Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Platí na:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytický platformový systém (PDW)
Analytický platformový systém (PDW)![]() SQL databáze v Microsoft Fabric
SQL databáze v Microsoft Fabric
Indexy columnstore jsou standardem pro ukládání a dotazování velkých tabulek faktů datového skladu. Tento index používá úložiště dat založené na sloupcích a zpracování dotazů k dosažení až 10krát vyššího výkonu dotazů v datovém skladu oproti tradičnímu úložišti orientovanému na řádky. Můžete také dosáhnout až 10násobného zmenšení velikosti dat ve srovnání s jejich nekomprimovanou velikostí. Počínaje SQL Serverem 2016 (13.x) SP1 umožňují indexy columnstore operační analýzu: možnost provádět výkonné analýzy v reálném čase pro transakční zátěže.
Další informace o souvisejícím scénáři:
- Sloupcové indexy v datových skladech
- Začínáme s technologií columnstore pro provozní analýzy v reálném čase
Co je index columnstore?
Index columnstore je technologie pro ukládání, načítání a správu dat pomocí sloupcového formátu dat označovaného jako columnstore.
Klíčové pojmy a koncepty
Následující klíčové termíny a koncepty jsou přidružené k indexům columnstore.
Columnstore
Columnstore je data, která jsou logicky uspořádaná jako tabulka s řádky a sloupci a fyzicky uložená ve sloupcovém formátu dat.
Rowstore
Úložiště řádků jsou data, která jsou logicky uspořádána jako tabulka s řádky a sloupci a fyzicky uložena ve formátu řádkových dat. Tento formát představuje tradiční způsob ukládání dat relační tabulky. V SQL Serveru odkazuje úložiště řádků na tabulku, ve které je podkladovým formátem úložiště dat halda, clusterovaný index nebo tabulka optimalizovaná pro paměť.
Note
V diskuzích o indexech columnstore se termíny rowstore a columnstore používají ke zvýraznění formátu úložiště dat.
Rowgroup
Skupina řádků je skupina řádků, které jsou současně komprimovány do formátu columnstore. Skupina řádků obvykle obsahuje maximální počet řádků na skupinu řádků, což je 1 048 576 řádků.
V případě vysokého výkonu a vysoké míry komprese index columnstore rozdělí tabulku do skupin řádků a poté zkomprimuje každou skupinu řádků podle sloupce. Počet řádků ve skupině řádků musí být dostatečně velký, aby zlepšil míry komprese, a zároveň dostatečně malý, aby těžil z operací v paměti.
Skupina řádků, ze které se odstranila všechna data, přechází ze stavu COMPRESSED do stavu TOMBSTONE a později je odstraněna procesem na pozadí nazývaným tuple-mover. Další informace o stavech skupiny řádků najdete v tématu sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tip
Příliš mnoho malých skupin řádků snižuje kvalitu indexu columnstore. Až do SQL Serveru 2017 (14.x) se vyžaduje operace reorganizace pro sloučení menších komprimovaných skupin řádků, a to podle zásad interní prahové hodnoty, která určuje, jak odebrat odstraněné řádky a zkombinovat komprimované skupiny řádků.
Počínaje SQL Serverem 2019 (15.x) funguje úloha sloučení na pozadí také ke sloučení komprimovaných skupin řádků, ze kterých byl odstraněn velký počet řádků.
Po sloučení menších skupin řádků by se měla zlepšit kvalita indexu.
Note
Počínaje SQL Serverem 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance a vyhrazenými SQL fondy v Azure Synapse Analytics je přesun tuplů podpořen úlohou automatického sloučení na pozadí, která komprimuje menší delta řádkové skupiny typu OPEN, jež existovaly po určitou dobu podle interní prahové hodnoty, nebo slučuje komprimované řádkové skupiny, odkud byl smazán velký počet řádků. To v průběhu času zlepšuje kvalitu indexu columnstore.
Segment sloupce
Segment sloupce je sloupec dat v rámci skupiny řádků.
- Každá skupina řádků obsahuje jeden segment sloupce pro každý sloupec v tabulce.
- Každý segment sloupce se komprimuje a ukládá na fyzické médium.
- U každého segmentu existují metadata, která umožňují rychlé odstranění segmentů bez jejich čtení.
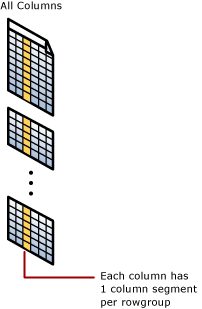
Clusterovaný sloupcový index
Fyzické úložiště pro celou tabulku poskytuje clusterovaný sloupcový index.
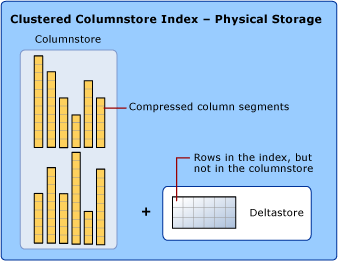
Kvůli snížení fragmentace segmentů sloupců a zvýšení výkonu může index columnstore dočasně ukládat některá data do clusterovaného indexu označovaného jako deltastore a seznam ID stromu B pro odstraněné řádky. Operace deltastore se zpracovávají na pozadí. Pokud chcete vrátit správné výsledky dotazu, clusterovaný index columnstore kombinuje výsledky dotazu z columnstore i deltastore.
Note
Dokumentace používá termín B-tree obecně v odkazu na indexy. V indexech rowstore databázový stroj implementuje strom B+. To neplatí pro indexy columnstore ani indexy v tabulkách optimalizovaných pro paměť. Další informace najdete v SQL Serveru a architektuře indexu Azure SQL a průvodci návrhem.
Delta rowgroup
Delta rowgroup je clusterovaný B-stromový index, který se používá pouze s columnstore indexy. Zlepšuje kompresi a výkon sloupcového úložiště tím, že ukládá řádky, dokud počet řádků nedosáhne prahové hodnoty (1 048 576 řádků) a pak se řádky přesunou do sloupcového úložiště.
Když rozdílová skupina řádků dosáhne maximálního počtu řádků, přejde ze stavu OPEN do stavu CLOSED. Proces běžící na pozadí s názvem tuple-mover kontroluje uzavřené skupiny řádků. Pokud proces najde uzavřenou skupinu řádků, zkomprimuje delta skupinu řádků a uloží ji do columnstore jako komprimovanou skupinu řádků.
Když je zkomprimovaná rozdílová skupina řádků, stávající rozdílová skupina řádků přejde do stavu TOMBSTONE, který se později odebere třídičem záznamů, pokud na ni již není odkaz.
Další informace o stavech skupiny řádků najdete v tématu sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Note
Od SQL Serveru 2019 (15.x) je funkce tuple-moveru podporována úlohou sloučení na pozadí, která automaticky komprimuje menší delta skupiny řádků, jež existují po určitou dobu, jak je určeno interním prahem, nebo slučuje komprimované skupiny řádků, z nichž byl odstraněn velký počet řádků. To v průběhu času zlepšuje kvalitu indexu columnstore.
Deltastore
Index columnstore může mít více než jednu delta skupinu řádků. Všechny rozdílové skupiny řádků se souhrnně nazývají "deltastore".
Během velkého hromadného importu většina řádků přejde přímo do columnstore, aniž by prošla přes deltastore. Některé řádky na konci hromadného načtení můžou být příliš málo početné, aby splnily minimální požadovaný počet pro skupinu řádků, což je 102 400 řádků. Výsledkem je, že poslední řádky směřují do deltastore místo columnstore. U malých hromadných načtení s méně než 102 400 řádky přejdou všechny řádky přímo do deltastore.
Neklastrovaný index sloupcového úložiště
Neclusterovaný columnstore index a clusterovaný columnstore index fungují stejně. Rozdíl je v tom, že neclusterovaný index je sekundární index vytvořený v tabulce rowstore, ale clusterovaný index columnstore je primární úložiště pro celou tabulku.
Neclusterovaný index obsahuje kopii části nebo všech řádků a sloupců v podkladové tabulce. Index je definován jako jeden nebo více sloupců tabulky a má volitelnou podmínku, která filtruje řádky.
Neclusterovaný index columnstore umožňuje provozní analýzu v reálném čase, kde úloha OLTP používá základní clusterovaný index, zatímco analýzy běží souběžně na indexu columnstore. Další informace najdete v tématu Začínáme s columnstore pro operační analytiku v reálném čase.
Spouštění v dávkovém režimu
Dávkový režim zpracování dotazů je metoda, která se používá ke zpracování více řádků najednou. Provádění dávkového režimu je úzce integrované se sloupcovým úložištěm a optimalizované pro tento formát úložiště. Dávkový režim se někdy označuje jako vektorově založené nebo vektorizované provádění. Dotazy na indexy columnstore používají zpracování v dávkovém režimu, což zlepšuje výkon dotazů obvykle dvakrát až čtyřikrát. Další informace najdete v průvodci architekturou zpracování dotazů .
Proč mám použít index columnstore?
Sloupcový index může poskytnout velmi vysokou úroveň komprese dat, obvykle až 10násobně, což výrazně sníží náklady na úložiště datového skladu. Index columnstore nabízí pro účely analýzy vyšší výkon než index B-tree. Indexy Columnstore jsou upřednostňovaným formátem úložiště dat pro datové sklady a analytické úlohy. Počínaje SQL Serverem 2016 (13.x) můžete použít indexy columnstore k analýze provozní úlohy v reálném čase.
Důvody, proč jsou indexy columnstore tak rychlé:
Sloupce ukládají hodnoty ze stejné domény a běžně mají podobné hodnoty, což má za následek vysokou míru komprese. Kritické body vstupně-výstupních operací ve vašem systému jsou minimalizované nebo eliminované a nároky na paměť se výrazně snižují.
Vysoké míry komprese zlepšují výkon dotazů pomocí menšího využití paměti. Výkon dotazů se zase může zlepšit, protože SQL Server může provádět více operací dotazování a dat v paměti.
Dávkové spouštění zlepšuje výkon dotazů, obvykle o dva až čtyřikrát, tím, že zpracovává více řádků dohromady.
Dotazy často z tabulky vybírají jenom několik sloupců, což snižuje celkový počet vstupně-výstupních operací z fyzického média.
Kdy mám použít index columnstore?
Doporučené případy použití:
Pro ukládání faktových tabulek a velkých tabulek dimenzí pro úlohy datových skladů použijte clusterovaný columnstore index. Tato metoda zlepšuje výkon dotazů a kompresi dat až o 10krát. Další informace najdete v tématu Sloupcové indexy pro datové sklady.
Pomocí neclusterovaného indexu columnstore můžete provádět analýzu úlohy OLTP v reálném čase. Další informace najdete v tématu Začínáme s columnstore pro operační analytiku v reálném čase.
Další scénáře použití pro indexy columnstore najdete v tématu Volba nejlepšího indexu columnstore pro vaše potřeby.
Jak se dá vybrat mezi indexem rowstore a indexem columnstore?
Indexy s ukládáním řádků pracují nejlépe s dotazy, které pronikají do dat, při hledání konkrétní hodnoty nebo pro dotazy na malý rozsah hodnot. Používejte indexy rowstore s transakčními úlohami, protože obvykle vyžadují převážně vyhledávání záznamů místo prohledávání tabulek.
Indexy Columnstore poskytují vysoké zvýšení výkonu analytických dotazů, které kontrolují velké objemy dat, zejména u velkých tabulek. Indexy columnstore používejte u datových skladů a analytických úloh, zejména u tabulek faktů, protože místo hledání tabulek vyžadují úplné prohledávání tabulek.
Seřazené indexy columnstore v clusteru zlepšují výkon dotazů na základě seřazených predikátů sloupců. Seřazené sloupcové indexy mohou zlepšit eliminaci skupin řádků, čímž se může zvýšit výkon tím, že se zcela vynechají skupiny řádků. Další informace najdete v sekci Ladění výkonu se seřazenými indexy typu columnstore. Pro dostupnost seřazeného columnstore indexu, viz Dostupnost seřazeného indexu sloupcového úložiště.
Můžu kombinovat řádkové úložiště a sloupcové úložiště ve stejné tabulce?
Yes. Od SQL Serveru 2016 (13.x) můžete vytvořit aktualizovatelný neclusterovaný index columnstore v tabulce rowstore. Index columnstore ukládá kopii vybraných sloupců, takže pro tato data potřebujete další místo, ale vybraná data se v průměru komprimují 10krát. Můžete spustit analýzu indexu columnstore a transakcí na indexu rowstore najednou. Columnstore se aktualizuje při změně dat v tabulce rowstore, takže oba indexy fungují se stejnými daty.
Počínaje SQL Serverem 2016 (13.x) můžete mít jeden nebo více neclusterovaných indexů rowstore v indexu columnstore a provádět efektivní hledání tabulek v podkladovém columnstore. K dispozici jsou i další možnosti. Omezení primárního klíče můžete například vynutit pomocí omezení UNIQUE v tabulce rowstore. Protože se nepodařilo vložit neunikátní hodnotu do tabulky typu rowstore, SQL Server nemůže vložit hodnotu do columnstore.
Seřazené sloupcové indexy
Díky povolení efektivního odstranění segmentů poskytují uspořádané indexy columnstore rychlejší výkon tím, že přeskočí velké objemy seřazených dat, které neodpovídají predikátu dotazu. Načtení dat do uspořádaného indexu columnstore může trvat déle než v neuspořádaném indexu kvůli operaci řazení dat, ale dotazy na uspořádané indexy columnstore můžou probíhat rychleji.
- Další informace o optimalizaci výkonu úloh datových skladů v databázovém stroji SQL s seřazenými indexy columnstore najdete v tématu Ladění výkonu s seřazenými indexy columnstore.
- Další informace o tom, kdy použít typ indexu columnstore, najdete v tématu Volba nejlepšího indexu columnstore pro vaše potřeby.
Dostupnost seřazeného sloupcového indexu
Uspořádané indexy columnstore jsou k dispozici na následujících platformách:
| Platform | Seřazené clusterované columnstore indexy | Seřazené indexy columnstore – neklastrované |
|---|---|---|
| Azure SQL Database | Yes | Yes |
| Spravovaná instance Azure SQL AUTD | Yes | Yes |
| Azure SQL Managed Instance2025 | Yes | Yes |
| Azure SQL Managed Instance2022 | Yes | No |
| Databáze SQL v rámci Microsoft Fabric | Yes1 | Yes |
| SQL Server 2025 (17.x) | Yes | Yes |
| SQL Server 2022 (16.x) | Yes | No |
| Vyhrazený fond SQL ve službě Azure Synapse Analytics | Yes | No |
AUTD platí pro službu Azure SQL Managed Instance nakonfigurovanou se zásadou aktualizace Always-up-to-date.
2025 platí pro službu Azure SQL Managed Instance nakonfigurovanou pomocí zásad aktualizace SQL Serveru 2025.
2022 platí pro službu Azure SQL Managed Instance nakonfigurovanou pomocí zásad aktualizace SQL Serveru 2022.
1v databázi SQL Fabric nejsou tabulky s clusterovanými indexy columnstore zrcadlené na Fabric OneLake.
Metadata
Všechny sloupce v indexu columnstore jsou uloženy v metadatech jako zahrnuté sloupce. Index columnstore nemá klíčové sloupce.
Související úkoly
| Task | Referenční články | Notes |
|---|---|---|
| Vytvořte tabulku jako sloupcové úložiště. | VYTVOŘIT TABULKU (Transact-SQL) | Ve výchozím nastavení používá při vytváření tabulky úložiště řádků jako podkladový formát dat. Počínaje SQL Serverem 2016 (13.x) můžete vytvořit tabulku s clusterovaným columnstore indexem použitím možnosti INDEX ... CLUSTERED COLUMNSTORE. Nemusíte nejprve vytvořit tabulku rowstore a pak ji převést na columnstore. |
| Převeďte tabulku rowstore na columnstore. | VYTVOŘIT COLUMNSTORE INDEX (Transact-SQL) | Převeďte existující haldu nebo B-tree na sloupcový úložiště. Příklady ukazují, jak zpracovat existující indexy a také název indexu při provádění tohoto převodu. |
| Vytvořte neclusterovaný index columnstore v tabulce rowstore. | VYTVOŘIT COLUMNSTORE INDEX (Transact-SQL) | Tabulka typu rowstore může mít jeden neklastrovaný index columnstore. Počínaje SQL Serverem 2016 (13.x) může mít neclusterovaný index columnstore filtrovanou podmínku. Příklady ukazují základní syntaxi. |
| Převeďte databázovou tabulku ze sloupcového úložiště na řádkové úložiště. | CREATE CLUSTERED INDEX (Transact-SQL) nebo Převést tabulku columnstore zpět na hromadu řádkového úložiště | Tento převod obvykle není nutný, ale někdy může docházet k převodu. Příklady ukazují, jak převést sloupcový index na hromadu nebo seskupený index. |
| Vytvořte sloupcové indexy pro datové sklady. | Columnstore indexy pro datové sklady | Popisuje, jak využívat columnstore indexy pro rychlé dotazování v datových skladech. |
| Vytváření indexů pro provozní analýzy | Začínáme s technologií columnstore pro provozní analýzy v reálném čase | Popisuje, jak vytvořit doplňkové indexy columnstore a B-tree, aby dotazy OLTP používaly indexy B-tree a analytické dotazy používají indexy columnstore. |
| Pomocí indexu stromu B vynucujte omezení primárního klíče u indexu columnstore. | Columnstore indexy pro datové sklady | Ukazuje, jak lze kombinovat indexy B-tree a columnstore pro vynucení omezení primárního klíče na tabulce columnstore. |
| Vytvořte tabulku optimalizovanou pro paměť s indexem úložiště sloupců. | VYTVOŘIT TABULKU (Transact-SQL) | Počínaje SQL Serverem 2016 (13.x) můžete vytvořit tabulku optimalizovanou pro paměť s indexem columnstore. Index columnstore lze také přidat po vytvoření tabulky pomocí syntaxe ALTER TABLE ADD INDEX. |
| Načtěte data do sloupcového indexu. | columnstore indexuje načítání dat | |
| Odstraňte index columnstore. | DROP INDEX (Transact-SQL) | Vyřazení indexu columnstore používá standardní syntaxi DROP INDEX, kterou používají indexy stromu B. Odstranění clusterovaného indexu columnstore převede tabulku columnstore na haldu. |
| Odstraňte řádek z indexu columnstore. | DELETE (Transact-SQL) | K odstranění řádku použijte DELETE (Transact-SQL). řádek columnstore: SQL Server označí řádek jako logicky odstraněný, ale fyzické úložiště řádku nepřevádí zpět, dokud není index znovu vytvořen. řádek v deltastore: SQL Server logicky i fyzicky odstraní řádek. |
| Aktualizujte řádek v indexu columnstore. | UPDATE (Transact-SQL) | K aktualizaci řádku použijte UPDATE (Transact-SQL). řádek columnstore: SQL Server označí řádek jako logicky odstraněný a potom vloží aktualizovaný řádek do deltastore. řádek deltastore: SQL Server aktualizuje řádek v deltastore. |
| Udržujte index typu columnstore. |
ALTER INDEX ... ZNOVUVYTVOŘIT PŘEORGANIZOVAT sloupcový index Metody údržby indexu: změna uspořádání a opětovného sestavení |
Ve většině případů ALTER INDEX ... REORGANIZE poskytuje výsledky podobné ALTER INDEX ... REBUILD , ale s nižší spotřebou prostředků.
ALTER INDEX ... REORGANIZE vždy funguje online. Obě možnosti defragmentují index columnstore a nutí řádky v deltastore přejít do columnstore.Počínaje SQL Serverem 2019 (15.x), ve službě Azure SQL Database a ve službě Azure SQL Managed Instance se kvalita indexu columnstore udržuje automaticky, takže ve většině případů není potřeba pravidelně udržovat indexy. |
Související obsah
- Co je nového v indexech columnstore
- Sloupcové indexy – průvodce načítáním dat
- Sloupcové indexy – Výkon dotazů
- Začněte s Columnstore pro analytiku v reálném čase
- Sloupcové indexy v datových skladech
- Defragmentace indexů Columnstore
- Architektura a navrhování indexů pro SQL Server a Azure SQL
- architektura indexu Columnstore
- VYTVOŘIT COLUMNSTORE INDEX (Transact-SQL)