Posun schématu při mapování toku dat
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Posun schématu je případ, kdy zdroje často mění metadata. Pole, sloupce a typy lze průběžně přidávat, odebírat nebo měnit. Bez zpracování posunu schématu se váš tok dat stává zranitelný vůči změnám nadřazeného zdroje dat. Typické vzory ETL selžou, když se změní příchozí sloupce a pole, protože jsou obvykle svázané s těmito názvy zdrojů.
Pokud chcete chránit před posunem schématu, je důležité mít zařízení v nástroji toku dat, abyste jako Datoví technici umožnili:
- Definování zdrojů s proměnlivými názvy polí, datovými typy, hodnotami a velikostmi
- Definování parametrů transformace, které můžou pracovat se vzory dat místo pevně zakódovaných polí a hodnot
- Definujte výrazy, které rozumí vzorům, aby odpovídaly příchozím polím, místo použití pojmenovaných polí.
Azure Data Factory nativně podporuje flexibilní schémata, která se mění ze spouštění na spouštění, abyste mohli vytvářet obecnou logiku transformace dat bez nutnosti překompilovat toky dat.
Pokud chcete přijmout posun schématu v celém toku dat, musíte v toku provést rozhodnutí o architektuře. Když to uděláte, můžete chránit před změnami schématu ze zdrojů. V průběhu toku dat ale ztratíte časnou vazbu sloupců a typů. Azure Data Factory zpracovává toky posunu schématu jako toky s pozdní vazbou, takže při sestavování transformací nebudou názvy posunovaných sloupců dostupné v zobrazení schématu v celém toku.
Toto video obsahuje úvod do některých složitých řešení, která můžete snadno sestavit v kanálech Azure Data Factory nebo Synapse Analytics pomocí funkce posunu schématu toku dat. V tomto příkladu vytváříme opakovaně použitelné vzory založené na flexibilních schématech databáze:
Posun schématu ve zdroji
Sloupce přicházející do toku dat z vaší definice zdroje se definují jako "posunované", pokud ve zdrojové projekci nejsou. Zdrojová projekce můžete zobrazit na kartě projekce ve zdrojové transformaci. Když pro zdroj vyberete datovou sadu, služba automaticky převezme schéma z datové sady a vytvoří projekci z této definice schématu datové sady.
V transformaci zdroje je posun schématu definován jako čtení sloupců, které nejsou definovány ve schématu datové sady. Pokud chcete povolit posun schématu, zaškrtněte políčko Povolit posun schématu ve zdrojové transformaci.
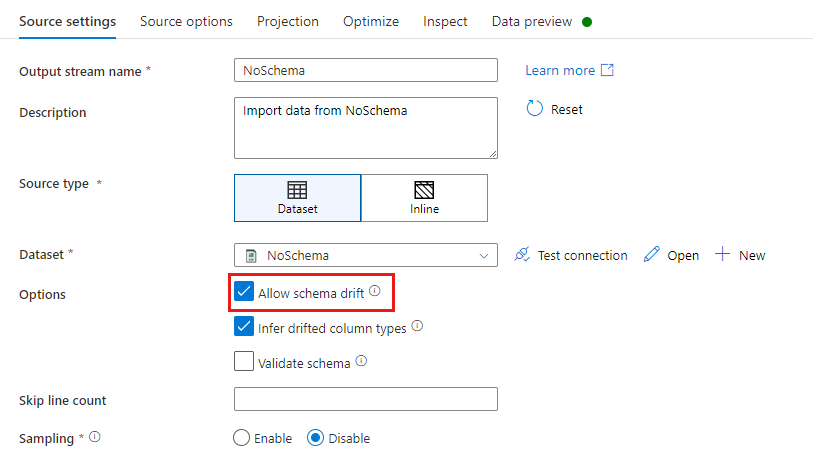
Pokud je povolen posun schématu, všechna příchozí pole se během provádění načtou z vašeho zdroje a předají se celým tokem do jímky. Ve výchozím nastavení všechny nově zjištěné sloupce, označované jako posunované sloupce, přicházejí jako datový typ řetězce. Pokud chcete, aby tok dat automaticky odvozoval datové typy posunovaných sloupců, zkontrolujte v nastavení zdroje odvozené typy posunutých sloupců .
