Trénování modelu pro porozumění konverzačnímu jazyku
Po dokončení označování promluv můžete začít trénovat model. Trénování je proces, ve kterém se model učí z označených promluv.
Pokud chcete vytrénovat model, spusťte trénovací úlohu. Pouze úspěšně dokončené úlohy vytvoří model. Platnost trénovacích úloh vyprší po sedmi dnech, po této době už nebudete moct načíst podrobnosti o úloze. Pokud se vaše trénovací úloha úspěšně dokončila a vytvořil se model, nebude to mít vliv na vypršení platnosti úlohy. Najednou můžete mít spuštěnou jenom jednu trénovací úlohu a nemůžete spustit jiné úlohy ve stejném projektu.
Časy trénování můžou být kdekoli během několika sekund při práci s jednoduchými projekty, až několik hodin, kdy dosáhnete maximálního limitu promluv.
Vyhodnocení modelu se aktivuje automaticky po úspěšném dokončení trénování. Proces vyhodnocení začíná použitím natrénovaného modelu ke spouštění predikcí promluv v testovací sadě a porovnává predikované výsledky s poskytnutými popisky (které stanoví směrný plán pravdy).
Požadavky
- Úspěšně vytvořený projekt s nakonfigurovaným účtem služby Azure Blob Storage
- Označené promluvy
Vyvážení trénovacích dat
Pokud jde o trénovací data, zkuste udržovat schéma dobře vyvážené. Zahrnutím velkého množství jednoho záměru a velmi málo dalších výsledků je model, který je zkreslený vůči konkrétním záměrům.
Pokud chcete tento scénář vyřešit, možná budete muset převzorkovat trénovací sadu. Nebo ho možná budete muset přidat. Pokud chcete downsample, můžete:
- Zbavte se určitého procenta trénovacích dat náhodně.
- Analyzujte datovou sadu a odeberte nadměrně reprezentované duplicitní položky, což je systematičtější způsob.
Pokud chcete přidat do trénovací sady, v sadě Language Studio na kartě Popisování dat vyberte Navrhnout promluvy. Konverzační language Understanding odesílá volání do Azure OpenAI za účelem vygenerování podobných promluv.

V trénovací sadě byste také měli hledat nezamýšlené vzory. Podívejte se například, jestli je trénovací sada pro konkrétní záměr malými písmeny nebo začíná konkrétní frází. V takových případech se model, který natrénujete, může naučit tyto nezamýšlené předsudky v trénovací sadě místo toho, aby bylo možné generalizovat.
Doporučujeme, abyste v trénovací sadě zavedli různou velikost a interpunkční rozmanitosti. Pokud se očekává, že váš model bude zpracovávat varianty, nezapomeňte mít trénovací sadu, která také odráží tuto rozmanitost. Můžete například zahrnout některé promluvy do správného písmena a některé ve všech malých písmenech.
Rozdělování dat
Než začnete s procesem trénování, označí se promluvy ve vašem projektu do trénovací sady a testovací sady. Každý z nich slouží jiné funkci. Trénovací sada se používá při trénování modelu. Jedná se o sadu, ze které se model učí popisované promluvy. Testovací sada je nevidomá sada , která se do modelu nevejde během trénování, ale pouze během vyhodnocení.
Po úspěšném vytrénování modelu je možné model použít k předpovědím z promluv v testovací sadě. Tyto předpovědi se používají k výpočtu metrik vyhodnocení. Doporučujeme zajistit, aby všechny vaše záměry a entity byly v trénovací i testovací sadě dostatečně reprezentované.
Principy konverzačního jazyka podporují dvě metody rozdělení dat:
- Automatické rozdělení testovací sady z trénovacích dat: Systém rozdělí označená data mezi trénovací a testovací sady podle procent, které zvolíte. Doporučené procento rozdělení je 80 % pro trénování a 20 % pro testování.
Poznámka:
Pokud zvolíte možnost Automatické rozdělení testovací sady z trénovacích dat , rozdělí se pouze data přiřazená k trénovací sadě podle zadaných procent.
- Použijte ruční rozdělení trénovacích a testovacích dat: Tato metoda umožňuje uživatelům definovat, které promluvy mají patřit do které sady. Tento krok je povolený jenom v případě, že jste do testovací sady přidali promluvy během označování.
Režimy trénování
MODUL CLU podporuje dva režimy pro trénování modelů.
Standardní trénování využívá k relativně rychlému trénování modelů algoritmy strojového učení. Tato možnost je aktuálně dostupná jenom pro angličtinu a je zakázaná pro všechny projekty, které nepoužívají angličtinu (USA) nebo angličtinu (UK) jako svůj primární jazyk. Tato možnost školení je bezplatná. Standardní školení umožňuje přidávat promluvy a testovat je rychle bez poplatků. Zobrazené hodnocení by vás mělo vést k tomu, kde provést změny v projektu a přidat další promluvy. Jakmile několikrát itestrujete a provedete přírůstková vylepšení, můžete zvážit použití pokročilého trénování k trénování jiné verze modelu.
Pokročilé trénování využívá nejnovější technologie strojového učení k přizpůsobení modelů s vašimi daty. Očekává se, že se pro vaše modely zobrazí lepší skóre výkonu a umožní vám také používat vícejazyčné funkce modulu CLU. Pokročilé trénování se za ceny liší. Podrobnosti najdete v informacích o cenách.
Hodnocení můžete použít k vedení vašich rozhodnutí. V případě nesprávné předpovědi konkrétního příkladu v pokročilém trénování může na rozdíl od použití standardního režimu trénování dojít k nesprávnému predikci konkrétního příkladu. Pokud jsou ale celkové výsledky vyhodnocení lepší, doporučujeme použít konečný model. Pokud tomu tak není a nechcete používat žádné vícejazyčné funkce, můžete model natrénovaný pomocí standardního režimu dál používat.
Poznámka:
Měli byste očekávat, že uvidíte rozdíl v chování v skóre spolehlivosti záměru mezi režimy trénování, protože každý algoritmus kalibruje skóre odlišně.
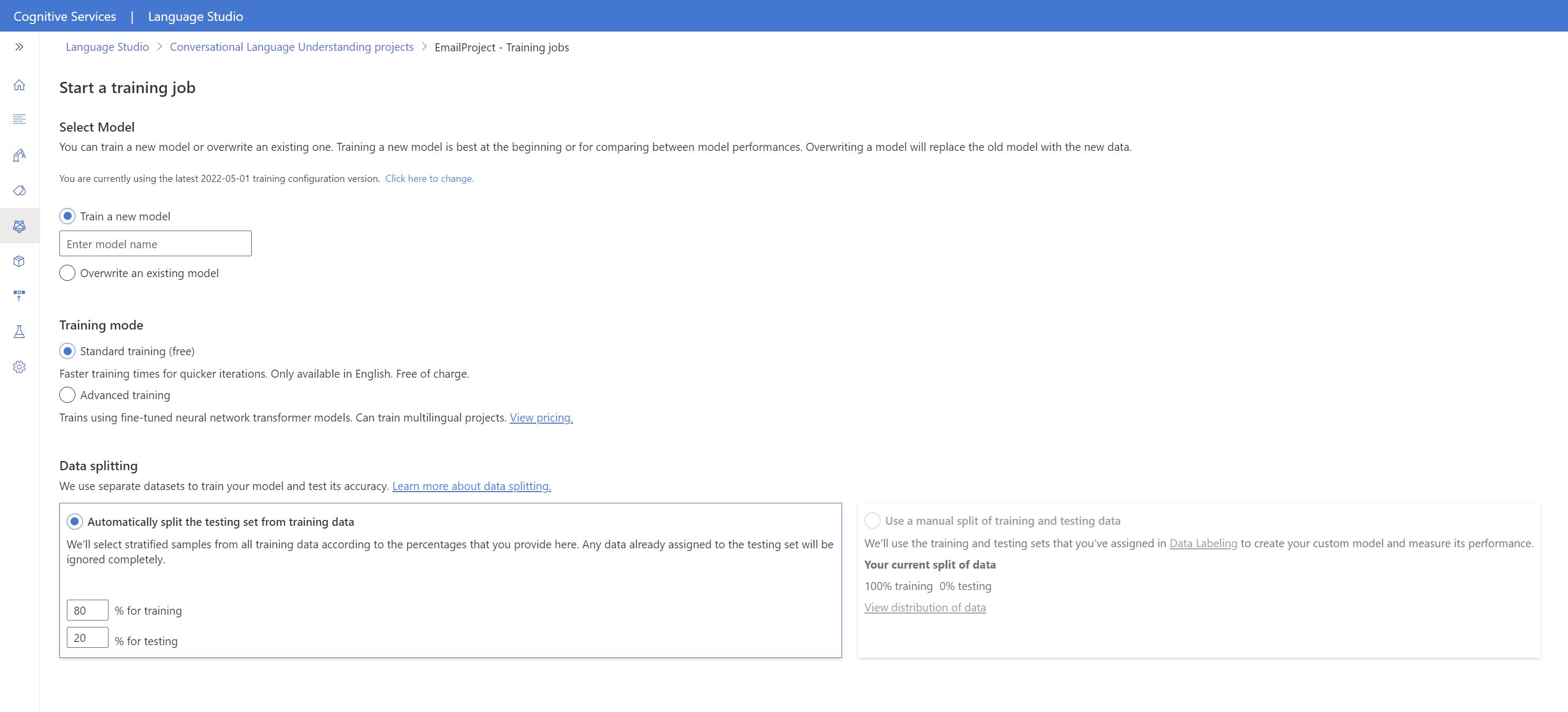
Trénování modelu
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Trénovat model .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte nový název modelu. V opačném případě chcete nahradit existující model modelem natrénovaným na nových datech, vyberte Přepsat existující model a pak vyberte existující model. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
Vyberte režim trénování. Pro rychlejší trénování můžete zvolit standardní trénování , ale je k dispozici pouze pro angličtinu. Nebo můžete zvolit rozšířené trénování , které je podporováno pro jiné jazyky a vícejazyčné projekty, ale zahrnuje delší dobu trénování. Přečtěte si další informace o režimech trénování.
Vyberte metodu rozdělení dat. Můžete zvolit automatické rozdělení testovací sady z trénovacích dat , kde systém rozdělí promluvy mezi trénovací a testovací sady podle zadaných procent. Nebo můžete použít ruční rozdělení trénovacích a testovacích dat, tato možnost je povolená jenom v případě, že jste do testovací sady přidali promluvy při označování promluv.
Vyberte tlačítko Trénovat.
V seznamu vyberte ID trénovací úlohy. Zobrazí se panel, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Trénování může nějakou dobu trvat několik minut až několik hodin na základě počtu promluv.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. Do dokončení spuštěné úlohy nemůžete spustit jiné trénovací úlohy v rámci stejného projektu.
- Strojové učení používané k trénování modelů se pravidelně aktualizuje. Pokud chcete vytrénovat předchozí verzi konfigurace, vyberte Možnost Vybrat, pokud chcete změnit stránku Spustit trénovací úlohu a zvolte předchozí verzi.

Zrušení trénovací úlohy
Zrušení trénovací úlohy v sadě Language Studio
- Na stránce Trénování modelu vyberte trénovací úlohu, kterou chcete zrušit, a v horní nabídce vyberte Zrušit.