Přizpůsobení modelu pomocí jemného ladění
Služba Azure OpenAI umožňuje přizpůsobit naše modely vašim osobním datovým sadám pomocí procesu označovaného jako jemné ladění. Tento krok přizpůsobení vám umožní získat více ze služby tím, že poskytuje:
- Vyšší kvalita výsledků než to, co můžete získat pouze z příkazového inženýrství
- Možnost trénovat na více příkladech, než se vejde do limitu maximálního počtu požadavků modelu.
- Úspory tokenů z důvodu kratších výzev
- Požadavky s nižší latencí, zejména při použití menších modelů.
Na rozdíl od učení s několika snímky zlepšuje vyladění modelu trénováním na mnoha dalších příkladech, než se vejde do výzvy, což vám umožní dosáhnout lepších výsledků u širokého počtu úkolů. Vzhledem k tomu, že vyladění upraví váhy základního modelu, aby se zlepšil výkon konkrétní úlohy, nemusíte do výzvy zahrnout tolik příkladů ani pokynů. To znamená méně odesílaných textu a méně tokenů zpracovaných při každém volání rozhraní API, což může ušetřit náklady a zlepšit latenci požadavků.
LoRA nebo aproximace nízkého pořadí používáme k vyladění modelů způsobem, který snižuje jejich složitost, aniž by to výrazně ovlivnilo jejich výkon. Tato metoda funguje aproximací původní matice s vysokým pořadím s nižším pořadím, takže pouze menší podmnožinu důležitých parametrů během fáze trénování pod dohledem, takže model bude lépe spravovatelný a efektivnější. Pro uživatele to znamená, že trénování je rychlejší a cenově výhodnější než jiné techniky.
Na portálu Azure AI Foundry existují dvě jedinečná prostředí pro vyladění:
- Zobrazení centra/projektu – podporuje jemně vyladěné modely od několika poskytovatelů, včetně Azure OpenAI, Meta Llama, Microsoft Phi atd.
- Zobrazení zaměřené na Azure OpenAI – podporuje pouze vyladění modelů Azure OpenAI, ale podporuje další funkce, jako je integrace Weights &Biases (W&B).
Pokud model Azure OpenAI dolaďujete jenom doladit, doporučujeme vám přejít na https://oai.azure.comprostředí zaměřené na Azure OpenAI, které je k dispozici.
Požadavky
- Přečtěte si průvodce vyladěním možností Kdy používat Azure OpenAI.
- Předplatné Azure. Vytvořte si ho zdarma.
- Prostředek Azure OpenAI umístěný v oblasti, která podporuje jemné ladění modelu Azure OpenAI. Projděte si tabulku souhrnu modelů a dostupnost oblastí pro seznam dostupných modelů podle oblastí a podporovaných funkcí. Další informace najdete v tématu Vytvoření prostředku a nasazení modelu pomocí Azure OpenAI.
- Vyladění přístupu vyžaduje přispěvatel OpenAI služeb Cognitive Services.
- Pokud ještě nemáte přístup k zobrazení kvóty a nasazujete modely na portálu Azure AI Foundry, budete potřebovat další oprávnění.
Modely
Následující modely podporují vyladění:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Vyladění tohoto modelu je aktuálně ve verzi Public Preview.
Nebo můžete doladit dříve vyladěný model formátovaný jako base-model.ft-{jobid}.
Na stránce modelů zkontrolujte, které oblasti aktuálně podporují vyladění.
Kontrola pracovního postupu pro portál Azure AI Foundry
Chvíli si projděte postup vyladění pro používání portálu Azure AI Foundry:
- Připravte trénovací a ověřovací data.
- K trénování vlastního modelu použijte průvodce vytvořením vlastního modelu na portálu Azure AI Foundry.
- Zkontrolujte stav vlastního jemně vyladěného modelu.
- Nasaďte vlastní model pro použití.
- Použijte vlastní model.
- Volitelně můžete analyzovat vlastní model tak, aby odpovídal výkonu a přizpůsobení.
Příprava trénovacích a ověřovacích dat
Vaše cvičební data a sady ověřovacích dat se skládají ze vstupních a výstupních příkladů toho, jak se má model provádět.
Různé typy modelů vyžadují jiný formát trénovacích dat.
Použitá trénovací a ověřovací data musí být naformátovaná jako dokument JSON Lines (JSONL). Pro gpt-35-turbo (všechny verze), gpt-4gpt-4oa , a gpt-4o-mini, je nutné doladit datovou sadu musí být formátován v konverzačním formátu, který používá rozhraní API pro dokončování chatu.
Pokud chcete podrobný postup vyladění gpt-4o-mini modelu (2024-07-18), projděte si kurz podrobného ladění Azure OpenAI.
Příklad formátu souboru
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formát souboru chatu s vícenásobným převodem na Azure OpenAI
Podporuje se také několik otočení konverzace v jednom řádku trénovacího souboru jsonl. Pokud chcete přeskočit jemné ladění konkrétních zpráv pomocníka, přidejte dvojici volitelných weight hodnot klíče. Aktuálně weight je možné nastavit hodnotu 0 nebo 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Dokončování chatu se zrakem
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Kromě formátu JSONL musí být trénovací a ověřovací datové soubory kódované v kódování UTF-8 a obsahovat značku pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Vytvoření trénovacích a ověřovacích datových sad
Čím více trénovacích příkladů máte, tím lépe. Úlohy jemného ladění nebudou pokračovat bez alespoň 10 příkladů trénování, ale takové malé číslo nestačí k výrazně ovlivnění odpovědí modelu. Osvědčeným postupem je poskytnout stovky příkladů trénování, pokud ne tisíce, aby byly úspěšné.
Obecně platí, že zdvojnásobení velikosti datové sady může vést k lineárnímu zvýšení kvality modelu. Mějte ale na paměti, že příklady nízké kvality můžou negativně ovlivnit výkon. Pokud model vytrénujete na velké množství interních dat, aniž byste nejprve datovou sadu vyřezávali jenom pro příklady s nejvyšší kvalitou, mohli byste skončit s modelem, který funguje mnohem hůře, než se čekalo.
Použití průvodce vytvořením vlastního modelu
Portál Azure AI Foundry poskytuje průvodce vytvořením vlastního modelu , takže můžete interaktivně vytvářet a trénovat jemně vyladěný model pro váš prostředek Azure.
Otevřete portál https://oai.azure.com/ Azure AI Foundry a přihlaste se pomocí přihlašovacích údajů, které mají přístup k vašemu prostředku Azure OpenAI. Během přihlašovacího pracovního postupu vyberte příslušný adresář, předplatné Azure a prostředek Azure OpenAI.
Na portálu Azure AI Foundry přejděte do podokna Nástroje > pro vyladění a vyberte Model vyladit.
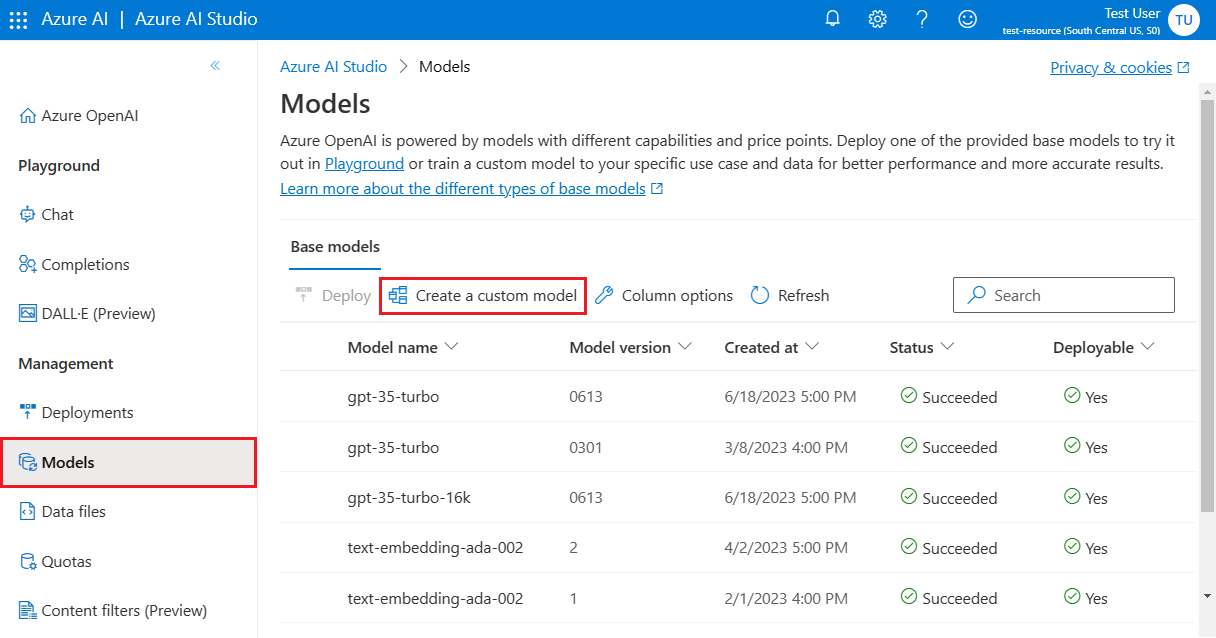

Otevře se průvodce vytvořením vlastního modelu .
Výběr základního modelu
Prvním krokem při vytváření vlastního modelu je zvolit základní model. Podokno Základní model umožňuje zvolit základní model, který se má použít pro vlastní model. Vaše volba ovlivňuje výkon i náklady modelu.
V rozevíracím seznamu Základní typ modelu vyberte základní model a pokračujte výběrem možnosti Další .
Vlastní model můžete vytvořit z některého z následujících dostupných základních modelů:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)Nebo můžete doladit dříve vyladěný model formátovaný jako base-model.ft-{jobid}.

Další informace o našich základních modelech, které je možné doladit, najdete v tématu Modely.
Volba trénovacích dat
Dalším krokem je zvolit stávající připravená trénovací data nebo nahrát nová připravená trénovací data, která se mají použít při přizpůsobení modelu. V podokně trénovacích dat se zobrazí všechny existující dříve nahrané datové sady a také možnosti pro nahrání nových trénovacích dat.

Pokud se trénovací data už nahrají do služby, vyberte Soubory z připojení Azure OpenAI.
- V zobrazeném rozevíracím seznamu vyberte soubor.
Pokud chcete nahrát nová trénovací data, použijte jednu z následujících možností:
Vyberte Místní soubor a nahrajte trénovací data z místního souboru.
Vyberte objekt blob Azure nebo jiná sdílená webová umístění pro import trénovacích dat z objektu blob Azure nebo jiného sdíleného webového umístění.
U velkých datových souborů doporučujeme importovat z úložiště objektů blob v Azure. Velké soubory se můžou stát nestabilní, když se nahrají prostřednictvím formulářů s více částmi, protože požadavky jsou atomické a nejde je opakovat ani obnovit. Další informace o službě Azure Blob Storage najdete v tématu Co je Azure Blob Storage?
Poznámka:
Trénovací datové soubory musí být formátované jako soubory JSONL zakódované v UTF-8 pomocí značky pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Nahrání trénovacích dat z místního souboru
Novou trénovací datovou sadu můžete do služby nahrát z místního souboru pomocí jedné z následujících metod:
Přetáhněte soubor do klientské oblasti podokna trénovacích dat a pak vyberte Nahrát soubor.
V klientské oblasti podokna Trénovací data vyberte Vyhledat soubor, zvolte soubor, který chcete nahrát z dialogového okna Otevřít, a pak vyberte Nahrát soubor.
Po výběru a nahrání trénovací datové sady pokračujte výběrem možnosti Další .

Import trénovacích dat z úložiště objektů blob v Azure
Trénovací datovou sadu můžete importovat z objektu blob Azure nebo jiného sdíleného webového umístění zadáním názvu a umístění souboru.
Zadejte název souboru.
Jako umístění Soubor zadejte adresu URL objektu blob Azure, sdílený přístupový podpis (SAS) služby Azure Storage nebo jiný odkaz na přístupné sdílené webové umístění.
Vyberte Importovat a naimportujte trénovací datovou sadu do služby.
Po výběru a nahrání trénovací datové sady pokračujte výběrem možnosti Další .

Volba ověřovacích dat
V dalším kroku najdete možnosti konfigurace modelu tak, aby používal ověřovací data v procesu trénování. Pokud nechcete používat ověřovací data, můžete zvolit Další a pokračovat v rozšířených možnostech modelu. Pokud máte ověřovací datovou sadu, můžete buď zvolit existující připravená ověřovací data, nebo nahrát nová připravená ověřovací data, která se mají použít při přizpůsobení modelu.
V podokně ověřovacích dat se zobrazí všechny existující dříve nahrané trénovací a ověřovací datové sady a možnosti, pomocí kterých můžete nahrát nová ověřovací data.

Pokud se ověřovací data už nahrají do služby, vyberte Zvolit datovou sadu.
- V seznamu zobrazeném v podokně Ověřovací data vyberte soubor.
Pokud chcete nahrát nová ověřovací data, použijte jednu z následujících možností:
Vyberte Místní soubor a nahrajte ověřovací data z místního souboru.
Vyberte objekt blob Azure nebo jiná sdílená webová umístění pro import ověřovacích dat z objektu blob Azure nebo jiného sdíleného webového umístění.
U velkých datových souborů doporučujeme importovat z úložiště objektů blob v Azure. Velké soubory se můžou stát nestabilní, když se nahrají prostřednictvím formulářů s více částmi, protože požadavky jsou atomické a nejde je opakovat ani obnovit.
Poznámka:
Podobně jako u trénovacích datových souborů musí být ověřovací datové soubory formátované jako soubory JSONL zakódované v kódování UTF-8 pomocí značky pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Nahrání ověřovacích dat z místního souboru
Novou ověřovací datovou sadu můžete do služby nahrát z místního souboru pomocí jedné z následujících metod:
Přetáhněte soubor do klientské oblasti podokna Ověřovací data a pak vyberte Nahrát soubor.
V klientské oblasti podokna Ověřovací data vyberte Vyhledat soubor, zvolte soubor, který chcete nahrát z dialogového okna Otevřít, a pak vyberte Nahrát soubor.
Po výběru a nahrání ověřovací datové sady pokračujte výběrem možnosti Další .

Import ověřovacích dat z úložiště objektů blob v Azure
Ověřovací datovou sadu můžete importovat z objektu blob Azure nebo jiného sdíleného webového umístění zadáním názvu a umístění souboru.
Zadejte název souboru.
Jako umístění Soubor zadejte adresu URL objektu blob Azure, sdílený přístupový podpis (SAS) služby Azure Storage nebo jiný odkaz na přístupné sdílené webové umístění.
Vyberte Importovat a naimportujte trénovací datovou sadu do služby.
Po výběru a nahrání ověřovací datové sady pokračujte výběrem možnosti Další .

Konfigurace parametrů úkolu
Průvodce vytvořením vlastního modelu zobrazuje parametry pro trénování jemně vyladěného modelu v podokně Parametry úlohy. K dispozici jsou následující parametry:
| Název | Typ | Popis |
|---|---|---|
batch_size |
integer | Velikost dávky, která se má použít pro trénování. Velikost dávky je počet trénovacích příkladů, které se používají k trénování jednoho dopředu a dozadu. Obecně jsme zjistili, že větší velikosti dávek obvykle fungují lépe u větších datových sad. Výchozí hodnota a maximální hodnota této vlastnosti jsou specifické pro základní model. Větší velikost dávky znamená, že parametry modelu se aktualizují méně často, ale s nižší odchylkou. |
learning_rate_multiplier |
Číslo | Násobitel rychlosti učení, který se má použít pro trénování. Míra doladění je původní míra učení používaná pro předtrénování vynásobenou touto hodnotou. Větší rychlost učení obvykle funguje lépe s většími velikostmi dávek. Doporučujeme experimentovat s hodnotami v rozsahu 0,02 až 0,2, abyste zjistili, co vede k dosažení nejlepších výsledků. Menší rychlost učení může být užitečná, abyste se vyhnuli přeurčení. |
n_epochs |
integer | Počet epoch pro trénování modelu. Epocha odkazuje na jeden celý cyklus prostřednictvím trénovací datové sady. |
seed |
integer | Počáteční hodnota řídí reprodukovatelnost úlohy. Předání stejných počátečních parametrů a parametrů úlohy by mělo vést ke stejným výsledkům, ale ve výjimečných případech se může lišit. Pokud není zadaná počáteční eda, vygeneruje se za vás. |
Beta |
integer | Parametr teploty pro ztrátu dpo, obvykle v rozsahu 0,1 až 0,5. To určuje, kolik pozornosti věnujeme referenčnímu modelu. Čím menší beta verze, tím více modelu můžeme odcházet od referenčního modelu. Vzhledem k tomu, že beta verze je čím dál menší, referenční model ignorujeme. |

Vyberte Výchozí , pokud chcete použít výchozí hodnoty pro úlohu vyladění, nebo vyberte Vlastní , pokud chcete zobrazit a upravit hodnoty hyperparametrů. Při výběru výchozích hodnot určíme algoritmus správné hodnoty na základě trénovacích dat.
Po nakonfigurování rozšířených možností vyberte Další , abyste zkontrolovali své volby a vytrénovali jemně vyladěný model.
Kontrola možností a trénování modelu
V podokně Kontrola průvodce se zobrazí informace o vašich možnostech konfigurace.

Pokud jste připraveni na trénování modelu, vyberte Spustit úlohu trénování a spusťte úlohu jemného ladění a vraťte se do podokna Modely .
Kontrola stavu vlastního modelu
Podokno Modely zobrazuje informace o vašem vlastním modelu na kartě Vlastní modely . Karta obsahuje informace o stavu a ID úlohy pro vlastní model. Po dokončení úlohy se na kartě zobrazí ID souboru výsledku. Možná budete muset vybrat Aktualizovat , abyste viděli aktualizovaný stav úlohy trénování modelu.

Po spuštění úlohy jemného ladění může dokončení nějakou dobu trvat. Vaše úloha může být zařazena do fronty za jinými úlohami v systému. Trénování modelu může trvat minuty nebo hodiny v závislosti na velikosti modelu a datové sady.
Tady jsou některé úlohy, které můžete dělat v podokně Modely :
Ve sloupci Stav na kartě Vlastní modely zkontrolujte stav úlohy vyladění vlastního modelu.
Ve sloupci Název modelu vyberte název modelu, abyste zobrazili další informace o vlastním modelu. Můžete zobrazit stav jemně vyladěné úlohy, výsledků trénování, trénovacích událostí a hyperparametrů použitých v úloze.
Vyberte Stáhnout trénovací soubor a stáhněte trénovací data, která jste použili pro model.
Výběrem možnosti Stáhnout výsledky stáhněte soubor výsledků připojený k úloze vyladění modelu a analyzujte vlastní model pro výkon trénování a ověření.
Vyberte možnost Obnovit, abyste aktualizovali informace na stránce.
Kontrolní body
Po dokončení každé epochy trénování se vygeneruje kontrolní bod. Kontrolní bod je plně funkční verze modelu, která se dá nasadit i použít jako cílový model pro následné úlohy jemného ladění. Kontrolní body můžou být zvlášť užitečné, protože můžou poskytnout snímek modelu před přeurčením. Po dokončení úlohy vyladění budete mít k dispozici tři nejnovější verze modelu, které je možné nasadit.
Bezpečnostní vyhodnocení GPT-4, GPT-4o a GPT-4o-mini fine-tuning - Public Preview
GPT-4o, GPT-4o-mini a GPT-4 jsou naše nejpokročilejší modely, které je možné doladit podle vašich potřeb. Stejně jako u modelů Azure OpenAI obecně přináší pokročilé funkce jemně vyladěných modelů zvýšené zodpovědné problémy s AI souvisejícími se škodlivým obsahem, manipulací, chováním podobným lidem, problémy s ochranou osobních údajů a dalšími funkcemi. Další informace o rizicích, možnostech a omezeních najdete v přehledu postupů zodpovědné umělé inteligence a poznámky k transparentnosti. Abychom pomohli zmírnit rizika spojená s pokročilými jemně vyladěnými modely, implementovali jsme další kroky vyhodnocení, které pomáhají detekovat a zabránit škodlivému obsahu v trénování a výstupech jemně vyladěných modelů. Tyto kroky jsou zakotveny v filtrování obsahu služby Microsoft Responsible AI Standard a Azure OpenAI Service.
- Vyhodnocení se provádí ve vyhrazených, zákaznických, soukromých pracovních prostorech;
- Zkušební koncové body jsou ve stejné zeměpisné oblasti jako prostředek Azure OpenAI;
- Trénovací data se neukládají v souvislosti s prováděním vyhodnocení; je zachováno pouze konečné posouzení modelu (nasaditelné nebo nenasazovatelné); a
Filtry hodnocení modelů GPT-4o, GPT-4o-mini a GPT-4 jsou nastaveny na předdefinované prahové hodnoty a zákazníci je nemůžou upravovat; nejsou svázané s konfigurací filtrování vlastního obsahu, kterou jste možná vytvořili.
Vyhodnocení dat
Před zahájením trénování se vaše data vyhodnotí jako potenciálně škodlivý obsah (násilí, sexuální, nenávist a nestrannost, sebepoškozování – viz definice kategorií zde). Pokud se zjistí škodlivý obsah nad zadanou úrovní závažnosti, vaše trénovací úloha selže a zobrazí se zpráva s informacemi o kategoriích selhání.
Ukázková zpráva:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vaše trénovací data se v rámci úlohy importu dat vyhodnocují automaticky jako součást poskytování možnosti vyladění.
Pokud úloha vyladění selže kvůli detekci škodlivého obsahu v trénovacích datech, nebude se vám účtovat poplatek.
Vyhodnocení modelu
Po dokončení trénování, ale před tím, než je k dispozici jemně vyladěný model pro nasazení, se výsledný model vyhodnotí jako potenciálně škodlivé reakce pomocí předdefinovaných metrik rizik a bezpečnosti Azure. Pomocí stejného přístupu k testování, který používáme pro základní velké jazykové modely, naše funkce hodnocení simuluje konverzaci s vaším jemně vyladěným modelem, aby posoudila potenciál výstupu škodlivého obsahu, a to znovu pomocí zadaných škodlivých kategorií obsahu (násilí, sexuální, nenávist a nestrannost, sebepoškozování).
Pokud se zjistí, že se v modelu vygeneruje výstup obsahující obsah, který je zjištěn jako škodlivý nad přijatelnou rychlostí, budete informováni, že váš model není k dispozici pro nasazení, s informacemi o konkrétních kategoriích zjištěných škod:
Ukázková zpráva:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Stejně jako u vyhodnocení dat se model vyhodnocuje automaticky v rámci vaší jemně vyladěné úlohy jako součást poskytování možnosti jemného ladění. Služba zaprotokoluje pouze výsledné hodnocení (nasaditelné nebo nejde nasaditelné). Pokud nasazení jemně vyladěného modelu selže kvůli detekci škodlivého obsahu ve výstupech modelu, nebude se vám účtovat za spuštění trénování.
Nasazení jemně vyladěného modelu
Pokud je úloha vyladění úspěšná, můžete vlastní model nasadit z podokna Modely . Abyste ho mohli používat s voláním dokončení, musíte nasadit vlastní model.
Důležité
Po nasazení přizpůsobeného modelu se nasazení odstraní, pokud nasazení zůstane neaktivní po dobu delší než patnáct (15) dnů. Nasazení přizpůsobeného modelu je neaktivní , pokud byl model nasazen před více než patnácti (15) dny a během nepřetržitého 15denního období se do něj neprovedou žádná dokončení ani dokončení chatu.
Odstranění neaktivního nasazení neodstraní ani neovlivní základní přizpůsobený model a přizpůsobený model je možné kdykoliv znovu nasadit. Jak je popsáno v cenách služby Azure OpenAI, každý přizpůsobený (vyladěný) model, který je nasazený, se každou hodinu hostuje bez ohledu na to, jestli se do modelu provádějí volání dokončení nebo dokončení chatu. Další informace o plánování a správě nákladů pomocí Azure OpenAI najdete v doprovodných materiálech v části Plánování správy nákladů na službu Azure OpenAI.
Poznámka:
Pro vlastní model je povoleno pouze jedno nasazení. Pokud vyberete již nasazený vlastní model, zobrazí se chybová zpráva.
Pokud chcete nasadit vlastní model, vyberte vlastní model, který chcete nasadit, a pak vyberte Nasadit model.

Otevře se dialogové okno Nasadit model . V dialogovém okně zadejte název nasazení a pak výběrem možnosti Vytvořit spusťte nasazení vlastního modelu.

Průběh nasazení můžete monitorovat v podokně Nasazení na portálu Azure AI Foundry.
Nasazení mezi oblastmi
Vyladění podporuje nasazení jemně vyladěného modelu do jiné oblasti, než kde byl model původně vyladěný. Můžete také nasadit do jiného předplatného nebo oblasti.
Jedinými omezeními je, že nová oblast musí také podporovat vyladění a při nasazování mezi předplatnými musí mít účet vygenerující autorizační token pro nasazení přístup ke zdrojovým i cílovým předplatným.
Nasazení mezi předplatnými nebo oblastmi je možné provést prostřednictvím Pythonu nebo REST.
Použití nasazeného vlastního modelu
Po nasazení vlastního modelu ho můžete použít jako jakýkoli jiný nasazený model. K experimentování s novým nasazením můžete použít dětské hřiště na portálu Azure AI Foundry. Stejné parametry můžete dál používat s vlastním modelem, například temperature a max_tokens, stejně jako u jiných nasazenýchmodelůch V případě jemně vyladěných babbage-002 a davinci-002 modelů použijete hřiště Completions a rozhraní API Pro doplňování. Pro jemně vyladěné gpt-35-turbo-0613 modely budete používat chatové hřiště a rozhraní API pro dokončování chatu.

Analýza vlastního modelu
Azure OpenAI připojí výsledný soubor s názvem results.csv ke každé úloze vyladění po dokončení. Výsledný soubor můžete použít k analýze výkonu trénování a ověření vlastního modelu. ID souboru výsledků je uvedené pro každý vlastní model ve sloupci ID souboru výsledku v podokně Modely pro portál Azure AI Foundry. ID souboru můžete použít k identifikaci a stažení výsledného souboru z podokna Datové soubory na portálu Azure AI Foundry.
Výsledný soubor je soubor CSV, který obsahuje řádek záhlaví a řádek pro každý krok trénování prováděný úlohou jemného ladění. Výsledný soubor obsahuje následující sloupce:
| Název sloupce | Popis |
|---|---|
step |
Počet kroků trénování. Trénovací krok představuje jeden průchod, dopředu a dozadu v dávce trénovacích dat. |
train_loss |
Ztráta pro trénovací dávku. |
train_mean_token_accuracy |
Procento tokenů v trénovací dávce správně predikované modelem. Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Ztráta pro ověřovací dávku. |
validation_mean_token_accuracy |
Procento tokenů v dávce ověřování správně predikované modelem Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Ztráta ověření vypočítaná na konci každé epochy. Když trénování půjde dobře, ztráta by se měla snížit. |
full_valid_mean_token_accuracy |
Platná průměrná přesnost tokenu vypočítaná na konci každé epochy. Při dobrém trénování by se měla zvýšit přesnost tokenů. |
Data v souboru results.csv můžete zobrazit také jako grafy na portálu Azure AI Foundry. Vyberte odkaz pro trénovaný model a zobrazí se tři grafy: ztráta, střední přesnost tokenu a přesnost tokenů. Pokud jste zadali ověřovací data, zobrazí se obě datové sady ve stejném grafu.
Vyhledejte ztrátu, abyste v průběhu času snížili a zvýšili přesnost. Pokud zjistíte rozdíl mezi trénovacími a ověřovacími daty, může to znamenat, že přeurčujete. Vyzkoušejte trénování s menším počtem epoch nebo menší násobitelem rychlosti učení.
Vyčištění nasazení, vlastních modelů a trénovacích souborů
Až budete s vlastním modelem hotovi, můžete nasazení a model odstranit. V případě potřeby můžete také odstranit trénovací a ověřovací soubory, které jste nahráli do služby.
Odstranění nasazení modelu
Důležité
Po nasazení přizpůsobeného modelu se nasazení odstraní, pokud nasazení zůstane neaktivní po dobu delší než patnáct (15) dnů. Nasazení přizpůsobeného modelu je neaktivní , pokud byl model nasazen před více než patnácti (15) dny a během nepřetržitého 15denního období se do něj neprovedou žádná dokončení ani dokončení chatu.
Odstranění neaktivního nasazení neodstraní ani neovlivní základní přizpůsobený model a přizpůsobený model je možné kdykoliv znovu nasadit. Jak je popsáno v cenách služby Azure OpenAI, každý přizpůsobený (vyladěný) model, který je nasazený, se každou hodinu hostuje bez ohledu na to, jestli se do modelu provádějí volání dokončení nebo dokončení chatu. Další informace o plánování a správě nákladů pomocí Azure OpenAI najdete v doprovodných materiálech v části Plánování správy nákladů na službu Azure OpenAI.
Nasazení vlastního modelu můžete odstranit v podokně Nasazení na portálu Azure AI Foundry. Vyberte nasazení, které chcete odstranit, a pak výběrem možnosti Odstranit nasazení odstraňte.
Odstranění vlastního modelu
Vlastní model můžete odstranit v podokně Modely na portálu Azure AI Foundry. Na kartě Vlastní modely vyberte vlastní model, který chcete odstranit, a pak vyberte Odstranit a odstraňte vlastní model.
Poznámka:
Pokud má existující nasazení, nemůžete odstranit vlastní model. Před odstraněním vlastního modelu musíte nejprve odstranit nasazení modelu.
Odstranění trénovacích souborů
Volitelně můžete odstranit trénovací a ověřovací soubory, které jste nahráli pro trénování, a výsledné soubory vygenerované během trénování v podokně Data pro správu>a indexy na portálu Azure AI Foundry. Vyberte soubor, který chcete odstranit, a pak soubor odstraňte výběrem možnosti Odstranit .
Průběžné jemné ladění
Jakmile vytvoříte jemně vyladěný model, můžete chtít model v průběhu času dále upřesnit prostřednictvím dalšího vyladění. Průběžné doladění je iterativní proces výběru již vyladěného modelu jako základního modelu a jeho dalšího vyladění v nových sadách trénovacích příkladů.
K vyladění modelu, který jste dříve vyladili, byste použili stejný postup, jak je popsáno v části Vytvoření přizpůsobeného modelu , ale místo zadání názvu obecného základního modelu byste zadali již vyladěný model. Vlastní jemně vyladěný model by vypadal takto: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

Doporučujeme také přidat suffix parametr, aby bylo snazší rozlišovat mezi různými iteracemi vašeho jemně vyladěného modelu.
suffix vezme řetězec a nastaví se k identifikaci jemně vyladěného modelu. S rozhraním OpenAI Python API se podporuje řetězec o velikosti až 18 znaků, který se přidá do vašeho jemně vyladěného názvu modelu.







Požadavky
- Přečtěte si průvodce vyladěním možností Kdy používat Azure OpenAI.
- Předplatné Azure. Vytvořte si ho zdarma.
- Prostředek Azure OpenAI. Další informace najdete v tématu Vytvoření prostředku a nasazení modelu pomocí Azure OpenAI.
- Následující knihovny Pythonu:
os,json,requests.openai - Knihovna OpenAI Python by měla mít minimálně verzi 0.28.1.
- Vyladění přístupu vyžaduje přispěvatel OpenAI služeb Cognitive Services.
- Pokud ještě nemáte přístup k zobrazení kvóty a nasazujete modely na portálu Azure AI Foundry, budete potřebovat další oprávnění.
Modely
Následující modely podporují vyladění:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Vyladění tohoto modelu je aktuálně ve verzi Public Preview.
Nebo můžete doladit dříve jemně vyladěný model formátovaný jako base-model.ft-{jobid}.
Na stránce modelů zkontrolujte, které oblasti aktuálně podporují vyladění.
Kontrola pracovního postupu pro sadu Python SDK
Chvilku si projděte vyladěný pracovní postup pro používání sady Python SDK s Azure OpenAI:
- Připravte trénovací a ověřovací data.
- Vyberte základní model.
- Nahrajte trénovací data.
- Trénujte nový přizpůsobený model.
- Zkontrolujte stav přizpůsobeného modelu.
- Nasaďte přizpůsobený model pro použití.
- Použijte přizpůsobený model.
- Volitelně můžete analyzovat přizpůsobený model tak, aby odpovídal výkonu a přizpůsobení.
Příprava trénovacích a ověřovacích dat
Vaše cvičební data a sady ověřovacích dat se skládají ze vstupních a výstupních příkladů toho, jak se má model provádět.
Různé typy modelů vyžadují jiný formát trénovacích dat.
Použitá trénovací a ověřovací data musí být naformátovaná jako dokument JSON Lines (JSONL). Pro gpt-35-turbo-0613 jemně vyladěnou datovou sadu musí být formátovaná v konverzačním formátu, který používá rozhraní API pro dokončování chatu .
Pokud chcete podrobný postup vyladění gpt-35-turbo-0613 , projděte si kurz podrobného ladění Azure OpenAI.
Příklad formátu souboru
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formát souboru chatu s vícenásobným převodem
Podporuje se také několik otočení konverzace v jednom řádku trénovacího souboru jsonl. Pokud chcete přeskočit jemné ladění konkrétních zpráv pomocníka, přidejte dvojici volitelných weight hodnot klíče. Aktuálně weight je možné nastavit hodnotu 0 nebo 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Dokončování chatu se zrakem
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Kromě formátu JSONL musí být trénovací a ověřovací datové soubory kódované v kódování UTF-8 a obsahovat značku pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Vytvoření trénovacích a ověřovacích datových sad
Čím více trénovacích příkladů máte, tím lépe. Úlohy jemného ladění nebudou pokračovat bez alespoň 10 příkladů trénování, ale takové malé číslo nestačí k výrazně ovlivnění odpovědí modelu. Osvědčeným postupem je poskytnout stovky příkladů trénování, pokud ne tisíce, aby byly úspěšné.
Obecně platí, že zdvojnásobení velikosti datové sady může vést k lineárnímu zvýšení kvality modelu. Mějte ale na paměti, že příklady nízké kvality můžou negativně ovlivnit výkon. Pokud model vytrénujete na velké množství interních dat, aniž byste nejprve datovou sadu vyřezávali jenom pro příklady s nejvyšší kvalitou, mohli byste skončit s modelem, který funguje mnohem hůře, než se čekalo.
Nahrání trénovacích dat
Dalším krokem je zvolit stávající připravená trénovací data nebo nahrát nová připravená trénovací data, která se mají použít při přizpůsobení modelu. Po přípravě trénovacích dat můžete soubory nahrát do služby. Trénovací data můžete nahrát dvěma způsoby:
U velkých datových souborů doporučujeme importovat z úložiště objektů blob v Azure. Velké soubory se můžou stát nestabilní, když se nahrají prostřednictvím formulářů s více částmi, protože požadavky jsou atomické a nejde je opakovat ani obnovit. Další informace o službě Azure Blob Storage najdete v tématu Co je Azure Blob Storage?
Poznámka:
Trénovací datové soubory musí být formátované jako soubory JSONL zakódované v UTF-8 pomocí značky pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Následující příklad Pythonu nahraje místní trénovací a ověřovací soubory pomocí sady Python SDK a načte vrácené ID souborů.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Vytvoření přizpůsobeného modelu
Po nahrání trénovacích a ověřovacích souborů jste připraveni zahájit úlohu vyladění.
Následující kód Pythonu ukazuje příklad vytvoření nové úlohy vyladění pomocí sady Python SDK:
V tomto příkladu předáváme také počáteční parametr. Počáteční hodnota řídí reprodukovatelnost úlohy. Předání stejných počátečních parametrů a parametrů úlohy by mělo vést ke stejným výsledkům, ale ve výjimečných případech se může lišit. Pokud není zadaná počáteční sada, vygeneruje se za vás.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Můžete také předat další volitelné parametry, jako jsou hyperparametry, abyste měli větší kontrolu nad procesem jemného ladění. Pro počáteční trénování doporučujeme použít automatické výchozí hodnoty, které jsou k dispozici bez zadání těchto parametrů.
Aktuální podporované hyperparametry pro vyladění jsou:
| Název | Typ | Popis |
|---|---|---|
batch_size |
integer | Velikost dávky, která se má použít pro trénování. Velikost dávky je počet trénovacích příkladů, které se používají k trénování jednoho dopředu a dozadu. Obecně jsme zjistili, že větší velikosti dávek obvykle fungují lépe u větších datových sad. Výchozí hodnota a maximální hodnota této vlastnosti jsou specifické pro základní model. Větší velikost dávky znamená, že parametry modelu se aktualizují méně často, ale s nižší odchylkou. |
learning_rate_multiplier |
Číslo | Násobitel rychlosti učení, který se má použít pro trénování. Míra doladění je původní míra učení používaná pro předtrénování vynásobenou touto hodnotou. Větší rychlost učení obvykle funguje lépe s většími velikostmi dávek. Doporučujeme experimentovat s hodnotami v rozsahu 0,02 až 0,2, abyste zjistili, co vede k dosažení nejlepších výsledků. Menší rychlost učení může být užitečná, abyste se vyhnuli přeurčení. |
n_epochs |
integer | Počet epoch pro trénování modelu. Epocha odkazuje na jeden celý cyklus prostřednictvím trénovací datové sady. |
seed |
integer | Počáteční hodnota řídí reprodukovatelnost úlohy. Předání stejných počátečních parametrů a parametrů úlohy by mělo vést ke stejným výsledkům, ale ve výjimečných případech se může lišit. Pokud není zadaná počáteční sada, vygeneruje se za vás. |
Nastavení vlastních hyperparametrů s verzí 1.x rozhraní OpenAI Python API:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Kontrola stavu úlohy v jemném ladění
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Vypsání událostí jemného ladění
Prozkoumání jednotlivých událostí vyladění, které byly generovány během trénování:
Abyste mohli tento příkaz spustit, budete možná muset upgradovat klientskou knihovnu OpenAI na nejnovější verzi pip install openai --upgrade .
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Kontrolní body
Po dokončení každé epochy trénování se vygeneruje kontrolní bod. Kontrolní bod je plně funkční verze modelu, která se dá nasadit i použít jako cílový model pro následné úlohy jemného ladění. Kontrolní body můžou být zvlášť užitečné, protože můžou poskytnout snímek modelu před přeurčením. Po dokončení úlohy vyladění budete mít k dispozici tři nejnovější verze modelu, které je možné nasadit. Poslední epocha bude reprezentována vaším jemně vyladěným modelem, předchozí dvě epochy budou k dispozici jako kontrolní body.
Spuštěním příkazu kontrolních bodů seznamu můžete načíst seznam kontrolních bodů přidružených k jednotlivým úlohám jemného ladění:
Abyste mohli tento příkaz spustit, budete možná muset upgradovat klientskou knihovnu OpenAI na nejnovější verzi pip install openai --upgrade .
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Bezpečnostní vyhodnocení GPT-4, GPT-4o, GPT-4o-mini jemné ladění - Public Preview
GPT-4o, GPT-4o-mini a GPT-4 jsou naše nejpokročilejší modely, které je možné doladit podle vašich potřeb. Stejně jako u modelů Azure OpenAI obecně přináší pokročilé funkce jemně vyladěných modelů zvýšené zodpovědné problémy s AI souvisejícími se škodlivým obsahem, manipulací, chováním podobným lidem, problémy s ochranou osobních údajů a dalšími funkcemi. Další informace o rizicích, možnostech a omezeních najdete v přehledu postupů zodpovědné umělé inteligence a poznámky k transparentnosti. Abychom pomohli zmírnit rizika spojená s pokročilými jemně vyladěnými modely, implementovali jsme další kroky vyhodnocení, které pomáhají detekovat a zabránit škodlivému obsahu v trénování a výstupech jemně vyladěných modelů. Tyto kroky jsou zakotveny v filtrování obsahu služby Microsoft Responsible AI Standard a Azure OpenAI Service.
- Vyhodnocení se provádí ve vyhrazených, zákaznických, soukromých pracovních prostorech;
- Zkušební koncové body jsou ve stejné zeměpisné oblasti jako prostředek Azure OpenAI;
- Trénovací data se neukládají v souvislosti s prováděním vyhodnocení; je zachováno pouze konečné posouzení modelu (nasaditelné nebo nenasazovatelné); a
Filtry hodnocení modelů GPT-4o, GPT-4o-mini a GPT-4 jsou nastaveny na předdefinované prahové hodnoty a zákazníci je nemůžou upravovat; nejsou svázané s konfigurací filtrování vlastního obsahu, kterou jste možná vytvořili.
Vyhodnocení dat
Před zahájením trénování se vaše data vyhodnotí jako potenciálně škodlivý obsah (násilí, sexuální, nenávist a nestrannost, sebepoškozování – viz definice kategorií zde). Pokud se zjistí škodlivý obsah nad zadanou úrovní závažnosti, vaše trénovací úloha selže a zobrazí se zpráva s informacemi o kategoriích selhání.
Ukázková zpráva:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vaše trénovací data se v rámci úlohy importu dat vyhodnocují automaticky jako součást poskytování možnosti vyladění.
Pokud úloha vyladění selže kvůli detekci škodlivého obsahu v trénovacích datech, nebude se vám účtovat poplatek.
Vyhodnocení modelu
Po dokončení trénování, ale před tím, než je k dispozici jemně vyladěný model pro nasazení, se výsledný model vyhodnotí jako potenciálně škodlivé reakce pomocí předdefinovaných metrik rizik a bezpečnosti Azure. Pomocí stejného přístupu k testování, který používáme pro základní velké jazykové modely, naše funkce hodnocení simuluje konverzaci s vaším jemně vyladěným modelem, aby posoudila potenciál výstupu škodlivého obsahu, a to znovu pomocí zadaných škodlivých kategorií obsahu (násilí, sexuální, nenávist a nestrannost, sebepoškozování).
Pokud se zjistí, že se v modelu vygeneruje výstup obsahující obsah, který je zjištěn jako škodlivý nad přijatelnou rychlostí, budete informováni, že váš model není k dispozici pro nasazení, s informacemi o konkrétních kategoriích zjištěných škod:
Ukázková zpráva:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Stejně jako u vyhodnocení dat se model vyhodnocuje automaticky v rámci vaší jemně vyladěné úlohy jako součást poskytování možnosti jemného ladění. Služba zaprotokoluje pouze výsledné hodnocení (nasaditelné nebo nejde nasaditelné). Pokud nasazení jemně vyladěného modelu selže kvůli detekci škodlivého obsahu ve výstupech modelu, nebude se vám účtovat za spuštění trénování.
Nasazení jemně vyladěného modelu
Pokud je úloha jemného ladění úspěšná, hodnota fine_tuned_model proměnné v textu odpovědi se nastaví na název vlastního modelu. Váš model je teď také k dispozici ke zjišťování ze seznamu rozhraní API modelů. Nemůžete ale vydávat volání dokončení přizpůsobeného modelu, dokud nebude nasazený přizpůsobený model. Abyste ho mohli používat s voláním dokončení, musíte nasadit přizpůsobený model.
Důležité
Po nasazení přizpůsobeného modelu se nasazení odstraní, pokud nasazení zůstane neaktivní po dobu delší než patnáct (15) dnů. Nasazení přizpůsobeného modelu je neaktivní , pokud byl model nasazen před více než patnácti (15) dny a během nepřetržitého 15denního období se do něj neprovedou žádná dokončení ani dokončení chatu.
Odstranění neaktivního nasazení neodstraní ani neovlivní základní přizpůsobený model a přizpůsobený model je možné kdykoliv znovu nasadit. Jak je popsáno v cenách služby Azure OpenAI, každý přizpůsobený (vyladěný) model, který je nasazený, se každou hodinu hostuje bez ohledu na to, jestli se do modelu provádějí volání dokončení nebo dokončení chatu. Další informace o plánování a správě nákladů pomocí Azure OpenAI najdete v doprovodných materiálech v části Plánování správy nákladů na službu Azure OpenAI.
K nasazení přizpůsobeného modelu můžete použít také Azure AI Foundry nebo Azure CLI.
Poznámka:
Pro přizpůsobený model je povoleno pouze jedno nasazení. Pokud vyberete již nasazený přizpůsobený model, dojde k chybě.
Na rozdíl od předchozích příkazů sady SDK je nutné nasazení provést pomocí rozhraní API řídicí roviny, které vyžaduje samostatnou autorizaci, jinou cestu rozhraní API a jinou verzi rozhraní API.
| proměnná | Definice |
|---|---|
| token | Existuje několik způsobů, jak vygenerovat autorizační token. Nejjednodušší metodou počátečního testování je spuštění Cloud Shellu z webu Azure Portal. Potom spusťte az account get-access-token. Tento token můžete použít jako dočasný autorizační token pro testování rozhraní API. Doporučujeme ho uložit do nové proměnné prostředí. |
| předplatné | ID předplatného přidruženého prostředku Azure OpenAI. |
| resource_group | Název skupiny prostředků pro prostředek Azure OpenAI. |
| resource_name | Název prostředku Azure OpenAI. |
| model_deployment_name | Vlastní název nového jemně vyladěného nasazení modelu. Jedná se o název, na který se bude v kódu odkazovat při volání dokončení chatu. |
| fine_tuned_model | Načtěte tuto hodnotu z výsledků úlohy vyladění v předchozím kroku. Bude vypadat jako gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Tuto hodnotu budete muset přidat do deploy_data json. Případně můžete také nasadit kontrolní bod předáním ID kontrolního bodu, které se zobrazí ve formátu. ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Nasazení mezi oblastmi
Vyladění podporuje nasazení jemně vyladěného modelu do jiné oblasti, než kde byl model původně vyladěný. Můžete také nasadit do jiného předplatného nebo oblasti.
Jedinými omezeními je, že nová oblast musí také podporovat vyladění a při nasazování mezi předplatnými musí mít účet vygenerující autorizační token pro nasazení přístup ke zdrojovým i cílovým předplatným.
Níže je příklad nasazení modelu, který byl v jednom předplatném nebo oblasti do jiného vyladěný.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Pokud chcete provést nasazení mezi stejným předplatným, ale v různých oblastech byste měli jenom předplatné a skupiny prostředků, musí být stejné pro zdrojové i cílové proměnné a pouze názvy zdrojových a cílových prostředků by musely být jedinečné.
Nasazení mezi tenanty
Účet použitý ke generování přístupových tokenů s oprávněními az account get-access-token --tenant přispěvatele OpenAI ve službách Cognitive Services by měl mít ke zdrojovým i cílovým prostředkům Azure OpenAI oprávnění. Budete muset vygenerovat dva různé tokeny, jeden pro zdrojového tenanta a druhý pro cílového tenanta.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Nasazení modelu pomocí Azure CLI
Následující příklad ukazuje, jak pomocí Azure CLI nasadit přizpůsobený model. Pomocí Azure CLI musíte zadat název nasazení přizpůsobeného modelu. Další informace o tom, jak pomocí Azure CLI nasadit přizpůsobené modely, najdete v tématu az cognitiveservices account deployment.
Pokud chcete spustit tento příkaz Azure CLI v okně konzoly, musíte nahradit následující <zástupné symboly> odpovídajícími hodnotami pro váš přizpůsobený model:
| Zástupný symbol | Hodnota |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Název nebo ID vašeho předplatného Azure |
| <YOUR_RESOURCE_GROUP> | Název vaší skupiny prostředků Azure |
| <YOUR_RESOURCE_NAME> | Název vašeho prostředku Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Název, který chcete použít pro nasazení modelu. |
| <YOUR_FINE_TUNED_MODEL_ID> | Název vlastního modelu. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Použití nasazeného přizpůsobeného modelu
Po nasazení vlastního modelu ho můžete použít jako jakýkoli jiný nasazený model. Dětské hřiště v Azure AI Foundry můžete použít k experimentování s novým nasazením. Stejné parametry můžete dál používat s vlastním modelem, například temperature a max_tokens, stejně jako u jiných nasazenýchmodelůch V případě jemně vyladěných babbage-002 a davinci-002 modelů použijete hřiště Completions a rozhraní API Pro doplňování. Pro jemně vyladěné gpt-35-turbo-0613 modely budete používat chatové hřiště a rozhraní API pro dokončování chatu.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analýza přizpůsobeného modelu
Azure OpenAI připojí výsledný soubor s názvem results.csv ke každé úloze doladění po dokončení. Výsledný soubor můžete použít k analýze výkonu trénování a ověřování přizpůsobeného modelu. ID souboru výsledku je uvedené pro každý přizpůsobený model a pomocí sady Python SDK můžete načíst ID souboru a stáhnout výsledný soubor pro analýzu.
Následující příklad Pythonu načte ID souboru prvního výsledného souboru připojeného k úloze vyladění vašeho přizpůsobeného modelu a pak pomocí sady Python SDK stáhne soubor do pracovního adresáře k analýze.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Výsledný soubor je soubor CSV, který obsahuje řádek záhlaví a řádek pro každý krok trénování prováděný úlohou jemného ladění. Výsledný soubor obsahuje následující sloupce:
| Název sloupce | Popis |
|---|---|
step |
Počet kroků trénování. Trénovací krok představuje jeden průchod, dopředu a dozadu v dávce trénovacích dat. |
train_loss |
Ztráta pro trénovací dávku. |
train_mean_token_accuracy |
Procento tokenů v trénovací dávce správně predikované modelem. Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Ztráta pro ověřovací dávku. |
validation_mean_token_accuracy |
Procento tokenů v dávce ověřování správně predikované modelem Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Ztráta ověření vypočítaná na konci každé epochy. Když trénování půjde dobře, ztráta by se měla snížit. |
full_valid_mean_token_accuracy |
Platná průměrná přesnost tokenu vypočítaná na konci každé epochy. Při dobrém trénování by se měla zvýšit přesnost tokenů. |
Data v souboru results.csv můžete zobrazit také jako grafy na portálu Azure AI Foundry. Vyberte odkaz pro trénovaný model a zobrazí se tři grafy: ztráta, střední přesnost tokenu a přesnost tokenů. Pokud jste zadali ověřovací data, zobrazí se obě datové sady ve stejném grafu.
Vyhledejte ztrátu, abyste v průběhu času snížili a zvýšili přesnost. Pokud zjistíte rozdíly mezi trénovacími a ověřovacími daty, které můžou znamenat, že přeurčujete. Vyzkoušejte trénování s menším počtem epoch nebo menší násobitelem rychlosti učení.
Vyčištění nasazení, přizpůsobených modelů a trénovacích souborů
Až budete hotovi s vlastním modelem, můžete nasazení a model odstranit. V případě potřeby můžete také odstranit trénovací a ověřovací soubory, které jste nahráli do služby.
Odstranění nasazení modelu
Důležité
Po nasazení přizpůsobeného modelu se nasazení odstraní, pokud nasazení zůstane neaktivní po dobu delší než patnáct (15) dnů. Nasazení přizpůsobeného modelu je neaktivní , pokud byl model nasazen před více než patnácti (15) dny a během nepřetržitého 15denního období se do něj neprovedou žádná dokončení ani dokončení chatu.
Odstranění neaktivního nasazení neodstraní ani neovlivní základní přizpůsobený model a přizpůsobený model je možné kdykoliv znovu nasadit. Jak je popsáno v cenách služby Azure OpenAI, každý přizpůsobený (vyladěný) model, který je nasazený, se každou hodinu hostuje bez ohledu na to, jestli se do modelu provádějí volání dokončení nebo dokončení chatu. Další informace o plánování a správě nákladů pomocí Azure OpenAI najdete v doprovodných materiálech v části Plánování správy nákladů na službu Azure OpenAI.
Nasazení vlastního modelu můžete odstranit pomocí různých metod:
- Azure AI Foundry
- Azure CLI
Odstranění přizpůsobeného modelu
Podobně můžete k odstranění přizpůsobeného modelu použít různé metody:
Poznámka:
Pokud má existující nasazení, nemůžete odstranit přizpůsobený model. Před odstraněním přizpůsobeného modelu musíte nejprve odstranit nasazení modelu.
Odstranění trénovacích souborů
Volitelně můžete odstranit trénovací a ověřovací soubory, které jste nahráli pro trénování, a výsledné soubory vygenerované během trénování z vašeho předplatného Azure OpenAI. K odstranění trénovacích, ověřovacích a výsledných souborů můžete použít následující metody:
- Azure AI Foundry
- Rozhraní REST API
- Sada Python SDK
Následující příklad Pythonu používá sadu Python SDK k odstranění trénovacích, ověřovacích a výsledných souborů pro váš přizpůsobený model:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Průběžné jemné ladění
Jakmile vytvoříte jemně vyladěný model, možná budete chtít model v průběhu času dále upřesňovat prostřednictvím dalšího vyladění. Průběžné doladění je iterativní proces výběru již vyladěného modelu jako základního modelu a jeho dalšího vyladění v nových sadách trénovacích příkladů.
K vyladění modelu, který jste dříve vyladili, byste použili stejný postup, jak je popsáno v části Vytvoření přizpůsobeného modelu , ale místo zadání názvu obecného základního modelu byste zadali ID modelu, který už je vyladěný. VYLADĚNÉ ID modelu vypadá takto: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Doporučujeme také přidat suffix parametr, aby bylo snazší rozlišovat mezi různými iteracemi vašeho jemně vyladěného modelu.
suffix vezme řetězec a nastaví se k identifikaci jemně vyladěného modelu. S rozhraním OpenAI Python API se podporuje řetězec o velikosti až 18 znaků, který se přidá do vašeho jemně vyladěného názvu modelu.
Pokud si nejste jisti ID existujícího jemně vyladěného modelu, najdete tyto informace na stránce Modely v Azure AI Foundry nebo můžete pomocí rozhraní REST API vygenerovat seznam modelů pro daný prostředek Azure OpenAI.
Požadavky
- Přečtěte si průvodce vyladěním možností Kdy používat Azure OpenAI.
- Předplatné Azure. Vytvořte si ho zdarma.
- Prostředek Azure OpenAI. Další informace najdete v tématu Vytvoření prostředku a nasazení modelu pomocí Azure OpenAI.
- Vyladění přístupu vyžaduje přispěvatel OpenAI služeb Cognitive Services.
- Pokud ještě nemáte přístup k zobrazení kvóty a nasazujete modely na portálu Azure AI Foundry, budete vyžadovat další oprávnění.
Modely
Následující modely podporují vyladění:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* Vyladění tohoto modelu je aktuálně ve verzi Public Preview.
Nebo můžete doladit dříve vyladěný model formátovaný jako base-model.ft-{jobid}.
Na stránce modelů zkontrolujte, které oblasti aktuálně podporují vyladění.
Kontrola pracovního postupu pro rozhraní REST API
Chvíli si projděte vyladěný pracovní postup pro používání rozhraní REST APIS a Pythonu s Azure OpenAI:
- Připravte trénovací a ověřovací data.
- Vyberte základní model.
- Nahrajte trénovací data.
- Trénujte nový přizpůsobený model.
- Zkontrolujte stav přizpůsobeného modelu.
- Nasaďte přizpůsobený model pro použití.
- Použijte přizpůsobený model.
- Volitelně můžete analyzovat přizpůsobený model tak, aby odpovídal výkonu a přizpůsobení.
Příprava trénovacích a ověřovacích dat
Vaše cvičební data a sady ověřovacích dat se skládají ze vstupních a výstupních příkladů toho, jak se má model provádět.
Různé typy modelů vyžadují jiný formát trénovacích dat.
Použitá trénovací a ověřovací data musí být naformátovaná jako dokument JSON Lines (JSONL). U gpt-35-turbo-0613 a dalších souvisejících modelů musí být datová sada vyladěná v konverzačním formátu, který používá rozhraní API pro dokončování chatu.
Pokud chcete podrobný postup vyladění gpt-35-turbo-0613 , projděte si kurz podrobného ladění Azure OpenAI.
Příklad formátu souboru
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formát souboru chatu s vícenásobným převodem
Podporuje se také několik otočení konverzace v jednom řádku trénovacího souboru jsonl. Pokud chcete přeskočit jemné ladění konkrétních zpráv pomocníka, přidejte dvojici volitelných weight hodnot klíče. Aktuálně weight je možné nastavit hodnotu 0 nebo 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Dokončování chatu se zrakem
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Kromě formátu JSONL musí být trénovací a ověřovací datové soubory kódované v kódování UTF-8 a obsahovat značku pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Vytvoření trénovacích a ověřovacích datových sad
Čím více trénovacích příkladů máte, tím lépe. Úlohy jemného ladění nebudou pokračovat bez alespoň 10 příkladů trénování, ale takové malé číslo nestačí k výrazně ovlivnění odpovědí modelu. Osvědčeným postupem je poskytnout stovky příkladů trénování, pokud ne tisíce, aby byly úspěšné.
Obecně platí, že zdvojnásobení velikosti datové sady může vést k lineárnímu zvýšení kvality modelu. Mějte ale na paměti, že příklady nízké kvality můžou negativně ovlivnit výkon. Pokud model vytrénujete na velké množství interních dat, aniž byste nejprve datovou sadu vyřezávali pouze pro nejvýkonnější příklady kvality, mohli byste skončit s modelem, který funguje mnohem hůře, než se čekalo.
Výběr základního modelu
Prvním krokem při vytváření vlastního modelu je zvolit základní model. Podokno Základní model umožňuje zvolit základní model, který se má použít pro vlastní model. Vaše volba ovlivňuje výkon i náklady modelu.
V rozevíracím seznamu Základní typ modelu vyberte základní model a pokračujte výběrem možnosti Další .
Vlastní model můžete vytvořit z některého z následujících dostupných základních modelů:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613) -
gpt-4o(2024-08-06) -
gpt-4o-mini(2023-07-18)
Nebo můžete doladit dříve vyladěný model formátovaný jako base-model.ft-{jobid}.
Další informace o našich základních modelech, které je možné doladit, najdete v tématu Modely.
Nahrání trénovacích dat
Dalším krokem je zvolit stávající připravená trénovací data nebo nahrát nová připravená trénovací data, která se mají použít při vyladění modelu. Po přípravě trénovacích dat můžete soubory nahrát do služby. Trénovací data můžete nahrát dvěma způsoby:
U velkých datových souborů doporučujeme importovat z úložiště objektů blob v Azure. Velké soubory se můžou stát nestabilní, když se nahrají prostřednictvím formulářů s více částmi, protože požadavky jsou atomické a nejde je opakovat ani obnovit. Další informace o službě Azure Blob Storage najdete v tématu Co je Azure Blob Storage?
Poznámka:
Trénovací datové soubory musí být formátované jako soubory JSONL zakódované v UTF-8 pomocí značky pořadí bajtů (BOM). Soubor musí mít velikost menší než 512 MB.
Nahrání trénovacích dat
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Nahrání ověřovacích dat
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Vytvoření přizpůsobeného modelu
Po nahrání trénovacích a ověřovacích souborů můžete začít úlohu vyladění. Následující kód ukazuje příklad vytvoření nové jemně vyladěné úlohy pomocí rozhraní REST API.
V tomto příkladu předáváme také počáteční parametr. Počáteční hodnota řídí reprodukovatelnost úlohy. Předání stejných počátečních hodnot a parametrů úlohy by mělo vést ke stejným výsledkům, ale může se ve výjimečných případech lišit. Pokud není zadaná počáteční hodnota, vygeneruje se za vás.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Můžete také předat další volitelné parametry, jako jsou hyperparametry , abyste měli větší kontrolu nad procesem jemného ladění. Pro počáteční trénování doporučujeme použít automatické výchozí hodnoty, které jsou k dispozici bez zadání těchto parametrů.
Aktuální podporované hyperparametry pro vyladění jsou:
| Název | Typ | Popis |
|---|---|---|
batch_size |
integer | Velikost dávky, která se má použít pro trénování. Velikost dávky je počet trénovacích příkladů, které se používají k trénování jednoho dopředu a dozadu. Obecně jsme zjistili, že větší velikosti dávek obvykle fungují lépe u větších datových sad. Výchozí hodnota a maximální hodnota této vlastnosti jsou specifické pro základní model. Větší velikost dávky znamená, že parametry modelu se aktualizují méně často, ale s nižší odchylkou. |
learning_rate_multiplier |
Číslo | Násobitel rychlosti učení, který se má použít pro trénování. Míra doladění je původní míra učení používaná pro předtrénování vynásobenou touto hodnotou. Větší rychlost učení obvykle funguje lépe s většími velikostmi dávek. Doporučujeme experimentovat s hodnotami v rozsahu 0,02 až 0,2, abyste zjistili, co vede k dosažení nejlepších výsledků. Menší rychlost učení může být užitečná, abyste se vyhnuli přeurčení. |
n_epochs |
integer | Počet epoch pro trénování modelu. Epocha odkazuje na jeden celý cyklus prostřednictvím trénovací datové sady. |
seed |
integer | Počáteční hodnota řídí reprodukovatelnost úlohy. Předání stejných počátečních parametrů a parametrů úlohy by mělo vést ke stejným výsledkům, ale ve výjimečných případech se může lišit. Pokud není zadaná počáteční sada, vygeneruje se za vás. |
Kontrola stavu přizpůsobeného modelu
Po spuštění úlohy vyladění může dokončení nějakou dobu trvat. Vaše úloha může být zařazena do fronty za jinými úlohami v systému. Trénování modelu může trvat minuty nebo hodiny v závislosti na velikosti modelu a datové sady. Následující příklad používá rozhraní REST API ke kontrole stavu úlohy jemného ladění. Příklad načte informace o vaší úloze pomocí ID úlohy vrácené z předchozího příkladu:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Vypsání událostí jemného ladění
Prozkoumání jednotlivých událostí vyladění, které byly generovány během trénování:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Kontrolní body
Po dokončení každé epochy trénování se vygeneruje kontrolní bod. Kontrolní bod je plně funkční verze modelu, která se dá nasadit i použít jako cílový model pro následné úlohy jemného ladění. Kontrolní body můžou být zvlášť užitečné, protože můžou poskytnout snímek modelu před přeurčením. Po dokončení úlohy vyladění budete mít k dispozici tři nejnovější verze modelu, které je možné nasadit. Poslední epocha bude reprezentována vaším jemně vyladěným modelem, předchozí dvě epochy budou k dispozici jako kontrolní body.
Spuštěním příkazu kontrolních bodů seznamu můžete načíst seznam kontrolních bodů přidružených k jednotlivým úlohám jemného ladění:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Bezpečnostní vyhodnocení GPT-4, GPT-4o, GPT-4o-mini jemné ladění - Public Preview
GPT-4o, GPT-4o-mini a GPT-4 jsou naše nejpokročilejší modely, které je možné doladit podle vašich potřeb. Stejně jako u modelů Azure OpenAI obecně přináší pokročilé funkce jemně vyladěných modelů zvýšené zodpovědné problémy s AI souvisejícími se škodlivým obsahem, manipulací, chováním podobným lidem, problémy s ochranou osobních údajů a dalšími funkcemi. Další informace o rizicích, možnostech a omezeních najdete v přehledu postupů zodpovědné umělé inteligence a poznámky k transparentnosti. Abychom pomohli zmírnit rizika spojená s pokročilými jemně vyladěnými modely, implementovali jsme další kroky vyhodnocení, které pomáhají detekovat a zabránit škodlivému obsahu v trénování a výstupech jemně vyladěných modelů. Tyto kroky jsou zakotveny v filtrování obsahu služby Microsoft Responsible AI Standard a Azure OpenAI Service.
- Vyhodnocení se provádí ve vyhrazených, zákaznických, soukromých pracovních prostorech;
- Zkušební koncové body jsou ve stejné zeměpisné oblasti jako prostředek Azure OpenAI;
- Trénovací data se neukládají v souvislosti s prováděním vyhodnocení; je zachováno pouze konečné posouzení modelu (nasaditelné nebo nenasazovatelné); a
Filtry hodnocení modelů GPT-4o, GPT-4o-mini a GPT-4 jsou nastaveny na předdefinované prahové hodnoty a zákazníci je nemůžou upravovat; nejsou svázané s konfigurací filtrování vlastního obsahu, kterou jste možná vytvořili.
Vyhodnocení dat
Před zahájením trénování se vaše data vyhodnotí jako potenciálně škodlivý obsah (násilí, sexuální, nenávist a nestrannost, sebepoškozování – viz definice kategorií zde). Pokud se zjistí škodlivý obsah nad zadanou úrovní závažnosti, vaše trénovací úloha selže a zobrazí se zpráva s informacemi o kategoriích selhání.
Ukázková zpráva:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Vaše trénovací data se v rámci úlohy importu dat vyhodnocují automaticky jako součást poskytování možnosti vyladění.
Pokud úloha vyladění selže kvůli detekci škodlivého obsahu v trénovacích datech, nebude se vám účtovat poplatek.
Vyhodnocení modelu
Po dokončení trénování, ale před tím, než je k dispozici jemně vyladěný model pro nasazení, se výsledný model vyhodnotí jako potenciálně škodlivé reakce pomocí předdefinovaných metrik rizik a bezpečnosti Azure. Pomocí stejného přístupu k testování, který používáme pro základní velké jazykové modely, naše funkce hodnocení simuluje konverzaci s vaším jemně vyladěným modelem, aby posoudila potenciál výstupu škodlivého obsahu, a to znovu pomocí zadaných škodlivých kategorií obsahu (násilí, sexuální, nenávist a nestrannost, sebepoškozování).
Pokud se zjistí, že se v modelu vygeneruje výstup obsahující obsah, který je zjištěn jako škodlivý nad přijatelnou rychlostí, budete informováni, že váš model není k dispozici pro nasazení, s informacemi o konkrétních kategoriích zjištěných škod:
Ukázková zpráva:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Stejně jako u vyhodnocení dat se model vyhodnocuje automaticky v rámci vaší jemně vyladěné úlohy jako součást poskytování možnosti jemného ladění. Služba zaprotokoluje pouze výsledné hodnocení (nasaditelné nebo nejde nasaditelné). Pokud nasazení jemně vyladěného modelu selže kvůli detekci škodlivého obsahu ve výstupech modelu, nebude se vám účtovat za spuštění trénování.
Nasazení jemně vyladěného modelu
Důležité
Po nasazení přizpůsobeného modelu se nasazení odstraní, pokud nasazení zůstane neaktivní po dobu delší než patnáct (15) dnů. Nasazení přizpůsobeného modelu je neaktivní , pokud byl model nasazen před více než patnácti (15) dny a během nepřetržitého 15denního období se do něj neprovedou žádná dokončení ani dokončení chatu.
Odstranění neaktivního nasazení neodstraní ani neovlivní základní přizpůsobený model a přizpůsobený model je možné kdykoliv znovu nasadit. Jak je popsáno v cenách služby Azure OpenAI, každý přizpůsobený (vyladěný) model, který je nasazený, se každou hodinu hostuje bez ohledu na to, jestli se do modelu provádějí volání dokončení nebo dokončení chatu. Další informace o plánování a správě nákladů pomocí Azure OpenAI najdete v doprovodných materiálech v části Plánování správy nákladů na službu Azure OpenAI.
Následující příklad Pythonu ukazuje, jak pomocí rozhraní REST API vytvořit nasazení modelu pro váš přizpůsobený model. Rozhraní REST API vygeneruje název nasazení přizpůsobeného modelu.
| proměnná | Definice |
|---|---|
| token | Existuje několik způsobů, jak vygenerovat autorizační token. Nejjednodušší metodou počátečního testování je spuštění Cloud Shellu z webu Azure Portal. Potom spusťte az account get-access-token. Tento token můžete použít jako dočasný autorizační token pro testování rozhraní API. Doporučujeme ho uložit do nové proměnné prostředí. |
| předplatné | ID předplatného přidruženého prostředku Azure OpenAI. |
| resource_group | Název skupiny prostředků pro prostředek Azure OpenAI. |
| resource_name | Název prostředku Azure OpenAI. |
| model_deployment_name | Vlastní název nového jemně vyladěného nasazení modelu. Jedná se o název, na který se bude v kódu odkazovat při volání dokončení chatu. |
| fine_tuned_model | Načtěte tuto hodnotu z výsledků úlohy vyladění v předchozím kroku. Bude vypadat jako gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83. Tuto hodnotu budete muset přidat do deploy_data json. Případně můžete také nasadit kontrolní bod předáním ID kontrolního bodu, které se zobrazí ve formátu. ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Nasazení mezi oblastmi
Vyladění podporuje nasazení jemně vyladěného modelu do jiné oblasti, než kde byl model původně vyladěný. Můžete také nasadit do jiného předplatného nebo oblasti.
Jedinými omezeními je, že nová oblast musí také podporovat vyladění a při nasazování mezi předplatnými musí mít účet vygenerující autorizační token pro nasazení přístup ke zdrojovým i cílovým předplatným.
Níže je příklad nasazení modelu, který byl v jednom předplatném nebo oblasti do jiného vyladěný.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Pokud chcete provést nasazení mezi stejným předplatným, ale různými oblastmi, měli byste jenom předplatné a skupiny prostředků stejné pro zdrojové i cílové proměnné a pouze názvy zdrojových a cílových prostředků by musely být jedinečné.
Nasazení mezi tenanty
Účet použitý ke generování přístupových tokenů s oprávněními az account get-access-token --tenant přispěvatele OpenAI ve službách Cognitive Services by měl mít ke zdrojovým i cílovým prostředkům Azure OpenAI oprávnění. Budete muset vygenerovat dva různé tokeny, jeden pro zdrojového tenanta a druhý pro cílového tenanta.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Nasazení modelu pomocí Azure CLI
Následující příklad ukazuje, jak pomocí Azure CLI nasadit přizpůsobený model. Pomocí Azure CLI musíte zadat název nasazení přizpůsobeného modelu. Další informace o tom, jak pomocí Azure CLI nasadit přizpůsobené modely, najdete v tématu az cognitiveservices account deployment.
Pokud chcete spustit tento příkaz Azure CLI v okně konzoly, musíte nahradit následující <zástupné symboly> odpovídajícími hodnotami pro váš přizpůsobený model:
| Zástupný symbol | Hodnota |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | Název nebo ID vašeho předplatného Azure |
| <YOUR_RESOURCE_GROUP> | Název vaší skupiny prostředků Azure |
| <YOUR_RESOURCE_NAME> | Název vašeho prostředku Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | Název, který chcete použít pro nasazení modelu. |
| <YOUR_FINE_TUNED_MODEL_ID> | Název vlastního modelu. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Použití nasazeného přizpůsobeného modelu
Po nasazení vlastního modelu ho můžete použít jako jakýkoli jiný nasazený model. Dětské hřiště v Azure AI Foundry můžete použít k experimentování s novým nasazením. Stejné parametry můžete dál používat s vlastním modelem, například temperature a max_tokens, stejně jako u jiných nasazenýchmodelůch V případě jemně vyladěných babbage-002 a davinci-002 modelů použijete hřiště Completions a rozhraní API Pro doplňování. Pro jemně vyladěné gpt-35-turbo-0613 modely použijete chatové hřiště a rozhraní API pro dokončování chatu.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analýza přizpůsobeného modelu
Azure OpenAI připojí výsledný soubor s názvem results.csv ke každé úloze doladění po dokončení. Výsledný soubor můžete použít k analýze výkonu trénování a ověřování přizpůsobeného modelu. ID souboru výsledku je uvedené pro každý přizpůsobený model a pomocí rozhraní REST API můžete načíst ID souboru a stáhnout výsledný soubor pro analýzu.
Následující příklad Pythonu pomocí rozhraní REST API načte ID souboru prvního výsledného souboru připojeného k úloze vyladění vlastního modelu a pak stáhne soubor do pracovního adresáře pro účely analýzy.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Výsledný soubor je soubor CSV, který obsahuje řádek záhlaví a řádek pro každý krok trénování prováděný úlohou jemného ladění. Výsledný soubor obsahuje následující sloupce:
| Název sloupce | Popis |
|---|---|
step |
Počet kroků trénování. Trénovací krok představuje jeden průchod, dopředu a dozadu v dávce trénovacích dat. |
train_loss |
Ztráta pro trénovací dávku. |
train_mean_token_accuracy |
Procento tokenů v trénovací dávce správně predikované modelem. Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Ztráta pro ověřovací dávku. |
validation_mean_token_accuracy |
Procento tokenů v dávce ověřování správně predikované modelem Pokud je například velikost dávky nastavena na hodnotu 3 a data obsahují dokončení [[1, 2], [0, 5], [4, 2]], je tato hodnota nastavena na 0,83 (5 z 6), pokud model predikoval [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Ztráta ověření vypočítaná na konci každé epochy. Když trénování půjde dobře, ztráta by se měla snížit. |
full_valid_mean_token_accuracy |
Platná průměrná přesnost tokenu vypočítaná na konci každé epochy. Při dobrém trénování by se měla zvýšit přesnost tokenů. |
Data v souboru results.csv můžete zobrazit také jako grafy na portálu Azure AI Foundry. Vyberte odkaz pro trénovaný model a zobrazí se tři grafy: ztráta, střední přesnost tokenu a přesnost tokenů. Pokud jste zadali ověřovací data, zobrazí se obě datové sady ve stejném grafu.
Vyhledejte ztrátu, abyste v průběhu času snížili a zvýšili přesnost. Pokud zjistíte rozdíly mezi trénovacími a ověřovacími daty, které můžou znamenat, že přeurčujete. Vyzkoušejte trénování s menším počtem epoch nebo menší násobitelem rychlosti učení.
Vyčištění nasazení, přizpůsobených modelů a trénovacích souborů
Až budete hotovi s vlastním modelem, můžete nasazení a model odstranit. V případě potřeby můžete také odstranit trénovací a ověřovací soubory, které jste nahráli do služby.
Odstranění nasazení modelu
Nasazení vlastního modelu můžete odstranit pomocí různých metod:
- Azure AI Foundry
- Azure CLI
Odstranění přizpůsobeného modelu
Podobně můžete k odstranění přizpůsobeného modelu použít různé metody:
Poznámka:
Pokud má existující nasazení, nemůžete odstranit přizpůsobený model. Před odstraněním přizpůsobeného modelu musíte nejprve odstranit nasazení modelu.
Odstranění trénovacích souborů
Volitelně můžete odstranit trénovací a ověřovací soubory, které jste nahráli pro trénování, a výsledné soubory vygenerované během trénování z vašeho předplatného Azure OpenAI. K odstranění trénovacích, ověřovacích a výsledných souborů můžete použít následující metody:
Průběžné jemné ladění
Jakmile vytvoříte jemně vyladěný model, možná budete chtít model v průběhu času dále upřesňovat prostřednictvím dalšího vyladění. Průběžné doladění je iterativní proces výběru již vyladěného modelu jako základního modelu a jeho dalšího vyladění v nových sadách trénovacích příkladů.
K vyladění modelu, který jste dříve doladili, byste použili stejný postup, jak je popsáno v části Vytvoření přizpůsobeného modelu , ale místo zadání názvu obecného základního modelu byste zadali ID již vyladěného modelu. VYLADĚNÉ ID modelu vypadá takto: gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Doporučujeme také přidat suffix parametr, aby bylo snazší rozlišovat mezi různými iteracemi vašeho jemně vyladěného modelu.
suffix vezme řetězec a nastaví se k identifikaci jemně vyladěného modelu. Přípona může obsahovat až 40 znaků (a-z, A-Z, 0-9 a _), které se přidají do vašeho jemně vyladěného názvu modelu.
Pokud si nejste jisti ID jemně vyladěného modelu, najdete tyto informace na stránce Modely azure AI Foundry nebo můžete vygenerovat seznam modelů pro daný prostředek Azure OpenAI pomocí rozhraní REST API.
Global Standard (Preview)
Vyladění Azure OpenAI podporuje globální standardní nasazení v oblastech USA – východ 2, USA – středosever a Švédsko – střed pro:
gpt-4o-mini-2024-07-18-
gpt-4o-2024-08-06(Nová nasazení nejsou k dispozici do ledna 2025)
Globální standardní jemně vyladěná nasazení nabízejí úsporu nákladů, ale vlastní hmotnosti modelů se můžou dočasně ukládat mimo geografickou oblast vašeho prostředku Azure OpenAI.

Globální standardní nasazení pro vyladění v současné době nepodporují zpracování obrazu a strukturované výstupy.
Vyladění obrazu
Jemné ladění je také možné s obrázky v souborech JSONL. Stejně jako můžete do dokončení chatu odeslat jeden nebo mnoho vstupů obrázků, můžete do trénovacích dat zahrnout stejné typy zpráv. Obrázky je možné poskytnout buď jako veřejně přístupné adresy URL, nebo identifikátory URI dat obsahující obrázky kódované podle base64.
Požadavky na datovou sadu obrázků
- Trénovací soubor může obsahovat maximálně 50 000 příkladů, které obsahují obrázky (včetně textových příkladů).
- Každý příklad může mít maximálně 64 obrázků.
- Každý obrázek může mít maximálně 10 MB.
Formát
Obrázky musí být:
- JPEG
- PNG
- WEBP
Obrázky musí být v režimu RGB nebo RGBA.
Obrázky nelze zahrnout jako výstup ze zpráv s rolí asistenta.
Zásady con režim stanu ration
Před trénováním zkontrolujeme vaše obrázky, abychom měli jistotu, že jsou v souladu s našimi zásadami transparentnosti používání. To může při ověřování souborů zavádět latenci před zahájením ladění.
Obrázky, které obsahují následující, budou z vaší datové sady vyloučeny a nebudou použity pro trénování:
- Lidé
- Tváře
- CAPTCHA
Důležité
Pro proces jemného ladění obrazu pro screening tváří: Na obrazovce pro tváře nebo osoby přeskočíme tyto obrázky z trénování modelu. Funkce screeningu využívá detekci tváří bez identifikace tváře, což znamená, že nevytváříme šablony obličeje ani změříme konkrétní geometrii obličeje a technologie použitá na obrazovce tváří nedokáže jedinečně identifikovat jednotlivce. Další informace o datech a ochraně osobních údajů pro rozpoznávání tváře najdete v tématu Data a ochrana osobních údajů pro rozpoznávání tváře – Služby Azure AI | Microsoft Learn.
Ukládání do mezipaměti výzvy
Vyladění Azure OpenAI podporuje ukládání výzev do mezipaměti s vybranými modely. Ukládání do mezipaměti umožňuje snížit celkovou latenci požadavků a náklady na delší výzvy, které mají na začátku výzvy stejný obsah. Další informace o ukládání výzev do mezipaměti najdete v tématu Začínáme s ukládáním do mezipaměti s výzvou.
Optimalizace přímých předvoleb (DPO) (Preview)
Optimalizace přímých předvoleb (DPO) je technika zarovnání pro velké jazykové modely, která se používá k úpravě hmotností modelu na základě lidských preferencí. Liší se od učení na základě zpětné vazby člověka (RLHF), že nevyžaduje přizpůsobení modelu odměny a používá jednodušší binární předvolby dat pro trénování. Je to výpočetně lehčí hmotnost a rychlejší než RLHF, zatímco stejně efektivní při zarovnání.
Proč je DPO užitečný?
DPO je zvlášť užitečné ve scénářích, kdy neexistuje žádná jasná správná odpověď a subjektivní prvky, jako je tón, styl nebo konkrétní předvolby obsahu, jsou důležité. Tento přístup také umožňuje modelu učit se z obou pozitivních příkladů (co se považuje za správné nebo ideální) a negativních příkladů (co je méně žádoucí nebo nesprávné).
U DPO se předpokládá, že se jedná o techniku, která zákazníkům usnadní generování vysoce kvalitních trénovacích datových sad. I když se mnoho zákazníků snaží generovat dostatečné velké datové sady pro vyladění pod dohledem, často mají data předvoleb shromážděná na základě uživatelských protokolů, testů A/B nebo menších ručních poznámek.
Formát datové sady optimalizace přímých předvoleb
Soubory optimalizace přímých předvoleb mají jiný formát než vyladění pod dohledem. Zákazníci poskytují "konverzaci" obsahující systémovou zprávu a počáteční uživatelskou zprávu a pak "dokončení" s spárovanými daty předvoleb. Uživatelé můžou zadat pouze dvě dokončení.
Tři pole nejvyšší úrovně: inputpreferred_output anon_preferred_output
- Každý prvek v preferred_output/non_preferred_output musí obsahovat alespoň jednu zprávu pomocníka.
- Každý prvek v preferred_output/non_preferred_output může mít jenom role (pomocník, nástroj).
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Trénovací datové sady musí být ve jsonl formátu:
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Podpora modelu optimalizace přímých předvoleb
-
gpt-4o-2024-08-06podporuje optimalizaci přímých předvoleb v příslušných oblastech vyladění. Nejnovější dostupnost oblastí se aktualizuje na stránce modelů.
Uživatelé můžou používat vyladění předvoleb u základních modelů a také modely, které už byly vyladěné pomocí jemného ladění pod dohledem, pokud se jedná o podporovaný model nebo verzi.
Jak používat optimalizaci přímých předvoleb?

- Připravte
jsonldatové sady ve formátu předvoleb. - Vyberte model a pak vyberte metodu optimalizace přímých předvoleb přizpůsobení.
- Nahrání datových sad – trénování a ověření Podle potřeby si prohlédněte náhled.
- Vyberte hyperparametry, výchozí hodnoty se doporučují pro počáteční experimentování.
- Zkontrolujte výběry a vytvořte úlohu jemného ladění.
Řešení problému
Návody povolit jemné ladění?
Abyste mohli úspěšně získat přístup k jemnému ladění, potřebujete přiřazeného přispěvatele OpenAI služeb Cognitive Services. I někdo s oprávněními správce služeb vysoké úrovně by tento účet stále potřeboval explicitně nastavit, aby mohl získat přístup k jemnému ladění. Další informace najdete v pokynech k řízení přístupu na základě role.
Proč se mi nepodařilo nahrát?
Pokud nahrávání souboru na portálu Azure AI Foundry selže, můžete zobrazit chybovou zprávu v části Datové soubory na portálu Azure AI Foundry. Najeďte myší na místo s textem "error" (pod sloupcem stavu) a zobrazí se vysvětlení selhání.

Zdá se, že můj vyladěný model se nezlepšil.
Chybějící systémová zpráva: Při vyladění musíte zadat systémovou zprávu. Při použití jemně vyladěného modelu budete chtít poskytnout stejnou systémovou zprávu. Pokud zadáte jinou systémovou zprávu, může se zobrazit jiné výsledky než to, co jste vyladili.
Nedostatek dat: zatímco 10 je minimum pro spuštění kanálu, potřebujete stovky až tisíce datových bodů, abyste model naučili novou dovednost. Příliš málo datových bodů riskuje přeurčení a špatnou generalizaci. Váš jemně vyladěný model může s trénovacími daty fungovat dobře, ale špatně na jiných datech, protože si místo vzorů učení zapamatoval příklady trénování. Nejlepších výsledků dosáhnete, když naplánujete přípravu datové sady se stovkami nebo tisíci datových bodů.
Špatná data: Špatně kurátorovaná nebo nerepresentní datová sada vytvoří model s nízkou kvalitou. Váš model se může naučit nepřesné nebo zkreslené vzory z vaší datové sady. Pokud například trénujete chatovacího robota pro služby zákazníkům, ale poskytujete pouze trénovací data pro jeden scénář (např. vrácení položky), nebude vědět, jak reagovat na jiné scénáře. Nebo pokud jsou trénovací data špatná (obsahují nesprávné odpovědi), váš model se naučí poskytovat nesprávné výsledky.
Vyladění s využitím zraku
Co dělat, když se obrázky přeskočí
Vaše obrázky se můžou přeskočit z následujících důvodů:
- obsahuje CAPTCHA
- obsahuje lidi
- obsahuje tváře.
Odeberte image. Prozatím nemůžeme doladit modely obrázky obsahujícími tyto entity.
Běžné problémy
| Problém | Důvod nebo řešení |
|---|---|
| Obrázky se přeskočily | Obrázky se dají přeskočit z následujících důvodů: obsahuje CAPTCHA, lidi nebo tváře. Odeberte image. Prozatím nemůžeme doladit modely obrázky obsahujícími tyto entity. |
| Nepřístupná adresa URL | Zkontrolujte, jestli je adresa URL obrázku veřejně přístupná. |
| Obrázek je příliš velký | Zkontrolujte, že vaše obrázky spadají do našich limitů velikosti datové sady. |
| Neplatný formát obrázku | Zkontrolujte, že vaše obrázky spadají do formátu naší datové sady. |
Jak nahrát velké soubory
Vaše trénovací soubory můžou být poměrně velké. Soubory o velikosti až 8 GB můžete nahrávat v několika částech pomocí rozhraní API pro nahrávání, nikoli pomocí rozhraní API pro soubory, které umožňuje nahrávání souborů až do 512 MB.
Snížení nákladů na školení
Pokud nastavíte parametr podrobností obrázku na minimum, změní se velikost obrázku na 512 o 512 pixelů a bude reprezentována pouze 85 tokeny bez ohledu na jeho velikost. Tím se sníží náklady na trénování.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Další důležité informace o jemném ladění zraku
Pokud chcete řídit věrnost porozumění obrázkům, nastavte parametr image_url podrobností na lowhodnotu , highnebo auto pro každý obrázek. To ovlivní také počet tokenů na image, které model uvidí během trénování a ovlivní náklady na trénování.
Další kroky
- Prozkoumejte možnosti jemného ladění v kurzu vyladění Azure OpenAI.
- Kontrola regionální dostupnosti modelu vyladění
- Další informace o kvótách Azure OpenAI