Pokud chcete vytrénovat model, spusťte trénovací úlohu. Model vytvoří pouze úspěšně dokončené úlohy. Platnost trénovacích úloh vyprší po sedmi dnech, po této době už nebudete moct načíst podrobnosti o úloze. Pokud se vaše trénovací úloha úspěšně dokončila a vytvořil se model, vypršení platnosti úlohy na ni nebude mít vliv. Najednou můžete mít spuštěnou jenom jednu úlohu trénování a nemůžete spustit jiné úlohy ve stejném projektu.
Doba trénování může být od několika sekund při práci s jednoduchými projekty až po několik hodin, kdy dosáhnete maximálního limitu promluv.
Vyhodnocení modelu se aktivuje automaticky po úspěšném dokončení trénování. Proces vyhodnocení začíná použitím natrénovaného modelu ke spouštění predikcí promluv v testovací sadě a porovnává předpovězené výsledky se zadanými popisky (které stanoví základní hodnoty pravdivosti). Výsledky se vrátí, abyste mohli zkontrolovat výkon modelu.
Požadavky
Úspěšně vytvořený projekt s nakonfigurovaným účtem úložiště objektů blob v Azure
Než začnete s procesem trénování, jsou označené promluvy ve vašem projektu rozdělené na trénovací sadu a testovací sadu. Každá z nich má jinou funkci.
Trénovací sada se používá při trénování modelu. Jedná se o sadu, ze které se model učí označené promluvy.
Testovací sada je sada nevidomých, která se do modelu nezavádí během trénování, ale pouze během vyhodnocení.
Po úspěšném natrénování modelu je možné ho použít k předpovědím z promluv v testovací sadě. Tyto předpovědi se používají k výpočtu metrik vyhodnocení.
Doporučujeme zajistit, aby všechny vaše záměry byly adekvátně zastoupeny v trénovací i testovací sadě.
Pracovní postup orchestrace podporuje dvě metody rozdělení dat:
Automatické rozdělení testovací sady od trénovacích dat: Systém rozdělí označená data mezi trénovací a testovací sadu podle zvolených procent. Doporučené procento rozdělení je 80 % pro trénování a 20 % pro testování.
Poznámka
Pokud zvolíte možnost Automaticky rozdělit testovací sadu od trénovacích dat , rozdělí se podle zadaných procent pouze data přiřazená k trénovací sadě.
Použití ručního rozdělení trénovacích a testovacích dat: Tato metoda umožňuje uživatelům definovat, které promluvy mají patřit do které sady. Tento krok je povolený jenom v případě, že jste během označování přidali do testovací sady promluvy.
Poznámka
Do trénovací datové sady můžete přidávat výroky jenom pro nespojované záměry.
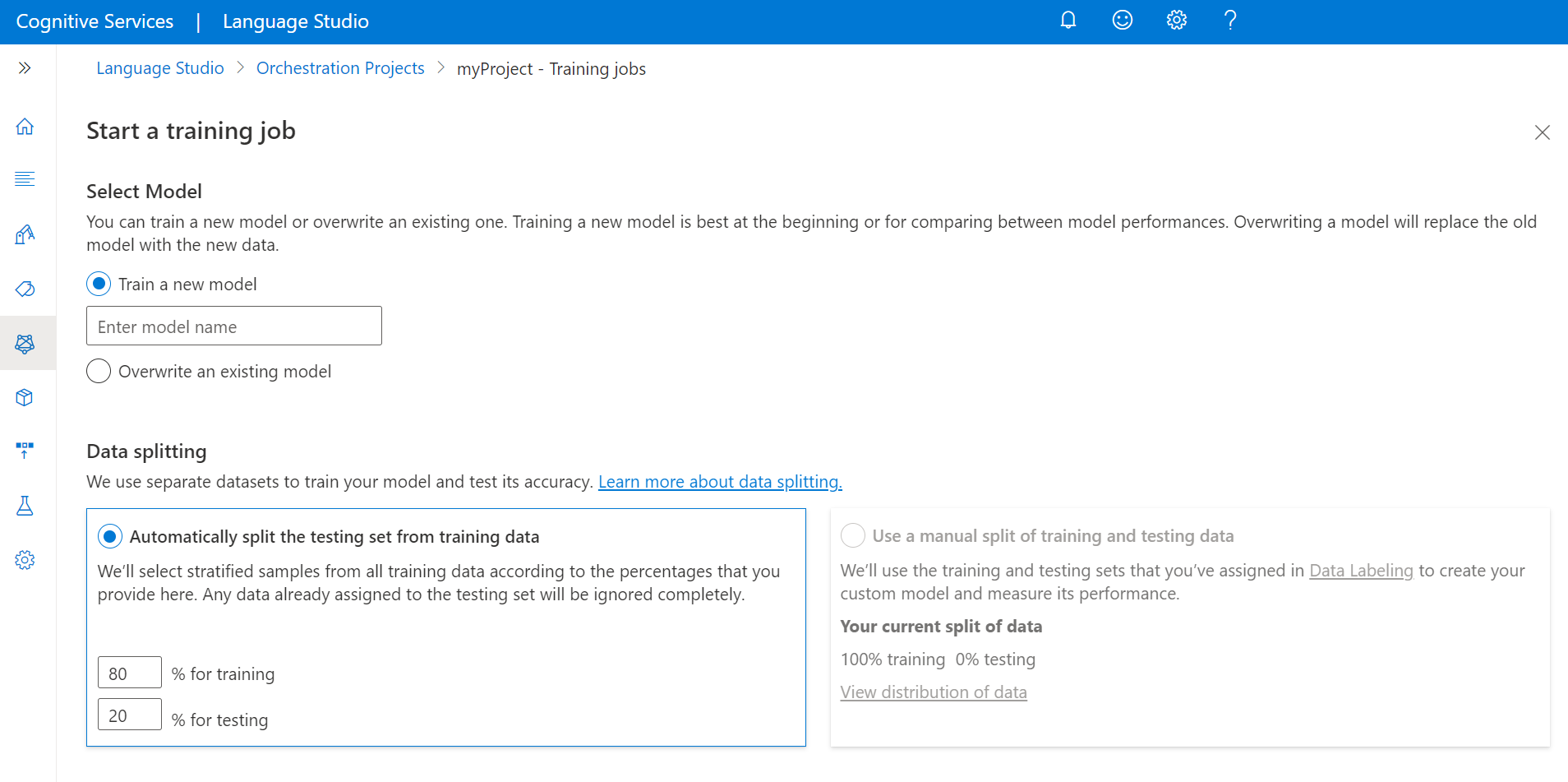
Pokud chcete začít s trénováním modelu v sadě Language Studio:
V nabídce na levé straně vyberte Trénovací úlohy .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Trénování nového modelu a do textového pole zadejte název modelu. Existující model můžete také přepsat tak, že vyberete tuto možnost a v rozevírací nabídce zvolíte model, který chcete přepsat. Přepsání natrénovaného modelu je nevratné, ale nasazené modely neovlivní, dokud nový model nenasadíte.
Automatické rozdělení testovací sady od trénovacích dat: Označené promluvy se náhodně rozdělí mezi trénovací a testovací sadu podle toho, kolik procent zvolíte. Výchozí procentuální rozdělení je 80 % pro trénování a 20 % pro testování. Pokud chcete tyto hodnoty změnit, zvolte sadu, kterou chcete změnit, a zadejte novou hodnotu.
Poznámka
Pokud zvolíte možnost Automaticky rozdělit testovací sadu od trénovacích dat , rozdělí se podle zadaných procent jenom promluvy ve vaší trénovací sadě.
Použití ručního rozdělení trénovacích a testovacích dat: Přiřaďte každou promluvu buď k trénovací , nebo testovací sadě během kroku označování projektu.
Poznámka
Možnost ručního rozdělení trénovacích a testovacích dat se povolí jenom v případě, že do testovací sady na stránce dat značek přidáte promluvy. V opačném případě bude zakázán.
Vyberte tlačítko Train (Trénovat).
Poznámka
Modely budou generovat pouze úspěšně dokončené trénovací úlohy.
Trénování může na základě velikosti označených dat nějakou dobu trvat několik minut až několik hodin.
Najednou můžete mít spuštěnou pouze jednu úlohu trénování. Nelze spustit jinou úlohu trénování se stejným projektem, dokud se spuštěná úloha nedokončí.
Vytvořte požadavek POST pomocí následující adresy URL, hlaviček a textu JSON a odešlete trénovací úlohu.
Adresa URL požadavku
Při vytváření požadavku rozhraní API použijte následující adresu URL. Nahraďte následující zástupné hodnoty vlastními hodnotami.
Režim trénování. V orchestraci je k dispozici pouze jeden režim trénování, kterým je standard.
standard
trainingConfigVersion
{CONFIG-VERSION}
Verze modelu konfigurace trénování. Ve výchozím nastavení se používá nejnovější verze modelu .
2022-05-01
kind
percentage
Metody rozdělení. Možné hodnoty jsou percentage nebo manual. Další informace najdete v tématu trénování modelu .
percentage
trainingSplitPercentage
80
Procento označených dat, která se mají zahrnout do trénovací sady Doporučená hodnota je 80.
80
testingSplitPercentage
20
Procento označených dat, která se mají zahrnout do testovací sady Doporučená hodnota je 20.
20
Poznámka
Hodnoty trainingSplitPercentage a testingSplitPercentage jsou vyžadovány pouze v případě, že Kind je nastavená na percentage hodnotu a součet obou procent by se měl rovnat hodnotě 100.
Jakmile odešlete požadavek rozhraní API, obdržíte odpověď označující 202 úspěch. V hlavičce odpovědi extrahujte operation-location hodnotu . Bude formátovaný takto:
V seznamu vyberte ID trénovací úlohy. Zobrazí se boční podokno, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti pro tuto úlohu.
Trénování může nějakou dobu trvat v závislosti na velikosti trénovacích dat a složitosti schématu. Pomocí následujícího požadavku můžete pokračovat v dotazování na stav trénovací úlohy, dokud nebude úspěšně dokončena.
Pomocí následujícího požadavku GET získáte stav průběhu trénování modelu. Nahraďte následující zástupné hodnoty vlastními hodnotami.
K ověření požadavku použijte následující hlavičku.
Klíč
Hodnota
Ocp-Apim-Subscription-Key
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API.
Text odpovědi
Jakmile požadavek odešlete, obdržíte následující odpověď. Pokračujte v dotazování tohoto koncového bodu, dokud se parametr status nezmění na "succeeded".
Pokud chcete zrušit úlohu trénování v nástroji Language Studio, přejděte na stránku Trénování modelu . Vyberte trénovací úlohu, kterou chcete zrušit, a v horní nabídce vyberte Zrušit .
Vytvořte požadavek POST pomocí následující adresy URL, hlaviček a textu JSON a zrušte trénovací úlohu.
Adresa URL požadavku
Při vytváření požadavku rozhraní API použijte následující adresu URL. Nahraďte následující zástupné hodnoty vlastními hodnotami.
K ověření požadavku použijte následující hlavičku.
Klíč
Hodnota
Ocp-Apim-Subscription-Key
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API.
Po odeslání požadavku rozhraní API obdržíte odpověď 202 označující úspěch, což znamená, že vaše trénovací úloha byla zrušena. Výsledky úspěšného volání s hlavičkou Operation-Location sloužící ke kontrole stavu úlohy.
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.