Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
K testování přesnosti rozpoznávání řeči nebo trénování vlastních modelů potřebujete zvuková nebo textová data. Informace o datových typech podporovaných pro testování nebo trénování modelu najdete v tématu trénování a testování datových sad.
Návod
Pomocí online editoru přepisu můžete také vytvářet a upřesňovat zvukové datové sady s popisky.
Nahrání datových sad
K nahrání datových sad pro trénování (vyladění) vlastního modelu řeči použijte tento postup.
Důležité
Opakujte kroky pro nahrání testovacích datových sad (například jenom zvuku ), které budete potřebovat později při vytváření testu. Můžete nahrát několik datových sad pro trénování a testování.
Přihlaste se k portálu Microsoft Foundry.
V levém podokně vyberte Jemné ladění a pak vyberte Vyladění služby AI.
Vyberte úlohu jemného ladění vlastní řeči (podle názvu modelu), kterou jste začali, jak je popsáno v článku o tom, jak začít s vyladěním vlastní řeči.
Vyberte Spravovat data>Přidat datovou sadu.
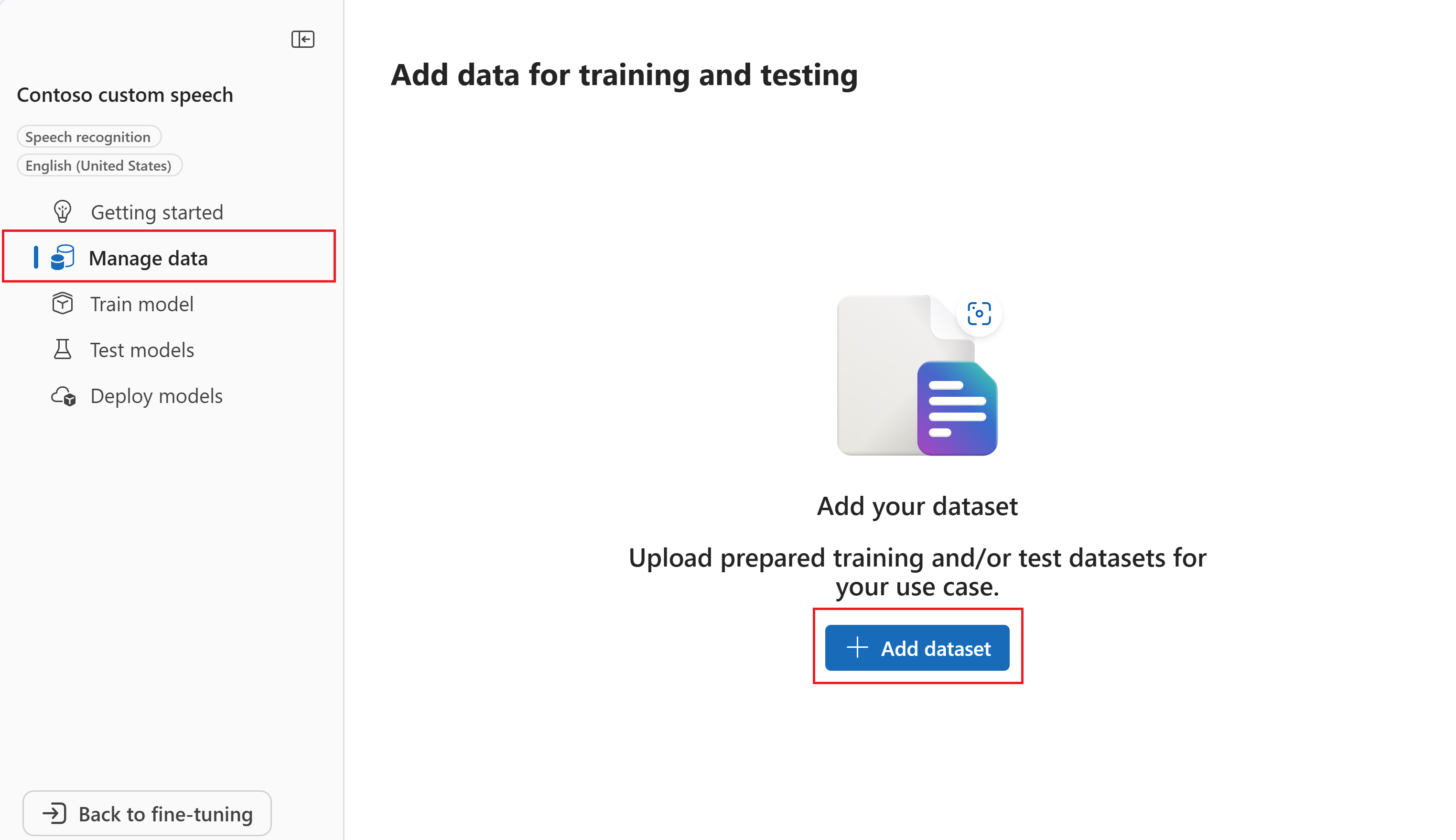
V průvodci přidáním dat vyberte typ trénovacích dat, která chcete přidat. V tomto příkladu vybereme přepis s popiskem zvuku a člověka. Pak vyberte Další.
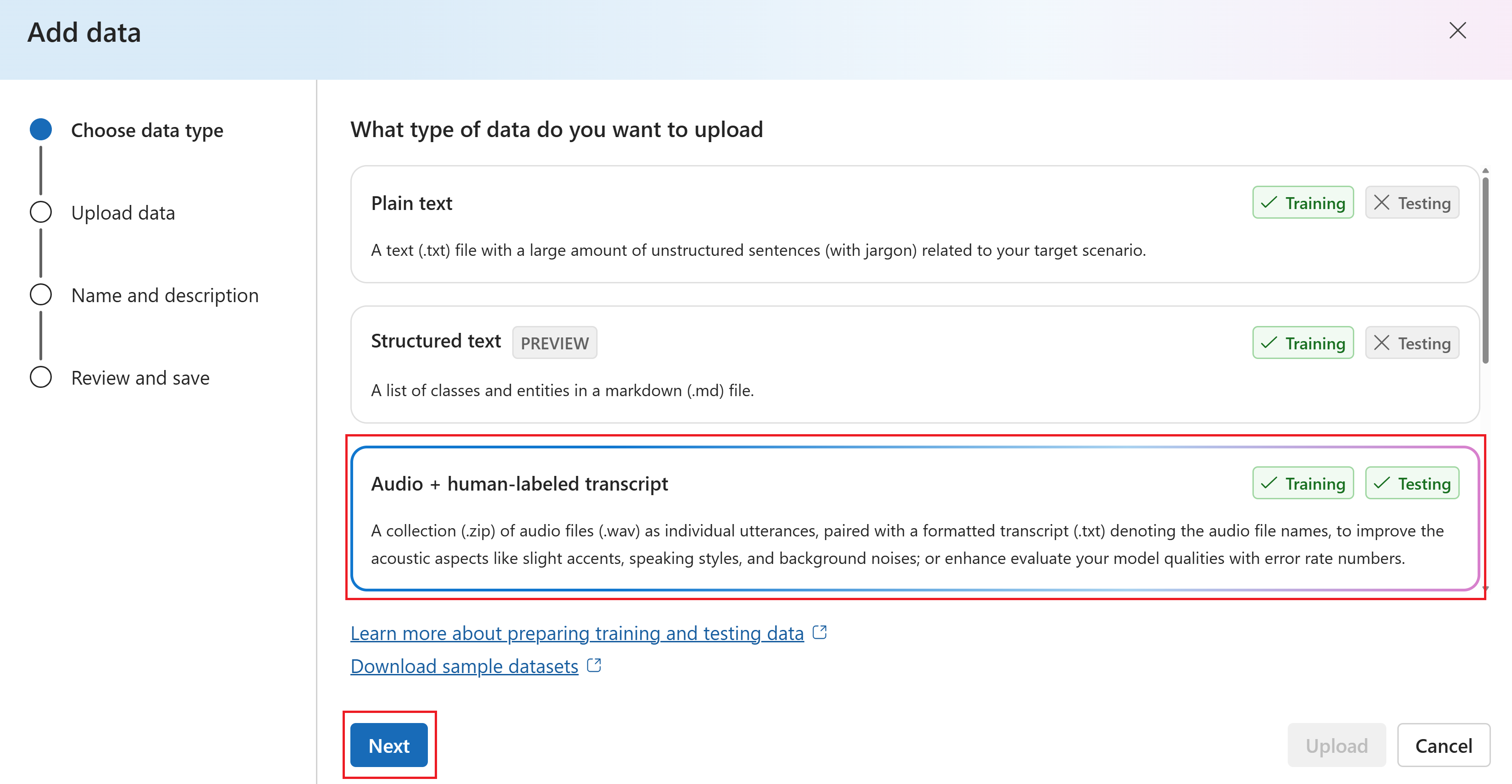
Na stránce Nahrát data vyberte místní soubory, Azure Blob Storage nebo jiná sdílená webová umístění. Pak vyberte Další.
Pokud vyberete vzdálené umístění a nepoužíváte mechanismus zabezpečení důvěryhodných služeb Azure, pak by vzdálené umístění mělo být adresa URL, která se dá načíst pomocí jednoduchého anonymního požadavku GET. Například adresa URL SAS nebo veřejně přístupná adresa URL. Adresy URL, které vyžadují další autorizaci nebo očekávají interakci uživatele, se nepodporují.
Poznámka:
Pokud používáte adresu URL objektu blob Azure, můžete zajistit maximální zabezpečení souborů datové sady pomocí důvěryhodného mechanismu zabezpečení služeb Azure. Používáte stejné techniky jako pro dávkové přepisy a adresy URL účtu úložiště pro soubory datových sad. Další podrobnosti najdete tady.
Zadejte název a popis dat. Pak vyberte Další.
Zkontrolujte data a vyberte Nahrát. Vrátíte se zpět na stránku Spravovat data . Stav dat je Zpracování.
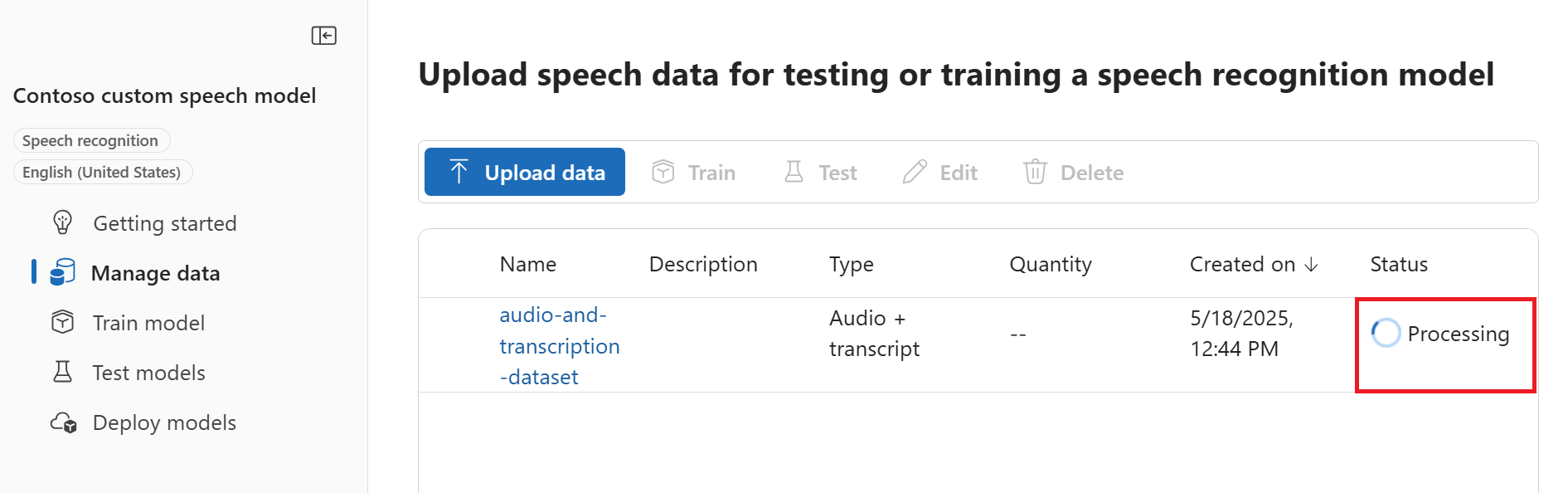
Opakujte kroky pro nahrání testovacích datových sad (například jenom zvuku ), které budete potřebovat později při vytváření testu. Můžete nahrát několik datových sad pro trénování a testování.
