Rychlý start: Rozpoznávání a převod řeči na text
Důležité
Některé funkce popsané v tomto článku můžou být dostupné jenom ve verzi Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
V tomto rychlém startu zkusíte řeč v reálném čase na text v Azure AI Studiu.
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Některé funkce služeb AI se dají vyzkoušet v AI Studiu. Pokud chcete získat přístup ke všem funkcím popsaným v tomto článku, musíte připojit služby AI k centru v AI Studiu.
Vyzkoušení řeči na text v reálném čase
V AI Studiu přejděte na domovskou stránku a v levém podokně vyberte Služby AI.
V seznamu služeb AI vyberte Službu Speech .
Vyberte řeč v reálném čase na text.

V části Vyzkoušet vyberte připojení služeb AI vašeho centra. Další informace o připojeních služeb AI najdete v tématu Připojení služeb AI k centru v AI Studiu.
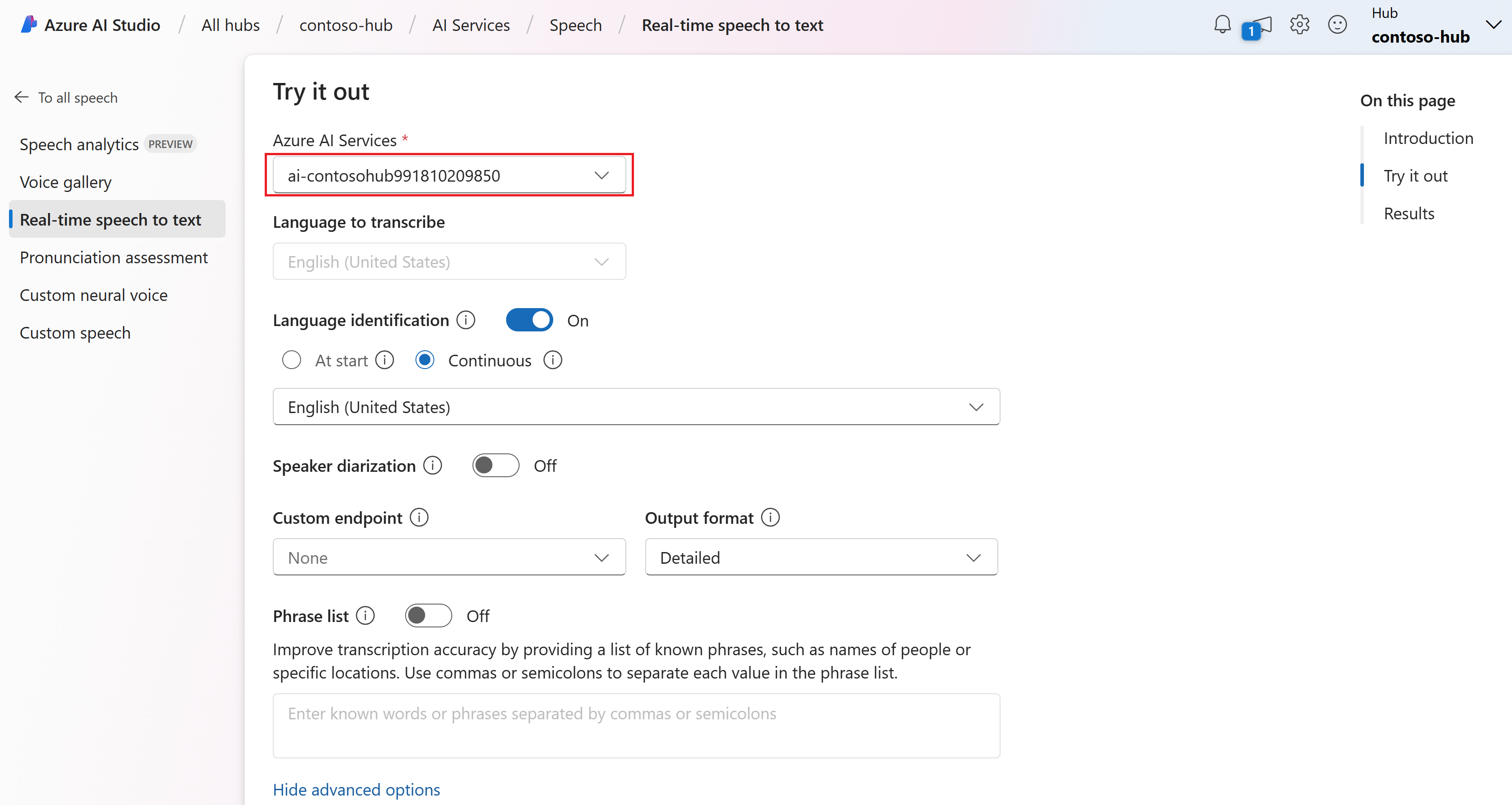
Pokud chcete nakonfigurovat možnosti převodu řeči na text, například:
- Identifikace jazyka: Používá se k identifikaci jazyků mluvených ve zvuku v porovnání se seznamem podporovaných jazyků. Další informace o možnostech identifikace jazyka, například při spuštění a průběžném rozpoznávání, najdete v tématu Identifikace jazyka.
- Diarizace mluvčího: Slouží k identifikaci a oddělení reproduktorů ve zvuku. Diarizace rozlišuje mezi různými mluvčími, kteří se účastní konverzace. Služba Speech poskytuje informace o tom, který mluvčí mluvil o konkrétní části přepisované řeči. Další informace o diarizaci mluvčího najdete v rychlém startu pro převod řeči na text v reálném čase pomocí diarizace mluvčího.
- Vlastní koncový bod: Ke zlepšení přesnosti rozpoznávání použijte nasazený model z vlastní řeči. Pokud chcete použít základní model Microsoftu, ponechte tuto možnost nastavenou na Hodnotu Žádné. Další informace o vlastní řeči najdete v tématu Vlastní řeč.
- Výstupní formát: Vyberte si mezi jednoduchými a podrobnými výstupními formáty. Jednoduchý výstup zahrnuje formát zobrazení a časové razítka. Podrobný výstup obsahuje další formáty (například zobrazení, lexikální, ITN a maskované ITN), časové razítka a N-nejlepší seznamy.
- Seznam frází: Zlepšení přesnosti přepisu tím, že poskytuje seznam známých frází, jako jsou jména lidí nebo konkrétní umístění. Jednotlivé hodnoty v seznamu frází oddělte čárkami nebo středníky. Další informace o seznamech frází najdete v tématu Seznamy frází.
Vyberte zvukový soubor, který chcete nahrát, nebo nahrát zvuk v reálném čase. V tomto příkladu
Call1_separated_16k_health_insurance.wavpoužijeme soubor, který je k dispozici v úložišti sady Speech SDK na GitHubu. Soubor si můžete stáhnout nebo použít vlastní zvukový soubor.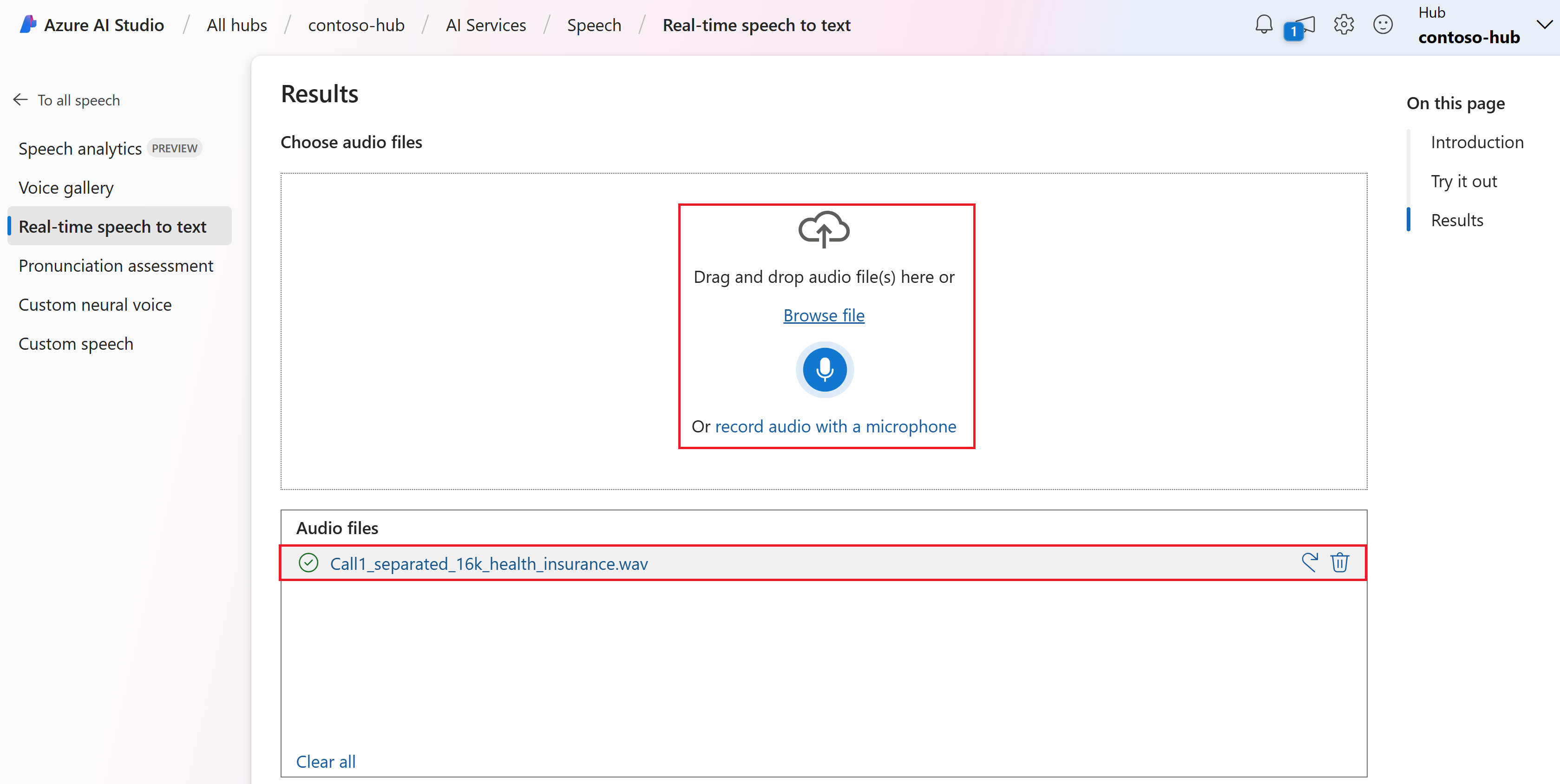
Výsledky řeči na text v reálném čase můžete zobrazit v části Výsledky .






Referenční dokumentace | – balíček (NuGet) | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Sada Speech SDK je k dispozici jako balíček NuGet a implementuje .NET Standard 2.0. Sadu Speech SDK nainstalujete později v této příručce. Další požadavky najdete v tématu Instalace sady Speech SDK.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pomocí těchto kroků vytvořte konzolovou aplikaci a nainstalujte sadu Speech SDK.
Ve složce, ve které chcete nový projekt, otevřete okno příkazového řádku. Spuštěním tohoto příkazu vytvořte konzolovou aplikaci pomocí rozhraní příkazového řádku .NET CLI.
dotnet new consoleTento příkaz vytvoří soubor Program.cs v adresáři projektu.
