Co je vlastní řeč?
Pomocí vlastní řeči můžete vyhodnotit a zlepšit přesnost rozpoznávání řeči pro vaše aplikace a produkty. Vlastní model řeči se dá použít pro převod řeči v reálném čase na text, překlad řeči a dávkový přepis.
Rozpoznávání řeči využívá univerzální jazykový model jako základní model trénovaný s daty vlastněnými Microsoftem a odráží běžně používaný mluvený jazyk. Základní model je předem natrénovaný pomocí dialektů a fonetik představujících různé běžné domény. Když provedete žádost o rozpoznávání řeči, použije se ve výchozím nastavení nejnovější základní model pro každý podporovaný jazyk . Základní model funguje dobře ve většině scénářů rozpoznávání řeči.
Vlastní model lze použít k rozšíření základního modelu za účelem zlepšení rozpoznávání slovníku specifického pro doménu specifickou pro aplikaci poskytnutím textových dat pro trénování modelu. Dá se také použít ke zlepšení rozpoznávání na základě konkrétních zvukových podmínek aplikace poskytnutím zvukových dat s referenčními přepisy.
Model se strukturovaným textem můžete vytrénovat také v případě, že se data řídí vzorem, určíte vlastní výslovnost a přizpůsobíte formátování textu pomocí vlastního inverzního normalizace textu, vlastního přepisu a vlastního filtrování vulgárních výrazů.
Jak to funguje?
Pomocí vlastní řeči můžete nahrát vlastní data, otestovat a vytrénovat vlastní model, porovnat přesnost mezi modely a nasadit model do vlastního koncového bodu.
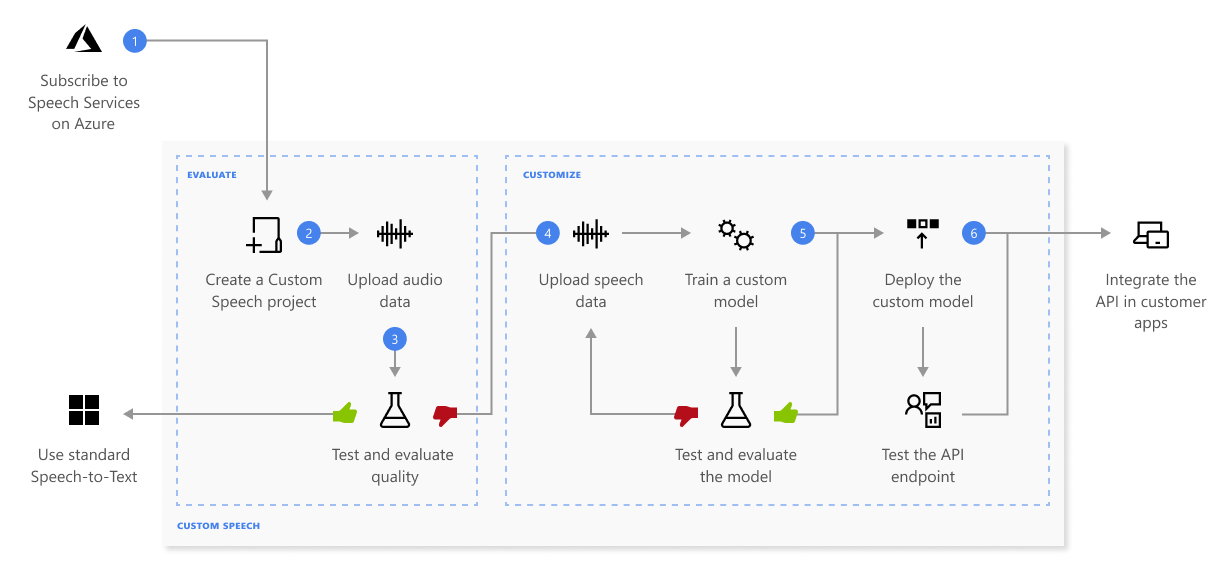
Tady jsou další informace o posloupnosti kroků zobrazených v předchozím diagramu:
- Vytvořte projekt a zvolte model. Použijte prostředek služby Speech, který vytvoříte na webu Azure Portal. Pokud vytrénujete vlastní model se zvukovými daty, zvolte oblast prostředků služby Speech s vyhrazeným hardwarem pro trénování zvukových dat. Další informace najdete v tabulce oblastí v poznámkách pod čarou.
- Nahrajte testovací data. Nahrajte testovací data pro vyhodnocení nabídky řeči na text pro vaše aplikace, nástroje a produkty.
- Kvalita rozpoznávání testů. Pomocí sady Speech Studio můžete přehrávat nahraný zvuk a kontrolovat kvalitu rozpoznávání řeči testovacích dat.
- Testování modelu kvantitativním způsobem. Vyhodnoťte a vylepšete přesnost převodu řeči na textový model. Služba Speech poskytuje kvantitativní chybovost slov (WER), kterou můžete použít k určení, jestli se vyžaduje další trénování.
- Trénování modelu Zadejte psané přepisy a související text spolu s odpovídajícími zvukovými daty. Testování modelu před a po trénování je volitelné, ale doporučuje se.
Poznámka:
Platíte za využití vlastního modelu řeči a hostování koncových bodů. Pokud byl základní model vytvořen 1. října 2023 a novější, bude se vám účtovat také trénování vlastního modelu řeči. Pokud byl základní model vytvořený před říjnem 2023, nebude se vám účtovat za trénování. Další informace najdete v tématu Ceny služby Azure AI Speech a část Poplatky za přizpůsobení v průvodci migrací převodu řeči na text 3.2.
- Nasazení modelu Jakmile budete s výsledky testu spokojeni, nasaďte model do vlastního koncového bodu. Kromě dávkového přepisu musíte nasadit vlastní koncový bod pro použití vlastního modelu řeči.
Zodpovědná AI
Systém AI zahrnuje nejen technologii, ale také uživatele, kteří ho používají, osoby, kterých se to týká, a prostředí, ve kterém je nasazené. Přečtěte si poznámky k transparentnosti a seznamte se s zodpovědným používáním a nasazením umělé inteligence ve vašich systémech.
- Poznámka transparentnosti a případy použití
- Charakteristiky a omezení
- Integrace a zodpovědné použití
- Data, ochrana osobních údajů a zabezpečení