Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Stream Analytics podporuje dělení výstupu objektu blob podle vlastních pravidel s vlastními poli nebo atributy a uživatelskými vzory cest DateTime.
Vlastní pole nebo atributy
Vlastní atributy pole nebo vstupu zlepšují následné pracovní postupy zpracování a generování sestav tím, že umožňují větší kontrolu nad výstupem.
Možnosti klíče oddílu
Klíč oddílu nebo název sloupce, který se používá k dělení vstupních dat, může obsahovat libovolný znak, který je pro blob názvy akceptován. Vnořená pole není možné použít jako klíč oddílu, pokud se nepoužívají společně s aliasy. K vytvoření hierarchie souborů však můžete použít určité znaky. Pokud například chcete vytvořit sloupec, který kombinuje data ze dvou dalších sloupců, abyste vytvořili jedinečný klíč oddílu, můžete použít následující dotaz:
SELECT name, id, CONCAT(name, "/", id) AS nameid
Klíč oddílu musí být NVARCHAR(MAX), BIGINT, FLOATnebo BIT (1.2 úroveň kompatibility nebo vyšší). Typy DateTime, Array a Records nejsou podporovány, ale dají se použít jako klíče oddílu, pokud jsou převedeny na řetězce. Další informace najdete v tématu Datové typy Azure Stream Analytics.
Příklad
Předpokládejme, že úloha přebírá vstupní data z živých uživatelských relací připojených k externí službě videohry, kde ingestované data obsahují sloupec client_id pro identifikaci relací. Pokud chcete data rozdělit podle client_id, nastavte pole vzoru cesty objektu blob tak, aby při vytváření úlohy zahrnovalo partiční token {client_id} ve výstupních vlastnostech objektu blob. Data s různými client_id hodnotami, která procházejí úlohou Stream Analytics, se ukládají do samostatných složek na základě jedinečné client_id hodnoty pro každou složku.

Podobně, pokud by vstupem úlohy byla data ze senzorů milionů snímačů, kde každý senzor měl sensor_id, vzor cesty by byl {sensor_id} pro rozdělení dat z každého snímače do různých složek.
Když použijete rozhraní REST API, může výstupní část souboru JSON použitého pro tento požadavek vypadat jako na následujícím obrázku:

Po spuštění clients úlohy může kontejner vypadat jako na následujícím obrázku:
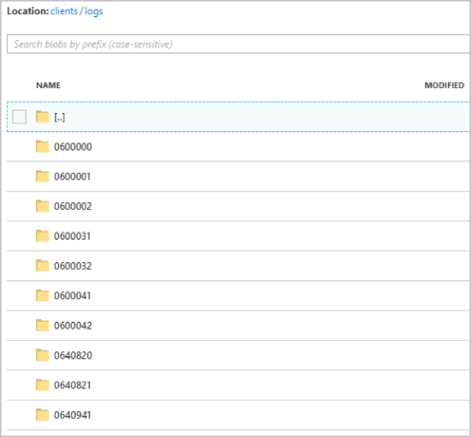
Každá složka může obsahovat více objektů blob, kde každý objekt blob obsahuje jeden nebo více záznamů. V předchozím příkladu je ve složce "06000000" označený jeden objekt blob s následujícím obsahem:
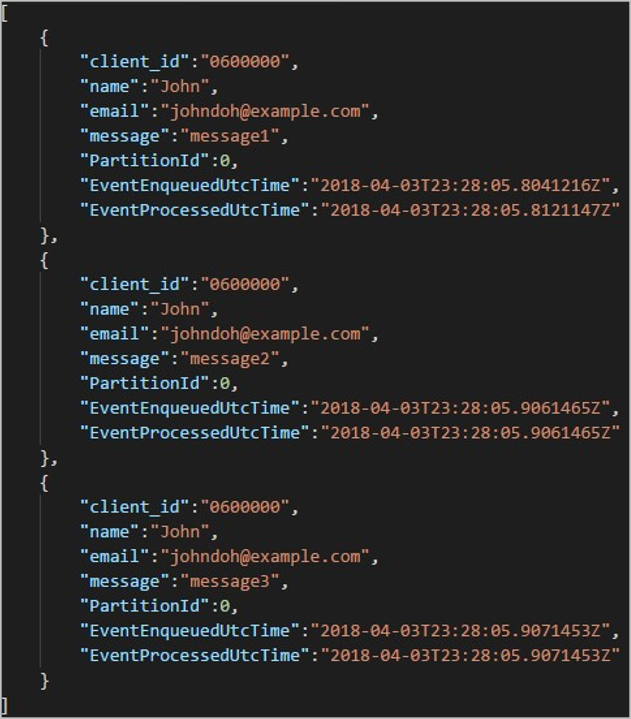
Všimněte si, že každý záznam v objektu blob má client_id sloupec odpovídající názvu složky, protože sloupec použitý k rozdělení výstupu do výstupní cesty byl client_id.
Omezení
Ve výstupní vlastnosti objektu blob vzoru cesty je povolen pouze jeden vlastní klíč oddílu. Všechny následující vzory cest jsou platné:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Pokud zákazníci chtějí použít více než jedno vstupní pole, můžou vytvořit složený klíč v dotazu pro vlastní oddíl cesty ve výstupu objektu blob pomocí
CONCAT. Příklad:select concat (col1, col2) as compositeColumn into blobOutput from input. Pak můžou jako vlastní cestu zadatcompositeColumnve službě Azure Blob Storage.Klíče oddílů nerozlišují psaní malými a velkými písmeny, takže klíče oddílů jako
Johnajohnjsou ekvivalentní. Výrazy se také nedají použít jako klíče oddílu. Například{columnA + columnB}nefunguje.Pokud se vstupní datový proud skládá ze záznamů s kardinalitou klíče rozdělení pod 8 000, záznamy se připojí k existujícím blobům. V případě potřeby vytvoří pouze nové blob. Pokud je kardinalita vyšší než 8 000, neexistuje žádná záruka, že se existující blob zapisují. Nové objekty blob se nebudou vytvářet pro libovolný počet záznamů se stejným klíčem oddílu.
Pokud je výstup objektu blob nakonfigurovaný jako neměnný, Stream Analytics při každém odeslání dat vytvoří nový objekt blob.
Vlastní vzory cesty DateTime
Vlastní DateTime vzory cest umožňují zadat výstupní formát, který je v souladu s konvencemi streamování Hive, což Stream Analytics umožňuje odesílání dat do Azure HDInsight a Azure Databricks pro následné zpracování. Vlastní DateTime vzory cest se snadno implementují pomocí klíčového slova datetime v poli Předpona cesty výstupu typu blob spolu se specifikátorem formátu. Příklad: {datetime:yyyy}.
Podporované tokeny
Následující specifikační tokeny formátu lze použít samostatně nebo v kombinaci k dosažení vlastních DateTime formátů.
| Specifikátor formátu | Popis | Výsledky v příkladovém čase 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Rok jako čtyřmístné číslo | 2018 |
| {datetime:MM} | Měsíc od 01 do 12 | 01 |
| {datetime:M} | Měsíc od 1 do 12 | 1 |
| {datetime:dd} | Den od 01 do 31 | 02 |
| {datetime:d} | Den od 1 do 31 | 2 |
| {datetime:HH} | Hodina ve 24hodinovém formátu, od 00 do 23 | 10 |
| {datetime:mm} | Minuty od 00 do 60 | 06 |
| {datetime:m} | Minuty od 0 do 60 | 6 |
| {datetime:ss} | Sekundy od 00 do 60 | 08 |
Pokud nechcete používat vlastní DateTime vzory, můžete přidat {date} a/nebo {time} token do pole Předpona cesty a vygenerovat rozevírací seznam s předdefinovanými DateTime formáty.

Rozšiřitelnost a omezení
Ve vzoru cesty můžete použít libovolný počet tokenů ({datetime:<specifier>}), dokud nedosáhnete limitu znaků předpony cesty. Specifikátory formátu se nedají kombinovat v rámci jednoho tokenu nad rámec kombinací, které už jsou uvedené v rozevíracích náznacích data a času.
Pro rozdělení cesty logs/MM/dd:
| Platný výraz | Neplatný výraz |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
V předponě cesty můžete stejný specifikátor formátu použít vícekrát. Token se musí opakovat pokaždé.
Konvence streamování Hive
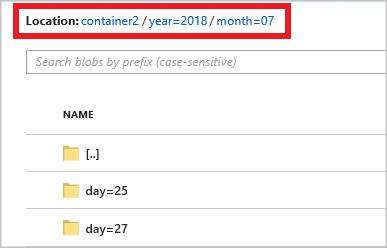
Vlastní vzory cest pro Blob Storage je možné použít s konvencí streamování Hive, která očekává, že složky budou označeny column= v názvu složky.
Příklad: year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Vlastní výstup eliminuje nesnáze se změnami tabulek a ručním přidáváním oddílů pro přenos dat mezi Stream Analytics a Hive. Místo toho je možné automaticky přidat mnoho složek pomocí:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Příklad
Vytvořte účet úložiště, skupinu prostředků, úlohu Stream Analytics a vstupní zdroj podle rychlého startu v Azure portálu Stream Analytics. Použijte stejná ukázková data použitá v rychlém startu. Ukázková data jsou k dispozici také na GitHubu.
Vytvořte výstupní jímku objektu blob s následující konfigurací:

Vzor úplné cesty je:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Při spuštění úlohy se v kontejneru objektů blob vytvoří struktura složek založená na vzoru cesty. Můžete přejít k podrobnostem na úrovni dne.