Nainstalujte sadu Speech SDK do nového projektu pomocí rozhraní příkazového řádku .NET.
dotnet add package Microsoft.CognitiveServices.SpeechObsah souboru Program.cs nahraďte tímto kódem:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu Identifikace jazyka.Spuštěním nové konzolové aplikace spusťte rozpoznávání řeči z mikrofonu:
dotnet runDůležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Po zobrazení výzvy promluvte do mikrofonu. Co mluvíte, by se mělo zobrazit jako text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Poznámky
Tady je několik dalších aspektů:
Tento příklad používá
RecognizeOnceAsyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
FromWavFileInputmístoFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | – balíček (NuGet) | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Sada Speech SDK je k dispozici jako balíček NuGet a implementuje .NET Standard 2.0. Sadu Speech SDK nainstalujete později v této příručce. Další požadavky najdete v tématu Instalace sady Speech SDK.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pomocí těchto kroků vytvořte konzolovou aplikaci a nainstalujte sadu Speech SDK.
Vytvořte nový projekt konzoly C++ v komunitě sady Visual Studio s názvem
SpeechRecognition.Vyberte nástroje>NuGet Správce balíčků> Správce balíčků konzole. V konzole Správce balíčků spusťte tento příkaz:
Install-Package Microsoft.CognitiveServices.SpeechSpeechRecognition.cppObsah nahraďte následujícím kódem:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu Identifikace jazyka.Sestavte a spusťte novou konzolovou aplikaci, která spustí rozpoznávání řeči z mikrofonu.
Důležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Po zobrazení výzvy promluvte do mikrofonu. Co mluvíte, by se mělo zobrazit jako text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Poznámky
Tady je několik dalších aspektů:
Tento příklad používá
RecognizeOnceAsyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
FromWavFileInputmístoFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | – balíček (Go) | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Nainstalujte sadu Speech SDK pro Go. Požadavky a pokyny najdete v tématu Instalace sady Speech SDK.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pomocí těchto kroků vytvořte modul GO.
Ve složce, ve které chcete nový projekt, otevřete okno příkazového řádku. Vytvořte nový soubor s názvem speech-recognition.go.
Zkopírujte následující kód do rozpoznávání řeči.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Spuštěním následujících příkazů vytvořte soubor go.mod , který odkazuje na komponenty hostované na GitHubu:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goDůležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Sestavte a spusťte kód:
go build go run speech-recognition
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Pokud chcete nastavit prostředí, nainstalujte sadu Speech SDK. Ukázka v tomto rychlém startu funguje s modulem Runtime Java.
Nainstalujte Apache Maven. Pak spusťte a potvrďte
mvn -vúspěšnou instalaci.V kořenovém adresáři projektu vytvořte nový
pom.xmlsoubor a zkopírujte do něj následující kód:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.38.0</version> </dependency> </dependencies> </project>Nainstalujte sadu Speech SDK a závislosti.
mvn clean dependency:copy-dependencies
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pokud chcete vytvořit konzolovou aplikaci pro rozpoznávání řeči, postupujte podle těchto kroků.
Ve stejném kořenovém adresáři projektu vytvořte nový soubor s názvem SpeechRecognition.java .
Do SpeechRecognition.java zkopírujte následující kód:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu Identifikace jazyka.Spuštěním nové konzolové aplikace spusťte rozpoznávání řeči z mikrofonu:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionDůležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Po zobrazení výzvy promluvte do mikrofonu. Co mluvíte, by se mělo zobrazit jako text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Poznámky
Tady je několik dalších aspektů:
Tento příklad používá
RecognizeOnceAsyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
fromWavFileInputmístofromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | Balíček (npm) | Další ukázky zdrojového kódu knihovny GitHub |
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Potřebujete také .wav zvukový soubor na místním počítači. Můžete použít vlastní .wav soubor (až 30 sekund) nebo si stáhnout https://crbn.us/whatstheweatherlike.wav ukázkový soubor.
Nastavení prostředí
Pokud chcete nastavit prostředí, nainstalujte sadu Speech SDK pro JavaScript. Spusťte tento příkaz: npm install microsoft-cognitiveservices-speech-sdk. Pokyny k instalaci s asistencí najdete v tématu Instalace sady Speech SDK.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávat řeč ze souboru
Pomocí těchto kroků vytvořte konzolovou aplikaci Node.js pro rozpoznávání řeči.
Otevřete okno příkazového řádku, ve kterém chcete nový projekt, a vytvořte nový soubor s názvem SpeechRecognition.js.
Nainstalujte sadu Speech SDK pro JavaScript:
npm install microsoft-cognitiveservices-speech-sdkDo SpeechRecognition.js zkopírujte následující kód:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();V SpeechRecognition.js nahraďte YourAudioFile.wav vlastním souborem .wav . Tento příklad rozpoznává řeč pouze ze souboru .wav . Informace o jiných formátech zvuku naleznete v tématu Použití komprimovaného vstupního zvuku. Tento příklad podporuje až 30 sekund zvuku.
Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu Identifikace jazyka.Spuštěním nové konzolové aplikace spusťte rozpoznávání řeči ze souboru:
node.exe SpeechRecognition.jsDůležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Řeč ze zvukového souboru by měla být výstupem jako text:
RECOGNIZED: Text=I'm excited to try speech to text.
Poznámky
Tento příklad používá recognizeOnceAsync operaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.
Poznámka:
Rozpoznávání řeči z mikrofonu se v Node.js nepodporuje. Podporuje se jenom v prostředí JavaScriptu založeném na prohlížeči. Další informace najdete v ukázce Reactu a implementaci řeči na text z mikrofonu na GitHubu.
Ukázka Reactu ukazuje vzory návrhu pro výměnu a správu ověřovacích tokenů. Zobrazuje také zachytávání zvuku z mikrofonu nebo souboru pro převod řeči na text.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | – balíček (PyPi) | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Sada Speech SDK pro Python je k dispozici jako modul PyPI (Python Package Index). Sada Speech SDK pro Python je kompatibilní s Windows, Linuxem a macOS.
- Pro Windows nainstalujte Microsoft Distribuovatelné součásti Visual C++ pro Visual Studio 2015, 2017, 2019 a 2022 pro vaši platformu. První instalace tohoto balíčku může vyžadovat restartování.
- V Linuxu musíte použít cílovou architekturu x64.
Nainstalujte verzi Pythonu z verze 3.7 nebo novější. Další požadavky najdete v tématu Instalace sady Speech SDK.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pomocí těchto kroků vytvořte konzolovou aplikaci.
Ve složce, ve které chcete nový projekt, otevřete okno příkazového řádku. Vytvořte nový soubor s názvem speech_recognition.py.
Spuštěním tohoto příkazu nainstalujte sadu Speech SDK:
pip install azure-cognitiveservices-speechDo speech_recognition.py zkopírujte následující kód:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu identifikace jazyka.Spuštěním nové konzolové aplikace spusťte rozpoznávání řeči z mikrofonu:
python speech_recognition.pyDůležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.Po zobrazení výzvy promluvte do mikrofonu. Co mluvíte, by se mělo zobrazit jako text:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Poznámky
Tady je několik dalších aspektů:
Tento příklad používá
recognize_once_asyncoperaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.Pokud chcete rozpoznat řeč ze zvukového souboru, použijte
filenamemístouse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte
PullAudioInputStreamneboPushAudioInputStream. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Referenční dokumentace | Balíček (stáhnout) | Další ukázky na GitHubu
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Sada Speech SDK pro Swift je distribuovaná jako sada rozhraní. Tato architektura podporuje Objective-C i Swift v iOSu i macOS.
Sadu Speech SDK je možné použít v projektech Xcode jako CocoaPod nebo stáhnout přímo a propojit ručně. Tato příručka používá CocoaPod. Nainstalujte správce závislostí CocoaPod, jak je popsáno v pokynech k instalaci.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávání řeči z mikrofonu
Pomocí těchto kroků rozpoznáte řeč v aplikaci pro macOS.
Naklonujte úložiště Azure-Samples/cognitive-services-speech-sdk , abyste získali rozpoznávání řeči z mikrofonu ve Swiftu v ukázkovém projektu macOS . Úložiště obsahuje také ukázky pro iOS.
V terminálu přejděte do adresáře stažené ukázkové aplikace (
helloworld).Spusťte příkaz
pod install. Tento příkaz vygenerujehelloworld.xcworkspacepracovní prostor Xcode obsahující ukázkovou aplikaci i sadu Speech SDK jako závislost.helloworld.xcworkspaceOtevřete pracovní prostor v Xcode.Otevřete soubor s názvem AppDelegate.swift a vyhledejte metody
applicationDidFinishLaunchingarecognizeFromMicmetody, jak je znázorněno zde.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }V AppDelegate.m použijte proměnné prostředí, které jste dříve nastavili pro klíč prostředku a oblast služby Speech.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Pokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US. Podrobnosti o tom, jak identifikovat jeden z více jazyků, které by mohly být mluvené, najdete v tématu Identifikace jazyka.Pokud chcete, aby byl výstup ladění viditelný, vyberte Zobrazit>konzolu aktivace oblasti>ladění.
Sestavte a spusťte ukázkový kód tak, že v nabídce vyberete Produkt>spustit nebo vyberete tlačítko Přehrát.
Důležité
Ujistěte se, že jste nastavili
SPEECH_KEYproměnné prostředí aSPEECH_REGIONproměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.
Když v aplikaci vyberete tlačítko a řeknete pár slov, měl by se zobrazit text, který jste mluvili v dolní části obrazovky. Když aplikaci spustíte poprvé, zobrazí se výzva, abyste aplikaci poskytli přístup k mikrofonu počítače.
Poznámky
Tento příklad používá recognizeOnce operaci k přepisu promluv do 30 sekund nebo do zjištění ticha. Informace o nepřetržitém rozpoznávání delšího zvuku, včetně vícejazyčných konverzací, najdete v tématu Rozpoznávání řeči.
Objective-C
Sada Speech SDK pro Objective-C sdílí klientské knihovny a referenční dokumentaci se sadou Speech SDK pro Swift. Příklady kódu Objective-C najdete v ukázkovém projektu Objective-C na GitHubu s rozpoznáváním řeči z mikrofonu v Objective-C .
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Speech to text REST API reference | Speech to text REST API for short audio reference | Additional Samples on GitHub
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Potřebujete také .wav zvukový soubor na místním počítači. Můžete použít vlastní .wav soubor až 60 sekund nebo stáhnout https://crbn.us/whatstheweatherlike.wav ukázkový soubor.
Nastavení proměnných prostředí
Aby vaše aplikace získala přístup k prostředkům služeb Azure AI, musí být ověřená. V produkčním prostředí použijte bezpečný způsob ukládání a přístupu k vašim přihlašovacím údajům. Když například získáte klíč pro prostředek služby Speech, zapište ho do nové proměnné prostředí na místním počítači, na kterém běží aplikace.
Tip
Nezahrňte klíč přímo do kódu a nikdy ho nesdělujte veřejně. Další možnosti ověřování, jako je Azure Key Vault, najdete v tématu Zabezpečení služeb Azure AI.
Pokud chcete nastavit proměnnou prostředí pro váš klíč prostředku služby Speech, otevřete okno konzoly a postupujte podle pokynů pro váš operační systém a vývojové prostředí.
- Pokud chcete nastavit proměnnou
SPEECH_KEYprostředí, nahraďte klíč jedním z klíčů vašeho prostředku. - Pokud chcete nastavit proměnnou
SPEECH_REGIONprostředí, nahraďte oblast jednou z oblastí vašeho prostředku.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Poznámka:
Pokud potřebujete přístup pouze k proměnným prostředí v aktuální konzole, můžete nastavit proměnnou prostředí namísto set setx.
Po přidání proměnných prostředí možná budete muset restartovat všechny programy, které potřebují přečíst proměnnou prostředí, včetně okna konzoly. Pokud například jako editor používáte Sadu Visual Studio, restartujte sadu Visual Studio před spuštěním příkladu.
Rozpoznávat řeč ze souboru
Otevřete okno konzoly a spusťte následující příkaz cURL. Nahraďte YourAudioFile.wav cestou a názvem zvukového souboru.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Důležité
Ujistěte se, že jste nastavili SPEECH_KEY proměnné prostředí a SPEECH_REGION proměnné prostředí. Pokud tyto proměnné nenastavíte, ukázka selže s chybovou zprávou.
Měla by se zobrazit odpověď podobná tomu, co se tady zobrazuje. Měl DisplayText by to být text, který byl rozpoznán ze zvukového souboru. Příkaz rozpozná až 60 sekund zvuku a převede ho na text.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Další informace najdete v tématu Rozhraní REST API pro převod řeči na text pro krátký zvuk.
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
V tomto rychlém startu vytvoříte a spustíte aplikaci pro rozpoznávání a přepis řeči na text v reálném čase.
Pokud chcete místo toho přepis zvukových souborů asynchronně přepisovat, přečtěte si téma Co je dávkový přepis. Pokud si nejste jistí, která řeč na text je pro vás správná, podívejte se, co je řeč na text?
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
- Na webu Azure Portal vytvořte prostředek služby Speech.
- Váš klíč prostředku služby Speech a oblast. Po nasazení prostředku služby Speech vyberte Přejít k prostředku a zobrazte a spravujte klíče. Další informace o prostředcích služeb Azure AI najdete v tématu Získání klíčů pro váš prostředek.
Nastavení prostředí
Postupujte podle těchtokrokůch
Spuštěním následujícího příkazu .NET CLI nainstalujte Rozhraní příkazového řádku služby Speech:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLISpuštěním následujících příkazů nakonfigurujte klíč prostředku a oblast služby Speech. Nahraďte
SUBSCRIPTION-KEYklíčem prostředku služby Speech a nahraďteREGIONoblastí prostředků služby Speech.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Rozpoznávání řeči z mikrofonu
Spuštěním následujícího příkazu spusťte rozpoznávání řeči z mikrofonu:
spx recognize --microphone --source en-USMluvte do mikrofonu a uvidíte přepis slov do textu v reálném čase. Rozhraní příkazového řádku služby Speech se zastaví po určité době ticha, 30 sekund nebo po výběru kombinace kláves Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Poznámky
Tady je několik dalších aspektů:
Pokud chcete rozpoznat řeč ze zvukového souboru, použijte místo
--file--microphone. Pro komprimované zvukové soubory, jako je MP4, nainstalujte GStreamer a použijte--format. Další informace naleznete v tématu Použití komprimovaného vstupního zvuku.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyPokud chcete zlepšit přesnost rozpoznávání konkrétních slov nebo promluv, použijte seznam frází. Seznam frází zahrnete do řádku nebo do textového souboru spolu s příkazem
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtPokud chcete změnit jazyk rozpoznávání řeči, nahraďte
en-USjiným podporovaným jazykem. Například proes-ESšpanělštinu (Španělsko). Pokud nezadáte jazyk, výchozí hodnota jeen-US.spx recognize --microphone --source es-ESPro nepřetržité rozpoznávání zvuku delší než 30 sekund připojte
--continuous:spx recognize --microphone --source es-ES --continuousSpuštěním tohoto příkazu zobrazíte informace o dalších možnostech rozpoznávání řeči, jako je vstup souboru a výstup:
spx help recognize
Vyčištění prostředků
Prostředek služby Speech, který jste vytvořili, můžete odebrat pomocí webu Azure Portal nebo rozhraní příkazového řádku Azure (CLI ).
Další krok
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro