Řešení potíží s výkonem inteligentních Přehledy – Azure SQL Database a Azure SQL Managed Instance
Platí pro:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Tato stránka obsahuje informace o problémech s výkonem služby Azure SQL Database a Azure SQL Managed Instance zjištěné prostřednictvím protokolu prostředků Intelligent Přehledy. Metriky a protokoly prostředků se dají streamovat do protokolů služby Azure Monitor, Azure Event Hubs, Azure Storage nebo řešení třetích stran pro vlastní možnosti upozorňování a vytváření sestav DevOps.
Poznámka:
Průvodce rychlým řešením potíží s výkonem pomocí inteligentních Přehledy najdete v tomto dokumentu v doporučeném vývojovém diagramu pro řešení potíží.
Inteligentní přehledy jsou funkce Preview, která není dostupná v následujících oblastech: Západní Evropa, Severní Evropa, USA – západ 1 a USA – východ 1.
Zjistitelné vzory výkonu databáze
Inteligentní Přehledy automaticky detekuje problémy s výkonem na základě doby čekání na spouštění dotazů, chyb nebo časových limitů. Inteligentní Přehledy výstupy zjištěné vzory výkonu do protokolu prostředků. Zjistitelné vzory výkonu jsou shrnuty v následující tabulce.
| Rozpoznatelné vzory výkonu | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Dosažení limitů prostředků | Spotřeba dostupných prostředků (DTU), pracovních vláken databáze nebo relací přihlášení k databázi dostupných v monitorovaném předplatném dosáhla limitů prostředků. To má vliv na výkon. | Spotřeba prostředků procesoru dosahuje limitů prostředků. To má vliv na výkon databáze. |
| Zvýšení zatížení | Zjistilo se zvýšení nebo průběžné akumulace úloh v databázi. To má vliv na výkon. | Zjistilo se zvýšení zatížení. To má vliv na výkon databáze. |
| Zatížení paměti | Pracovní procesy, které požadovaly přidělení paměti, musí čekat na přidělení paměti na statisticky významné množství času nebo existuje zvýšená akumulace pracovních procesů, které požadovaly přidělení paměti. To má vliv na výkon. | Pracovní procesy, které požadovaly udělení paměti, čekají na přidělení paměti na statisticky významné množství času. To má vliv na výkon databáze. |
| Uzamčení | Bylo zjištěno nadměrné uzamčení databáze, které má vliv na výkon. | Bylo zjištěno nadměrné uzamčení databáze, které má vliv na výkon databáze. |
| Zvýšená hodnota MAXDOP | Maximální stupeň paralelismu (MAXDOP) se změnil, což má vliv na efektivitu provádění dotazů. To má vliv na výkon. | Maximální stupeň paralelismu (MAXDOP) se změnil, což má vliv na efektivitu provádění dotazů. To má vliv na výkon. |
| Kolize se stránkovacími prvky | Více vláken se současně pokouší o přístup ke stejným stránkám vyrovnávací paměti dat v paměti, což vede ke zvýšení doby čekání a způsobuje kolize stránkování. To má vliv na výkon. | Více vláken se současně pokouší o přístup ke stejným stránkám vyrovnávací paměti dat v paměti, což vede ke zvýšení doby čekání a způsobuje kolize stránkování. To má vliv na výkon databáze. |
| Chybějící index | Byl zjištěn chybějící index, který má vliv na výkon. | Byl zjištěn chybějící index, který má vliv na výkon databáze. |
| Nový dotaz | Zjistil se nový dotaz, který má vliv na celkový výkon. | Zjistil se nový dotaz, který má vliv na celkový výkon databáze. |
| Zvýšená statistika čekání | Byly zjištěny zvýšené doby čekání databáze, které mají vliv na výkon. | Byla zjištěna zvýšená doba čekání databáze, která ovlivňuje výkon databáze. |
| Kolize tempDB | Problém způsobuje několik vláken, která se snaží získat přístup ke stejnému tempdb prostředku. To má vliv na výkon. |
Problém způsobuje několik vláken, která se snaží získat přístup ke stejnému tempdb prostředku. To má vliv na výkon databáze. |
| Nedostatek DTU elastického fondu | Nedostatek dostupných eDTU v elastickém fondu ovlivňuje výkon. | Azure SQL Managed Instance není k dispozici, protože používá model virtuálních jader. |
| Regrese plánu | Zjistil se nový plán nebo změna úlohy existujícího plánu. To má vliv na výkon. | Zjistil se nový plán nebo změna úlohy existujícího plánu. To má vliv na výkon databáze. |
| Změna hodnoty konfigurace v oboru databáze | Byla zjištěna změna konfigurace databáze, která má vliv na výkon databáze. | Byla zjištěna změna konfigurace databáze, která má vliv na výkon databáze. |
| Pomalý klient | Pomalý klient aplikace nemůže dostatečně rychle využívat výstup z databáze. To má vliv na výkon. | Pomalý klient aplikace nemůže dostatečně rychle využívat výstup z databáze. To má vliv na výkon databáze. |
| Downgrade cenové úrovně | Akce downgradu cenové úrovně snížila dostupné prostředky. To má vliv na výkon. | Akce downgradu cenové úrovně snížila dostupné prostředky. To má vliv na výkon databáze. |
Tip
Pro průběžnou optimalizaci výkonu databází povolte automatické ladění. Tato integrovaná funkce inteligentních funkcí průběžně monitoruje vaši databázi, automaticky ladí indexy a používá opravy plánů provádění dotazů.
Následující část popisuje zjistitelné vzory výkonu podrobněji.
Dosažení limitů prostředků
Co se děje
Tento zjistitelný vzor výkonu kombinuje problémy s výkonem, které souvisejí s dosažením dostupných limitů prostředků, limitů pracovních procesů a limitů relací. Po zjištění tohoto problému s výkonem označuje pole popisu diagnostického protokolu, jestli problém s výkonem souvisí s limity prostředků, pracovních procesů nebo relací.
Prostředky ve službě Azure SQL Database se obvykle označují jako prostředky DTU nebo virtuálních jader a prostředky ve službě Azure SQL Managed Instance se označují jako prostředky virtuálních jader. Model dosažení limitů prostředků se rozpozná, když je zjištěno snížení výkonu dotazů způsobené dosažením některého z měřených limitů prostředků.
Prostředek omezení relace označuje počet dostupných souběžných přihlášení k databázi. Tento model výkonu se rozpozná, když aplikace připojené k databázím dosáhly počtu dostupných souběžných přihlášení k databázi. Pokud se aplikace pokusí použít více relací, než je k dispozici v databázi, bude ovlivněn výkon dotazu.
Dosažení limitů pracovních procesů je konkrétním případem dosažení limitů prostředků, protože dostupné pracovní procesy se do využití DTU nebo virtuálních jader nezapočítávají. Dosažení limitů pracovních procesů v databázi může způsobit nárůst doby čekání specifické pro prostředky, což vede ke snížení výkonu dotazů.
Řešení problému
V protokolu diagnostiky se vypíše hodnoty hash dotazů, které ovlivnily procento výkonu a spotřeby prostředků. Tyto informace můžete použít jako výchozí bod pro optimalizaci úloh databáze. Konkrétně můžete optimalizovat dotazy, které ovlivňují snížení výkonu, přidáním indexů. Nebo můžete optimalizovat aplikace s rovnoměrnějším rozdělením úloh. Pokud nemůžete snížit zatížení nebo provést optimalizace, zvažte zvýšení cenové úrovně předplatného databáze, abyste zvýšili množství dostupných prostředků.
Pokud jste dosáhli dostupných limitů relací, můžete optimalizovat aplikace snížením počtu přihlášení provedených do databáze. Pokud nemůžete snížit počet přihlášení z aplikací do databáze, zvažte zvýšení cenové úrovně vašeho předplatného databáze. Nebo můžete databázi rozdělit a přesunout do více databází pro vyváženější distribuci úloh.
Další návrhy na řešení limitů relací najdete v tématu Jak řešit limity maximálních přihlášení. Informace o omezeních na serveru najdete v části Přehled limitů na úrovni serveru a předplatného.
Zvýšení zatížení
Co se děje
Tento model výkonu identifikuje problémy způsobené zvýšením zatížení nebo v jeho přísnější podobě, kdy se zatížení hromadí.
Tato detekce se provádí kombinací několika metrik. Měřená základní metrika zjišťuje zvýšení zatížení v porovnání s předchozími směrnými plány úloh. Druhá forma detekce je založená na měření velkého nárůstu aktivních pracovních vláken, které jsou dostatečně velké, aby ovlivnily výkon dotazů.
Ve své těžší podobě může úloha průběžně hromadit kvůli nemožnosti databáze zpracovávat úlohy. Výsledkem je nepřetržitě rostoucí velikost úlohy, což je stav pile-up úlohy. Vzhledem k této podmínce roste doba, po kterou úloha čeká na spuštění. Tato podmínka představuje jeden z nejvýraznějších problémů s výkonem databáze. Tento problém se zjistí monitorováním nárůstu počtu přerušených pracovních vláken.
Řešení problému
V protokolu diagnostiky se vypíše počet dotazů, jejichž provádění se zvýšilo, a hodnota hash dotazu s největším příspěvkem ke zvýšení zatížení. Tyto informace můžete použít jako výchozí bod pro optimalizaci úlohy. Dotaz identifikovaný jako největší přispěvatel k nárůstu zatížení je zvlášť užitečný jako výchozí bod.
Můžete zvážit rovnoměrnější distribuci úloh do databáze. Zvažte optimalizaci dotazu, který ovlivňuje výkon přidáním indexů. Můžete také distribuovat úlohy mezi více databází. Pokud tato řešení nejsou možná, zvažte zvýšení cenové úrovně předplatného databáze, abyste zvýšili množství dostupných prostředků.
Přetížení paměti
Co se děje
Tento model výkonu indikuje snížení výkonu aktuální databáze způsobené tlakem paměti nebo v jeho silnější podobě stavu hromady paměti v porovnání s předchozím sedmidenním standardním výkonem.
Zatížení paměti označuje stav výkonu, ve kterém existuje velký počet pracovních vláken požadujících udělení paměti. Velký svazek způsobuje podmínku vysokého využití paměti, ve které databáze nedokáže efektivně přidělit paměť všem pracovníkům, kteří ji požadují. Jeden z nejběžnějších důvodů tohoto problému souvisí s velikostí paměti dostupnou pro databázi na jedné straně. Na druhou stranu zvýšení zatížení způsobuje zvýšení pracovních vláken a zatížení paměti.
Silnější forma paměťového tlaku je stav hromady paměti. Tato podmínka značí, že vyšší počet pracovních vláken požaduje udělení paměti, než jsou dotazy uvolněné paměti. Tento počet pracovních vláken, které požadují udělení paměti, může také neustále narůstá (hromadí se), protože databázový stroj nemůže přidělit paměť dostatečně efektivně, aby splnil poptávku. Stav hromady paměti představuje jeden z nejvýraznějších problémů s výkonem databáze.
Řešení problému
Protokol diagnostiky vypíše podrobnosti o úložišti objektů paměti s pracovníkem označeným jako nejvyšší důvod vysokého využití paměti a relevantních časových razítek. Tyto informace můžete použít jako základ pro řešení potíží.
Dotazy související s pracovníky můžete optimalizovat nebo odebírat s nejvyšším využitím paměti. Můžete se také ujistit, že se dotazujete na data, která neplánujete použít. Osvědčeným postupem je vždy používat klauzuli WHERE v dotazech. Kromě toho doporučujeme vytvořit neclusterované indexy, abyste hledali data, a neskenovali je.
Úlohu můžete také snížit optimalizací nebo distribucí do více databází. Nebo můžete úlohy distribuovat mezi více databází. Pokud tato řešení nejsou možná, zvažte zvýšení cenové úrovně databáze, abyste zvýšili množství prostředků paměti dostupných pro databázi.
Další návrhy pro řešení potíží naleznete v tématu Memory grant meditace: tajemný příjemce paměti SQL Serveru s mnoha názvy. Další informace o chybách nedostatku paměti ve službě Azure SQL Database najdete v tématu Řešení chyb kvůli nedostatku paměti ve službě Azure SQL Database.
Uzamčení
Co se děje
Tento model výkonu indikuje snížení výkonu aktuální databáze, ve kterém je zjištěno nadměrné uzamčení databáze ve srovnání s minulými sedmidenními standardními hodnotami výkonu.
V moderních rdBMS je uzamčení nezbytné pro implementaci vícevláknových systémů, ve kterých je výkon maximalizován spuštěním více souběžných pracovních procesů a paralelních databázových transakcí, pokud je to možné. Uzamčení v tomto kontextu odkazuje na integrovaný přístupový mechanismus, ve kterém může pouze jedna transakce přistupovat výhradně k řádkům, stránkám, tabulkám a souborům, které jsou požadovány, a nekonkurují s jinou transakcí pro prostředky. Když se s nimi provede transakce, která uzamkne prostředky pro použití, uvolní se zámek těchto prostředků, který umožňuje jiným transakcím přístup k požadovaným prostředkům. Další informace o uzamčení naleznete v tématu Uzamčení v databázovém stroji.
Pokud transakce spuštěné modulem SQL čekají na delší dobu pro přístup k prostředkům uzamčeným pro použití, tato doba čekání způsobí zpomalení výkonu spouštění úloh.
Řešení problému
Protokol diagnostiky vypíše podrobnosti o uzamčení, které můžete použít jako základ pro řešení potíží. Můžete analyzovat ohlášené blokující dotazy, tj. dotazy, které zavádějí snížení výkonu uzamčení, a odebrat je. V některých případech můžete být úspěšní při optimalizaci blokujících dotazů.
Nejjednodušším a nejbezpečnějším způsobem, jak tento problém zmírnit, je zachovat transakce krátké a snížit nároky na uzamčení nejnákladnějších dotazů. Velké množství operací můžete rozdělit do menších operací. Osvědčeným postupem je snížit nároky na uzamčení dotazů tím, že dotaz co nejefektivněji dosáhnete. Snižte velké kontroly, protože zvyšují pravděpodobnost zablokování a nepříznivě ovlivňují celkový výkon databáze. U identifikovaných dotazů, které způsobují uzamčení, můžete vytvořit nové indexy nebo přidat sloupce do existujícího indexu, abyste se vyhnuli prohledávání tabulek.
Další návrhy najdete tady:
- Vysvětlení a řešení problémů blokujících Azure SQL
- Řešení blokujících problémů způsobených eskalací zámku na SQL Serveru
Zvýšená hodnota MAXDOP
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku, ve které byl vybraný plán provádění dotazů paralelizován více, než by mělo být. Optimalizátor dotazů může zvýšit výkon úloh prováděním dotazů paralelně, aby urychlil věci tam, kde je to možné. V některých případech paralelní pracovníci zpracovávající dotaz tráví více času čekáním na synchronizaci a sloučení výsledků ve srovnání s prováděním stejného dotazu s menším počtem paralelních pracovních procesů nebo dokonce v některých případech ve srovnání s jedním pracovním vláknem.
Expertní systém analyzuje aktuální výkon databáze v porovnání se základním obdobím. Určuje, jestli dříve spuštěný dotaz běží pomaleji než dříve, protože plán provádění dotazů je paralelnější, než by měl být.
Možnost konfigurace serveru MAXDOP se používá k řízení počtu jader procesoru, které lze použít k paralelnímu spuštění stejného dotazu.
Řešení problému
Výstupem protokolu diagnostiky jsou hodnoty hash dotazů související s dotazy, pro které se doba provádění zvýšila, protože byly paralelizovány více, než by měly být. Protokol také vypíše dobu čekání CXP. Tentokrát představuje čas, kdy jedno vlákno organizátora nebo koordinátora (vlákno 0) čeká na dokončení všech ostatních vláken před sloučením výsledků a přechodem dopředu. Protokol diagnostiky navíc vypíše dobu čekání, po kterou dotazy s nízkým výkonem čekaly při celkovém spuštění. Tyto informace můžete použít jako základ pro řešení potíží.
Nejprve optimalizujte nebo zjednodušte složité dotazy. Osvědčeným postupem je rozdělit dlouhé dávkové úlohy na menší. Kromě toho se ujistěte, že jste vytvořili indexy pro podporu vašich dotazů. Maximální stupeň paralelismu (MAXDOP) můžete také ručně vynutit u dotazu, který byl označen jako nízký výkon. Pokud chcete tuto operaci nakonfigurovat pomocí T-SQL, přečtěte si téma Konfigurace možnosti konfigurace serveru MAXDOP.
Nastavení možnosti konfigurace serveru MAXDOP na nulu (0) jako výchozí hodnota označuje, že databáze může používat všechna dostupná jádra procesoru k paralelizaci vláken pro spuštění jednoho dotazu. Nastavení MAXDOP na jednu (1) označuje, že pro jedno spuštění dotazu se dá použít jenom jedno jádro. V praxi to znamená, že paralelismus je vypnutý. V závislosti na jednotlivých případech můžete dostupná jádra databáze a diagnostické protokoly vyladit možnost MAXDOP na počet jader používaných pro paralelní spouštění dotazů, které by mohly problém vyřešit ve vašem případě.
Kolize se stránkovacími prvky
Co se děje
Tento model výkonu označuje snížení výkonu aktuální úlohy databáze z důvodu kolize stránkování v porovnání se sedmidenními směrnými plány úloh.
Západky jsou odlehčené synchronizační mechanismy, které se používají k povolení vícevláknového formátování. Zaručují konzistenci struktur v paměti, které zahrnují indexy, datové stránky a další interní struktury.
K dispozici je mnoho typů západek. Pro zjednodušení se západky vyrovnávací paměti používají k ochraně stránek v paměti ve fondu vyrovnávací paměti. Západky vstupně-výstupních operací slouží k ochraně stránek, které ještě nejsou načteny do fondu vyrovnávací paměti. Při každém zápisu dat do nebo čtení ze stránky ve fondu vyrovnávací paměti musí pracovní vlákno nejprve získat západku vyrovnávací paměti pro stránku. Pokaždé, když se pracovní vlákno pokusí získat přístup ke stránce, která ještě není dostupná ve fondu vyrovnávací paměti, provede se požadavek vstupně-výstupních operací pro načtení požadovaných informací z úložiště. Tato posloupnost událostí označuje přísnější formu snížení výkonu.
Kolize na západkách stránky nastane, když se více vláken současně pokusí získat západky ve stejné struktuře v paměti, což představuje zvýšenou dobu čekání na spuštění dotazu. V případě kolizí stránkování vstupně-výstupních operací, kdy je potřeba získat přístup k datům z úložiště, je tato doba čekání ještě větší. Může výrazně ovlivnit výkon úloh. Kolize pagelatch je nejběžnější scénář vláken čekajících na sebe a soupeření o prostředky v několika systémech procesoru.
Řešení problému
Výstupem diagnostického protokolu jsou podrobnosti o kolizích stránky. Tyto informace můžete použít jako základ pro řešení potíží.
Vzhledem k tomu, že stránkování je mechanismus interního řízení, automaticky určuje, kdy je použít. Rozhodnutí o aplikacích, včetně návrhu schématu, můžou ovlivnit chování stránkování kvůli deterministickému chování západek.
Jednou z metod zpracování kolize západek je nahrazení sekvenčního indexového klíče nesekvenčním klíčem k rovnoměrné distribuci vložení do rozsahu indexu. Úvodní sloupec v indexu obvykle distribuuje úlohu úměrně. Další metodou, jak zvážit, je dělení tabulek. Vytvoření schématu dělení hash s počítaným sloupcem v dělené tabulce je běžným přístupem ke zmírnění nadměrné kolize západek. Vpřípaděch
Další informace najdete v tématu Diagnostika a řešení kolize západek na SQL Serveru (stažení PDF).
Chybějící index
Co se děje
Tento model výkonu značí snížení výkonu aktuálního výkonu databázové úlohy v porovnání s posledních sedmidenními směrnými plány kvůli chybějícímu indexu.
Index se používá ke zrychlení výkonu dotazů. Poskytuje rychlý přístup k tabulkovým datům snížením počtu stránek datové sady, které je potřeba navštívit nebo zkontrolovat.
Konkrétní dotazy, které způsobily snížení výkonu, jsou identifikovány prostřednictvím této detekce, pro kterou by vytváření indexů bylo přínosné pro výkon.
Řešení problému
Protokol diagnostiky vypíše hodnoty hash dotazů pro dotazy, které byly identifikovány, aby ovlivnily výkon úloh. Pro tyto dotazy můžete vytvářet indexy. Tyto dotazy můžete také optimalizovat nebo odebrat, pokud nejsou potřeba. Dobrým postupem výkonu je vyhnout se dotazování na data, která nepoužíváte.
Tip
Věděli jste, že integrované inteligentní funkce můžou automaticky spravovat nejvýkonnější indexy pro vaše databáze?
Pro průběžnou optimalizaci výkonu doporučujeme povolit automatické ladění. Tato jedinečná integrovaná inteligentní funkce průběžně monitoruje vaši databázi a automaticky ladí a vytváří indexy pro vaše databáze.
Nový dotaz
Co se děje
Tento model výkonu označuje, že se zjistí nový dotaz, který funguje špatně a ovlivňuje výkon úloh ve srovnání se sedmidenním směrným plánem výkonu.
Zápis dobře fungujícího dotazu může někdy být náročný úkol. Další informace o psaní dotazů najdete v tématu Psaní dotazů SQL. Pokud chcete optimalizovat výkon stávajících dotazů, přečtěte si téma Ladění dotazů.
Řešení problému
Protokol diagnostiky vypíše informace až o dvou nových dotazech s nejvyšším využitím procesoru, včetně jejich hodnot hash dotazů. Vzhledem k tomu, že zjištěný dotaz ovlivňuje výkon úloh, můžete dotaz optimalizovat. Osvědčeným postupem je načíst jenom data, která potřebujete použít. Také doporučujeme používat dotazy s klauzulí WHERE. Doporučujeme také zjednodušit složité dotazy a rozdělit je na menší dotazy. Dalším dobrým postupem je rozdělit velké dávkové dotazy na menší dávkové dotazy. Představujeme indexy pro nové dotazy, obvykle je vhodné tento problém s výkonem zmírnit.
Ve službě Azure SQL Database zvažte použití nástroje Query Performance Insight.
Zvýšená statistika čekání
Co se děje
Tento zjistitelný vzor výkonu označuje snížení výkonu úloh, při kterém jsou v porovnání se sedmidenním směrným plánem úloh identifikovány dotazy s nízkým výkonem.
V tomto případě systém nemůže klasifikovat dotazy s nízkým výkonem v rámci žádné jiné standardní zjistitelné kategorie výkonu, ale zjistil statistiku čekání odpovědnou za regresi. Proto je považuje za dotazy se zvýšenými statistikami čekání, kde je také vystavena statistika čekání odpovědná za regresi.
Řešení problému
Protokol diagnostiky vypíše informace o zvýšených podrobnostech o době čekání a hodnotách hash dotazů ovlivněných dotazů.
Vzhledem k tomu, že systém nemohl úspěšně identifikovat původní příčinu dotazů s nízkým výkonem, jsou diagnostické informace dobrým výchozím bodem pro ruční řešení potíží. Výkon těchto dotazů můžete optimalizovat. Osvědčeným postupem je načíst jenom data, která potřebujete použít, a zjednodušit a rozdělit složité dotazy na menší.
Další informace o optimalizaci výkonu dotazů najdete v tématu Ladění dotazů.
Kolize v databázi TempDB
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku výkonu databáze, ve které existuje kritický bod vláken, která se snaží získat přístup k tempdb prostředkům. (Tato podmínka nesouvisí se vstupně-výstupními operacemi.) Typickým scénářem tohoto problému s výkonem jsou stovky souběžných dotazů, které všechny vytvářejí, používají a pak odstraňují malé tempdb tabulky. Systém zjistil, že počet souběžných dotazů používajících stejné tempdb tabulky se zvýšil s dostatečným statistickým významem, aby ovlivnil výkon databáze v porovnání s předchozím sedmidenním standardním výkonem.
Řešení problému
Protokol diagnostiky vypíše tempdb podrobnosti kolize. Informace můžete použít jako výchozí bod pro řešení potíží. Existují dvě věci, které můžete zmírnit tento druh kolizí a zvýšit propustnost celkové úlohy: Můžete přestat používat dočasné tabulky. Můžete také použít tabulky optimalizované pro paměť.
Další informace naleznete v tématu Úvod do tabulek optimalizovaných pro paměť.
Nedostatek DTU elastického fondu
Co se děje
Tento zjistitelný vzor výkonu značí snížení výkonu aktuálního výkonu databázových úloh v porovnání s předchozím sedmidenním směrným plánem. Důvodem je nedostatek dostupných DTU v elastickém fondu vašeho předplatného.
Prostředky elastického fondu Azure se používají jako fond dostupných prostředků sdílených mezi několika databázemi pro účely škálování. Pokud dostupné prostředky eDTU ve vašem elastickém fondu nejsou dostatečně velké, aby podporovaly všechny databáze ve fondu, systém zjistí problém s nedostatkem DTU elastického fondu.
Řešení problému
Protokol diagnostiky vypíše informace o elastickém fondu, obsahuje seznam databází s nejvyšším využitím DTU a poskytuje procento DTU fondu, které používá databáze s nejvyšším využitím.
Vzhledem k tomu, že tato podmínka výkonu souvisí s více databázemi používajícími stejný fond eDTU v elastickém fondu, kroky pro řešení potíží se zaměřují na databáze s nejvyšším využitím DTU. Můžete snížit zatížení databází s nejvyšším využitím, což zahrnuje optimalizaci nejžádychaných dotazů na tyto databáze. Můžete také zajistit, že se dotazujete na data, která nepoužíváte. Dalším přístupem je optimalizace aplikací s využitím databází s nejvyšším využitím DTU a redistribuce úloh mezi více databází.
Pokud není možné snížit a optimalizovat aktuální úlohu v databázích s nejvyšším využitím DTU, zvažte zvýšení cenové úrovně elastického fondu. Takové zvýšení vede k nárůstu dostupných DTU v elastickém fondu.
Regrese plánu
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku, ve které databáze využívá neoptimální plán provádění dotazů. Neoptimální plán obvykle způsobuje zvýšené spouštění dotazů, což vede k delší době čekání na aktuální a další dotazy.
Databázový stroj určuje plán provádění dotazů s nejnižšími náklady na provedení dotazu. Vzhledem k tomu, že se mění typ dotazů a úloh, někdy už stávající plány nejsou efektivní nebo databázový stroj nevytvořil dobré hodnocení. V rámci opravy je možné plány provádění dotazů ručně vynutit.
Tento zjistitelný model výkonu kombinuje tři různé případy regrese plánu: novou regresi plánu, starou regresi plánu a existující změněné úlohy plánů. Konkrétní typ regrese plánu, ke kterému došlo, je uveden v vlastnosti podrobností v diagnostickém protokolu.
Nová podmínka regrese plánu odkazuje na stav, ve kterém databázový stroj spustí nový plán provádění dotazů, který není tak efektivní jako starý plán. Původní podmínka regrese plánu odkazuje na stav, kdy databázový stroj přepne z použití nového, efektivnějšího plánu na starý plán, který není tak efektivní jako nový plán. Stávající plány změnily regresi úloh na stav, ve kterém se staré a nové plány neustále střídají, přičemž zůstatek směřuje k plánu s nízkým výkonem.
Další informace o regresích plánu najdete v tématu Co je regrese plánu na SQL Serveru?.
Řešení problému
V protokolu diagnostiky se vypíše hodnoty hash dotazů, ID dobrého plánu, ID chybného plánu a ID dotazů. Tyto informace můžete použít jako základ pro řešení potíží.
Můžete analyzovat, který plán je lépe výkonný pro konkrétní dotazy, které můžete identifikovat pomocí zadaných hodnot hash dotazů. Jakmile určíte, který plán bude pro vaše dotazy fungovat lépe, můžete ho vynutit ručně.
Další informace najdete v tématu Informace o tom, jak SQL Server brání regresím plánu.
Tip
Věděli jste, že integrovaná funkce inteligentních funkcí dokáže automaticky spravovat nejlepší plány provádění dotazů pro vaše databáze?
Pro průběžnou optimalizaci výkonu doporučujeme povolit automatické ladění. Tato integrovaná funkce inteligentních funkcí nepřetržitě monitoruje vaši databázi a automaticky ladí a vytváří pro vaše databáze nejlepší plány provádění dotazů.
Změna hodnoty konfigurace v oboru databáze
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku, ve které změna konfigurace v oboru databáze způsobuje regresi výkonu, která se zjistí v porovnání s chováním úloh databáze za posledních 7 dnů. Tento vzor označuje, že nedávné změny provedené v konfiguraci s oborem databáze nejsou pro výkon databáze přínosné.
Změny konfigurace v oboru databáze lze nastavit pro každou jednotlivou databázi. Tato konfigurace se používá v jednotlivých případech k optimalizaci individuálního výkonu databáze. Pro každou jednotlivou databázi je možné nakonfigurovat následující možnosti: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES a CLEAR PROCEDURE_CACHE.
Řešení problému
Protokol diagnostiky vypíše změny konfigurace v rozsahu databáze, které byly provedeny nedávno, které způsobily snížení výkonu v porovnání s předchozím sedmidenním chováním úloh. Změny konfigurace můžete vrátit na předchozí hodnoty. Hodnotu můžete také ladit podle hodnoty, dokud nedosáhnete požadované úrovně výkonu. Konfigurační hodnoty oboru databáze můžete zkopírovat z podobné databáze s uspokojivým výkonem. Pokud nemůžete řešit potíže s výkonem, vraťte se k výchozím hodnotám a pokuste se ladit od tohoto směrného plánu.
Další informace o optimalizaci konfigurace s oborem databáze a syntaxi T-SQL při změně konfigurace naleznete v tématu Alter database-scoped configuration (Transact-SQL).
Pomalý klient
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku, ve které klient používající databázi nemůže využívat výstup z databáze tak rychle, jak databáze odesílá výsledky. Vzhledem k tomu, že databáze neuloží výsledky spuštěných dotazů do vyrovnávací paměti, zpomalí se a počká, než klient bude využívat přenášené výstupy dotazu. Tato podmínka může také souviset se sítí, která není dostatečně rychlá k přenosu výstupů z databáze do spotřebujícího klienta.
Tato podmínka se vygeneruje pouze v případě, že se zjistí regrese výkonu v porovnání s chováním úloh databáze za posledních 7 dnů. Tento problém s výkonem se zjistí jenom v případě, že dojde ke statisticky významnému snížení výkonu v porovnání s předchozím chováním výkonu.
Řešení problému
Tento zjistitelný vzor výkonu označuje podmínku na straně klienta. Řešení potíží se vyžaduje v aplikaci na straně klienta nebo v síti na straně klienta. Protokol diagnostiky vypíše hodnoty hash dotazů a doby čekání, které zdánlivě čekají nejvíce na to, aby je klient během posledních dvou hodin spotřeboval. Tyto informace můžete použít jako základ pro řešení potíží.
Výkon aplikace můžete optimalizovat pro využití těchto dotazů. Můžete také zvážit možné problémy s latencí sítě. Vzhledem k tomu, že problém se snížením výkonu byl založen na změně v posledních sedmidenních směrných hodnotách výkonu, můžete zjistit, jestli nedávné změny stavu aplikace nebo sítě způsobily tuto regresní událost výkonu.
Downgrade cenové úrovně
Co se děje
Tento zjistitelný vzor výkonu označuje podmínku, ve které došlo k downgradu cenové úrovně vašeho předplatného databáze. Kvůli snížení prostředků (DTU) dostupných pro databázi systém zjistil pokles aktuálního výkonu databáze v porovnání s předchozím sedmidenním směrným plánem.
Kromě toho může existovat podmínka, ve které byla cenová úroveň vašeho předplatného databáze downgradována a následně upgradována na vyšší úroveň během krátkého časového období. Detekce tohoto dočasného snížení výkonu se zobrazí v části podrobností diagnostického protokolu jako downgrade a upgrade cenové úrovně.
Řešení problému
Pokud jste snížili cenovou úroveň, a proto jsou dostupné jednotky DTU a jste spokojení s výkonem, nemusíte nic dělat. Pokud jste snížili cenovou úroveň a nejste spokojeni s výkonem databáze, snižte zatížení databáze nebo zvažte zvýšení cenové úrovně na vyšší úroveň.
Doporučený tok řešení potíží
Při řešení potíží s výkonem s využitím inteligentních Přehledy postupujte podle vývojového diagramu.
Přístup k inteligentnímu Přehledy prostřednictvím webu Azure Portal prostřednictvím Azure SQL Analytics. Pokuste se najít příchozí upozornění na výkon a vyberte ho. Zjistěte, co se děje na stránce detekce. Podívejte se na zadanou analýzu původní příčiny problému, textu dotazu, trendů doby dotazu a vývoje incidentů. Pokuste se problém vyřešit pomocí doporučení Inteligentní Přehledy pro zmírnění problému s výkonem.
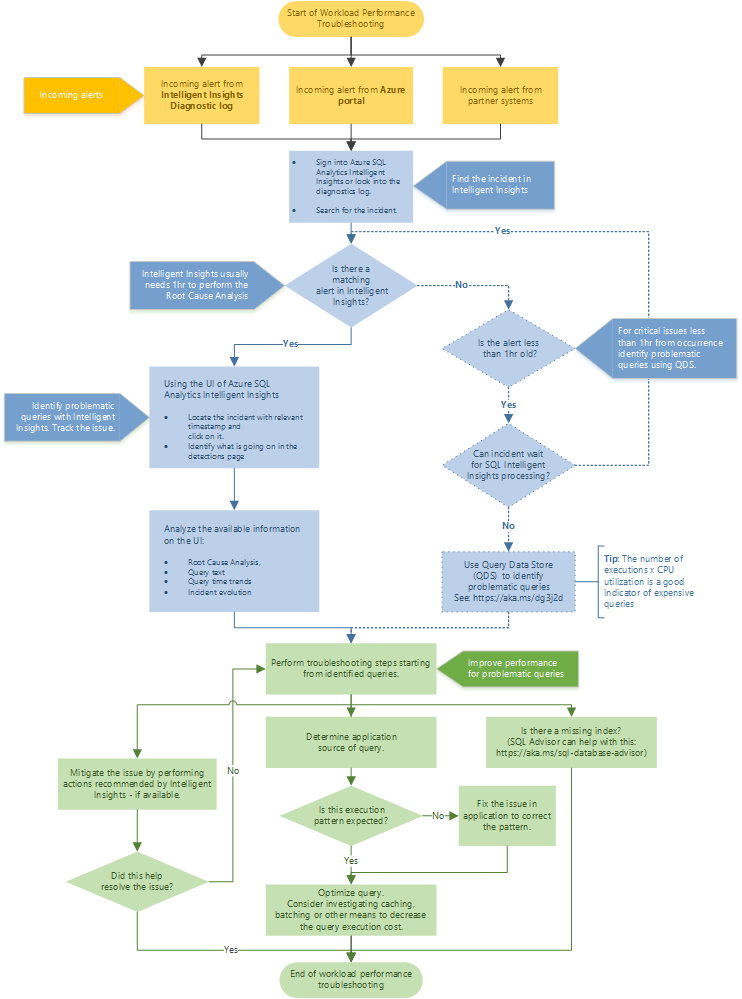
Tip
Vyberte vývojový diagram a stáhněte si verzi PDF.
Inteligentní Přehledy obvykle potřebuje hodinu času k provedení analýzy původní příčiny problému s výkonem. Pokud nemůžete najít problém v inteligentním Přehledy a je pro vás důležité, pomocí úložiště dotazů ručně identifikujte původní příčinu problému s výkonem. (Obvykle jsou tyto problémy starší než jedna hodina.) Další informace najdete v tématu Monitorování výkonu pomocí úložiště dotazů.
Další kroky
- Seznamte se s inteligentními koncepty Přehledy.
- Použijte protokol inteligentní diagnostiky výkonu Přehledy.
- Monitorování pomocí Azure SQL Analytics
- Zjistěte, jak shromažďovat a využívat data protokolů z prostředků Azure.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro