Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Monitor
Distribuované aplikace a služby běžící v cloudu jsou podle své povahy komplexní části softwaru, které tvoří mnoho pohyblivých částí. V produkčním prostředí je důležité sledovat způsob, jakým uživatelé používají váš systém, sledovat využití prostředků a obecně monitorovat stav a výkon systému. Tyto informace můžete použít jako diagnostickou pomůcku k rozpoznání a opravě problémů a také k tomu, abyste si všimli potenciálních problémů a zabránili jejich výskytu.
Scénáře monitorování a diagnostiky
Monitorování můžete použít k získání přehledu o tom, jak dobře systém funguje. Monitorování je klíčovou součástí udržování cílů kvality služeb. Mezi běžné scénáře shromažďování dat monitorování patří:
- Zajištění, aby systém zůstal v pořádku.
- Sledování dostupnosti systému a jeho součástí
- Udržování výkonu, aby se zajistila neočekávaná propustnost systému při nárůstu objemu práce.
- Záruka, že systém splňuje všechny smlouvy o úrovni služeb (SLA) vytvořené se zákazníky.
- Ochrana soukromí a zabezpečení systému, uživatelů a jejich dat.
- Sledování operací prováděných pro účely auditování nebo právních předpisů
- Monitorování každodenního používání systému a sledování trendů, které můžou vést k problémům, pokud nejsou vyřešené.
- Sledování problémů, ke kterým dochází, od počátečních zpráv až po analýzu možných příčin, nápravy, následných aktualizací softwaru a nasazení.
- Operace trasování a ladění vydaných verzí softwaru
Poznámka:
Tento seznam není určen k tomu, aby byl vyčerpávající. Tento dokument se zaměřuje na tyto scénáře jako nejčastější situace pro provádění monitorování. Můžou existovat i jiné, které jsou méně časté nebo jsou specifické pro vaše prostředí.
Následující části popisují tyto scénáře podrobněji. Informace pro jednotlivé scénáře jsou popsány v následujícím formátu:
- Stručný přehled scénáře
- Typické požadavky tohoto scénáře.
- Nezpracovaná data instrumentace, která jsou nutná k podpoře scénáře, a možné zdroje těchto informací.
- Způsob analýzy a kombinování těchto nezpracovaných dat za účelem generování smysluplných diagnostických informací
Monitorování stavu
Systém je v pořádku, pokud je spuštěný a schopný zpracovávat požadavky. Účelem monitorování stavu je vygenerovat snímek aktuálního stavu systému, abyste mohli ověřit, že všechny součásti systému fungují podle očekávání.
Požadavky na monitorování stavu
Operátor by měl být rychle upozorněn (během několika sekund), pokud je některá část systému považována za špatnou. Operátor by měl být schopen zjistit, které části systému fungují normálně a které části mají problémy. Stav systému je možné zvýraznit prostřednictvím systému semaforu:
- Červená pro nefunkční stav (systém se zastavil)
- Žlutá pro částečně v pořádku (systém běží se sníženou funkčností)
- Zelená znamená zcela zdravý stav
Komplexní systém pro monitorování stavu umožňuje operátorovi přejít k podrobnostem systému a zobrazit stav subsystémů a komponent. Pokud je například celkový systém zobrazen jako částečně v pořádku, měl by být operátor schopný přiblížit a určit, které funkce jsou aktuálně degradované nebo nedostupné.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Nezpracovaná data potřebná k podpoře monitorování stavu se dají vygenerovat v důsledku:
- Trasování provádění uživatelských požadavků Tyto informace lze použít k určení, které požadavky byly úspěšné, které selhaly a jak dlouho trvá jednotlivé požadavky.
- Syntetické monitorování uživatelů. Tento proces simuluje kroky prováděné uživatelem a řídí se předdefinovanou řadou kroků. Výsledky jednotlivých kroků by se měly zachytit.
- Protokolování výjimek, chyb a upozornění Tyto informace je možné zachytit v důsledku příkazů trasování vložených do kódu aplikace a také načtení informací z protokolů událostí všech služeb, na které systém odkazuje.
- Monitorování stavu všech služeb třetích stran, které systém používá. Toto monitorování může vyžadovat načtení a analýzu dat o stavu, která tyto služby poskytují. Tyto informace můžou mít různé formáty.
- Monitorování koncových bodů Tento mechanismus je podrobněji popsán v části Monitorování dostupnosti.
- Shromažďování informací o okolním výkonu, jako je využití procesoru na pozadí nebo vstupně-výstupní aktivita (včetně sítě).
Analýza dat o stavu
Hlavním cílem monitorování stavu je rychle indikovat, jestli je systém spuštěný. Horká analýza okamžitých dat může aktivovat výstrahu, pokud je kritická komponenta zjištěna jako poškozená (například nereaguje na po sobě jdoucí řadu příkazů ping). Operátor pak může provést příslušnou nápravnou akci.
Pokročilejší systém může zahrnovat prediktivní prvek, který provádí studenou analýzu za posledních a aktuálních úloh. Studená analýza dokáže odhalit trendy a určit, jestli systém pravděpodobně zůstane v pořádku nebo jestli systém potřebuje další prostředky. Tento prediktivní prvek by měl být založený na důležitých metrikách výkonu, například:
- Rychlost požadavků směrovaných na každou službu nebo subsystém.
- Doby odezvy těchto požadavků.
- Objem dat proudících do a ven z každé služby.
Pokud hodnota jakékoli metriky překročí definovanou prahovou hodnotu, může systém vyvolat výstrahu, která operátorovi nebo automatickému škálování (pokud je k dispozici) umožnit provedení preventivních akcí nezbytných k zachování stavu systému. Tyto akce můžou zahrnovat přidání prostředků, restartování jedné nebo více služeb, které selhávají, nebo omezení požadavků s nižší prioritou.
Monitorování dostupnosti
Skutečně zdravý systém vyžaduje, aby byly dostupné komponenty a subsystémy, které systém tvoří. Monitorování dostupnosti úzce souvisí s monitorováním stavu. Monitorování stavu sice poskytuje okamžitý přehled o aktuálním stavu systému, ale monitorování dostupnosti se zabývá sledováním dostupnosti systému a jejích součástí za účelem generování statistik o době provozu systému.
V mnoha systémech jsou některé komponenty (například databáze) nakonfigurované s integrovanou redundancí, která umožňuje rychlé převzetí služeb při selhání v případě závažné chyby nebo ztráty připojení. V ideálním případě by uživatelé neměli vědět, že k takové chybě došlo. Z hlediska monitorování dostupnosti je ale nutné shromáždit co nejvíce informací o takových selháních, abyste zjistili příčinu a podnikli nápravné akce, aby se zabránilo jejich opakovanému opakování.
Data potřebná ke sledování dostupnosti můžou záviset na několika faktorech nižší úrovně. Mnoho z těchto faktorů může být specifické pro aplikaci, systém a prostředí. Efektivní monitorovací systém zaznamenává data o dostupnosti, která odpovídají těmto faktorům nízké úrovně, a pak je agreguje, aby získal celkový přehled o systému. Například v systému elektronického obchodování můžou obchodní funkce, které zákazníkovi umožňují zadávat objednávky, záviset na úložišti, kde jsou uloženy podrobnosti objednávky, a platební systém, který zpracovává peněžní transakce za platbu za tyto objednávky. Dostupnost části systému pro umísťování objednávek je proto funkcí dostupnosti úložiště a subsystému plateb.
Požadavky na monitorování dostupnosti
Operátor by měl mít také možnost zobrazit historickou dostupnost jednotlivých systémů a subsystémů a tyto informace použít ke sledování trendů, které by mohly způsobit pravidelné selhání jednoho nebo více subsystémů. Operátor může například pomocí dat o dostupnosti zjistit, že služby začnou selhávat v konkrétní denní době odpovídající hodině zpracování ve špičce.
Řešení monitorování by mělo poskytnout okamžitý a historický přehled o dostupnosti nebo nedostupnosti jednotlivých subsystémů. Měl by také být schopný rychle upozornit operátora, když jedna nebo více služeb selže nebo když se uživatelé nemůžou připojit ke službám. Jedná se nejen o monitorování jednotlivých služeb, ale také zkoumání akcí, které každý uživatel provede, pokud tyto akce selžou při pokusu o komunikaci se službou. V určitém rozsahu je míra selhání připojení normální a může být způsobená přechodnými chybami. Může ale být užitečné, aby systém mohl vyvolat upozornění na počet selhání připojení k zadanému subsystému, ke kterému dochází během určitého období.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Stejně jako u monitorování stavu je možné nezpracovaná data požadovaná k podpoře monitorování dostupnosti vygenerovat v důsledku syntetického monitorování uživatelů a protokolování všech výjimek, chyb a upozornění, ke kterým může dojít. Kromě toho je možné získat data o dostupnosti z monitorování koncových bodů. Aplikace může zveřejnit jeden nebo více koncových bodů stavu, přičemž každý testuje přístup k funkční oblasti v rámci systému. Monitorovací systém může každý koncový bod otestovat příkazem ping podle definovaného plánu a shromáždit výsledky (úspěch nebo selhání).
Všechny časové limity, chyby připojení k síti a pokusy o opakování připojení se musí zaznamenávat. Všechna data by měla být opatřena časovým razítkem.
Analýza dat o dostupnosti
Data instrumentace musí být agregovaná a korelovaná, aby podporovala následující typy analýz:
- Okamžitá dostupnost systému a subsystémů.
- Míra selhání dostupnosti systému a subsystémů. V ideálním případě by měl být operátor schopný korelovat selhání s konkrétními aktivitami: co se stalo, když došlo k selhání systému?
- Historický pohled na míru selhání systému nebo všech subsystémů v jakémkoli zadaném období a zatížení systému (například počet uživatelských požadavků), když došlo k selhání.
- Důvody nedostupnosti systému nebo jakýchkoli subsystémů Důvody mohou být například neběžící služba, ztráta připojení, připojení, ale vypršení časového limitu, a připojení, ale vrací chyby.
Procentuální dostupnost služby můžete vypočítat v určitém časovém období pomocí následujícího vzorce:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
To je užitečné pro účely smlouvy SLA. (Monitorování smluv SLA je podrobněji popsáno dále v těchto doprovodných materiálech.) Definice výpadků závisí na službě. Například Visual Studio Team Services Build Service definuje výpadek jako období (celkové kumulované minuty), během kterého je služba buildu nedostupná. Minuta se považuje za nedostupnou, pokud všechny HTTP požadavky na Build Service pro provádění zákazníkem iniciovaných operací v dané minutě buď skončí chybovým kódem, nebo nevrátí odpověď.
Monitorování výkonu
Vzhledem k tomu, že je systém více namáhán kvůli zvyšujícímu se počtu uživatelů, roste velikost datových sad, ke kterým tito uživatelé přistupují, a pravděpodobnost selhání jedné nebo více součástí je pravděpodobnější. Selhání komponent často předchází snížení výkonu. Pokud takové snížení výkonu dokážete zjistit, můžete proaktivně provést kroky k nápravě situace.
Výkon systému závisí na několika faktorech. Každý faktor se obvykle měří prostřednictvím klíčových ukazatelů výkonu (KPI), jako je počet databázových transakcí za sekundu nebo objem síťových požadavků, které se úspěšně obsluhují v zadaném časovém rámci. Některé z těchto klíčových ukazatelů výkonu můžou být k dispozici jako konkrétní míry výkonu, zatímco jiné můžou být odvozené z kombinace metrik.
Poznámka:
Určení špatného nebo dobrého výkonu vyžaduje, abyste pochopili úroveň výkonu, při které by měl být systém schopný běžet. To vyžaduje sledování systému, zatímco funguje v typickém zatížení a zaznamenává data pro každý klíčový ukazatel výkonu v určitém časovém období. To může zahrnovat spuštění systému pod simulovaným zatížením v testovacím prostředí a shromáždění příslušných dat před nasazením systému do produkčního prostředí.
Měli byste také zajistit, aby monitorování pro účely výkonu nezatěžuje systém. Úprava úrovně podrobností pro data, která proces monitorování výkonu shromažďuje, vám pomůže optimalizovat výkon.
Požadavky na monitorování výkonu
Aby operátor prozkoumal výkon systému, obvykle potřebuje zobrazit informace, které zahrnují:
- Rychlost odpovědi pro žádosti uživatelů.
- Počet souběžných uživatelských požadavků.
- Objem síťového provozu.
- Sazby, za které jsou obchodní transakce dokončeny.
- Průměrná doba zpracování požadavků.
Může být také užitečné poskytnout nástroje, které operátorovi umožňují odhalit korelace, například:
- Počet souběžných uživatelů oproti latenci požadavků (jak dlouho trvá zahájení zpracování požadavku po odeslání žádosti).
- Počet souběžných uživatelů oproti průměrné době odezvy (jak dlouho trvá dokončení požadavku po zahájení zpracování).
- Objem požadavků versus počet chyb zpracování.
Kromě těchto informací o funkcích vysoké úrovně by měl být operátor schopný získat podrobné zobrazení výkonu pro každou komponentu v systému. Tato data se obvykle poskytují prostřednictvím čítačů výkonu nízké úrovně, které sledují informace, jako jsou:
- Využití paměti
- Počet vláken
- Doba zpracování procesoru
- Délka fronty žádosti
- Frekvence vstupně-výstupních operací disku nebo sítě a chyby
- Počet zapsaných nebo přečtených bajtů
- Indikátory middlewaru, jako je délka fronty
Všechny vizualizace by měly operátorovi umožnit zadat časové období. Zobrazená data můžou být snímkem aktuální situace nebo historickým zobrazením výkonu.
Operátor by měl být schopen vyvolat výstrahu na základě jakékoli míry výkonu pro libovolnou zadanou hodnotu během libovolného zadaného časového intervalu.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Můžete shromažďovat data o výkonu vysoké úrovně (například propustnost, počet souběžných uživatelů, počet obchodních transakcí a chybovost) monitorováním průběhu požadavků uživatelů při jejich doručení a průchodu systémem. To zahrnuje zahrnutí příkazů trasování v klíčových bodech kódu aplikace spolu s informacemi o načasování. Všechny chyby, výjimky a upozornění by měly být zachyceny s dostatečnými daty pro jejich korelaci s požadavky, které je způsobily.
Pokud je to možné, měli byste také zaznamenávat údaje o výkonu pro všechny externí systémy, které aplikace používá. Tyto externí systémy můžou poskytovat vlastní čítače výkonu nebo jiné funkce pro vyžádání dat o výkonu. Pokud to není možné, zaznamenejte informace, jako je počáteční čas a koncový čas každého požadavku provedeného v externím systému, spolu se stavem (úspěch, selhání nebo upozornění) operace. Můžete například použít přístup stopek k časovým žádostem: spuštění časovače při spuštění požadavku a zastavení časovače po dokončení požadavku.
Data o nízké úrovni výkonu pro jednotlivé komponenty v systému můžou být dostupná prostřednictvím funkcí a služeb, jako jsou čítače výkonu Windows a Diagnostika Azure.
Analýza dat o výkonu
Velká část analýzy se skládá z agregace dat o výkonu podle typu požadavku uživatele nebo subsystému nebo služby, do které se každý požadavek odesílá. Příkladem žádosti uživatele je přidání položky do nákupního košíku nebo provedení procesu rezervace v systému elektronického obchodování.
Dalším běžným požadavkem je shrnutí údajů o výkonu ve vybraných percentilech. Operátor může například určit dobu odezvy 99 procent požadavků, 95 procent požadavků a 70 procent požadavků. Pro každý percentil můžou být nastavené cíle SLA nebo jiné cíle. Probíhající výsledky by měly být hlášeny téměř v reálném čase, aby se pomohly odhalit okamžité problémy. Výsledky by se také měly agregovat po delší dobu pro statistické účely.
V případě problémů s latencí ovlivňujících výkon by měl být operátor schopný rychle identifikovat příčinu kritického bodu prozkoumáním latence každého kroku, který každý požadavek provádí. Údaje o výkonu proto musí poskytovat způsob korelace měr výkonu pro každý krok, aby je svážel s konkrétní žádostí.
V závislosti na požadavcích vizualizace může být užitečné vygenerovat a uložit datovou krychli, která obsahuje zobrazení nezpracovaných dat. Tato datová krychle umožňuje komplexní ad hoc dotazování a analýzu informací o výkonu.
Monitorování zabezpečení
Všechny komerční systémy, které obsahují citlivá data, musí implementovat strukturu zabezpečení. Složitost mechanismu zabezpečení je obvykle funkcí citlivosti dat. V systému, který vyžaduje ověření uživatelů, byste měli zaznamenat:
- Všechny pokusy o přihlášení bez ohledu na to, jestli selžou nebo uspěly.
- Všechny operace prováděné ověřeným uživatelem a podrobnosti o všech prostředcích, ke které má přístup.
- Když uživatel ukončí relaci a odhlásí se.
Monitorování může pomoct odhalit útoky na systém. Například velký počet neúspěšných pokusů o přihlášení může znamenat útok hrubou silou. Neočekávaný nárůst požadavků může být výsledkem distribuovaného útoku DDoS (Denial-of-Service). Musíte být připraveni monitorovat všechny požadavky na všechny prostředky bez ohledu na zdroj těchto požadavků. Systém, který má ohrožení zabezpečení přihlašování, může neúmyslně vystavit prostředky vnějšímu světu, aniž by uživatel musel skutečně přihlásit.
Požadavky na monitorování zabezpečení
Nejdůležitější aspekty monitorování zabezpečení by měly operátorovi umožnit rychlé:
- Zjištění pokusů o neoprávněná vniknutí neověřenou entitou
- Identifikujte pokusy entit o provádění operací s daty, pro která nebyl udělen přístup.
- Určete, jestli je systém nebo některá část systému pod útokem zvenčí nebo uvnitř. Například ověřený uživatel se zlými úmysly se může pokoušet systém snížit.
Pro podporu těchto požadavků by měl být operátor upozorněn, pokud:
- Jeden účet provádí opakované neúspěšné pokusy o přihlášení během zadaného období.
- Jeden ověřený účet se během zadaného období opakovaně pokouší získat přístup k zakázanému prostředku.
- Během zadaného období dochází k velkému počtu neověřených nebo neautorizovaných požadavků.
Informace poskytnuté operátorovi by měly obsahovat adresu hostitele zdroje pro každý požadavek. Pokud porušení zabezpečení pravidelně vznikají z určitého rozsahu adres, můžou být tito hostitelé zablokovaní.
Klíčovou součástí udržování zabezpečení systému je schopnost rychle zjišťovat akce, které se odchylují od obvyklého vzoru. Informace, jako je počet neúspěšných nebo úspěšných žádostí o přihlášení, se dají vizuálně zobrazit, aby bylo možné zjistit, jestli v neobvyklé době dochází k prudkému nárůstu aktivity. Příkladem této aktivity je přihlášení uživatelů v 3:00 a provádění velkého počtu operací, když pracovní den začíná v 9:00.
Tyto informace lze použít také ke konfiguraci automatického škálování založeného na čase. Pokud například operátor zjistí, že se v konkrétní denní době pravidelně přihlašuje velký počet uživatelů, může operátor uspořádat další ověřovací služby pro zpracování objemu práce a po uplynutí špičky tyto další služby vypnout.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Zabezpečení je všezahrnující aspekt většiny distribuovaných systémů. Příslušná data se pravděpodobně generují v několika bodech v celém systému. Měli byste zvážit přijetí přístupu pro správu informací o zabezpečení a událostí (SIEM) ke shromáždění informací souvisejících se zabezpečením, které vyplývají z událostí vyvolaných aplikací, síťovým vybavením, servery, branami firewall, antivirovým softwarem a dalšími prvky ochrany před neoprávněným vniknutím.
Monitorování zabezpečení může zahrnovat data z nástrojů, které nejsou součástí vaší aplikace. Tyto nástroje můžou zahrnovat nástroje, které identifikují aktivity prohledávání portů externími institucemi, nebo síťové filtry, které zjistí pokusy o získání neověřeného přístupu k vaší aplikaci a datům. V některých případech nástroje pro nasazení CI/CD také tvoří důležitou součást životního cyklu aplikace a tyto nástroje by také měly označit neobvyklé chování.
Ve všech případech musí shromážděná data správci umožnit určit povahu jakéhokoli útoku a provést příslušná protiopatření.
Analýza dat zabezpečení
Klíčovou funkcí monitorování zabezpečení je, že shromažďuje data z mnoha zdrojů. Různé formáty a úroveň podrobností často vyžadují komplexní analýzu zachycených dat, aby je spojily do koherentního vlákna informací. Kromě základních případů (například zjišťování mnoha neúspěšných přihlášení nebo opakovaných pokusů o získání neoprávněného přístupu k důležitým prostředkům) nemusí být složité automatizované zpracování dat zabezpečení proveditelné. Místo toho může být vhodnější zapsat tato data se časovým razítkem, avšak jinak v jejich původní podobě, do zabezpečeného úložiště, aby bylo umožněno provést odbornou ruční analýzu.
Monitorování smluv SLA
Mnoho komerčních systémů, které podporují placení zákazníků, činí závazky týkající se výkonu systému ve formě smluv SLA. Smlouvy SLA v podstatě uvádějí, že systém dokáže zpracovat definovaný objem práce v rámci schváleného časového rámce a bez ztráty důležitých informací. Monitorování smluv SLA se zabývá zajištěním, aby systém mohl splňovat měřitelné smlouvy SLA.
Poznámka:
Monitorování smlouvy SLA úzce souvisí s monitorováním výkonu. Vzhledem k tomu, že monitorování výkonu je zaměřeno na zajištění optimálního fungování systému, řídí se monitorování SLA smluvní povinností, která definuje, co optimálně skutečně znamená.
SLA jsou často definovány v těchto termínech:
- Celková dostupnost systému. Organizace se například může zavázat k tomu, že systém bude dostupný 99,9 % času. To odpovídá ne více než 9 hodin výpadkům za rok nebo přibližně 10 minut týdně.
- Provozní propustnost. Tento aspekt se často vyjadřuje pomocí jednoho nebo více ukazatelů výkonnosti, například závazku, že systém může podporovat až 100 000 souběžných uživatelských požadavků nebo zpracovat 10 000 souběžných obchodních transakcí.
- Provozní doba odezvy. Systém může také učinit závazky týkající se rychlosti zpracování požadavků. Příkladem je, že 99 % všech obchodních transakcí se dokončí během dvou sekund a jedna transakce trvá déle než 10 sekund.
Poznámka:
Některé smlouvy o komerčních systémech můžou zahrnovat také smlouvy SLA pro zákaznickou podporu. Příkladem je, že všechny žádosti help-desku vyvolaly odpověď během pěti minut a že 99 procent všech problémů je plně vyřešeno během jednoho pracovního dne. Efektivní sledování problémů (popsané dále v této části) je klíčem ke splnění smluv SLA, jako jsou tyto.
Požadavky na monitorování smluv SLA
Na nejvyšší úrovni by měl být operátor schopen zjistit na první pohled, jestli systém splňuje schválené smlouvy SLA, nebo ne. Pokud ne, operátor by měl být schopný přejít k podrobnostem a prozkoumat podkladové faktory a určit důvody pro nestandardní výkon.
Mezi typické indikátory vysoké úrovně, které lze vizuálně znázornit, patří:
- Procento doby provozu služby.
- Propustnost aplikace (měřená z hlediska úspěšných transakcí nebo operací za sekundu)
- Počet úspěšných a neúspěšných požadavků aplikace.
- Počet chyb aplikací a systémů, výjimek a upozornění.
Všechny tyto indikátory by měly být schopné filtrovat podle zadaného časového období.
Cloudová aplikace pravděpodobně zahrnuje několik subsystémů a komponent. Operátor by měl být schopný vybrat ukazatel vysoké úrovně a zjistit, jak se skládá ze stavu podkladových prvků. Pokud například doba provozu celého systému klesne pod přijatelnou hodnotu, operátor by měl být schopný přiblížit a určit, které prvky přispívají k tomuto selhání.
Poznámka:
Dostupnost systému musí být definovaná pečlivě. V systému, který používá redundanci k zajištění maximální dostupnosti, může dojít k selhání jednotlivých instancí prvků, ale systém může zůstat funkční. Dostupnost systému, jak je prezentováno monitorováním stavu, by měla indikovat agregovanou dobu provozu jednotlivých prvků, a ne nutně to, jestli se systém skutečně zastavil. Kromě toho může být selhání izolovaná. Takže i když je určitý systém nedostupný, zbytek systému může zůstat dostupný, i když s nižší funkčností. V systému elektronického obchodování může selhání systému bránit zákazníkovi v zadávání objednávek, ale zákazník může stále procházet katalog produktů.
Pro účely upozorňování by systém měl být schopný vyvolat událost, pokud některý z indikátorů vysoké úrovně překročí zadanou prahovou hodnotu. Podrobnosti na nižší úrovni různých faktorů, které tvoří ukazatel vysoké úrovně, by měly být k dispozici jako kontextová data pro systém výstrah.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Nezpracovaná data potřebná k podpoře monitorování SLA se podobají surovým datům potřebným pro monitorování výkonu, spolu s některými aspekty monitorování stavu a dostupnosti. Další informace najdete v těchto částech. Tato data můžete zachytit takto:
- Provádění monitorování koncových bodů
- Protokolování výjimek, chyb a upozornění
- Trasování provádění uživatelských požadavků
- Monitorování dostupnosti všech služeb třetích stran, které systém používá.
- Použití metrik výkonu a čítačů
Všechna data musí být načasovaná a opatřená časovými razítky.
Analýza dat SLA
Data instrumentace musí být agregována, aby se vygeneroval obrázek celkového výkonu systému. Agregovaná data musí také podporovat přechod k podrobnostem, aby bylo možné zkoumat výkon základních subsystémů. Měli byste být například schopni:
- Vypočítejte celkový počet uživatelských požadavků během zadaného období a určete úspěšnost a míru selhání těchto požadavků.
- Zkombinujte doby odezvy uživatelských požadavků a vygenerujte celkový přehled doby odezvy systému.
- Analyzujte průběh uživatelských požadavků, abyste rozdělili celkovou dobu odezvy požadavku do doby odezvy jednotlivých pracovních položek v této žádosti.
- Určete celkovou dostupnost systému jako procento doby provozu pro každé konkrétní období.
- Analyzujte procento dostupnosti jednotlivých komponent a služeb v systému. To může zahrnovat analýzu protokolů, které vygenerovaly služby třetích stran.
Mnoho komerčních systémů musí předkládat skutečné údaje o výkonnosti podle dohodnutých SLA za určité období, obvykle měsíc. Tyto informace lze použít k výpočtu kreditů nebo jiných forem splátek pro zákazníky, pokud během tohoto období nejsou splněny smlouvy SLA. Dostupnost služby můžete vypočítat pomocí techniky popsané v části Analýza dat dostupnosti.
Pro interní účely může organizace také sledovat počet a povahu incidentů, které způsobily selhání služeb. Když se naučíte, jak tyto problémy rychle vyřešit nebo je úplně odstranit, pomůžete snížit výpadky a splnit smlouvy SLA.
Kontrola
V závislosti na povaze aplikace může existovat zákonné nebo jiné právní předpisy, které určují požadavky na auditování operací uživatelů a zaznamenávání veškerého přístupu k datům. Auditování může poskytnout důkazy, které spojují zákazníky s konkrétními požadavky. Nonrepudiace je důležitým faktorem v mnoha e-obchodních systémech, aby se udržovala důvěra mezi zákazníkem a organizací odpovědnou za aplikaci nebo službu.
