Trénování profesionálního hlasového modelu
V tomto článku se dozvíte, jak trénovat vlastní neurální hlas prostřednictvím portálu Speech Studio.
Důležité
Vlastní trénování neurálních hlasů je v současné době dostupné jenom v některých oblastech. Jakmile se hlasový model vytrénuje v podporované oblasti, můžete ho podle potřeby zkopírovat do prostředku služby Speech v jiné oblasti. Další informace najdete v poznámkách pod čarou v tabulce služby Speech.
Doba trvání trénování se liší v závislosti na tom, kolik dat používáte. Trénování vlastního neurálního hlasu trvá v průměru přibližně 40 výpočetních hodin. Uživatelé s předplatným Standard (S0) můžou trénovat čtyři hlasy současně. Pokud dosáhnete limitu, počkejte, až aspoň jeden z vašich hlasových modelů dokončí trénování, a zkuste to znovu.
Poznámka:
I když se celkový počet hodin požadovaných pro metodu trénování liší, platí pro každou jednotkovou cenu stejná jednotková cena. Další informace najdete v podrobnostech o cenách vlastního neurálního trénování.
Volba metody trénování
Po ověření datových souborů je použijte k vytvoření vlastního neurálního hlasového modelu. Když vytvoříte vlastní neurální hlas, můžete ho vytrénovat pomocí jedné z následujících metod:
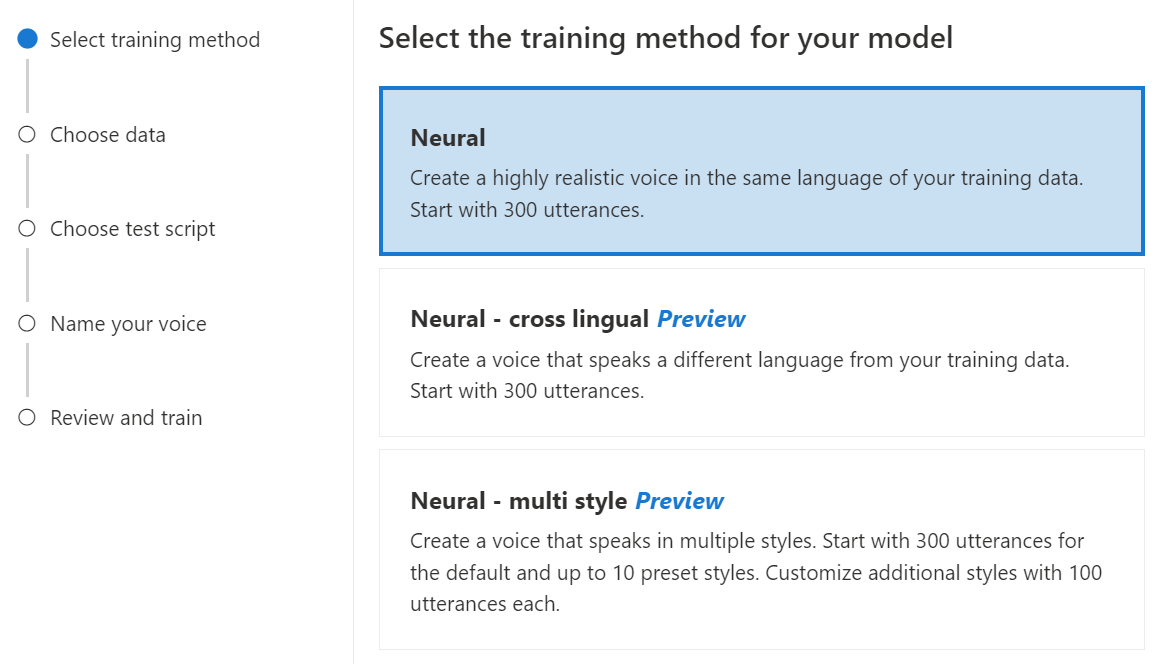
Neurální: Vytvořte hlas ve stejném jazyce trénovacích dat.
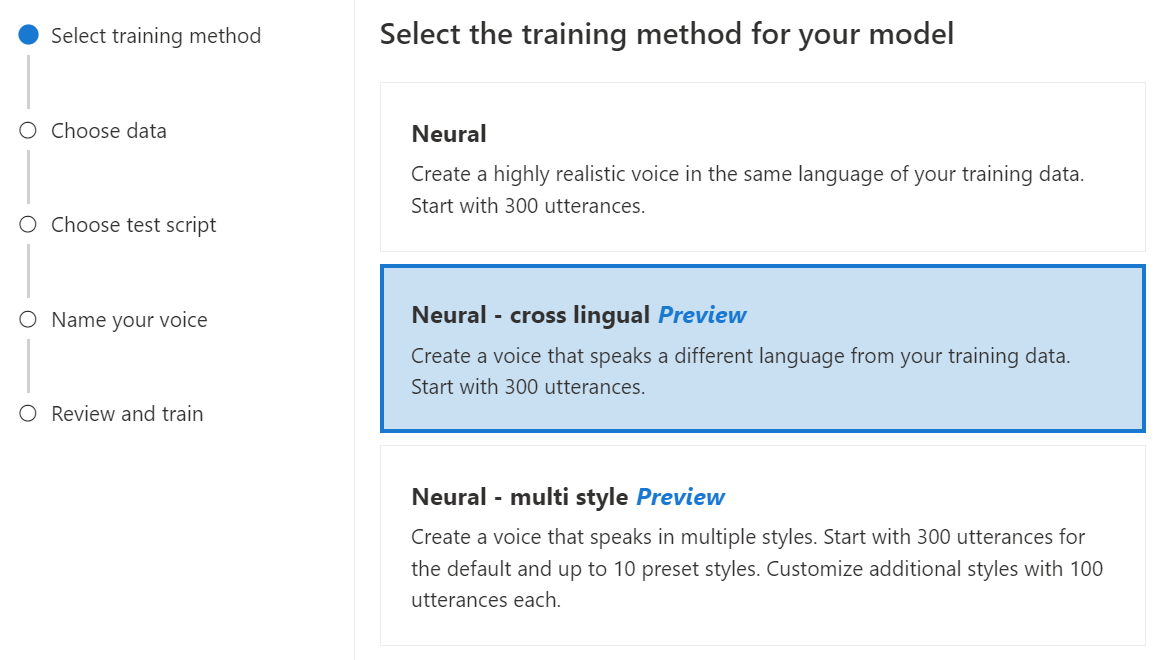
Neurální – křížový jazyk: Vytvořte hlas, který mluví jiným jazykem než trénovací data. Například s
zh-CNtrénovacími datyen-USmůžete vytvořit hlas, který mluví .Jazyk trénovacích dat a cílového jazyka musí být jedním z jazyků, které jsou podporovány pro křížové jazykové trénování hlasu. Nemusíte připravovat trénovací data v cílovém jazyce, ale váš testovací skript musí být v cílovém jazyce.
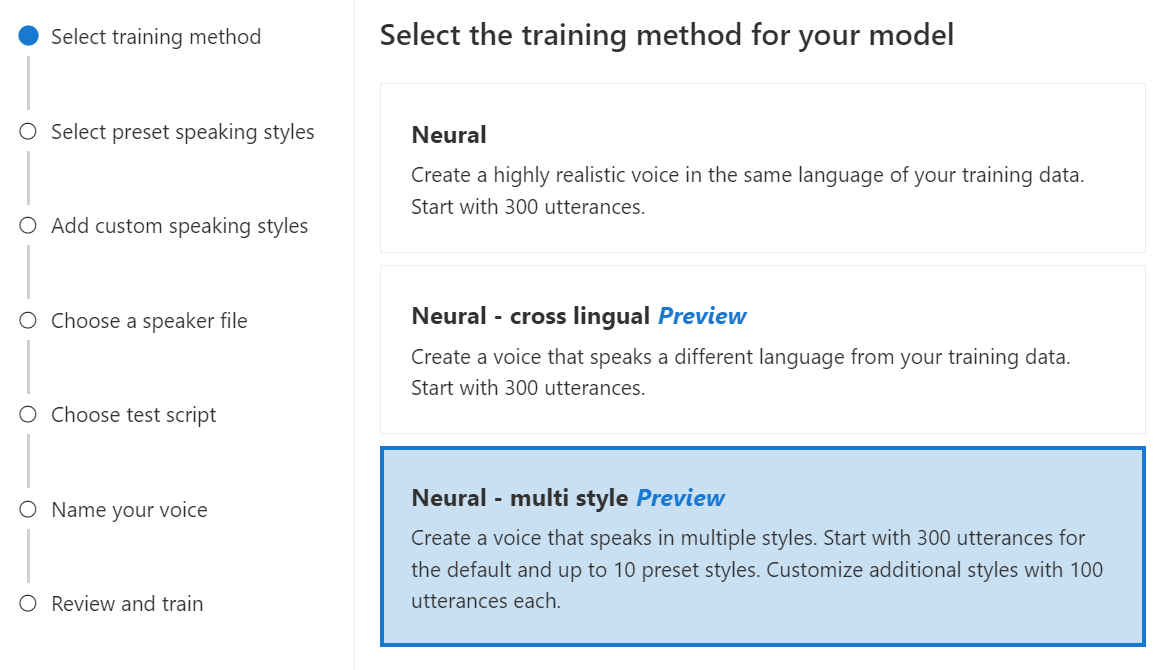
Neurální – více stylů: Vytvořte vlastní neurální hlas, který mluví ve více stylech a emocích, aniž byste museli přidávat nová trénovací data. Více stylů hlasy jsou užitečné pro znaky videohry, konverzační chatboty, audioknihy, čtenáře obsahu a další.
Pokud chcete vytvořit hlas s více styly, musíte připravit sadu obecných trénovacích dat, a to alespoň 300 promluv. Vyberte jeden nebo více přednastavených stylů cílového mluvení. Můžete také vytvořit více vlastních stylů tím, že poskytnete ukázky stylů s nejméně 100 promluvami na styl, jako další trénovací data pro stejný hlas. Podporované přednastavené styly se liší podle různých jazyků. Podívejte se na dostupné přednastavené styly v různých jazycích.
Jazyk trénovacích dat musí být jedním z jazyků, které jsou podporovány pro vlastní neurální hlas, křížový jazyk nebo trénování ve více stylech.
Trénování vlastního neurálního hlasového modelu
Pokud chcete vytvořit vlastní neurální hlas v sadě Speech Studio, postupujte podle těchto kroků pro jednu z následujících metod:
Přihlaste se k sadě Speech Studio.
Vyberte Vlastní hlas<>Název projektu>>Trénování modelu>Trénování nového modelu.
Jako metodu trénování modelu vyberte Neurální a pak vyberte Další. Pokud chcete použít jinou metodu trénování, přečtěte si téma Neuron – křížový neboneurální – více stylů.
