Použití vzorů sloupců v mapování toků dat
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Několik transformací mapování toků dat umožňuje odkazovat na sloupce šablon založené na vzorech místo pevně zakódovaných názvů sloupců. Tato shoda se označuje jako vzory sloupců. Můžete definovat vzory tak, aby odpovídaly sloupcům na základě názvu, datového typu, datového proudu, zdroje nebo pozice, a nemusíte vyžadovat přesné názvy polí. Existují dva scénáře, ve kterých jsou vzorce sloupců užitečné:
- Pokud se příchozí zdrojová pole často mění, například případ změny sloupců v textových souborech nebo databázích NoSQL. Tento scénář se označuje jako posun schématu.
- Pokud chcete provést běžnou operaci u velké skupiny sloupců. Například chcete přetypovat každý sloupec, který má v názvu sloupce součet, na dvojitou.
Vzory sloupců v odvozených sloupcích a agregaci
Pokud chcete přidat vzor sloupce do odvozeného sloupce, agregace nebo transformace okna, klikněte na Přidat nad seznam sloupců nebo ikonu plus vedle existujícího odvozeného sloupce. Zvolte Přidat vzor sloupce.
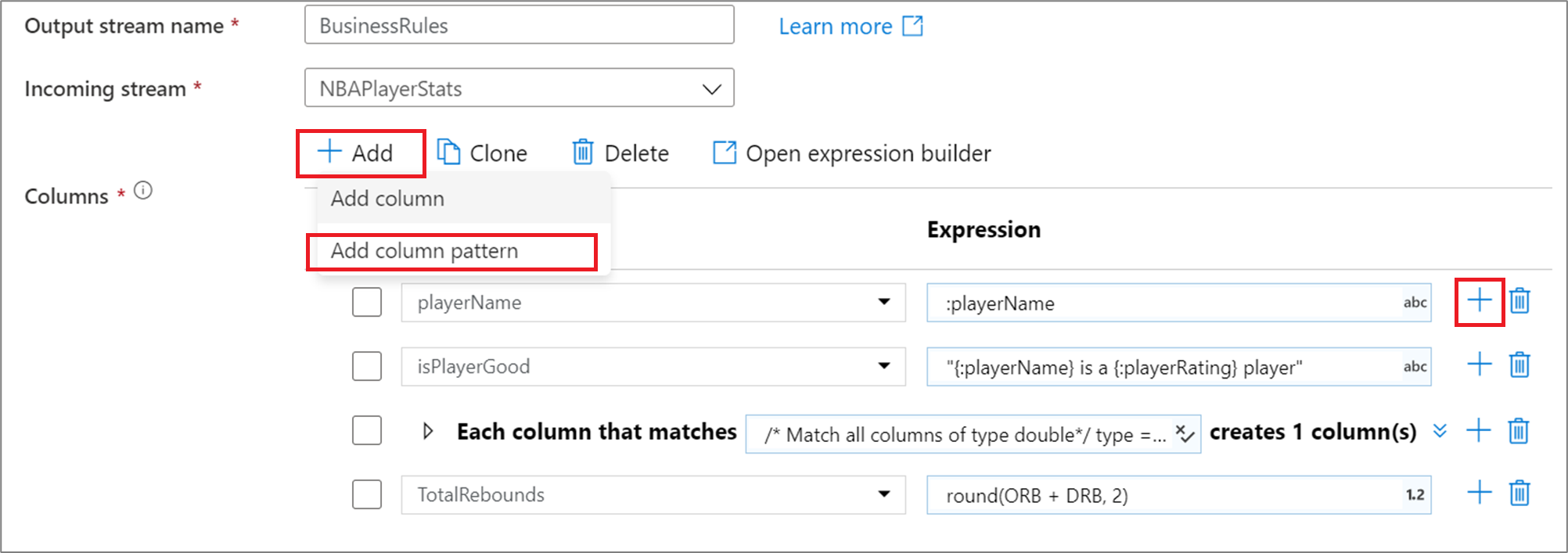
Pomocí tvůrce výrazů zadejte podmínku shody. Vytvořte logický výraz, který odpovídá sloupcům založeným na sloupci name, type, originstream, a position ve sloupci. Vzor ovlivní jakýkoli sloupec, posun nebo definovaný, kde podmínka vrátí hodnotu true.
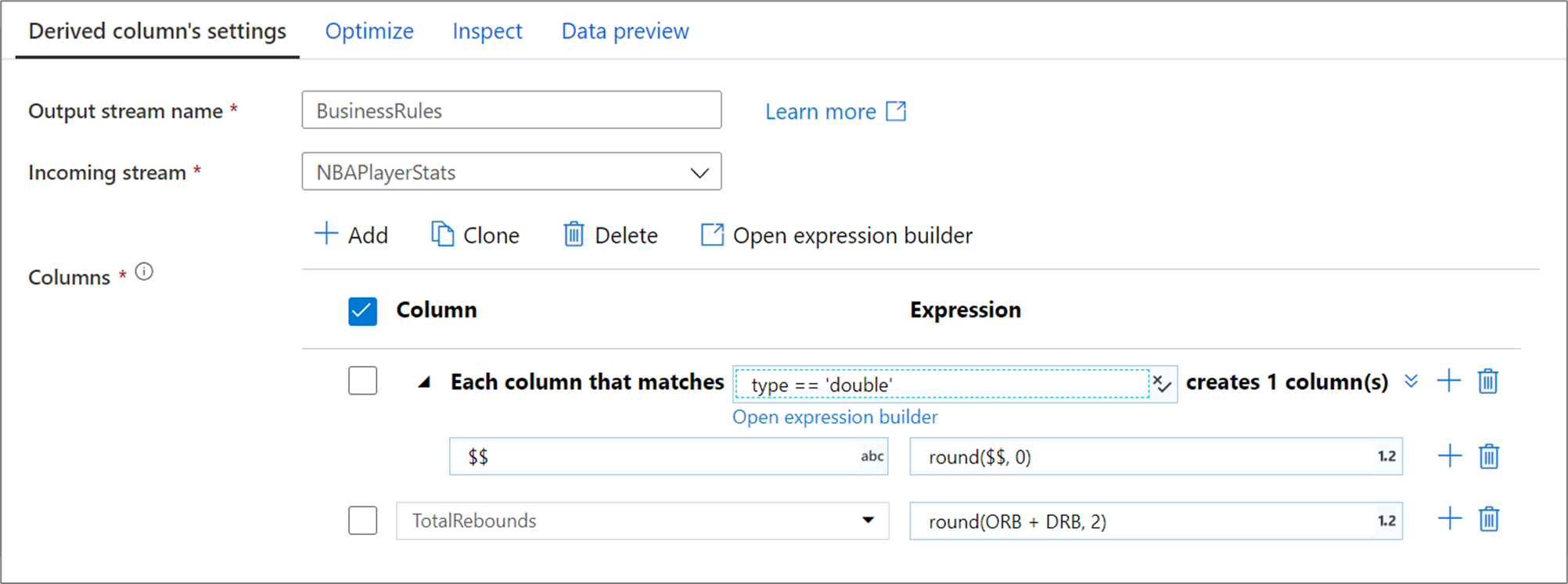
Výše uvedený vzor sloupce odpovídá každému sloupci typu double a vytvoří jeden odvozený sloupec podle shody. Když jako pole s názvem sloupce uvedete $$ , každý odpovídající sloupec se aktualizuje se stejným názvem. Hodnota každého sloupce je existující hodnota zaokrouhlená na dvě desetinná místa.
Pokud chcete ověřit správnost odpovídající podmínky, můžete ověřit výstupní schéma definovaných sloupců na kartě Kontrola nebo získat snímek dat na kartě Náhled dat.
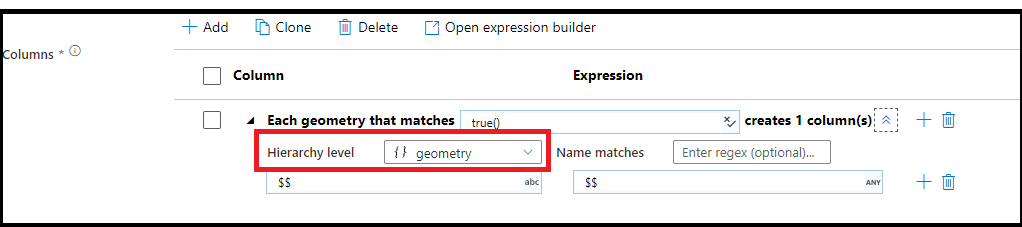
Porovnávání hierarchických vzorů
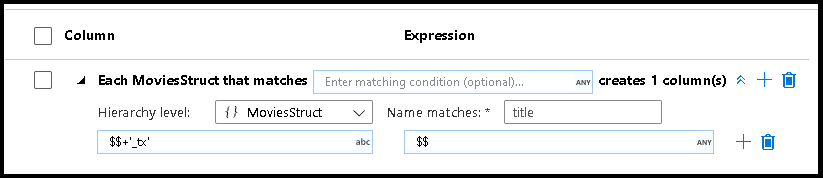
Můžete také vytvořit porovnávání vzorů uvnitř složitých hierarchických struktur. Rozbalte oddíl Each MoviesStruct that matches , ve kterém se zobrazí výzva pro každou hierarchii datového streamu. Pak můžete vytvořit odpovídající vzory pro vlastnosti v rámci zvolené hierarchie.
Zploštěné konstrukce
Pokud data obsahují složité struktury, jako jsou pole, hierarchické struktury a mapy, můžete pomocí transformace Flatten zrušit registraci polí a denormalizovat data. U struktur a map použijte odvozenou transformaci sloupců se vzory sloupců k vytvoření zploštěné relační tabulky z hierarchií. Můžete použít vzory sloupců, které by vypadaly jako v této ukázce, což zploštělo geografickou hierarchii do formuláře relační tabulky:
Mapování na základě pravidel ve výběru a jímce
Při mapování sloupců ve zdroji a výběrových transformací můžete přidat buď pevné mapování, nebo mapování založená na pravidlech. Porovná se na namezákladě sloupce , , typestream, origina position sloupců. Můžete mít libovolnou kombinaci pevných mapování a mapování založených na pravidlech. Ve výchozím nastavení se ve všech projekcích s více než 50 sloupci ve výchozím nastavení použije mapování založené na pravidlech, které odpovídá každému sloupci a vypíše zadaný název.
Chcete-li přidat mapování založené na pravidlech, klepněte na tlačítko Přidat mapování a vyberte mapování založené na pravidlech.

Každé mapování založené na pravidlech vyžaduje dva vstupy: podmínku, podle které se má shodovat, a název každého mapovaného sloupce. Obě hodnoty se zadávají prostřednictvím tvůrce výrazů. Do levého pole výrazu zadejte logickou podmínku shody. Do pravého pole výrazu zadejte, na co se bude namapovat odpovídající sloupec.

Pomocí $$ syntaxe můžete odkazovat na vstupní název odpovídajícího sloupce. Když použijete výše uvedený obrázek jako příklad, řekněme, že uživatel chce shodovat se všemi řetězcovými sloupci, jejichž názvy jsou kratší než šest znaků. Pokud byl pojmenován testjeden příchozí sloupec , výraz $$ + '_short' přejmenuje sloupec test_short. Pokud je to jediné mapování, které existuje, všechny sloupce, které nesplňují podmínku, se z výstupních dat zahodí.
Vzory odpovídají posunutým i definovaným sloupcům. Pokud chcete zjistit, které definované sloupce jsou mapovány pravidlem, klikněte na ikonu brýlí vedle pravidla. Ověřte výstup pomocí náhledu dat.
Mapování regulárních výrazů
Pokud kliknete na ikonu dvojité šipky dolů, můžete zadat podmínku mapování regulárních výrazů. Podmínka mapování regulárních výrazů odpovídá všem názvům sloupců, které odpovídají zadané podmínce regulárního výrazu. To lze použít v kombinaci se standardními mapováními založenými na pravidlech.

Výše uvedený příklad odpovídá vzoru regulárního výrazu (r) nebo libovolnému názvu sloupce, který obsahuje malé písmeno r. Podobně jako u standardního mapování založeného na pravidlech se všechny odpovídající sloupce mění podmínkou na pravé straně pomocí $$ syntaxe.
Hierarchie založené na pravidlech
Pokud má definovaná projekce hierarchii, můžete k mapování podsloupců hierarchií použít mapování založené na pravidlech. Zadejte odpovídající podmínku a složitý sloupec, jehož podsloupce chcete mapovat. Každý odpovídající podsloupec se vypíše pomocí pravidla Name as zadaného na pravé straně.
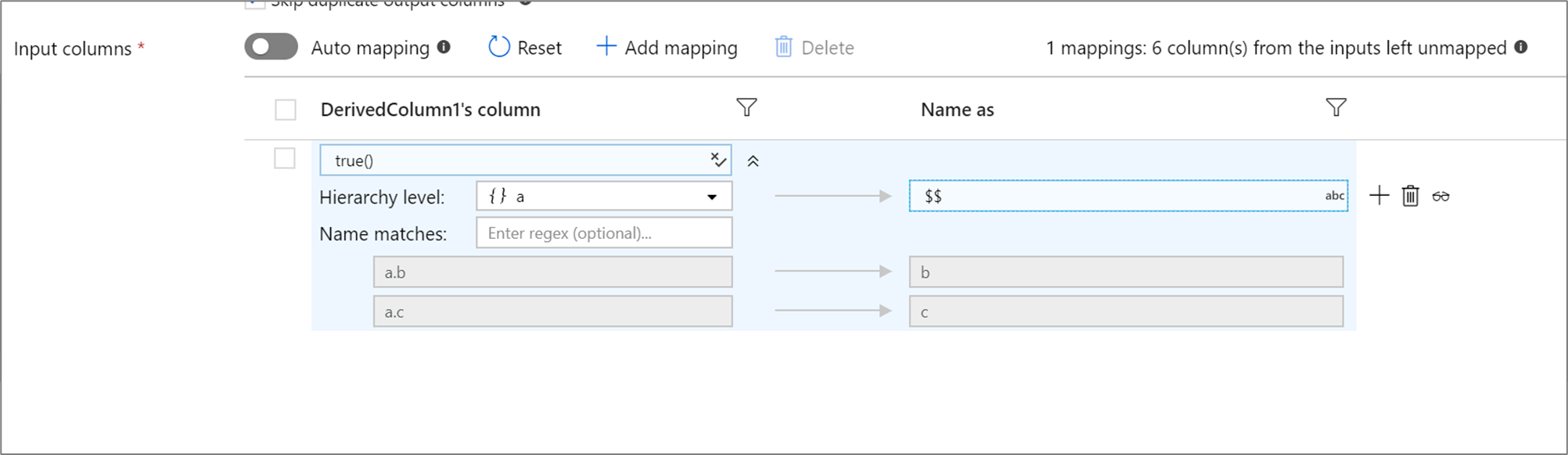
Výše uvedený příklad odpovídá všem dílčím sloupcům komplexního sloupce a. a obsahuje dva podsloupce b a c. Výstupní schéma bude obsahovat dva sloupce b a c jako podmínku Name as je $$.
Hodnoty porovnávání vzorů výrazů
$$přeloží na název nebo hodnotu každé shody za běhu.$$Představte si, že je ekvivalentníthis$0pro skalární typy se přeloží na shodu názvu aktuálního sloupce za běhu. U hierarchických typů$0představuje aktuální odpovídající cestu hierarchie sloupců.namepředstavuje název každého příchozího sloupce.typepředstavuje datový typ každého příchozího sloupce. Seznam datových typů v systému typů toků dat najdete tady.streampředstavuje název přidružený ke každému datovému proudu nebo transformaci ve vašem toku.positionje pořadové umístění sloupců ve vašem toku dat.originje transformace, kde sloupec pochází nebo byl naposledy aktualizován.
Související obsah
- Další informace o jazyce výrazů mapování toků dat pro transformace dat
- Použití vzorů sloupců v transformaci jímky a výběr transformace s mapováním založeným na pravidlech