Posun schématu v jímce
Při transformaci jímky je posun schématu při zápisu dalších sloupců nad tím, co je definováno ve schématu dat jímky. Pokud chcete povolit posun schématu, zaškrtněte políčko Povolit posun schématu v transformaci jímky.
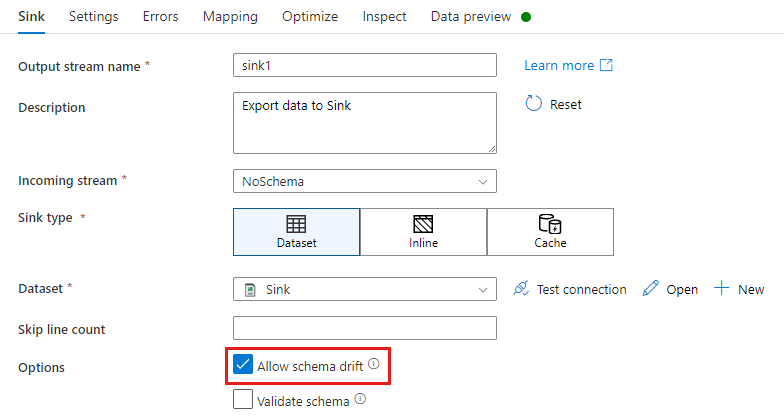
Pokud je povolen posun schématu, ujistěte se, že je zapnutý posuvník automatického mapování na kartě Mapování. Pomocí tohoto posuvníku jsou všechny příchozí sloupce zapsány do cíle. V opačném případě je nutné použít mapování založené na pravidlech k zápisu posunovaných sloupců.
Transformace posunutých sloupců
Pokud má tok dat posunované sloupce, můžete k nim přistupovat ve svých transformacích pomocí následujících metod:
byPositionPomocí výrazů můžetebyNameexplicitně odkazovat na sloupec podle názvu nebo čísla pozice.- Přidání vzoru sloupce do odvozeného sloupce nebo agregační transformace, která se shoduje s libovolnou kombinací názvu, datového proudu, pozice, původu nebo typu
- Přidání mapování založeného na pravidlech v transformaci Výběr nebo Jímka tak, aby odpovídalo posunovaným sloupcům s aliasy sloupců prostřednictvím vzoru
Další informace o implementaci vzorů sloupců najdete v tématu Vzory sloupců v mapování toku dat.
Rychlá akce mapování posunovaných sloupců
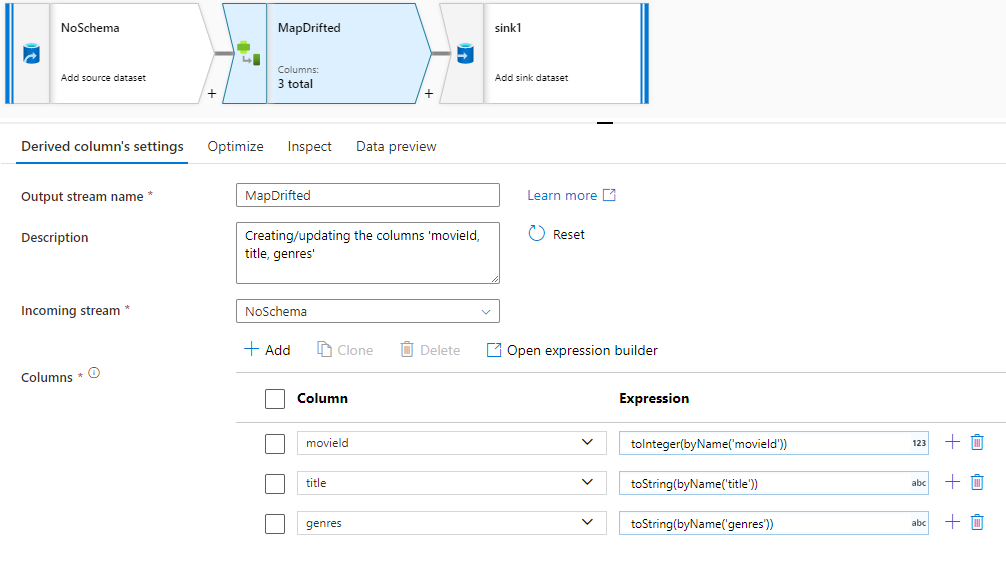
Pokud chcete explicitně odkazovat na posunované sloupce, můžete rychle vygenerovat mapování těchto sloupců prostřednictvím rychlé akce náhledu dat. Jakmile je režim ladění zapnutý, přejděte na kartu Náhled dat a kliknutím na Aktualizovat načtěte náhled dat. Pokud datová továrna zjistí, že existují posunované sloupce, můžete kliknout na Mapovat posuny a vygenerovat odvozený sloupec, který umožňuje odkazovat na všechny posunované sloupce v zobrazení schématu podřízené.
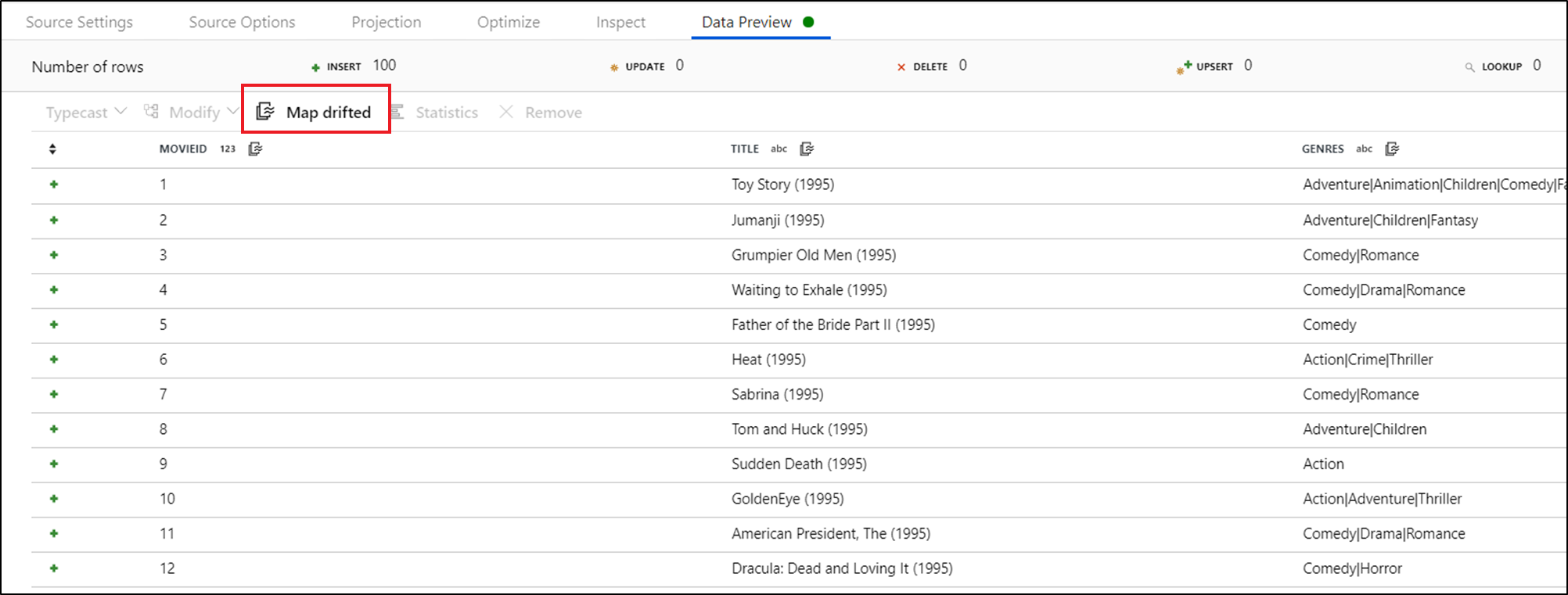
Ve vygenerované transformaci odvozeného sloupce se každý posunovaný sloupec mapuje na jeho rozpoznaný název a datový typ. Ve výše uvedeném náhledu dat se sloupec movieId rozpozná jako celé číslo. Po kliknutí na mapový posun se videoId definuje v odvozený sloupec jako toInteger(byName('movieId')) a je součástí zobrazení schématu v podřízených transformacích.
Související obsah
V jazyce výrazů Tok dat najdete další možnosti pro vzory sloupců a posun schématu, včetně "byName" a "byPosition".