Vyberte verzi trénovacího receptu pro váš model. Ve výchozím nastavení je vybraná nejnovější verze. Podporované funkce a doba trénování se můžou lišit podle verze. Za normálních okolností doporučujeme nejnovější verzi. V některých případech můžete zvolit starší verzi, abyste zkrátili dobu trénování. Další informace o dvojjazyčné trénování a rozdílech mezi národními prostředími najdete v tématu Dvojjazyčné školení .
Vyberte data, která chcete použít pro trénování. Z trénování se odeberou duplicitní názvy zvuku. Ujistěte se, že vámi zvolená data neobsahují stejné názvy zvuků ve více .zip souborech.
Pro trénování můžete vybrat pouze úspěšně zpracované datové sady. Pokud v seznamu nevidíte trénovací sadu, zkontrolujte stav zpracování dat.
Vyberte soubor mluvčího s prohlášením o talentu hlasu, který odpovídá mluvčímu ve vašich trénovacích datech.
Vyberte Další.
Každé trénování vygeneruje automaticky 100 ukázkových zvukových souborů, které vám pomůžou model otestovat pomocí výchozího skriptu.
Volitelně můžete také vybrat Přidat vlastní testovací skript a zadat vlastní testovací skript s až 100 promluvami, které model otestují bez dalších poplatků. Vygenerované zvukové soubory jsou kombinací automatických testovacích skriptů a vlastních testovacích skriptů. Další informace najdete v požadavcích na testovací skript.
Zadejte název, který vám pomůže model identifikovat. Pečlivě zvolte jméno. Název modelu se používá jako hlasový název v požadavku na syntézu řeči pomocí sady SDK a vstupu SSML. Jsou povolená jenom písmena, číslice a několik interpunkčních znaků. Pro různé neurální hlasové modely používejte různé názvy.
Volitelně můžete zadat popis , který vám pomůže model identifikovat. Běžným použitím popisu je zaznamenání názvů dat, která jste použili k vytvoření modelu.
Vyberte Další.
Zkontrolujte nastavení a zaškrtněte políčko, abyste přijali podmínky použití.
Výběrem možnosti Odeslat zahájíte trénování modelu.
Dvojjazyčné školení
Pokud vyberete typ neurálního trénování, můžete vytrénovat hlas pro mluvení ve více jazycích. zh-TW Obě národní prostředí zh-CN podporují dvojjazyčné školení pro hlas pro mluvení čínštiny i angličtiny. V závislosti na trénovacích datech může syntetizovaný hlas mluvit anglicky s anglickým nativním zvýrazněním nebo angličtinou se stejným zvýrazněním jako trénovací data.
Poznámka:
Pokud chcete, aby hlas v zh-CN národním prostředí mluvil anglicky se stejným zvýrazněním jako ukázková data, měli byste zvolit Chinese (Mandarin, Simplified), English bilingual při vytváření projektu nebo určit zh-CN (English bilingual) národní prostředí pro data trénovací sady prostřednictvím rozhraní REST API.
Následující tabulka ukazuje rozdíly mezi těmito dvěma národními prostředími:
| Národní prostředí sady Speech Studio | Národní prostředí rest API | Dvoujazyčná podpora |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Pokud vaše ukázková data obsahují angličtinu, syntetizovaný hlas mluví anglicky s anglickým nativním zvýrazněním, místo stejného zvýraznění jako ukázková data bez ohledu na množství anglických dat. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Pokud chcete, aby syntetizovaný hlas mluvil anglicky se stejným zvýrazněním jako ukázková data, doporučujeme zahrnout do trénovací sady více než 10 % anglických dat. V opačném případě nemusí být přízvuk pro angličtinu ideální. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Pokud chcete vytrénovat syntetizovaný hlas schopný mluvit anglicky se stejným zvýrazněním jako ukázková data, nezapomeňte do trénovací sady poskytnout více než 10 % anglických dat. V opačném případě se ve výchozím nastavení nastaví nativní zvýraznění v angličtině. Prahová hodnota 10 % se vypočítá na základě dat přijatých po úspěšném nahrání, nikoli dat před nahráním. Pokud jsou některá nahraná anglická data odmítnuta z důvodu vad a nesplňuje 10% prahovou hodnotu, syntetizovaná hlasová výchozí hodnota odpovídá anglickému nativnímu zvýraznění. |
Dostupné přednastavené styly v různých jazycích
Následující tabulka shrnuje různé přednastavené styly podle různých jazyků.
| Styl řeči | Jazyk (národní prostředí) |
|---|---|
| Rozzlobený | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Klid | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| chat | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Veselý | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Nespokojený | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Nadšený | Angličtina (USA) (en-US) |
| Strach | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Přátelské | Angličtina (USA) (en-US) |
| Nadějný | Angličtina (USA) (en-US) |
| Smutné | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Křičel | Angličtina (USA) (en-US) |
| Vážné | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Vyděšený | Angličtina (USA) (en-US) |
| Nepřátelský | Angličtina (USA) (en-US) |
| Šeptal | Angličtina (USA) (en-US) |
1 Styl neurálního hlasu je k dispozici ve verzi Public Preview. Styly ve verzi Public Preview jsou dostupné jenom v těchto oblastech služeb: USA – východ, Západní Evropa a Jihovýchodní Asie.
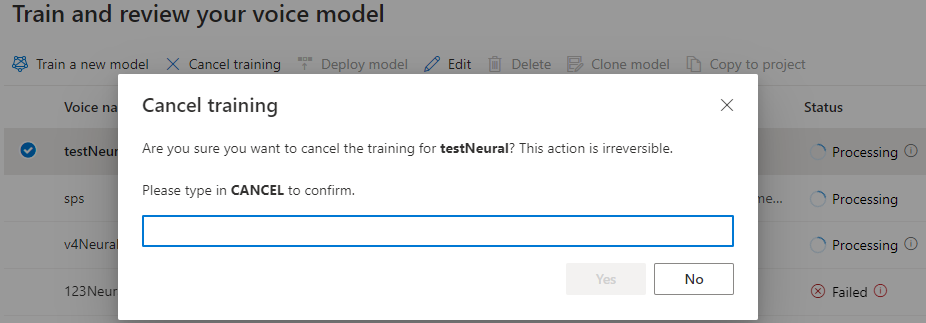
Tabulka Trénování modelu zobrazí novou položku, která odpovídá tomuto nově vytvořenému modelu. Stav odráží proces převodu dat na hlasový model, jak je popsáno v této tabulce:
| Stav | Význam |
|---|---|
| zpracovává se | Váš hlasový model se vytváří. |
| Úspěšný | Vytvořili jste hlasový model a můžete ho nasadit. |
| Neúspěšný | Váš hlasový model se při trénování nezdařil. Příčinou selhání může být například nezoznané problémy s daty nebo problémy se sítí. |
| Zrušeno | Trénování pro váš hlasový model bylo zrušeno. |
Když je stav modelu Zpracování, můžete výběrem možnosti Zrušit trénování zrušit hlasový model. Za toto zrušené trénování se vám neúčtují poplatky.
Po úspěšném trénování modelu si můžete prohlédnout podrobnosti o modelu a otestovat hlasový model.
Pomocí nástroje Pro vytváření zvukového obsahu v sadě Speech Studio můžete vytvořit zvuk a doladit nasazený hlas. Pokud je to možné pro váš hlas, můžete vybrat jeden z více stylů.
Přejmenování modelu
Pokud chcete model, který jste vytvořili, přejmenovat, vyberte Klonovat model a vytvořte klon modelu s novým názvem v aktuálním projektu.
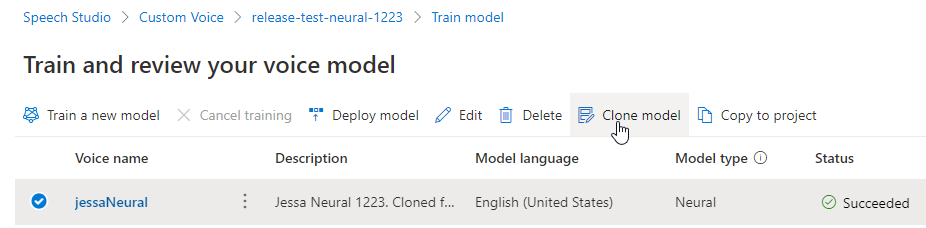
Do okna Klonovat hlasový model zadejte nový název a pak vyberte Odeslat. Text Neurální se automaticky přidá jako přípona k novému názvu modelu.
Testování hlasového modelu
Po úspěšném sestavení hlasového modelu můžete před nasazením použít vygenerované ukázkové zvukové soubory k otestování.
Kvalita hlasu závisí na mnoha faktorech, například:
- Velikost trénovacích dat
- Kvalita nahrávky.
- Přesnost souboru přepisu.
- Jak dobře zaznamenaný hlas v trénovacích datech odpovídá osobnosti navrženého hlasu pro váš zamýšlený případ použití.
V části Testování vyberte Výchozítesty a poslechněte si ukázkové zvukové soubory. Výchozí ukázky testů zahrnují 100 ukázkových zvukových souborů vygenerovaných automaticky během trénování, které vám pomůžou model otestovat. Kromě těchto 100 zvukovýchsouborůch Tento dodatek je maximálně 100 promluv. Za testování pomocí defaulttestů se vám neúčtují poplatky.
Pokud chcete nahrát vlastní testovací skripty pro další testování modelu, vyberte Přidat testovací skripty a nahrajte vlastní testovací skript.
Než nahrajete testovací skript, zkontrolujte požadavky na testovací skript. Za dodatečné testování se vám účtuje syntéza dávek na základě počtu fakturovatelných znaků. Podívejte se na ceny služby Azure AI Speech.
V části Přidat testovací skripty vyberte Vyhledat soubor , abyste vybrali vlastní skript a pak ho nahráli výběrem možnosti Přidat .
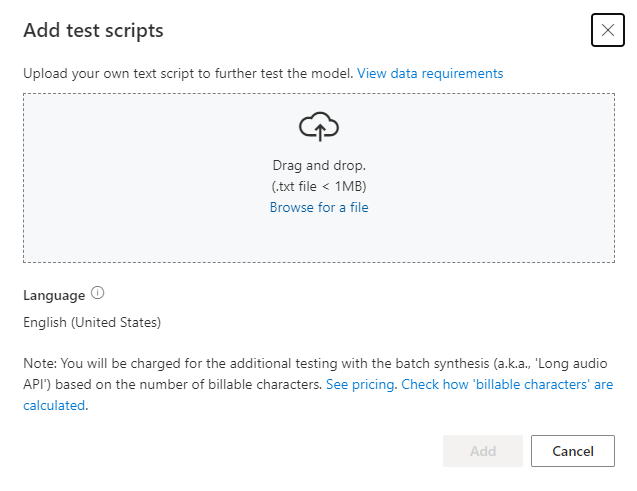
Požadavky na testovací skripty
Testovací skript musí být .txt soubor, který je menší než 1 MB. Mezi podporované formáty kódování patří ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE nebo UTF-16-BE.
Na rozdíl od souborů přepisu trénování by měl testovací skript vyloučit ID promluvy, což je název souboru každé promluvy. Jinak se tyto ID mluví.
Tady je příklad sady promluv v jednom souboru .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Každý odstavec promluvy má za následek samostatný zvuk. Pokud chcete zkombinovat všechny věty do jednoho zvuku, udělejte z nich jeden odstavec.
Poznámka:
Vygenerované zvukové soubory jsou kombinací automatických testovacích skriptů a vlastních testovacích skriptů.
Aktualizace verze modulu pro hlasový model
Moduly pro převod textu do řeči Azure se průběžně aktualizují, aby zachytily nejnovější jazykový model, který definuje výslovnost jazyka. Po vytrénování hlasu můžete svůj hlas použít na nový jazykový model aktualizací na nejnovější verzi modulu.
Pokud je k dispozici nový modul, zobrazí se výzva k aktualizaci neurálního hlasového modelu.

Přejděte na stránku s podrobnostmi o modelu a podle pokynů na obrazovce nainstalujte nejnovější modul.
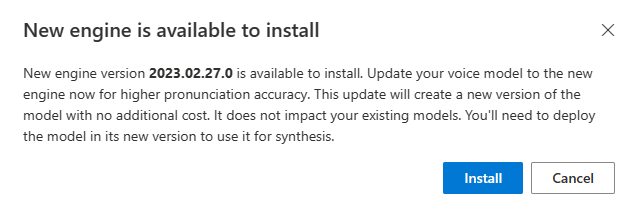
Případně vyberte Nainstalovat nejnovější modul později a aktualizujte model na nejnovější verzi modulu.
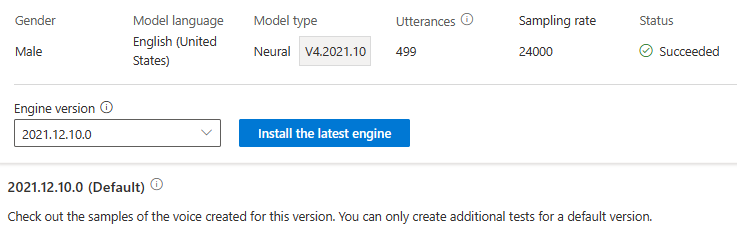
Za aktualizaci modulu se vám neúčtují poplatky. Předchozí verze jsou stále zachovány.
Všechny verze modulu pro model můžete zkontrolovat v seznamu verzí modulu nebo je odebrat, pokud už ho nepotřebujete.
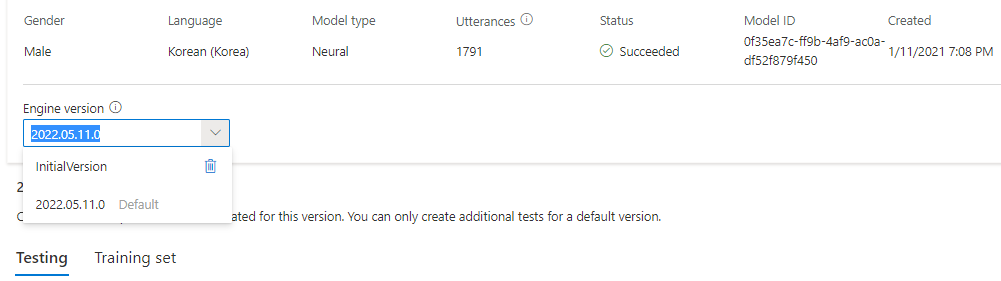
Aktualizovaná verze se automaticky nastaví jako výchozí. Výchozí verzi ale můžete změnit tak, že v rozevíracím seznamu vyberete verzi a vyberete Nastavit jako výchozí.
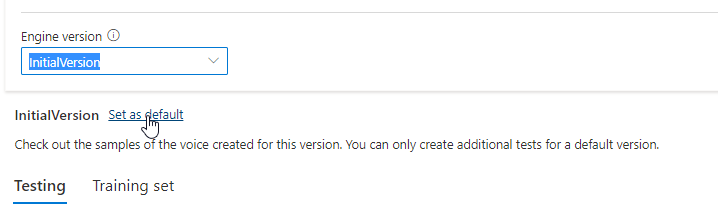

Pokud chcete otestovat každou verzi modulu hlasového modelu, můžete ze seznamu vybrat verzi a pak v části Testování vybrat výchozítesty a poslouchat ukázkové zvukové soubory. Pokud chcete nahrát vlastní testovací skripty pro další testování aktuální verze modulu, nejprve se ujistěte, že je verze nastavená jako výchozí, a pak postupujte podle kroků v části Testování hlasového modelu.
Aktualizace modulu vytvoří novou verzi modelu bez dalších poplatků. Po aktualizaci verze modulu pro váš hlasový model je potřeba nasadit novou verzi a vytvořit nový koncový bod. Můžete nasadit jenom výchozí verzi.
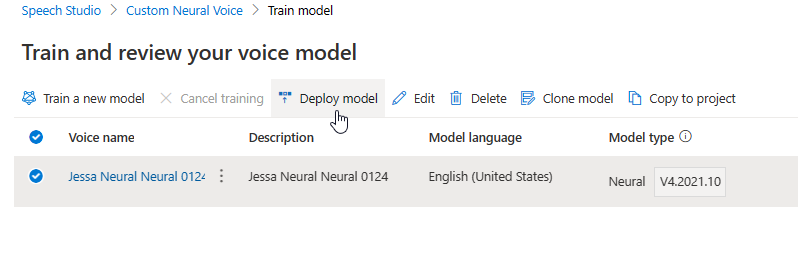
Po vytvoření nového koncového bodu musíte přenosy přenést do nového koncového bodu ve vašem produktu.
Další informace o možnostech a omezeních této funkce a osvědčeným postupem pro zlepšení kvality modelu najdete v tématu Charakteristiky a omezení pro používání vlastního neurálního hlasu.
Zkopírování hlasového modelu do jiného projektu
Hlasový model můžete zkopírovat do jiného projektu pro stejnou oblast nebo jinou oblast. Můžete například zkopírovat neurální hlasový model, který byl vytrénován v jedné oblasti, do projektu pro jinou oblast.
Poznámka:
Vlastní trénování neurálních hlasů je v současné době dostupné jenom v některých oblastech. Můžete zkopírovat neurální hlasový model z těchto oblastí do jiných oblastí. Další informace najdete v oblastech pro vlastní neurální hlas.
Kopírování vlastního neurálního hlasového modelu do jiného projektu:
Na kartě Trénování modelu vyberte hlasový model, který chcete zkopírovat, a pak vyberte Kopírovat do projektu.
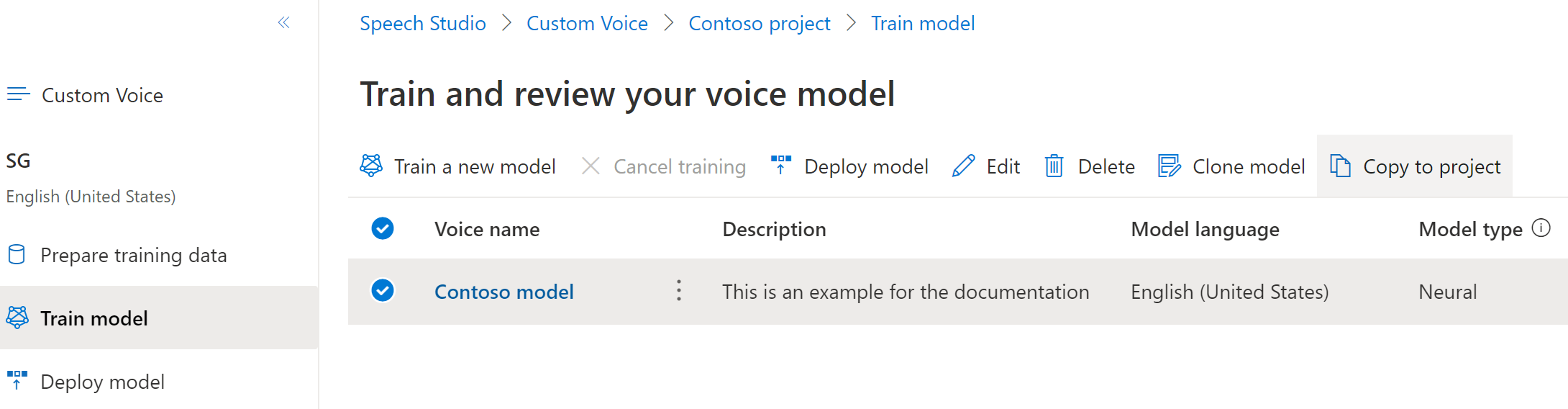
Vyberte oblast, prostředek služby Speech a projekt, do kterého chcete model zkopírovat. V cílové oblasti musíte mít prostředek a projekt řeči, jinak je musíte napřed vytvořit.
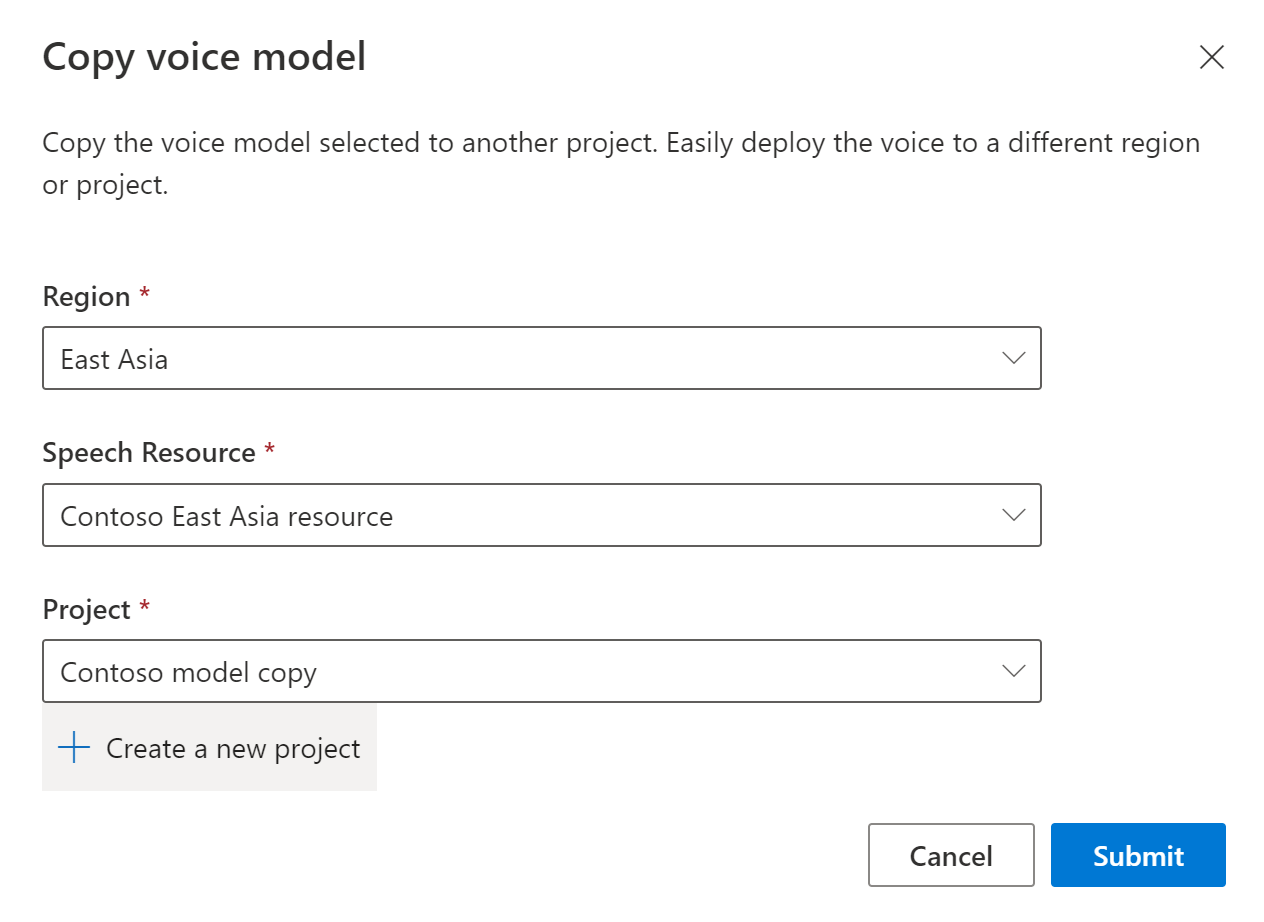
Vyberte Odeslat a zkopírujte model.
Vyberte Zobrazit model v oznamovací zprávě pro úspěšné kopírování.
Přejděte do projektu, do kterého jste model zkopírovali a nasadili kopii modelu.
Další kroky
V tomto článku se dozvíte, jak trénovat vlastní neurální hlas prostřednictvím vlastního hlasového rozhraní API.
Důležité
Vlastní trénování neurálních hlasů je v současné době dostupné jenom v některých oblastech. Jakmile se hlasový model vytrénuje v podporované oblasti, můžete ho podle potřeby zkopírovat do prostředku služby Speech v jiné oblasti. Další informace najdete v poznámkách pod čarou v tabulce služby Speech.
Doba trvání trénování se liší v závislosti na tom, kolik dat používáte. Trénování vlastního neurálního hlasu trvá v průměru přibližně 40 výpočetních hodin. Uživatelé s předplatným Standard (S0) můžou trénovat čtyři hlasy současně. Pokud dosáhnete limitu, počkejte, až aspoň jeden z vašich hlasových modelů dokončí trénování, a zkuste to znovu.
Poznámka:
I když se celkový počet hodin požadovaných pro metodu trénování liší, platí pro každou jednotkovou cenu stejná jednotková cena. Další informace najdete v podrobnostech o cenách vlastního neurálního trénování.
Volba metody trénování
Po ověření datových souborů je použijte k vytvoření vlastního neurálního hlasového modelu. Když vytvoříte vlastní neurální hlas, můžete ho vytrénovat pomocí jedné z následujících metod:
Neurální: Vytvořte hlas ve stejném jazyce trénovacích dat.
Neurální – křížový jazyk: Vytvořte hlas, který mluví jiným jazykem než trénovací data. Například s
fr-FRtrénovacími datyen-USmůžete vytvořit hlas, který mluví .Jazyk trénovacích dat a cílového jazyka musí být jedním z jazyků, které jsou podporovány pro křížové jazykové trénování hlasu. Nemusíte připravovat trénovací data v cílovém jazyce, ale váš testovací skript musí být v cílovém jazyce.
Neurální – více stylů: Vytvořte vlastní neurální hlas, který mluví ve více stylech a emocích, aniž byste museli přidávat nová trénovací data. Více stylů hlasy jsou užitečné pro znaky videohry, konverzační chatboty, audioknihy, čtenáře obsahu a další.
Pokud chcete vytvořit hlas s více styly, musíte připravit sadu obecných trénovacích dat, a to alespoň 300 promluv. Vyberte jeden nebo více přednastavených stylů cílového mluvení. Můžete také vytvořit více vlastních stylů tím, že poskytnete ukázky stylů s nejméně 100 promluvami na styl, jako další trénovací data pro stejný hlas. Podporované přednastavené styly se liší podle různých jazyků. Podívejte se na dostupné přednastavené styly v různých jazycích.
Jazyk trénovacích dat musí být jedním z jazyků, které jsou podporovány pro vlastní neurální hlas, křížové nebo více style trénování.
Vytvoření hlasového modelu
Pokud chcete vytvořit neurální hlas, použijte Models_Create operaci vlastního rozhraní API hlasu. Sestavte tělo požadavku podle následujících pokynů:
- Nastavte požadovanou
projectIdvlastnost. Viz vytvoření projektu. - Nastavte požadovanou
consentIdvlastnost. Viz přidání souhlasu s talentem hlasu. - Nastavte požadovanou
trainingSetIdvlastnost. Viz vytvoření trénovací sady. - Nastavte požadovanou vlastnost receptu
kindnaDefaultneuronové trénování hlasu. Druh receptu označuje metodu trénování a nelze ji později změnit. Pokud chcete použít jinou metodu trénování, přečtěte si téma Neuron – křížový neboneurální – více stylů. Další informace o dvojjazyčné trénování a rozdílech mezi národními prostředími najdete v tématu Dvojjazyčné školení . - Nastavte požadovanou
voiceNamevlastnost. Název hlasu musí končit neurálním názvem a nelze ho později změnit. Pečlivě zvolte jméno. Hlasový název se používá ve vašem požadavku na syntézu řeči vstupem sady SDK a SSML. Jsou povolená jenom písmena, číslice a několik interpunkčních znaků. Pro různé neurální hlasové modely používejte různé názvy. - Volitelně můžete nastavit
descriptionvlastnost pro popis hlasu. Popis hlasu můžete později změnit.
Vytvořte požadavek HTTP PUT pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu Models_Create.
- Nahraďte
YourResourceKeyklíčem prostředku služby Speech. - Nahraďte
YourResourceRegionoblastí prostředků služby Speech. - Nahraďte
JessicaModelIdpodle svého výběru ID modelu. V identifikátoru URI modelu se použije rozlišují malá a velká písmena a později ho nejde změnit.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Dvojjazyčné školení
Pokud vyberete typ neurálního trénování, můžete vytrénovat hlas pro mluvení ve více jazycích. zh-TW Obě národní prostředí zh-CN podporují dvojjazyčné školení pro hlas pro mluvení čínštiny i angličtiny. V závislosti na trénovacích datech může syntetizovaný hlas mluvit anglicky s anglickým nativním zvýrazněním nebo angličtinou se stejným zvýrazněním jako trénovací data.
Poznámka:
Pokud chcete, aby hlas v zh-CN národním prostředí mluvil anglicky se stejným zvýrazněním jako ukázková data, měli byste zvolit Chinese (Mandarin, Simplified), English bilingual při vytváření projektu nebo určit zh-CN (English bilingual) národní prostředí pro data trénovací sady prostřednictvím rozhraní REST API.
Následující tabulka ukazuje rozdíly mezi těmito dvěma národními prostředími:
| Národní prostředí sady Speech Studio | Národní prostředí rest API | Dvoujazyčná podpora |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Pokud vaše ukázková data obsahují angličtinu, syntetizovaný hlas mluví anglicky s anglickým nativním zvýrazněním, místo stejného zvýraznění jako ukázková data bez ohledu na množství anglických dat. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Pokud chcete, aby syntetizovaný hlas mluvil anglicky se stejným zvýrazněním jako ukázková data, doporučujeme zahrnout do trénovací sady více než 10 % anglických dat. V opačném případě nemusí být přízvuk pro angličtinu ideální. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Pokud chcete vytrénovat syntetizovaný hlas schopný mluvit anglicky se stejným zvýrazněním jako ukázková data, nezapomeňte do trénovací sady poskytnout více než 10 % anglických dat. V opačném případě se ve výchozím nastavení nastaví nativní zvýraznění v angličtině. Prahová hodnota 10 % se vypočítá na základě dat přijatých po úspěšném nahrání, nikoli dat před nahráním. Pokud jsou některá nahraná anglická data odmítnuta z důvodu vad a nesplňuje 10% prahovou hodnotu, syntetizovaná hlasová výchozí hodnota odpovídá anglickému nativnímu zvýraznění. |
Dostupné přednastavené styly v různých jazycích
Následující tabulka shrnuje různé přednastavené styly podle různých jazyků.
| Styl řeči | Jazyk (národní prostředí) |
|---|---|
| Rozzlobený | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Klid | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| chat | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Veselý | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Nespokojený | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Nadšený | Angličtina (USA) (en-US) |
| Strach | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Přátelské | Angličtina (USA) (en-US) |
| Nadějný | Angličtina (USA) (en-US) |
| Smutné | Angličtina (USA) (en-US)Japonština (Japonsko) ( ja-JP) 1Čínština (mandarínština, zjednodušená) ( zh-CN) 1 |
| Křičel | Angličtina (USA) (en-US) |
| Vážné | Čínština (mandarínština, zjednodušená) (zh-CN) 1 |
| Vyděšený | Angličtina (USA) (en-US) |
| Nepřátelský | Angličtina (USA) (en-US) |
| Šeptal | Angličtina (USA) (en-US) |
1 Styl neurálního hlasu je k dispozici ve verzi Public Preview. Styly ve verzi Public Preview jsou dostupné jenom v těchto oblastech služeb: USA – východ, Západní Evropa a Jihovýchodní Asie.
Získání stavu trénování
Pokud chcete získat stav trénování hlasového modelu, použijte Models_Get operaci vlastního hlasového rozhraní API. Podle následujících pokynů vytvořte identifikátor URI požadavku:
Vytvořte požadavek HTTP GET pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu Models_Get.
- Nahraďte
YourResourceKeyklíčem prostředku služby Speech. - Nahraďte
YourResourceRegionoblastí prostředků služby Speech. - Nahraďte
JessicaModelId, pokud jste v předchozím kroku zadali jiné ID modelu.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Měl by se zobrazit text odpovědi v následujícím formátu.
Poznámka:
Recept kind a další vlastnosti závisí na tom, jak jste trénovali hlas. V tomto příkladu je Default druh receptu určen pro neuronové trénování hlasu.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Možná budete muset několik minut počkat, než se trénování dokončí. Stav se nakonec změní na buď Succeeded nebo Failed.