Opakujte předchozí kroky a nahrajte zvuková data , která použijete později k testování. V průvodci přidáním dat vyberte Zvuk pro typ dat, která chcete přidat.



Pokud chcete nahrát vlastní datové sady v sadě Speech Studio, postupujte takto:
Přihlaste se k sadě Speech Studio.
Vyberte Custom speech> Your project name >Speech datasets>Upload data.
Vyberte kartu Trénovací data nebo Testovací data.
Vyberte typ datové sady a pak vyberte Další.
Zadejte umístění datové sady a pak vyberte Další. Můžete zvolit místní soubor nebo zadat vzdálené umístění, jako je adresa URL objektu blob Azure. Pokud vyberete vzdálené umístění a nepoužíváte mechanismus zabezpečení důvěryhodných služeb Azure, pak by vzdálené umístění mělo být adresa URL, která se dá načíst pomocí jednoduchého anonymního požadavku GET. Například adresa URL SAS nebo veřejně přístupná adresa URL. Adresy URL, které vyžadují další autorizaci nebo očekávají interakci uživatele, se nepodporují.
Poznámka:
Pokud používáte adresu URL objektu blob Azure, můžete zajistit maximální zabezpečení souborů datové sady pomocí důvěryhodného mechanismu zabezpečení služeb Azure. Používáte stejné techniky jako pro přepis v režimu Batch a adresy URL jednoduchých účtů úložiště pro soubory datové sady. Další podrobnosti najdete tady.
Zadejte název a popis datové sady a pak vyberte Další.
Zkontrolujte nastavení a pak vyberte Uložit a zavřít.
Po nahrání datové sady přejděte na stránku Trénovat vlastní modely a natrénujte vlastní model.
Než budete pokračovat, ujistěte se, že máte nainstalované a nakonfigurované rozhraní příkazového řádku služby Speech .
S rozhraním Speech CLI a rozhraním API pro převod řeči na text, na rozdíl od portálu Microsoft Foundry a sady Speech Studio, nevyberete, jestli je datová sada určená k testování nebo trénování v době nahrávání. Určíte, jak se datová sada používá při trénování modelu nebo spuštění testu.
I když neuvádíte, jestli je datová sada určená k testování nebo trénování, musíte zadat typ datové sady. Typ datové sady se používá k určení typu datové sady, která se vytvoří. V některých případech se typ datové sady používá jenom k testování nebo trénování, ale neměli byste na tom mít závislost. Hodnoty rozhraní speech CLI a rozhraní REST API kind odpovídají možnostem na portálu Microsoft Foundry a sadě Speech Studio , jak je popsáno v následující tabulce:
| Typ rozhraní příkazového řádku a rozhraní API | Možnosti portálu |
|---|---|
| Akustický | Trénovací data: Audio + přepis označený člověkem Testování dat: Přepis (automatická syntéza zvuku) Testování dat: Audio + přepis označený člověkem |
| Zvukové soubory | Testování dat: Zvuk |
| Jazyk | Trénovací data: Prostý text |
| LanguageMarkdown | Trénovací data: Strukturovaný text ve formátu Markdownu |
| Výslovnost | Trénovací data: Výslovnost |
| Formátování výstupu | Trénovací data: Výstupní formát |
Důležité
K přímému nahrání datových souborů nepoužíváte rozhraní Speech CLI ani rozhraní REST API. Nejprve uložíte soubory trénovacích nebo testovacích datových sad na adrese URL, ke které má rozhraní Speech CLI nebo rozhraní REST API přístup. Po nahrání datových souborů můžete pomocí rozhraní speech CLI nebo rozhraní REST API vytvořit datovou sadu pro vlastní testování řeči nebo trénování.
Pokud chcete vytvořit datovou sadu a připojit ji k existujícímu projektu, použijte spx csr dataset create příkaz. Parametry požadavku se sestaví podle následujících pokynů:
projectNastavte vlastnost na ID existujícího projektu. Tatoprojectvlastnost se doporučuje, abyste mohli také spravovat jemné ladění pro vlastní řeč na portálu Microsoft Foundry. Id projektu získáte v tématu Získání ID projektu pro dokumentaci k rozhraní REST API .Nastavte požadovanou
kindvlastnost. Možnou sadou hodnot pro druh trénovací datové sady jsou: Acoustic, AudioFiles, Language, LanguageMarkdown a Výslovnost.Nastavte požadovanou
contentUrlvlastnost. Tento parametr je umístění datové sady. Pokud nepoužíváte důvěryhodný mechanismus zabezpečení služeb Azure (viz další poznámka),contentUrlměla by tato vlastnost být adresa URL, která se dá načíst pomocí jednoduchého anonymního požadavku GET. Například adresa URL SAS nebo veřejně přístupná adresa URL. Adresy URL, které vyžadují dodatečnou autorizaci, nebo očekávají, že interakce uživatelů se nepodporuje.Poznámka:
Pokud používáte adresu URL objektu blob Azure, můžete zajistit maximální zabezpečení souborů datové sady pomocí důvěryhodného mechanismu zabezpečení služeb Azure. Používáte stejné techniky jako pro přepis v režimu Batch a adresy URL jednoduchých účtů úložiště pro soubory datové sady. Další podrobnosti najdete tady.
Nastavte požadovanou
languagevlastnost. Národní prostředí datové sady musí odpovídat národnímu prostředí projektu. Národní prostředí nelze později změnit. Vlastnostlanguagerozhraní příkazového řádku služby Speech odpovídá vlastnostilocalev požadavku a odpovědi JSON.Nastavte požadovanou
namevlastnost. Tento parametr je název zobrazený na portálu Microsoft Foundry. Vlastnostnamerozhraní příkazového řádku služby Speech odpovídá vlastnostidisplayNamev požadavku a odpovědi JSON.
Tady je ukázkový příkaz Rozhraní příkazového řádku služby Speech, který vytvoří datovou sadu a připojí ji k existujícímu projektu:
spx csr dataset create --api-version v3.2 --kind "Acoustic" --name "My Acoustic Dataset" --description "My Acoustic Dataset Description" --project YourProjectId --content YourContentUrl --language "en-US"
Důležité
Musíte nastavit --api-version v3.2. Rozhraní příkazového řádku služby Speech používá rozhraní REST API, ale zatím nepodporuje verze novější než v3.2.
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/aaaabbbb-0000-cccc-1111-dddd2222eeee",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
Vlastnost nejvyšší úrovně self v textu odpovědi je identifikátor URI datové sady. Pomocí tohoto identifikátoru URI získáte podrobnosti o projektu a souborech datové sady. Tento identifikátor URI slouží také k aktualizaci nebo odstranění datové sady.
V případě nápovědy k rozhraní příkazového řádku služby Speech s datovými sadami spusťte následující příkaz:
spx help csr dataset
S rozhraním Speech CLI a rozhraním API pro převod řeči na text, na rozdíl od portálu Microsoft Foundry a sady Speech Studio, nevyberete, jestli je datová sada určená k testování nebo trénování v době nahrávání. Určíte, jak se datová sada používá při trénování modelu nebo spuštění testu.
I když neuvádíte, jestli je datová sada určená k testování nebo trénování, musíte zadat typ datové sady. Typ datové sady se používá k určení typu datové sady, která se vytvoří. V některých případech se typ datové sady používá jenom k testování nebo trénování, ale neměli byste na tom mít závislost. Hodnoty rozhraní speech CLI a rozhraní REST API kind odpovídají možnostem na portálu Microsoft Foundry a sadě Speech Studio , jak je popsáno v následující tabulce:
| Typ rozhraní příkazového řádku a rozhraní API | Možnosti portálu |
|---|---|
| Akustický | Trénovací data: Audio + přepis označený člověkem Testování dat: Přepis (automatická syntéza zvuku) Testování dat: Audio + přepis označený člověkem |
| Zvukové soubory | Testování dat: Zvuk |
| Jazyk | Trénovací data: Prostý text |
| LanguageMarkdown | Trénovací data: Strukturovaný text ve formátu Markdownu |
| Výslovnost | Trénovací data: Výslovnost |
| Formátování výstupu | Trénovací data: Výstupní formát |
Důležité
K přímému nahrání datových souborů nepoužíváte rozhraní Speech CLI ani rozhraní REST API. Nejprve uložíte soubory trénovacích nebo testovacích datových sad na adrese URL, ke které má rozhraní Speech CLI nebo rozhraní REST API přístup. Po nahrání datových souborů můžete pomocí rozhraní speech CLI nebo rozhraní REST API vytvořit datovou sadu pro vlastní testování řeči nebo trénování.
Pokud chcete vytvořit datovou sadu a připojit ji k existujícímu projektu, použijte Datasets_Create operaci rozhraní REST API pro převod řeči na text. Sestavte tělo požadavku podle následujících pokynů:
projectNastavte vlastnost na ID existujícího projektu. Tatoprojectvlastnost se doporučuje, abyste mohli také spravovat jemné ladění pro vlastní řeč na portálu Microsoft Foundry. Id projektu získáte v tématu Získání ID projektu pro dokumentaci k rozhraní REST API .Nastavte požadovanou
kindvlastnost. Možnou sadou hodnot pro druh trénovací datové sady jsou: Acoustic, AudioFiles, Language, LanguageMarkdown a Výslovnost.Nastavte požadovanou
contentUrlvlastnost. Tato vlastnost je umístění datové sady. Pokud nepoužíváte důvěryhodný mechanismus zabezpečení služeb Azure (viz další poznámka),contentUrlměla by tato vlastnost být adresa URL, která se dá načíst pomocí jednoduchého anonymního požadavku GET. Například adresa URL SAS nebo veřejně přístupná adresa URL. Adresy URL, které vyžadují dodatečnou autorizaci, nebo očekávají, že interakce uživatelů se nepodporuje.Poznámka:
Pokud používáte adresu URL objektu blob Azure, můžete zajistit maximální zabezpečení souborů datové sady pomocí důvěryhodného mechanismu zabezpečení služeb Azure. Používáte stejné techniky jako pro přepis v režimu Batch a adresy URL jednoduchých účtů úložiště pro soubory datové sady. Další podrobnosti najdete tady.
Nastavte požadovanou
localevlastnost. Národní prostředí datové sady musí odpovídat národnímu prostředí projektu. Národní prostředí nelze později změnit.Nastavte požadovanou
displayNamevlastnost. Tato vlastnost je název, který se zobrazuje na portálu Microsoft Foundry.
Vytvořte požadavek HTTP POST pomocí identifikátoru URI, jak je znázorněno v následujícím příkladu. Nahraďte YourSpeechResoureKey klíčem prostředku služby Speech, nahraďte YourServiceRegion oblastí prostředků služby Speech a nastavte vlastnosti textu požadavku, jak jsme popsali dříve.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"kind": "Acoustic",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"contentUrl": "https://contoso.com/mydatasetlocation",
"locale": "en-US",
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/datasets"
Měl by se zobrazit text odpovědi v následujícím formátu:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/aaaabbbb-0000-cccc-1111-dddd2222eeee",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
Vlastnost nejvyšší úrovně self v textu odpovědi je identifikátor URI datové sady. Pomocí tohoto identifikátoru URI získáte podrobnosti o projektu a souborech datové sady. Tento identifikátor URI také použijete k aktualizaci nebo odstranění datové sady.
Důležité
Připojení datové sady k vlastnímu projektu řeči se nevyžaduje k trénování a testování vlastního modelu pomocí rozhraní REST API nebo rozhraní speech CLI. Pokud ale datová sada není připojená k žádnému projektu, nemůžete ji vybrat pro trénování nebo testování na portálu Microsoft Foundry.