ve službě Azure SQL Database najdete v tématu Konfigurace maximálního stupně paralelismu (MAXDOP) ve službě Azure SQL Database.
Problémy související s čekáním
Jakmile odstraníte neoptimální plán a problémy související s čekáním, které souvisejí s problémy s prováděním, problém s výkonem obvykle dotazy pravděpodobně čekají na nějaký prostředek. Problémy související s čekáním mohou být způsobeny:
Blokování:
Jeden dotaz může uzamknout objekty v databázi, zatímco ostatní se pokoušejí získat ke stejným objektům přístup. Blokující dotazy můžete identifikovat pomocí zobrazení dynamické správy nebo Intelligent Insights. Další informace najdete v tématu Vysvětlení a řešení problémů blokujících službu Azure SQL Database.
Problémy se vstupně-výstupními operace
Dotazy můžou čekat, až se stránky zapíšou do datových souborů nebo protokolů. V tomto případě zkontrolujte statistiky
INSTANCE_LOG_RATE_GOVERNOR,WRITE_LOGneboPAGEIOLATCH_*v zobrazení dynamické správy. Projděte si informace o používání zobrazení dynamické správy k identifikaci problémů s výkonem V/V operací.Problémy s databází Tempdb
Pokud úloha používá dočasné tabulky nebo v plánech dochází k přelití do
tempdb, dotazy můžou mít potíže s propustností tabulkytempdb. Pokud chcete zjistit další informace, projděte si problémy s databází tempdb.Problémy související s pamětí
Pokud úloha nemá dostatek paměti, očekávaná doba životnosti stránky se může zkrátit nebo dotazy můžou získat méně paměti, než potřebují. V některých případech integrované inteligentní funkce v Optimalizátoru dotazů problémy související s pamětí dokážou opravit. Projděte si informace o používání zobrazení dynamické správy k identifikaci problémů s přidělováním paměti. Další informace a ukázkové dotazy najdete v tématu Řešení chyb nedostatku paměti ve službě Azure SQL Database. Pokud dojde k chybám s nedostatkem paměti, zkontrolujte sys.dm_os_out_of_memory_events.
Metody pro zobrazení hlavních kategorií čekání
Tyto metody se běžně používají k zobrazení hlavních kategorií typů čekání:
- Použití Intelligent Insights k identifikaci dotazů se snížením výkonu kvůli zvýšenému čekání
- Pomocí úložiště dotazů můžete najít statistiky čekání pro každý dotaz v průběhu času. V úložišti dotazů se typy čekání kombinují do kategorií čekání. Mapování kategorií čekání na typy čekání najdete v sys.query_store_wait_stats.
- Pomocí sys.dm_db_wait_stats můžete vrátit informace o všech čekáních zjištěných vlákny, která se spustila během operace dotazu. Toto agregované zobrazení můžete použít k diagnostice problémů s výkonem služby Azure SQL Database a také s konkrétními dotazy a dávkami. Dotazy můžou čekat na prostředky, čekání fronty nebo externí čekání.
- Pomocí sys.dm_os_waiting_tasks můžete vrátit informace o frontě úloh, které čekají na nějaký prostředek.
Ve scénářích s vysokým využitím procesoru nemusí statistika úložiště dotazů a čekání odrážet využití procesoru, pokud:
- Dotazy s vysokým využitím procesoru se stále spouštějí.
- Dotazy s vysokým využitím procesoru byly spuštěny, když došlo k převzetí služeb při selhání.
Zobrazení dynamické správy, které sledují úložiště dotazů a statistiky čekání zobrazují výsledky pouze pro úspěšně dokončené a časově zastaralé dotazy. Nezobrazují data pro aktuálně spouštěné příkazy, dokud se příkazy nedokončí. Pomocí zobrazení dynamické správy sys.dm_exec_requests můžete sledovat aktuálně spuštěné dotazy a přidruženou dobu pracovního procesu.
Další kroky
- Konfigurace maximálního stupně paralelismu (MAXDOP) ve službě Azure SQL Database
- Vysvětlení a řešení problémů s blokováním služby Azure SQL Database ve službě Azure SQL Database
- Diagnostika a řešení potíží s vysokým využitím procesoru ve službě Azure SQL Database
- Přehled monitorování a ladění služby SQL Database
- Monitorování výkonu služby Microsoft Azure SQL Database pomocí zobrazení dynamické správy
- Ladění neclusterovaných indexů chybějícími návrhy indexů
- Správa prostředků ve službě Azure SQL Database
- Limity prostředků pro jednoúčelové databáze využívající nákupní model založený na virtuálních jádrech
- Limity prostředků pro elastické fondy využívající nákupní model založený na virtuálních jádrech
- Limity prostředků pro jednoúčelové databáze využívající nákupní model založený na jednotkách DTU
- Limity prostředků pro elastické fondy využívající nákupní model založený na DTU
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro