Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí pro: Dedikované SQL fondy v Azure Synapse Analytics
Když se uživatelé dotazují na tabulku columnstore ve vyhrazeném fondu SQL, optimalizátor zkontroluje minimální a maximální hodnoty uložené v jednotlivých segmentech. Segmenty, které jsou mimo hranice predikátu dotazu, se nečtou z disku do paměti. Dotaz se může dokončit rychleji, pokud je počet segmentů ke čtení a jejich celková velikost malá.
Poznámka:
Tento článek se týká vyhrazených fondů SQL služby Azure Synapse Analytics. Informace o seřazených indexech columnstore na SQL Serveru a dalších platformách SQL najdete v tématu Ladění výkonu s seřazenými clusterovanými indexy columnstore.
Seřazený vs. neseřazený clusterovaný sloupcový index
Ve výchozím nastavení pro každou tabulku vytvořenou bez možnosti indexu vytvoří interní komponenta (tvůrce indexů) neřazený clusterovaný index columnstore (CCI). Data v každém sloupci se komprimují do samostatného segmentu skupiny řádků CCI. V rozsahu hodnot jednotlivých segmentů jsou metadata, takže segmenty, které jsou mimo hranice predikátu dotazu, se během provádění dotazu nečtou z disku. CCI nabízí nejvyšší úroveň komprese dat a snižuje velikost segmentů pro čtení, aby dotazy mohly běžet rychleji. Vzhledem k tomu, že tvůrce indexů neřadí data před jejich komprimací do segmentů, může dojít k segmentům s překrývajícími se rozsahy hodnot, což způsobí, že dotazy budou číst další segmenty z disku a jejich dokončení trvá déle.
Uspořádané sloupcové indexy s clusterováním umožňují efektivní eliminaci segmentů, což vede k mnohem rychlejšímu výkonu tím, že přeskočí velké objemy seřazených dat, která neodpovídají predikátu dotazu. Při vytváření uspořádané CCI seřadí vyhrazený modul fondu SQL existující data v paměti podle klíčů pořadí před tím, než je tvůrce indexů zkomprimuje do segmentů indexu. Díky seřazeným datům se zmenší překrývání segmentů, což umožňuje dotazům dosáhnout efektivnějšího odstranění segmentů a tím rychlejšího výkonu, protože počet segmentů pro čtení z disku je menší. Pokud lze řadit všechna data v paměti najednou, můžete se vyhnout překrývání segmentů. Vzhledem k velkým tabulkám v datových skladech se tento scénář často neprovádí.
Pokud chcete zkontrolovat rozsahy segmentů pro sloupec, spusťte následující příkaz s názvem tabulky a názvem sloupce:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Poznámka:
V seřazené tabulce CCI se nová data vyplývající ze stejné dávky DML nebo operací načítání dat se seřadí v rámci této dávky, takže neexistuje globální řazení napříč všemi daty v tabulce. Uživatelé mohou znovu sestavit CCI v pořadí, aby seřadili všechna data v tabulce. Ve vyhrazeném fondu SQL je operace REBUILD indexu columnstore offline. U dělené tabulky se proces REBUILD provádí postupně, jeden oddíl za druhým. Data v znovu sestaveném oddílu jsou offline a nedostupná, dokud se pro tento oddíl nedokončí opětovné sestavení.
Výkonnost dotazů
Výkon dotazu z seřazeného CCI závisí na vzorech dotazu, velikosti dat, způsobu řazení dat, fyzické struktuře segmentů a třídě DWU a třídy prostředků zvolené pro provádění dotazu. Uživatelé by měli před výběrem sloupců řazení při návrhu uspořádané tabulky CCI zkontrolovat všechny tyto faktory.
Dotazy se všemi těmito vzory obvykle běží rychleji na základě uspořádaného CCI.
- Dotazy mají predikáty rovnosti, nerovnosti nebo rozsahu.
- Sloupce predikátu a seřazené sloupce CCI jsou stejné.
V tomto příkladu má tabulka T1 clusterovaný index columnstore seřazený v posloupnosti Col_C, Col_B a Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Výkon dotazu 1 a dotazu 2 může těžit z seřazených CCI než u ostatních dotazů, protože odkazují na všechny seřazené sloupce CCI.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Výkon načítání dat
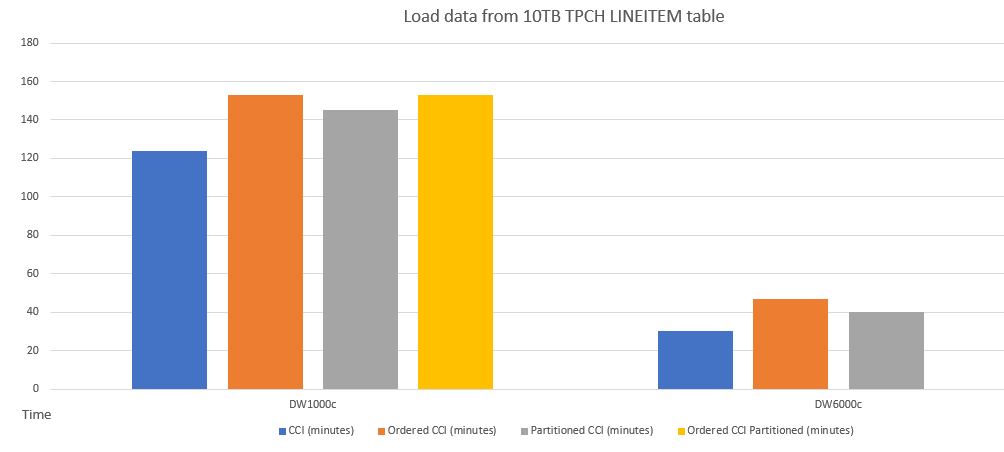
Výkon načítání dat do seřazené tabulky CCI se podobá dělené tabulce. Načtení dat do seřazené tabulky CCI může trvat déle než do neseřazené tabulky CCI kvůli operaci řazení dat, dotazy však mohou následně běžet rychleji se seřazenými CCI.
Tady je příklad porovnání výkonu načítání dat do tabulek s různými schématy.
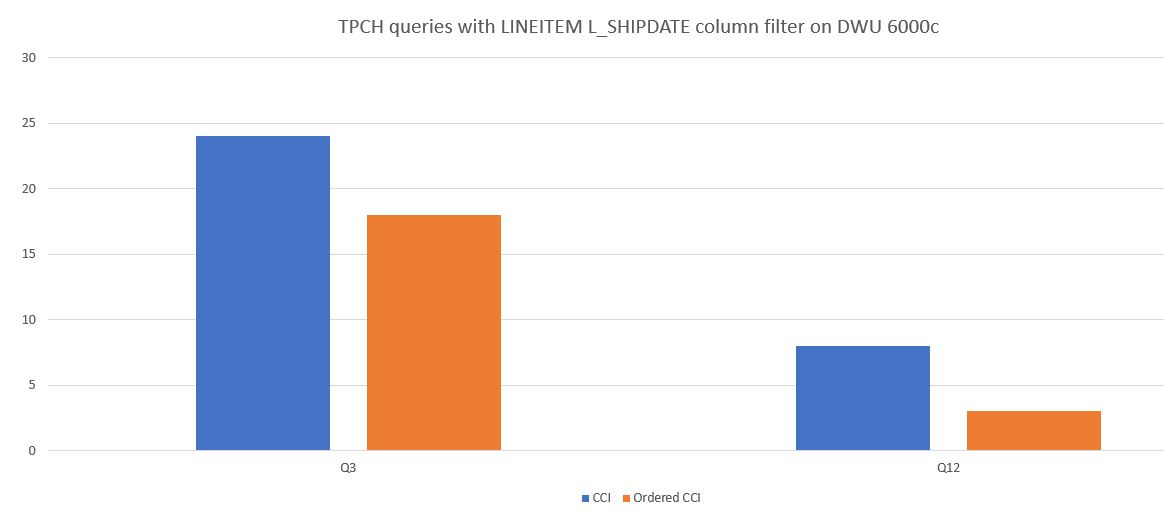
Zde je příklad srovnání výkonu dotazů mezi CCI a seřazeným CCI.
Snižte překrývání segmentů
Počet překrývajících se segmentů závisí na velikosti dat, která se mají seřadit, dostupné paměti a maximálním stupni paralelismu (MAXDOP) během seřazeného vytváření CCI. Následující strategie snižují překrývající se segmenty při vytváření uspořádaných CCI.
Použijte třídu prostředků
xlargercna vyšší DWU, aby bylo k dispozici více paměti pro řazení dat předtím, než tvůrce indexu zkomprimuje data do segmentů. Jakmile je v indexovém segmentu, fyzické umístění dat nelze změnit. V rámci segmentu nebo napříč segmenty neexistuje žádné řazení dat.Vytvořit seřazené CCI s
OPTION (MAXDOP = 1). Každé vlákno použité pro seřazené vytváření CCI funguje na podmnožině dat a místně je seřadí. Neexistuje globální řazení mezi daty seřazenými podle různých vláken. Použití paralelních vláken může zkrátit dobu potřebnou ke vytvoření seřazeného CCI, ale vygeneruje více překrývajících se segmentů než použití jednoho vlákna. Použití jedné operace s vlákny poskytuje nejvyšší kvalitu komprese. Příklad:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Poznámka:
V současné době se ve vyhrazených fondech SQL ve službě Azure Synapse Analytics podporuje možnost MAXDOP pouze při vytváření seřazené tabulky CCI pomocí CREATE TABLE AS SELECT příkazu. Vytvoření uspořádané CCI pomocí příkazů CREATE INDEX nebo CREATE TABLE nepodporuje možnost MAXDOP. Toto omezení neplatí pro SQL Server 2022 a novější verze, kde můžete zadat MAXDOP pomocí CREATE INDEX příkazů nebo CREATE TABLE příkazů.
- Před načtením dat do tabulek je předem seřaďte podle klíčů řazení.
Tady je příklad seřazené distribuce tabulky CCI, která má nulový segment překrývající se podle výše uvedených doporučení. Seřazená tabulka CCI se vytvoří v databázi DWU1000c prostřednictvím CTAS z hromadné tabulky o velikosti 20 GB pomocí MAXDOP 1 a xlargerc. CCI je řazen podle sloupce BIGINT bez duplicit.
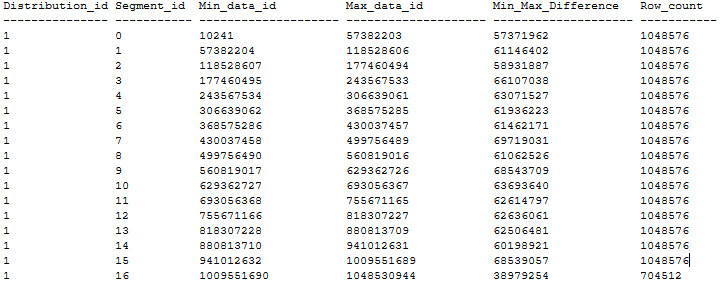
Vytvořte seřazené CCI ve velkých tabulkách
Vytvoření seřazeného CCI je offline operace. U tabulek bez oddílů nebudou data přístupná uživatelům, dokud se nedokončí uspořádaný proces vytváření CCI. V případě dělených tabulek, protože databázový stroj vytváří uspořádaný CCI oddíl po oddílu, mají uživatelé stále přístup k datům v oddílech, kde se nevytváří seřazený CCI. Tuto možnost můžete použít k minimalizaci výpadků během plánovaného vytváření CCI u velkých tabulí.
- Vytvořte partice v cílové velké tabulce, nazývané
Table_A. - Vytvořte prázdnou uspořádanou tabulku CCI (volanou
Table_B) se stejnou tabulkou a schématem oddílů jakoTable_A. - Přepněte jeden oddíl z
Table_AdoTable_B. - Spusťte
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>pro opětovné sestavení přepnutého oddílu naTable_B. - Opakujte krok 3 a 4 pro každý oddíl v souboru
Table_A. - Jakmile jsou všechny oddíly přepnuty z
Table_AnaTable_Ba byly znovu sestaveny, odstraňteTable_Aa přejmenujteTable_BnaTable_A.
Tip
Pro vyhrazenou tabulku fondu SQL s seřazeným CCI, ALTER INDEX REBUILD znovu seřadí data pomocí tempdb. Monitorujte tempdb během operací opětovného sestavení Pokud potřebujete více tempdb místa, zvětšete kapacitu fondu. Po dokončení opětovného sestavení indexu opět snížit velikost.
Pro vyhrazenou tabulku fondu SQL s seřazeným CCI, ALTER INDEX REORGANIZE nepřeřazuje data. Pokud chcete data uspořádat, použijte ALTER INDEX REBUILD.
Další informace o plánované údržbě CCI naleznete v tématu Optimalizace clusterovaných columnstore indexů.
Rozdíly mezi funkcemi SQL Serveru 2022
SQL Server 2022 (16.x) zavedl uspořádané clusterované indexy sloupcového úložiště podobné funkci v dedikovaných SQL poolech Azure Synapse.
- Aktuálně podporují clusterované funkce columnstore s vylepšeným odstraňováním segmentů pro řetězcové, binární a guid datové typy a datový typ datetimeoffset pro škálování větší než dvě pouze SQL Server 2022 (16.x) a novější verze. Dříve se odstranění tohoto segmentu vztahuje na číselné datové typy, datum a čas a datový typ datetimeoffset s měřítkem menší nebo rovnou dvěma.
- V současné době pouze SQL Server 2022 (16.x) a novější verze podporují odstranění skupin řádků clusterovaného columnstore pro předponu
LIKEpredikátů, napříkladcolumn LIKE 'string%'. Vyloučení segmentů není podporováno pro nepředponové použití LIKE, napříkladcolumn LIKE '%string'.
Další informace najdete v tématu Co je nového v indexech Columnstore.
Příklady
A. Chcete-li zkontrolovat sloupce ve správném pořadí a čísla v pořadí:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Pokud chcete změnit pořadí sloupců, přidejte nebo odeberte sloupce ze seznamu pořadí nebo změňte CCI na „seřazené CCI“.
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Další kroky
- Další tipy pro vývoj najdete v přehledu vývoje.
- Indexy columnstore – přehled
- Novinky v indexech columnstore
- Indexy columnstore – pokyny k návrhu
- Indexy columnstore – výkonnost dotazů