Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat přes následné zpracování dat, analýzy v reálném čase, podnikovou inteligenci a reporting. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Aktivita poznámkového bloku Azure Databricks v potrubí spouští poznámkový blok Databricks ve vašem pracovním prostoru Azure Databricks. Tento článek vychází z článku o aktivitách transformace dat, který představuje obecný přehled transformace dat a podporovaných transformačních aktivit. Azure Databricks je spravovaná platforma pro spouštění Apache Sparku.
Notebook Databricks můžete vytvořit pomocí šablony ARM v JSON, nebo přímo prostřednictvím uživatelského rozhraní Azure Data Factory Studio. Podrobný návod, jak vytvořit aktivitu poznámkového bloku Databricks pomocí uživatelského rozhraní, najdete v kurzu Spuštění poznámkového bloku Databricks s aktivitou poznámkového bloku Databricks ve službě Azure Data Factory.
Přidejte úlohu poznámkového bloku pro Azure Databricks do zpracovatelského řetězce pomocí uživatelského rozhraní.
Pokud chcete v kanálu použít aktivitu poznámkového bloku pro Azure Databricks, proveďte následující kroky:
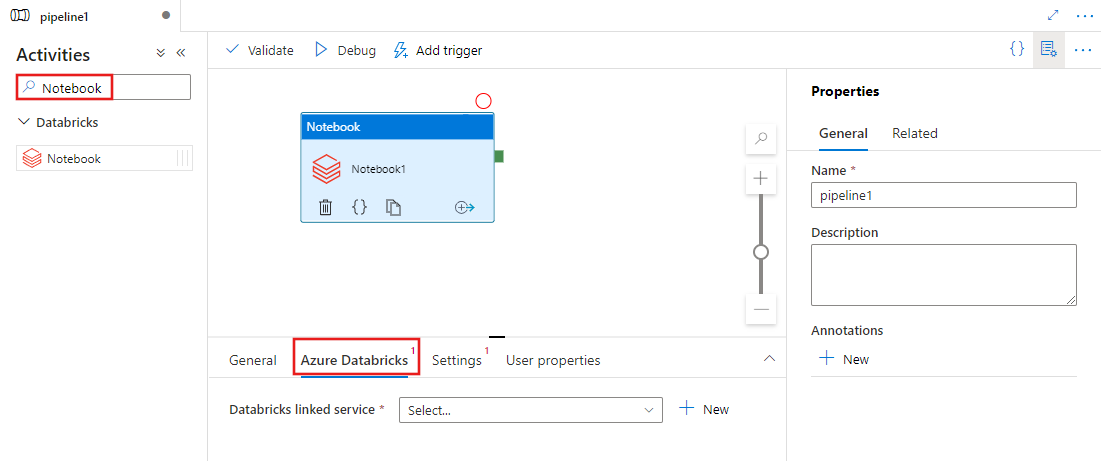
Vyhledejte poznámkový blok v podokně Aktivity kanálu a přetáhněte aktivitu poznámkového bloku na plátno kanálu.
Pokud ještě není vybraná, vyberte na plátně novou aktivitu poznámkového bloku.
Vyberte kartu Azure Databricks a vyberte nebo vytvořte novou propojenou službu Azure Databricks, která vykoná notebookovou aktivitu.
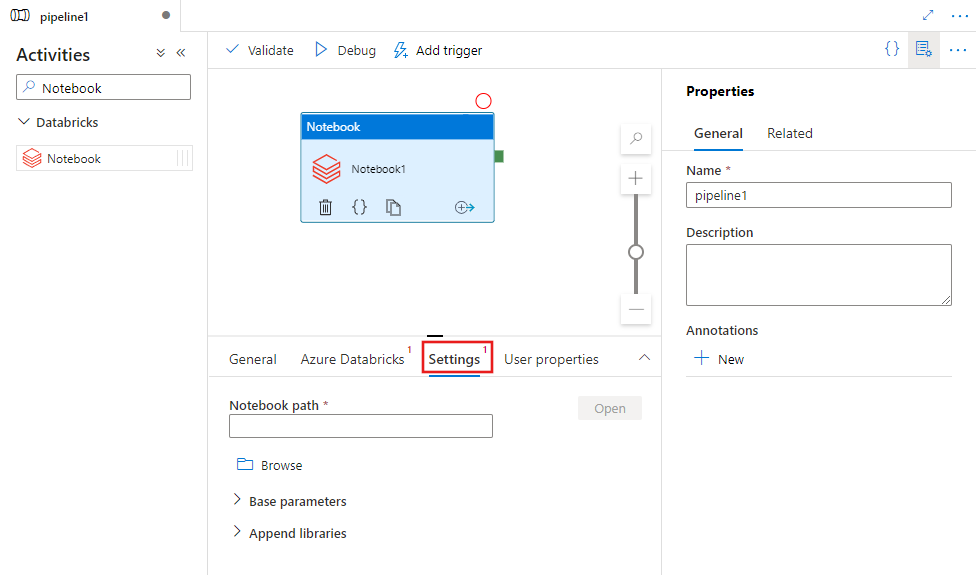
Vyberte kartu Nastavení a zadejte cestu poznámkového bloku, která se má spustit v Azure Databricks, volitelné základní parametry, které se mají předat do poznámkového bloku, a všechny další knihovny, které se mají nainstalovat do clusteru, aby se úloha spustila.
Definice aktivity poznámkového bloku Databricks
Tady je ukázková definice JSON aktivity poznámkového bloku Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Vlastnosti aktivity poznámkového bloku Databricks
Následující tabulka popisuje vlastnosti JSON použité v definici JSON:
| Vlastnost | Popis | Povinné |
|---|---|---|
| název | Název aktivity v potrubí. | Ano |
| popis | Text popisující, co aktivita dělá. | Ne |
| typ | U aktivity poznámkového bloku Databricks je typ aktivity DatabricksNotebook. | Ano |
| názevPrepojenéSlužby | Název služby Databricks Linked Service, na které běží notebook Databricks. Další informace o této propojené službě najdete v článku o propojených službách Compute. | Ano |
| notebookPath | Absolutní cesta notebooku, který se má spustit v pracovním prostoru Databricks. Tato cesta musí začínat lomítkem. | Ano |
| základníParametry | Pole klíčových-hodnotových párů. Základní parametry lze použít pro každé spuštění aktivity. Pokud poznámkový blok vezme parametr, který není zadaný, použije se výchozí hodnota z poznámkového bloku. Další informace o parametrech najdete v Databricks Notebooky. | Ne |
| knihovny | Seznam knihoven, které se mají nainstalovat do clusteru, který spustí úlohu. Může to být pole <řetězců, objektů>. | Ne |
Podporované knihovny pro aktivity Databricks
V definici aktivity Databricks zadáte tyto typy knihoven: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Další informace najdete v dokumentaci k Databricks pro typy knihoven.
Předávání parametrů mezi notebooky a pipelineami
Parametry můžete předat poznámkovým blokům pomocí vlastnosti baseParameters v aktivitě Databricks.
V některých případech může být potřebné předat určité hodnoty z poznámkového bloku zpět do služby, které lze použít pro řídicí tok (podmínkové kontroly) ve službě nebo být zpracovány následnými aktivitami (limit velikosti je 2 MB).
V poznámkovém bloku můžete zavolat dbutils.notebook.exit("returnValue") a odpovídající "returnValue" bude vrácen do služby.
Výstup ve službě můžete využívat pomocí výrazu, například
@{activity('databricks notebook activity name').output.runOutput}.Důležité
Pokud předáváte objekt JSON, můžete načíst hodnoty připojením názvů vlastností. Příklad:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Jak nahrát knihovnu v Databricks
Můžete použít uživatelské rozhraní pracovního prostoru:
Použití uživatelského rozhraní pracovního prostoru Databricks
K získání cesty dbfs knihovny přidané pomocí uživatelského rozhraní můžete použít Rozhraní příkazového řádku Databricks.
Knihovny Jar se obvykle ukládají v souboru dbfs:/FileStore/jars při používání uživatelského rozhraní. Můžete vypsat všechny prostřednictvím příkazového řádku (CLI): databricks fs ls dbfs:/FileStore/job-jars
Nebo můžete použít rozhraní příkazového řádku Databricks:
Postupujte podle pokynů ke kopírování knihovny pomocí rozhraní příkazového řádku Databricks.
Použijte Databricks CLI (kroky instalace)
Například zkopírování souboru JAR do dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar