dotazovací jazyk Kusto v Microsoft Sentinelu
dotazovací jazyk Kusto je jazyk, který použijete k práci s daty a manipulaci s nimi v Microsoft Sentinelu. Pokud je nemůžete analyzovat a získat důležité informace skryté ve všech datech, za protokoly, které do svého pracovního prostoru vložíte, moc nestojí. dotazovací jazyk Kusto má nejen výkon a flexibilitu pro získání informací, ale jednoduchost, která vám pomůže rychle začít. Pokud máte zkušenosti se skriptováním nebo prací s databázemi, hodně obsahu tohoto článku bude velmi známé. Pokud ne, nemějte obavy, protože intuitivní povaha jazyka vám umožní rychle začít psát vlastní dotazy a řídit hodnotu pro vaši organizaci.
Tento článek představuje základy dotazovací jazyk Kusto, které pokrývají některé z nejčastěji používaných funkcí a operátorů, které by měly adresovat 75 až 80 procent dotazů, které budete psát každý den. Pokud budete potřebovat větší hloubku nebo spustíte pokročilejší dotazy, můžete využít výhod nového sešitu Advanced KQL pro Microsoft Sentinel (viz tento úvodní blogový příspěvek). Projděte si také oficiální dotazovací jazyk Kusto dokumentaci a také řadu online kurzů (jako je pluralsight).
Pozadí – proč dotazovací jazyk Kusto?
Služba Microsoft Sentinel je založená na službě Azure Monitor a využívá pracovní prostory služby Log Analytics služby Azure Monitor k ukládání všech dat. Tato data zahrnují některou z následujících možností:
- data ingestovaná z externích zdrojů do předdefinovaných tabulek pomocí datových konektorů Microsoft Sentinelu.
- data ingestovaná z externích zdrojů do uživatelsky definovaných vlastních tabulek pomocí vlastních datových konektorů a některých typů předdefinovaných konektorů.
- data vytvořená samotnou službou Microsoft Sentinel, která jsou výsledkem analýz, které vytváří a provádí – například výstrahy, incidenty a informace související s UEBA.
- data nahraná do Microsoft Sentinelu, která pomáhají s detekcí a analýzou – například informační kanály analýzy hrozeb a seznamy ke zhlédnutí.
dotazovací jazyk Kusto byla vyvinuta jako součást služby Azure Data Explorer a je proto optimalizovaná pro vyhledávání prostřednictvím úložišť velkých objemů dat v cloudovém prostředí. Inspirovaná slavným průzkumníkem Podmořanem JacquesEm Cousteauem (a vyslovuje se odpovídajícím způsobem "koo-STOH"), je navržená tak, aby vám pomohla ponořit se hluboko do oceánů dat a prozkoumat jejich skryté poklady.
dotazovací jazyk Kusto se také používá ve službě Azure Monitor (a proto v Microsoft Sentinelu), včetně některých dalších funkcí služby Azure Monitor, které umožňují načítat, vizualizovat, analyzovat a analyzovat data v úložištích dat Log Analytics. V Microsoft Sentinelu používáte nástroje založené na dotazovací jazyk Kusto vždy, když vizualizujete a analyzujete data a proaktivní vyhledávání hrozeb, ať už v existujících pravidlech a sešitech, nebo při vytváření vlastních.
Vzhledem k tomu, že dotazovací jazyk Kusto je součástí téměř všeho, co v Microsoft Sentinelu děláte, jasné porozumění tomu, jak to funguje, vám pomůže získat z siEM mnohem více informací.
Co je dotaz?
Dotaz dotazovací jazyk Kusto je požadavek jen pro čtení pro zpracování dat a vrácení výsledků – nezapisuje žádná data. Dotazy pracují s daty uspořádanými do hierarchie databází, tabulek a sloupců, podobně jako SQL.
Požadavky jsou uvedeny v prostém jazyce a používají model toku dat navržený tak, aby se syntaxe snadno četla, zapisovala a automatizovala. Uvidíme to podrobně.
dotazovací jazyk Kusto dotazy se skládají z příkazů oddělených středníky. Existuje mnoho druhů příkazů, ale zde probereme jen dva široce používané typy:
příkazy tabulkového výrazu obvykle znamenají, když mluvíme o dotazech – jedná se o skutečný text dotazu. Důležité vědět o příkazech tabulkových výrazů je, že přijímají tabulkový vstup (tabulku nebo jiný tabulkový výraz) a vytvářejí tabulkový výstup. Vyžaduje se aspoň jedna z těchto možností. Většina zbytku tohoto článku se bude zabývat tímto druhem prohlášení.
Příkazy let umožňují vytvářet a definovat proměnné a konstanty mimo tělo dotazu, což usnadňuje čitelnost a všestrannost. Ty jsou volitelné a závisí na vašich konkrétních potřebách. Tento druh příkazu budeme řešit na konci článku.
Ukázkové prostředí
V ukázkovém prostředí Log Analytics na webu Azure Portal si můžete procvičit dotazovací jazyk Kusto příkazy , včetně příkazů v tomto článku. Za použití tohoto praktického prostředí se neúčtují žádné poplatky, ale pro přístup k němu potřebujete účet Azure.
Prozkoumejte ukázkové prostředí. Podobně jako Log Analytics v produkčním prostředí ho můžete použít několika způsoby:
Zvolte tabulku, na které chcete vytvořit dotaz. Na výchozí kartě Tabulky (zobrazený v červeném obdélníku vlevo nahoře) vyberte tabulku ze seznamu tabulek seskupených podle témat (zobrazených vlevo dole). Rozbalte témata, abyste viděli jednotlivé tabulky, a můžete dále rozbalit každou tabulku, abyste viděli všechna její pole (sloupce). Poklikáním na tabulku nebo název pole ji umístíte na místo kurzoru v okně dotazu. Zadejte zbytek dotazu podle názvu tabulky, jak je znázorněno níže.
Vyhledejte existující dotaz pro studium nebo úpravu. Výběrem karty Dotazy (zobrazený v červeném obdélníku v levém horním rohu) zobrazíte seznam dotazů, které jsou k dispozici předem. Nebo vyberte Dotazy z panelu tlačítek v pravém horním rohu. Můžete prozkoumat dotazy, které jsou součástí Microsoft Sentinelu. Poklikáním na dotaz umístíte celý dotaz do okna dotazu v místě kurzoru.
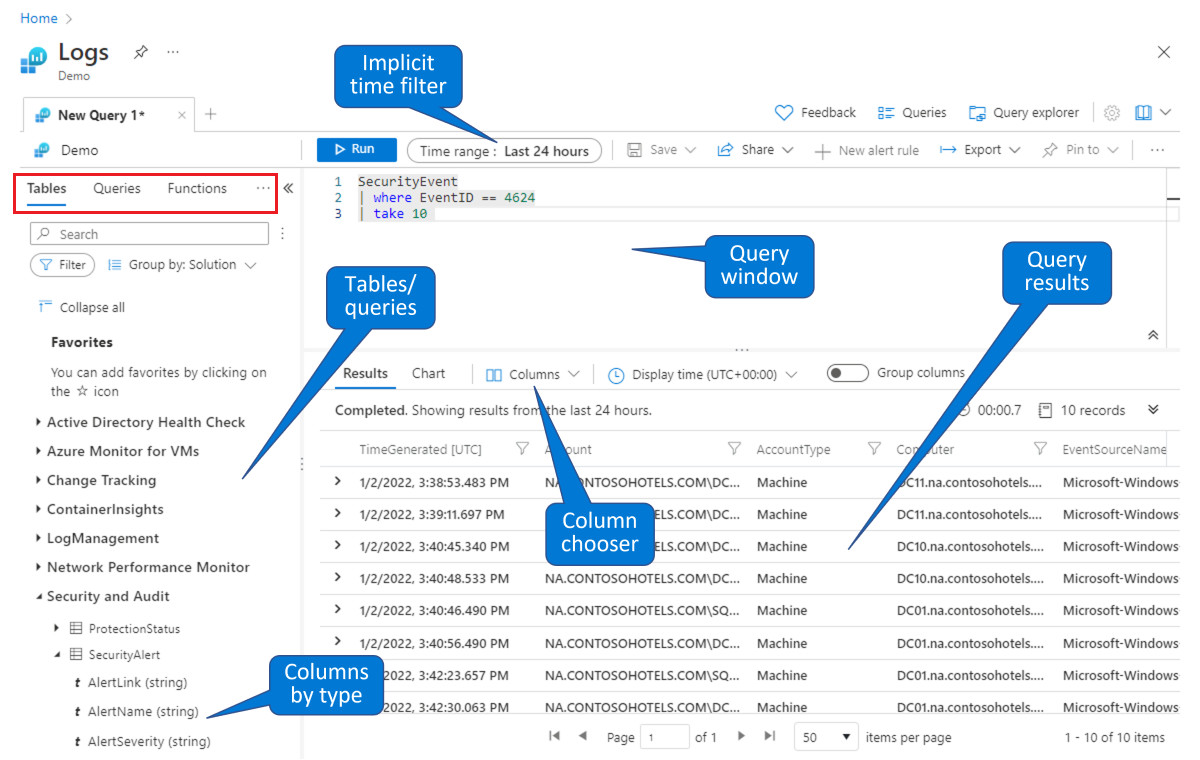
Podobně jako v tomto ukázkovém prostředí můžete dotazovat a filtrovat data na stránce Protokoly Microsoft Sentinelu. Můžete vybrat tabulku a přejít k podrobnostem a zobrazit sloupce. Výchozí sloupce zobrazené pomocí výběru sloupců můžete upravit a pro dotazy můžete nastavit výchozí časový rozsah. Pokud je časový rozsah explicitně definovaný v dotazu, nebude filtr času dostupný (šedě).
Struktura dotazu
Dobrým místem, kde začít učit dotazovací jazyk Kusto, je porozumět celkové struktuře dotazů. První věc, kterou si všimnete, když se podíváte na dotaz Kusto, je použití symbolu kanálu (|). Struktura dotazu Kusto začíná získáním dat ze zdroje dat a následným předáním dat v rámci kanálu a každý krok poskytuje určitou úroveň zpracování a pak je předá dalšímu kroku. Na konci kanálu získáte konečný výsledek. To je v podstatě náš kanál:
Get Data | Filter | Summarize | Sort | Select
Díky tomuto konceptu předávání dat kanálem je velmi intuitivní struktura, protože v každém kroku můžete snadno vytvořit duševní obraz vašich dat.
Abychom to mohli ilustrovat, podívejme se na následující dotaz, který se podívá na protokoly přihlášení Microsoft Entra. Při čtení jednotlivých řádků uvidíte klíčová slova, která označují, co se děje s daty. Do kanálu jsme zahrnuli příslušnou fázi jako komentář na každém řádku.
Poznámka:
Komentáře můžete do libovolného řádku dotazu přidat tak, že před ně přidáte dvojité lomítko (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Vzhledem k tomu, že výstup každého kroku slouží jako vstup pro následující krok, pořadí kroků může určit výsledky dotazu a ovlivnit jeho výkon. Je důležité, abyste postup naspořádal podle toho, co chcete z dotazu dostat.
Tip
- Dobrým pravidlem je filtrování dat v rané fázi, takže předáváte jenom relevantní data do kanálu. Tím se výrazně zvýší výkon a zajistíte, že do kroků souhrnu omylem nezahrnete irelevantní data.
- Tento článek upozorňuje na některé další osvědčené postupy, které je potřeba mít na paměti. Podrobnější seznam najdete v osvědčených postupech pro dotazy.
Doufejme, že teď oceníte celkovou strukturu dotazu v dotazovací jazyk Kusto. Teď se podíváme na samotné operátory dotazů, které se používají k vytvoření dotazu.
Datové typy
Než se dostaneme k operátorům dotazů, pojďme se nejprve rychle podívat na datové typy. Stejně jako ve většině jazyků datový typ určuje, jaké výpočty a manipulace se dají spouštět s hodnotou. Pokud máte například hodnotu typu řetězec, nebudete s ní moct provádět aritmetické výpočty.
Ve dotazovací jazyk Kusto většina datových typů dodržuje standardní konvence a má názvy, které jste pravděpodobně viděli dříve. Následující tabulka obsahuje úplný seznam:
Tabulka datových typů
| Typ | Další názvy | Ekvivalentní typ v .NET |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
I když je většina datových typů standardní, možná znáte typy, jako jsou dynamické, časové rozpětí a identifikátor GUID.
Dynamická má velmi podobnou strukturu JSON, ale s jedním klíčovým rozdílem: Může ukládat datové typy specifické pro dotazovací jazyk Kusto, které tradiční JSON nemůže, například vnořenou dynamickou hodnotu nebo časový rozsah. Tady je příklad dynamického typu:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Časový rozsah je datový typ, který odkazuje na míru času, jako jsou hodiny, dny nebo sekundy. Nezaměňujte časový interval s datetime, který se vyhodnotí jako skutečné datum a čas, nikoli míra času. Následující tabulka obsahuje seznam přípon časového rozsahu.
Přípony časového rozsahu
| Function | Popis |
|---|---|
D |
dny (dní) |
H |
hodin(y) |
M |
minutes |
S |
sekund(y) |
Ms |
milisekundy |
Microsecond |
mikrosekundy |
Tick |
nanosekund |
Identifikátor GUID představuje datový typ představující 128bitový globálně jedinečný identifikátor, který se řídí standardním formátem [8]-[4]-[4]-[4]-[12], kde každý [číslo] představuje počet znaků a každý znak může být v rozsahu od 0 do 9 nebo a-f.
Poznámka:
dotazovací jazyk Kusto má tabulkové i skalární operátory. Pokud ve zbytku tohoto článku jednoduše vidíte slovo "operátor", můžete předpokládat, že to znamená tabulkový operátor, pokud není uvedeno jinak.
Získání, omezení, řazení a filtrování dat
Základní slovník dotazovací jazyk Kusto – základ, který vám umožní provést naprostou většinu úkolů – je kolekce operátorů pro filtrování, řazení a výběr dat. Zbývající úkoly, které budete muset udělat, budou vyžadovat, abyste roztáhli znalosti jazyka tak, aby vyhovovaly vašim pokročilejším potřebám. Pojďme se trochu podívat na některé příkazy, které jsme použili v našem předchozím příkladu , a podívat se na take, sorta where.
Pro každý z těchto operátorů prozkoumáme jeho použití v našem předchozím příkladu SigninLogs a naučíme se užitečný tip nebo osvědčený postup.
Získání dat
První řádek každého základního dotazu určuje, se kterou tabulkou chcete pracovat. V případě Microsoft Sentinelu to bude pravděpodobně název typu protokolu ve vašem pracovním prostoru, například SigninLogs, SecurityAlert nebo CommonSecurityLog. Příklad:
SigninLogs
Všimněte si, že v dotazovací jazyk Kusto se v názvech protokolů rozlišují malá a signinLogs velká písmena, takže SigninLogs se budou interpretovat jinak. Při výběru názvů pro vlastní protokoly je potřeba dbát na to, aby byly snadno identifikovatelné a ne příliš podobné jinému protokolu.
Omezení dat: omezení /
Operátor take (a identický operátor limitu ) slouží k omezení výsledků vrácením pouze daného počtu řádků. Následuje celé číslo, které určuje počet řádků, které se mají vrátit. Obvykle se používá na konci dotazu po určení pořadí řazení a v takovém případě vrátí daný počet řádků v horní části seřazeného pořadí.
Použití take dříve v dotazu může být užitečné pro testování dotazu, pokud nechcete vracet velké datové sady. Pokud ale operaci umístíte take před jakékoli sort operace, take vrátí náhodně vybrané řádky – a případně jinou sadu řádků při každém spuštění dotazu. Tady je příklad použití:
SigninLogs
| take 5

Tip
Při práci na úplně novém dotazu, kde možná nevíte, jak bude dotaz vypadat, může být užitečné vložit take příkaz na začátku, aby se datová sada uměle omezila pro rychlejší zpracování a experimentování. Jakmile budete s úplným dotazem spokojeni, můžete počáteční take krok odebrat.
Řazení dat: pořadí řazení /
Operátor řazení (a identický operátor pořadí ) slouží k seřazení dat podle zadaného sloupce. V následujícím příkladu jsme výsledky seřadili podle TimeGenerated a nastavili směr pořadí sestupně s parametrem desc a umístili jsme nejvyšší hodnoty jako první. Pro vzestupné pořadí bychom použili asc.
Poznámka:
Výchozí směr řazení je sestupný, takže technicky vzato je nutné zadat pouze v případě, že chcete řadit vzestupně. Pokud ale zadáte směr řazení v jakémkoli případě, bude váš dotaz čitelnější.
SigninLogs
| sort by TimeGenerated desc
| take 5
Jak jsme zmínili, operátor jsme před operátor umístili sort take . Nejdřív musíme seřadit, abychom měli jistotu, že dostaneme odpovídající pět záznamů.

Vrchol
Horní operátor nám umožňuje zkombinovat sort operace take do jednoho operátoru:
SigninLogs
| top 5 by TimeGenerated desc
V případech, kdy dva nebo více záznamů mají stejnou hodnotu ve sloupci, podle kterého řadíte, můžete přidat další sloupce, podle kterých chcete řadit. Přidejte další sloupce řazení do seznamu odděleného čárkami, který se nachází za prvním sloupcem řazení, ale před klíčové slovo pořadí řazení. Příklad:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Pokud je timeGenerated stejný mezi více záznamy, pokusí seřadit podle hodnoty ve sloupci Identita .
Poznámka:
Kdy použít sort a takekdy použít top
Pokud řadíte pouze jedno pole, použijte
top, protože poskytuje lepší výkon než kombinacesortatake.Pokud potřebujete řadit podle více než jednoho pole (jako v předchozím příkladu výše),
topnemůžete to udělat, takže musíte použítsortatake.
Filtrování dat: kde
Operátor where je pravděpodobně nejdůležitějším operátorem, protože je klíčem k tomu, abyste měli jistotu, že pracujete jenom s podmnožinou dat, která jsou pro váš scénář relevantní. Měli byste co nejlépe filtrovat data co nejdříve v dotazu, protože tím se zlepší výkon dotazů snížením množství dat, která je potřeba zpracovat v následných krocích; zajišťuje také, že provádíte výpočty pouze s požadovanými daty. Podívejte se na tento příklad:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
Operátor where určuje proměnnou, operátor porovnání (skalární) a hodnotu. V našem případě jsme použili >= k označení, že hodnota ve sloupci TimeGenerated musí být větší než (tj. pozdější než) nebo rovna sedmi dnům.
V dotazovací jazyk Kusto existují dva typy relačních operátorů: řetězec a číselná. Následující tabulka obsahuje úplný seznam číselných operátorů:
Číselné operátory
| Operátor | Popis |
|---|---|
+ |
Dodatek |
- |
Odčítání |
* |
Násobení |
/ |
Oddělení |
% |
Zbytek po dělení |
< |
Je menší než |
> |
Je větší než |
== |
Rovno |
!= |
Nikoli rovno |
<= |
Menší než nebo rovno |
>= |
Větší než nebo rovno |
in |
Rovná se jednomu z prvků |
!in |
Nerovná se žádnému z prvků |
Seznam řetězcových operátorů je mnohem delší seznam, protože obsahuje permutace pro citlivost písmen, umístění podřetězců, předpony, přípony a mnoho dalšího. Operátor == je číselný i řetězcový operátor, což znamená, že ho lze použít pro čísla i text. Například oba následující příkazy by byly platné příkazy where:
| where ResultType == 0| where Category == 'SignInLogs'
Tip
Osvědčený postup: Ve většině případů budete pravděpodobně chtít data filtrovat podle více než jednoho sloupce nebo filtrovat stejný sloupec více než jedním způsobem. V těchtopřípadechch
Pomocí klíčového slova a klíčového slova můžete zkombinovat více where příkazů do jednoho kroku. Příklad:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Pokud máte více filtrů spojených s jedním příkazem pomocí klíčového where slova a klíčového slova, jako je výše, dosáhnete lepšího výkonu tak, že nejprve vložíte filtry, které odkazují jenom na jeden sloupec. Lepší způsob, jak napsat výše uvedený dotaz, by tedy byl:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
V tomto příkladu první filtr zmíní jeden sloupec (TimeGenerated), zatímco druhý odkazuje na dva sloupce (Resource a ResourceGroup).
Shrnutí dat
Sumarizace je jedním z nejdůležitějších tabulkových operátorů v dotazovací jazyk Kusto, ale je to také jeden z složitějších operátorů, které se naučíte, jestli v dotazovacích jazycích obecně začínáte. Úkolem summarize je vzít v tabulce dat a vytvořit výstup novou tabulku , která je agregovaná jedním nebo více sloupci.
Struktura příkazu summarize
Základní struktura summarize příkazu je následující:
| summarize <aggregation> by <column>
Například následující vrátí počet záznamů pro každou hodnotu CounterName v tabulce Perf :
Perf
| summarize count() by CounterName

Vzhledem k tomu, že výstupem summarize je nová tabulka, žádné sloupce, které nejsou explicitně zadané v summarize příkazu, nebudou předány kanálu. Pro ilustraci tohoto konceptu zvažte tento příklad:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
Na druhém řádku určujeme, že se staráme pouze o sloupce ObjectName, CounterValue a CounterName. Potom jsme shrnuli, abychom získali počet záznamů podle CounterName a nakonec se pokusíme data seřadit vzestupně podle sloupce ObjectName . Tento dotaz bohužel selže s chybou (značící, že název objektu je neznámý), protože při shrnutí jsme do nové tabulky zahrnuli pouze sloupce Count a CounterName. Abychom se této chybě vyhnuli, můžeme jednoduše přidat ObjectName na konec našeho summarize kroku, například takto:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Způsob čtení summarize řádku v hlavě by byl: "sumarizovat počet záznamů podle CounterName a seskupit podle ObjectName". Můžete pokračovat v přidávání sloupců oddělených čárkami na konec summarize příkazu.

Pokud chceme agregovat více sloupců najednou, můžeme toho dosáhnout přidáním agregací do operátoru summarize oddělených čárkami. V následujícím příkladu dostáváme nejen počet všech záznamů, ale také součet hodnot ve sloupci CounterValue ve všech záznamech (které odpovídají všem filtrům v dotazu):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc

Přejmenování agregovaných sloupců
Zdá se, že je vhodný čas mluvit o názvech sloupců pro tyto agregované sloupce. Na začátku této části jsme řekli, že summarize operátor vezme tabulku dat a vytvoří novou tabulku a pouze sloupce zadané v summarize příkazu budou pokračovat v kanálu. Pokud byste tedy chtěli spustit výše uvedený příklad, výsledné sloupce pro naši agregaci by se count_ a sum_CounterValue.
Modul Kusto automaticky vytvoří název sloupce bez toho, abychom museli být explicitní, ale často zjistíte, že nový sloupec bude mít přívětivější název. Sloupec v summarize příkazu můžete snadno přejmenovat zadáním nového názvu = a agregace, například takto:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Teď se naše souhrnné sloupce budou jmenovat Count (Počet ) a CounterSum (CounterSum).

Pro operátora je mnohem více summarize , než zde můžeme pokrýt, ale měli byste investovat čas, abyste se dozvěděli, protože se jedná o klíčovou součást pro jakoukoli analýzu dat, kterou plánujete provést s vašimi daty Microsoft Sentinelu.
Referenční informace k agregaci
Jedná se o mnoho agregačních funkcí, ale některé z nejčastěji používaných funkcí , sum()count()a avg(). Tady je částečný seznam (podívejte se na úplný seznam):
Agregační funkce
| Function | Popis |
|---|---|
arg_max() |
Vrátí jeden nebo více výrazů, pokud je argument maximalizován. |
arg_min() |
Vrátí jeden nebo více výrazů při minimalizaci argumentu. |
avg() |
Vrátí průměrnou hodnotu ve skupině. |
buildschema() |
Vrátí minimální schéma, které přijímá všechny hodnoty dynamického vstupu. |
count() |
Vrátí počet skupin. |
countif() |
Vrátí počet s predikátem skupiny. |
dcount() |
Vrátí přibližný počet jedinečných prvků skupiny. |
make_bag() |
Vrátí tašku vlastností dynamických hodnot ve skupině. |
make_list() |
Vrátí seznam všech hodnot ve skupině. |
make_set() |
Vrátí sadu jedinečných hodnot v rámci skupiny. |
max() |
Vrátí maximální hodnotu ve skupině. |
min() |
Vrátí minimální hodnotu ve skupině. |
percentiles() |
Vrátí percentil přibližnou hodnotu skupiny. |
stdev() |
Vrátí směrodatnou odchylku ve skupině. |
sum() |
Vrátí součet prvků ve skupině. |
take_any() |
Vrátí náhodnou neprázdnou hodnotu pro skupinu. |
variance() |
Vrátí odchylku napříč skupinou. |
Výběr: přidávání a odebírání sloupců
Když začnete pracovat s dotazy více, můžete zjistit, že máte více informací, než potřebujete na předmětech (to znamená příliš mnoho sloupců v tabulce). Nebo možná budete potřebovat víc informací, než máte (to znamená, že musíte přidat nový sloupec, který bude obsahovat výsledky analýzy jiných sloupců). Pojďme se podívat na několik klíčových operátorů pro manipulaci se sloupci.
Project and project-away
Project je zhruba ekvivalentní příkazům select v mnoha jazycích. Umožňuje zvolit, které sloupce chcete zachovat. Pořadí vrácených sloupců bude odpovídat pořadí sloupců, které v project příkazu vypíšete, jak je znázorněno v tomto příkladu:
Perf
| project ObjectName, CounterValue, CounterName

Jak si můžete představit, když pracujete s velmi širokými datovými sadami, můžete mít velké množství sloupců, které chcete zachovat, a jejich zadání podle názvu by vyžadovalo hodně psaní. V těchto případech máte projekt pryč, což vám umožní určit, které sloupce se mají odebrat, a nikoli sloupce, které se mají zachovat, například takto:
Perf
| project-away MG, _ResourceId, Type
Tip
Může být užitečné použít project ve dvou umístěních v dotazech, na začátku a znovu na konci. Použití project v rané fázi dotazu může přispět ke zlepšení výkonu tím, že odstraníte velké bloky dat, která nemusíte kanál předávat. Když ho použijete znovu na konci, můžete se zbavit všech sloupců, které mohly být vytvořeny v předchozích krocích, a nejsou potřeba v konečném výstupu.
Prodloužit
Rozšíření slouží k vytvoření nového počítaného sloupce. To může být užitečné, když chcete provést výpočet s existujícími sloupci a zobrazit výstup pro každý řádek. Pojďme se podívat na jednoduchý příklad, ve kterém vypočítáme nový sloupec s názvem Kbajtů, který můžeme vypočítat vynásobením hodnoty MB (ve stávajícím sloupci Množství ) o 1 024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Na posledním řádku našeho project příkazu jsme přejmenovali sloupec Quantity na Mbytes, abychom mohli snadno zjistit, která měrná jednotka je relevantní pro každý sloupec.

Stojí za zmínku, že extend funguje i s již počítanými sloupci. Můžeme například přidat další sloupec s názvem Bajty vypočítaný z Kbajtů:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes

Spojování tabulek
Většinu práce v Microsoft Sentinelu je možné provádět pomocí jednoho typu protokolu, ale existují chvíle, kdy budete chtít data vzájemně korelovat nebo vyhledávat s jinou sadou dat. Stejně jako většina dotazovacích jazyků nabízí dotazovací jazyk Kusto několik operátorů, které slouží k provádění různých typů spojení. V této části se podíváme na nejčastěji používané operátory union a join.
Svaz
Sjednocení jednoduše vezme dvě nebo více tabulek a vrátí všechny řádky. Příklad:
OfficeActivity
| union SecurityEvent
Tím by se vrátily všechny řádky z tabulek OfficeActivity i SecurityEvent . Union nabízí několik parametrů, které lze použít k úpravě chování sjednocení. Dvě z nejužitečnějších jsou se zdroji a druhem:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Parametr withsource umožňuje zadat název nového sloupce, jehož hodnota v daném řádku bude název tabulky, ze které řádek přišel. V předchozím příkladu jsme pojmenovali sloupec SourceTable a v závislosti na řádku bude hodnota OfficeActivity nebo SecurityEvent.
Druhý parametr, který jsme zadali, byl druh, který má dvě možnosti: vnitřní nebo vnější. V předchozím příkladu jsme zadali vnitřní, což znamená, že jedinými sloupci, které budou zachovány během sjednocení, jsou sloupce, které existují v obou tabulkách. Případně pokud bychom zadali vnější (což je výchozí hodnota), vrátí se všechny sloupce z obou tabulek.
Join (Spojení)
Spojení funguje podobně unionjako , s výjimkou toho, že místo spojování tabulek vytvoříme novou tabulku, spojíme řádky a vytvoříme novou tabulku. Stejně jako většina databázových jazyků existuje několik typů spojení, které můžete provést. Obecná syntaxe pro:join
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
join Za operátorem určíme typ spojení, za nímž chceme provést otevřenou závorku. V závorkách zadáte tabulku, kterou chcete spojit, a také všechny další příkazy dotazu v této tabulce, které chcete přidat. Za pravou závorku použijeme klíčové slovo on , za kterým následuje naše levá ($left.<klíčové slovo columnName> ) a vpravo ($right.<columnName>) sloupce oddělené operátorem == Tady je příklad vnitřního spojení:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Poznámka:
Pokud obě tabulky mají stejný název sloupců, na kterých provádíte spojení, nemusíte místo toho používat $left a $right; stačí zadat název sloupce. Použití $left a $right je však explicitnější a obecně se považuje za osvědčený postup.
Následující tabulka obsahuje seznam dostupných typů spojení.
Typy spojení
| Typ spojení | Popis |
|---|---|
inner |
Vrátí jednu pro každou kombinaci odpovídajících řádků z obou tabulek. |
innerunique |
Vrátí řádky z levé tabulky s jedinečnými hodnotami v propojeném poli, které mají shodu v pravé tabulce. Toto je výchozí nespecifikovaný typ spojení. |
leftsemi |
Vrátí všechny záznamy z levé tabulky, které mají shodu v pravé tabulce. Vrátí se pouze sloupce z levé tabulky. |
rightsemi |
Vrátí všechny záznamy z pravé tabulky, které mají shodu v levé tabulce. Vrátí se pouze sloupce z pravé tabulky. |
leftanti/leftantisemi |
Vrátí všechny záznamy z levé tabulky, které nemají shodu v pravé tabulce. Vrátí se pouze sloupce z levé tabulky. |
rightanti/rightantisemi |
Vrátí všechny záznamy z pravé tabulky, které nemají shodu v levé tabulce. Vrátí se pouze sloupce z pravé tabulky. |
leftouter |
Vrátí všechny záznamy z levé tabulky. U záznamů, které nemají žádnou shodu v pravé tabulce, budou hodnoty buněk null. |
rightouter |
Vrátí všechny záznamy z správné tabulky. U záznamů, které nemají v levé tabulce žádnou shodu, budou hodnoty buněk null. |
fullouter |
Vrátí všechny záznamy z levé i pravé tabulky, které odpovídají nebo ne. Chybějící hodnoty budou mít hodnotu null. |
Tip
Osvědčeným postupem je mít na levé straně nejmenší tabulku. V některýchpřípadechch
Evaluate
Možná si pamatujete, že v prvním příkladu jsme viděli operátor vyhodnocení na jednom z řádků. Operátor evaluate je méně často používaný než ten, na který jsme se dříve dotkli. Znalost toho, jak evaluate operátor funguje, ale stojí za váš čas. Ještě jednou tady je první dotaz, kde se zobrazí evaluate na druhém řádku.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Tento operátor umožňuje vyvolat dostupné moduly plug-in (v podstatě integrované funkce). Mnoho z těchto modulů plug-in se zaměřuje na datové vědy, jako jsou automatickéclustery, diffpatterny a sequence_detect, které umožňují provádět pokročilou analýzu a objevovat statistické anomálie a odlehlé hodnoty.
Modul plug-in použitý ve výše uvedeném příkladu se nazývá bag_unpack a velmi snadno vezme blok dynamických dat a převede je na sloupce. Nezapomeňte, že dynamická data jsou datový typ, který vypadá velmi podobně jako JSON, jak je znázorněno v tomto příkladu:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
V tomto případě jsme chtěli sumarizovat data podle města, ale město je obsaženo jako vlastnost ve sloupci LocationDetails . Abychom mohli v dotazu použít vlastnost města , museli jsme ji nejprve převést na sloupec pomocí bag_unpack.
Když se vrátíme k původním krokům kanálu, viděli jsme toto:
Get Data | Filter | Summarize | Sort | Select
Teď, když jsme operátor zvážili evaluate , vidíme, že představuje novou fázi kanálu, která teď vypadá takto:
Get Data | Parse | Filter | Summarize | Sort | Select
Existuje mnoho dalších příkladů operátorů a funkcí, které lze použít k analýze zdrojů dat do čitelnějšího a čitelnějšího formátu. Další informace o nich a zbytek dotazovací jazyk Kusto najdete v úplné dokumentaci a v sešitu.
Příkazy Let
Teď, když jsme probrali mnoho hlavních operátorů a datových typů, zabalíme si příkaz let, což je skvělý způsob, jak usnadnit čtení, úpravy a údržbu dotazů.
Umožňuje vytvořit a nastavit proměnnou nebo přiřadit název výrazu. Tento výraz může být jedna hodnota, ale může to být také celý dotaz. Tady je jednoduchý příklad:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Tady jsme zadali název aWeekAgo a nastavili ho tak, aby se rovnal výstupu funkce časového rozpětí , která vrací hodnotu datetime . Příkaz let pak ukončíme středníkem. Teď máme novou proměnnou s názvem aWeekAgo , kterou můžete použít kdekoli v našem dotazu.
Jak jsme už zmínili, můžete použít příkaz let k pořízení celého dotazu a zadání výsledku názvu. Vzhledem k tomu, že výsledky dotazu, které jsou tabulkové výrazy, se dají použít jako vstupy dotazů, můžete s tímto pojmenovaným výsledkem zacházet jako s tabulkou za účelem spuštění jiného dotazu. Tady je drobná úprava předchozího příkladu:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
V tomto případě jsme vytvořili druhý příkaz let , kde jsme celý dotaz zabalili do nové proměnné s názvem getSignins. Stejně jako předtím ukončíme druhý letový příkaz středníkem. Potom zavoláme proměnnou na posledním řádku, který spustí dotaz. Všimněte si, že jsme v druhém příkazu let mohli použít aWeekAgo. Je to proto, že jsme ho zadali na předchozím řádku; Pokud bychom prohodili příkazy let tak, aby getSignins přišly jako první, zobrazila by se chyba.
Teď můžeme použít getSignins jako základ jiného dotazu (ve stejném okně):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Díky příkazům získáte větší sílu a flexibilitu při uspořádání dotazů. Umožňuje definovat skalární a tabulkové hodnoty a také vytvářet uživatelem definované funkce. Jsou skutečně užitečné, když organizujete složitější dotazy, které můžou provádět více spojení.
Další kroky
I když tento článek sotva poškrábal povrch, máte teď potřebný základ a probrali jsme části, které budete používat nejčastěji k práci v Microsoft Sentinelu.
Rozšířený sešit KQL pro Microsoft Sentinel
Využijte výhod sešitu dotazovací jazyk Kusto přímo ve službě Microsoft Sentinel – rozšířeného KQL pro sešit Microsoft Sentinelu. Poskytuje podrobnou nápovědu a příklady pro řadu situací, se kterými se pravděpodobně setkáte během každodenních operací zabezpečení, a také vás upozorňuje na spoustu předdefinovaných příkladů analytických pravidel, sešitů, pravidel proaktivního vyhledávání a dalších prvků, které používají dotazy Kusto. Spusťte tento sešit z okna Sešity v Microsoft Sentinelu.
Pokročilý sešit KQL Framework - Umožňuje vám stát se KQL-savvy je vynikající blogový příspěvek, který ukazuje, jak používat tento sešit.
Další materiály
Podívejte se na tuto kolekci výukových, školicích a kvalifikovaných zdrojů pro rozšíření a prohlubování znalostí dotazovací jazyk Kusto.