Požadavky na auditování
Analytik musí být schopný sledovat posloupnost obchodních operací, které uživatelé provádějí, abyste mohli rekonstruovat akce uživatelů. Tento záznam může být nezbytný pro účely dokumentace nebo jako součást forenzního vyšetřování.
Informace o auditu jsou vysoce citlivé. Pravděpodobně obsahuje data, která identifikují uživatele systému spolu s úlohami, které provádějí. Z tohoto důvodu mají informace o auditu formu sestav dostupných pouze důvěryhodným analytikům, spíše než interaktivní systém podporující podrobné procházení grafických operací. Analytik by měl být schopen vygenerovat celou řadu reportů. Sestavy můžou například zobrazit seznam všech aktivit uživatelů, ke kterým dochází během zadaného časového rámce, podrobně zobrazit chronologii aktivity pro jednoho uživatele nebo zobrazit posloupnost operací provedených s jedním nebo více prostředky.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Mezi primární zdroje informací pro auditování patří:
- Systém zabezpečení, který spravuje ověřování uživatelů.
- Sledovací protokoly, které zaznamenávají aktivity uživatelů.
- Protokoly zabezpečení, které sledují všechny identifikovatelné a neidentifikovatelné síťové požadavky.
Formát dat auditu a způsob, jakým jsou uložena, může být řízen zákonnými požadavky. Pokud předpisy vyžadují, aby byla data zaznamenána v původním formátu, nemusí být možné data žádným způsobem vyčistit. Proto musí být přístup k úložišti, kde je uložen, úzce chráněn, aby se zabránilo manipulaci.
Analýza dat auditu
Analytik musí mít přístup k nezpracovaným datům v celé jeho původní podobě. Kromě požadavku na generování běžných sestav auditu budou nástroje pro analýzu těchto dat pravděpodobně specializované a budou se uchovávat mimo systém.
Monitorování využití
Monitorování využití sleduje, jak se používají funkce a součásti aplikace. Operátor může shromážděná data použít k:
Určete, které funkce se silně používají, a určete případné hotspoty v systému. Prvky s vysokým provozem můžou těžit z funkčního dělení nebo dokonce replikace, aby se zatížení rovnoměrněji rozložily. Operátor může tyto informace použít také ke zjištění, které funkce se často používají a které jsou možné kandidáty na vyřazení nebo nahrazení v budoucí verzi systému.
Získejte informace o provozních událostech systému v normálním použití. Například na webu elektronického obchodování můžete zaznamenávat statistické informace o počtu transakcí a objemu zákazníků, kteří za ně zodpovídají. Tyto informace je možné použít k plánování kapacity s rostoucím počtem zákazníků.
Zjištění (pravděpodobně nepřímo) spokojenosti uživatele s výkonem nebo funkčností systému Pokud například velký počet zákazníků v systému elektronického obchodování pravidelně opouští své nákupní košíky, může to být způsobeno problémem s funkcí rezervace.
Generování fakturačních údajů Komerční aplikace nebo víceklientová služba můžou zákazníkům účtovat poplatky za prostředky, které používají.
Vynucujte kvóty. Pokud uživatel v systému s více tenanty překročí svou placenou kvótu času zpracování nebo využití prostředků během zadaného období, může být přístup omezený nebo může být omezen.
Rozpozná problémy s hlučnou sousedou. Schopnost určit, jestli je provoz rovnoměrně rozložený nebo jestli malá skupina uživatelů generuje velkou část, může pomoct při vyšetřování chyb nebo rozhodování o produktech. Pokud je jeden uživatel jediným uživatelem, který používá funkci aplikace a který generuje odchozí objem provozu, může to znamenat, že tato funkce potřebuje určitou optimalizaci výkonu. Případně se můžete rozhodnout, že pro vyřešení problému uložíte další kvóty.
Požadavky na monitorování využití
K prozkoumání využití systému obvykle potřebuje operátor zobrazit informace, které zahrnují:
- Počet požadavků, které jsou zpracovány jednotlivými subsystémy a směrovány na každý prostředek.
- Práce, kterou každý uživatel provádí.
- Objem úložiště dat, které každý uživatel zabírá.
- Prostředky, ke kterým každý uživatel přistupuje.
Operátor by měl být také schopný generovat grafy. Mezi běžné příklady generovaných grafů patří grafy, které zobrazují uživatele, kteří spotřebovávají nejvíce prostředků, a nejčastěji využívané prostředky nebo funkce systému.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Sledování využití je možné provádět na relativně vysoké úrovni. Může si všimnout počátečního a koncového času každého požadavku a povahy požadavku (v závislosti na příslušném prostředku na čtení, zápisu a dalších požadavcích). Tyto informace můžete získat takto:
- Trasování aktivity uživatelů
- Zaznamenávání čítačů výkonu, které měří využití jednotlivých prostředků.
- Monitorování spotřeby prostředků jednotlivými uživateli
Pro účely měření musíte být také schopni zjistit, kteří uživatelé zodpovídají za provádění operací a prostředků, které tyto operace používají. Shromážděné informace by měly být dostatečně podrobné, aby bylo možné povolit přesnou fakturaci.
Sledování problémů
Zákazníci a jiní uživatelé můžou nahlásit problémy, pokud v systému dojde k neočekávaným událostem nebo chováním. Sledování problémů se zabývá správou těchto problémů, jejich přidružením k řešení jakýchkoli hlubších problémů v systému a informováním zákazníků o možných řešeních.
Požadavky na sledování problémů
Operátoři často provádějí sledování problémů pomocí samostatného systému, který jim umožňuje zaznamenávat a hlásit podrobnosti o problémech, které uživatelé hlásí. Tyto podrobnosti mohou zahrnovat úlohy, které se uživatel pokusil provést, příznaky problému, posloupnost událostí a všechny chybové nebo výstražné zprávy, které byly vydány.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Počátečním zdrojem dat pro data sledování problémů je uživatel, který problém nahlásil na prvním místě. Uživatel může poskytnout další data, například:
- Výpis stavu systému (pokud aplikace obsahuje komponentu, která běží na počítači uživatele).
- Snímek obrazovky
- Datum a čas výskytu chyby spolu s dalšími informacemi o prostředí, jako je umístění uživatele.
Tyto informace lze použít k usnadnění procesu ladění a vytvoření plánu úkolů pro budoucí verze softwaru.
Analýza dat sledování problémů
Stejný problém můžou nahlásit různí uživatelé. Systém sledování problémů by měl přidružit společné zprávy.
Průběh ladění by měl být zaznamenáván u každé zprávy o problému. Po vyřešení problému může být zákazník o řešení informován.
Pokud uživatel hlásí problém se známým řešením v systému sledování problémů, operátor by měl být schopen uživatele o řešení informovat okamžitě.
Trasování operací a ladění softwarových verzí
Když uživatel hlásí problém, často si je vědom pouze okamžitého účinku, který má na své operace. Uživatel může hlásit pouze výsledky vlastní zkušenosti operátorovi, který je zodpovědný za údržbu systému. Tyto zkušenosti jsou obvykle jen viditelným příznakem jednoho nebo více základních problémů. V mnoha případech musí analytik prozkoumat chronologii základních operací, aby vytvořil hlavní příčinu problému. Tento proces se nazývá analýza původní příčiny.
Poznámka:
Analýza původní příčiny může odhalit nedostatky v návrhu aplikace. V těchto situacích může být možné přepracovat ovlivněné prvky a nasadit je jako součást následné verze. Tento proces vyžaduje pečlivou kontrolu a aktualizované komponenty by měly být pečlivě sledovány.
Požadavky na trasování a ladění
Pro trasování neočekávaných událostí a dalších problémů je důležité, aby data monitorování poskytovala dostatek informací, aby analytik mohl sledovat původ těchto problémů a rekonstruovat posloupnost událostí, ke kterým došlo. Tyto informace musí stačit k tomu, aby analytik mohl diagnostikovat původní příčinu jakýchkoli problémů. Vývojář pak může provést potřebné úpravy, aby se zabránilo jejich opakování.
Požadavky na zdroje dat, instrumentaci a shromažďování dat
Řešení potíží může zahrnovat trasování všech metod (a jejich parametrů) vyvolaných v rámci operace za účelem vytvoření stromu, který znázorňuje logický tok systémem, když zákazník provede konkrétní požadavek. Výjimky a upozornění, které systém generuje v důsledku tohoto toku, musí být zaznamenány a protokolovány.
Kvůli podpoře ladění může systém poskytovat háky, které operátorovi umožňují zaznamenávat informace o stavu v klíčových bodech systému. Systém může také poskytovat podrobné podrobné informace o průběhu vybraných operací. Zachytávání dat na této úrovni podrobností může znamenat dodatečné zatížení systému a mělo by se jednat o dočasný proces. Operátor tento proces používá hlavně v případě, že dojde k velmi neobvyklé řadě událostí a je obtížné je replikovat, nebo když nová verze jednoho nebo více prvků do systému vyžaduje pečlivé monitorování, aby se zajistilo, že prvky fungují podle očekávání.
Kanál monitorování a diagnostiky
Monitorování velkého distribuovaného systému je velkou výzvou. Každý ze scénářů popsaných v předchozí části by se neměl nutně považovat za izolovanou. V monitorování a diagnostických datech, která jsou nutná pro každou situaci, se pravděpodobně výrazně překrývají, i když tato data může být potřeba zpracovávat a prezentovat různými způsoby. Z těchto důvodů byste měli vzít holistický pohled na monitorování a diagnostiku.
Celý proces monitorování a diagnostiky si můžete představit jako kanál, který se skládá z fází zobrazených na obrázku 1.
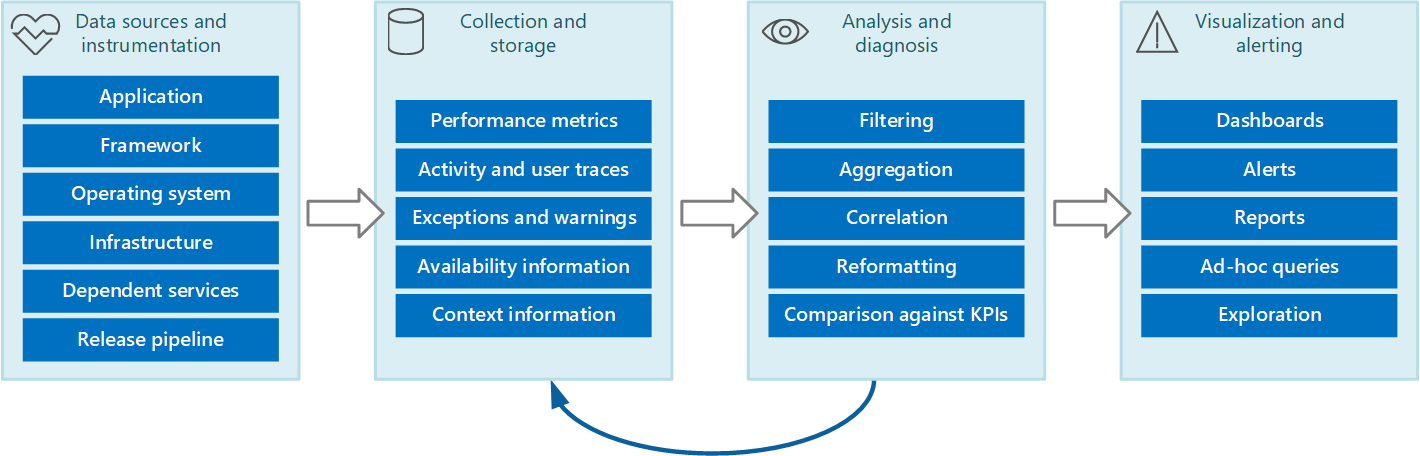
Obrázek 1 – Fáze v kanálu monitorování a diagnostiky
Obrázek 1 zdůrazňuje, jak můžou data pro monitorování a diagnostiku pocházet z různých zdrojů dat. Fáze instrumentace a shromažďování se zabývají identifikací zdrojů, ze kterých je potřeba data zachytit, určit, která data se mají zachytit, jak je zachytit, jak je naformátovat, aby bylo možné je snadno prozkoumat. Fáze analýzy/diagnostiky přebírá nezpracovaná data a používá je k vygenerování smysluplných informací, které může operátor použít k určení stavu systému. Operátor může tyto informace použít k rozhodování o možných akcích, které se mají provést, a výsledky pak vrátit zpět do fází instrumentace a shromažďování. Fáze vizualizace/upozorňování představuje srozumitelné zobrazení stavu systému. Může zobrazovat informace téměř v reálném čase pomocí řady řídicích panelů. A může generovat sestavy, grafy a diagramy, které poskytují historický pohled na data, jež pomáhají identifikovat dlouhodobé trendy. Pokud informace naznačují, že klíčový ukazatel výkonu pravděpodobně překročí přijatelné hranice, může tato fáze také aktivovat upozornění na operátora. V některých případech lze výstrahu použít také k aktivaci automatizovaného procesu, který se pokusí provést opravné akce, jako je automatické škálování.
Tyto kroky představují proces průběžného toku, ve kterém se fáze provádějí paralelně. V ideálním případě by měly být všechny fáze dynamicky konfigurovatelné. V některých případech, zejména v případě, že je systém nově nasazený nebo dochází k problémům, může být nutné shromažďovat rozšířená data častěji. Jindy by mělo být možné vrátit se k zachycení základní úrovně základních informací, abyste ověřili, že systém funguje správně.
Kromě toho by se celý proces monitorování měl považovat za živé, probíhající řešení, které je předmětem vyladění a vylepšení v důsledku zpětné vazby. Můžete například začít měřením mnoha faktorů, které určují stav systému. Analýza v průběhu času může vést k vylepšení, protože zahodíte míry, které nejsou relevantní, a umožní vám přesněji zaměřit se na potřebná data a minimalizovat šum na pozadí.
Zdroje monitorovacích a diagnostických dat
Informace, které proces monitorování používá, mohou pocházet z několika zdrojů, jak je znázorněno na obrázku 1. Na úrovni aplikace pocházejí informace z protokolů trasování začleněných do kódu systému. Vývojáři by měli dodržovat standardní přístup ke sledování toku řízení prostřednictvím kódu. Například položka metody může generovat trasovací zprávu, která určuje název metody, aktuální čas, hodnotu každého parametru a všechny další relevantní informace. Záznam doby vstupu a ukončení může být také užitečný.
Měli byste protokolovat všechny výjimky a upozornění a postarat se o to, abyste zachovali úplné trasování všech vnořených výjimek a upozornění. V ideálním případě byste měli zaznamenávat také informace, které identifikují uživatele, který kód spouští, spolu s informacemi o korelaci aktivit (ke sledování požadavků při průchodu systémem). Měli byste také protokolovat pokusy o přístup ke všem prostředkům, jako jsou fronty zpráv, databáze, soubory a další závislé služby. Tyto informace lze použít pro účely měření a auditování.
Mnoho aplikací používá knihovny a architektury k provádění běžných úloh, jako je přístup k úložišti dat nebo komunikace přes síť. Tyto architektury můžou být konfigurovatelné tak, aby poskytovaly vlastní trasovací zprávy a nezpracované diagnostické informace, jako jsou rychlosti transakcí a úspěšnost přenosu dat a selhání.
Poznámka:
Mnoho moderních frameworků automaticky zveřejňuje události výkonu a sledování. Zachycení těchto informací zahrnuje způsob, jak načíst a uložit události, aby je bylo možné zpracovat a analyzovat.
Operační systém, na kterém je aplikace spuštěná, může být zdrojem informací na úrovni systému nízké úrovně, jako jsou čítače výkonu, které označují rychlost vstupně-výstupních operací, využití paměti a využití procesoru. Chyby operačního systému (například chyby při správném otevření souboru) mohou být hlášeny také.
Měli byste také zvážit základní infrastrukturu a komponenty, na kterých běží váš systém. Virtuální počítače, virtuální sítě a služby úložiště můžou být zdroji důležitých čítačů výkonu na úrovni infrastruktury a dalších diagnostických dat.
Pokud vaše aplikace používá jiné externí služby, jako je webový server nebo systém pro správu databází, můžou tyto služby publikovat vlastní informace o trasování, protokoly a čítače výkonu. Mezi příklady patří zobrazení dynamické správy SQL Serveru pro sledování operací prováděných s databází SQL Serveru a protokoly trasování Application Insights pro zaznamenávání požadavků provedených ve službě Azure App Service.
Při úpravě součástí systému a nasazení nových verzí je důležité mít možnost přiřazovat problémy, události a metriky pro každou verzi. Tyto informace by měly být propojené s vydávací pipeline, aby bylo možné rychle vysledovat a napravit problémy s konkrétní verzí komponenty.
K problémům se zabezpečením může dojít v jakémkoli okamžiku v systému. Uživatel se například může pokusit přihlásit pomocí neplatného ID uživatele nebo hesla. Ověřený uživatel se může pokusit získat neoprávněný přístup k prostředku. Nebo uživatel může poskytnout neplatný nebo zastaralý klíč pro přístup k šifrovaným informacím. Informace související se zabezpečením pro úspěšné a neúspěšné požadavky by se měly vždy protokolovat.
Část Instrumentace aplikace obsahuje další pokyny k informacím, které byste měli zaznamenat. K získání těchto informací ale můžete použít různé strategie:
Monitorování aplikací a systémů. Tato strategie používá interní zdroje v rámci aplikace, aplikačních architektur, operačního systému a infrastruktury. Kód aplikace může během životního cyklu požadavku klienta vygenerovat vlastní data monitorování v kritických bodech. Aplikace může obsahovat příkazy trasování, které mohou být selektivně povoleny nebo zakázány při diktování okolností. Pomocí diagnostické architektury může být také možné dynamicky vkládat diagnostiku. Tyto frameworky obvykle poskytují doplňky, které lze připojit k různým bodům instrumentace ve vašem kódu a zachytávat sledovací data v těchto bodech.
Kromě toho může váš kód nebo základní infrastruktura vyvolat události v kritických bodech. Monitorovací agenti nakonfigurovaní tak, aby naslouchali těmto událostem, mohou zaznamenávat informace o událostech.
Monitorování skutečných uživatelů Tento přístup zaznamenává interakce mezi uživatelem a aplikací a sleduje tok jednotlivých požadavků a odpovědí. Tyto informace můžou mít dvounásobný účel: dají se použít k měření využití jednotlivými uživateli a dají se použít k určení, jestli uživatelé dostávají vhodnou kvalitu služby (například rychlá doba odezvy, nízká latence a minimální chyby). Zachycená data můžete použít k identifikaci oblastí zájmu, ve kterých nejčastěji dochází k selháním. Data můžete také použít k identifikaci prvků, ve kterých se systém zpomalí, pravděpodobně kvůli hotspotům v aplikaci nebo nějaké jiné formě kritických bodů. Pokud tento přístup implementujete pečlivě, může být možné rekonstruovat toky uživatelů prostřednictvím aplikace pro účely ladění a testování.
Důležité
Data zachycená při monitorování skutečných uživatelů byste měli považovat za vysoce citlivá, protože mohou obsahovat důvěrné materiály. Pokud uložíte zachycená data, bezpečně je uložte. Pokud chcete data použít pro účely monitorování výkonu nebo ladění, nejprve odstraňte všechna osobní data.
Syntetické monitorování uživatelů. V tomto přístupu napíšete vlastního testovacího klienta, který simuluje uživatele a provádí konfigurovatelnou, ale typickou řadu operací. Můžete sledovat výkon testovacího klienta, abyste mohli určit stav systému. V rámci operace zátěžového testování můžete také použít více instancí testovacího klienta, abyste určili, jak systém reaguje pod stresem a jaký druh výstupu monitorování se vygeneruje za těchto podmínek.
Poznámka:
Skutečné a syntetické monitorování uživatelů můžete implementovat tak, že zahrnete kód, který trasuje a krát provádění volání metod a dalších důležitých částí aplikace.
Profilace. Tento přístup je primárně zaměřen na monitorování a zlepšení výkonu aplikace. Místo toho, aby fungoval na funkční úrovni skutečného a syntetického monitorování uživatelů, zachycuje informace na nižší úrovni při spuštění aplikace. Profilaci můžete implementovat pomocí pravidelného vzorkování stavu spuštění aplikace (určení, který kód aplikace běží v daném časovém okamžiku). Můžete také použít instrumentaci, která vloží sondy do kódu na důležitých místech (jako je začátek a konec volání metody) a zaznamenává, které metody byly vyvolány, kdy a jak dlouho každé volání trvalo. Pak můžete tato data analyzovat a určit, které části aplikace můžou způsobit problémy s výkonem.
Monitorování koncových bodů Tato technika používá jeden nebo více diagnostických koncových bodů, které aplikace zveřejňuje speciálně k povolení monitorování. Koncový bod poskytuje cestu do kódu aplikace a může vracet informace o stavu systému. Různé koncové body se můžou zaměřit na různé aspekty funkčnosti. Můžete napsat vlastního diagnostického klienta, který odesílá pravidelné požadavky na tyto koncové body a assimilovat odpovědi. Další informace najdete v modelu monitorování koncových bodů stavu.
Uživatelské výpisy chyb Tato technika spoléhá na aplikaci, která poskytuje elegantní způsob, jak shromáždit snímek stavu aplikace, pokud nemůže obnovit, a aby uživatelé dobrovolně sdíleli tento snímek. I když není zaručeno, že bude vždy spuštěno, data nižší úrovně poskytovaná výpisem chyb mohou být neuvěřitelně užitečná k zjištění příčiny chyb. To platí zejména v případě, že k dotyčným chybám dochází zřídka nebo pokud jsou chyby izolované na méně často používanou funkci v aplikaci.
Pro maximální pokrytí byste měli použít kombinaci těchto technik.
Instrumentace aplikace
Instrumentace je důležitou součástí procesu monitorování. Smysluplná rozhodnutí o výkonu a stavu systému můžete provádět pouze v případě, že data, která vám umožní tato rozhodnutí provést, nejprve zachytíte. Informace, které shromažďujete pomocí instrumentace, by měly stačit k tomu, abyste mohli posoudit výkon, diagnostikovat problémy a rozhodovat se, aniž byste se museli přihlásit ke vzdálenému produkčnímu serveru, abyste mohli provádět trasování (a ladění) ručně. Data instrumentace obvykle zahrnují metriky a informace zapsané do protokolů trasování.
Obsah protokolu trasování může být výsledkem textových dat, která jsou napsána aplikací nebo binárními daty vytvořenými v důsledku události trasování, pokud aplikace používá trasování událostí pro Windows (ETW). Dají se také generovat ze systémových protokolů, které zaznamenávají události vyplývající z částí infrastruktury, jako je webový server. Zprávy textového protokolu jsou často navržené tak, aby byly čitelné pro člověka, ale měly by být napsané také ve formátu, který umožňuje automatizovanému systému snadno analyzovat je.
Měli byste také kategorizovat protokoly. Nezapisujte všechna data trasování do jednoho protokolu, ale použijte samostatné protokoly k zaznamenání výstupu trasování z různých provozních aspektů systému. Zprávy protokolu pak můžete rychle filtrovat čtením z příslušného protokolu a nemusíte zpracovávat jeden dlouhý soubor. Nikdy nezapisujte informace, které mají různé požadavky na zabezpečení (například informace o auditu a ladicí data) do stejného protokolu.
Poznámka:
Protokol lze implementovat jako soubor v systému souborů, nebo může být uložen v jiném formátu, například jako blob v blobovém úložišti. Informace protokolu se můžou uchovávat také ve strukturovanějším úložišti, například v řádcích v tabulce.
Metriky jsou obecně míra nebo počet některých aspektů nebo prostředků v systému v určitém okamžiku s jednou nebo více přidruženými značkami nebo dimenzemi (někdy označovanými jako ukázka). Jedna instance metriky obvykle není užitečná izolovaně. Místo toho je potřeba zaznamenávat metriky v průběhu času. Klíčovým problémem, který je potřeba vzít v úvahu, je to, které metriky byste měli zaznamenávat a jak často. Generování dat pro metriky příliš často může znamenat významné dodatečné zatížení systému, zatímco příliš vzácný sběr metrik může způsobit, že přehlédnete okolnosti vedoucí k významné události. Aspekty se liší od metriky po metriku. Například využití procesoru na serveru může kolísat od sekundy po sekundu, ale vysoké využití se stává starostí pouze v případě, že trvá několik minut.
Informace o korelaci dat
Můžete snadno monitorovat jednotlivé čítače výkonu na úrovni systému, zaznamenávat metriky pro prostředky a získávat informace o trasování aplikací z různých souborů protokolů. Některé formy monitorování ale vyžadují, aby fáze analýzy a diagnostiky v kanálu monitorování korelovala data načtená z několika zdrojů. Tato data mohou mít v nezpracovaných datech několik forem a proces analýzy musí mít k dispozici dostatečná data k instrumentaci, aby bylo možné mapovat tyto různé formy. Například na úrovni architektury aplikace může být úloha identifikována ID vlákna. V rámci aplikace může být stejná práce přidružená k ID uživatele, který tuto úlohu provádí.
Také není pravděpodobné, že by mezi vlákny a požadavky uživatelů bylo mapování 1:1, protože asynchronní operace můžou opakovaně používat stejná vlákna k provádění operací jménem více uživatelů. Aby se situace dále zkomplikovala, může jeden požadavek zpracovávat více než jedno vlákno, protože provádění prochází systémem. Pokud je to možné, přidružte každý požadavek k jedinečnému ID aktivity, které se šíří v systému jako součást kontextu požadavku. (Technika generování a zahrnutí ID aktivit v informacích o trasování závisí na technologii, která se používá k zachycení dat trasování.)
Všechna monitorovací data by měla být časově označena stejným způsobem. Pro konzistenci zaznamenejte všechna data a časy pomocí koordinovaného univerzálního času (UTC). To vám pomůže snadněji sledovat posloupnosti událostí.
Poznámka:
Počítače fungující v různých časových pásmech a sítích nemusí být synchronizované. Nespoléhejte na použití časových razítek pouze pro korelaci dat instrumentace, která pokrývají více počítačů.
Informace, které se mají zahrnout do dat instrumentace
Při rozhodování o tom, která data instrumentace potřebujete shromáždit, zvažte následující body:
Ujistěte se, že informace zachycené událostmi sledování jsou strojově a lidsky čitelné. K usnadnění automatizovaného zpracování dat protokolů napříč systémy a zajištění konzistence provozním a technickým pracovníkům, kteří protokoly čtou, osvojte si dobře definovaná schémata pro tyto informace. Uveďte informace o prostředí, jako je prostředí nasazení, počítač, na kterém je proces spuštěný, podrobnosti procesu a zásobník volání.
Povolte profilování pouze tehdy, když je to nezbytné, protože může na systém navést významnou zátěž. Profilace pomocí instrumentace zaznamenává událost (například volání metody) při každém výskytu, zatímco vzorkování zaznamenává pouze vybrané události. Výběr může být založený na čase (jednou za n sekund) nebo na základě frekvence (jednou za každých n požadavků). Pokud se události vyskytují velmi často, může profilování za pomoci instrumentace způsobit příliš velkou zátěž a samo ovlivnit celkový výkon. V takovém případě může být vhodnější přístup k vzorkování. Pokud je však frekvence událostí nízká, může je vzorkování vynechat. V tomto případě by instrumentace mohla být lepším přístupem.
Poskytněte dostatečný kontext, který umožní vývojáři nebo správci určit zdroj jednotlivých požadavků. Může to zahrnovat určitou formu ID aktivity, která identifikuje konkrétní instanci požadavku. Může také obsahovat informace, které lze použít ke korelaci této aktivity s výpočetní prací provedenou a použitými prostředky. Tato práce může překračovat hranice procesů a počítačů. Pro měření by měl kontext zahrnovat (přímo nebo nepřímo prostřednictvím jiných korelovaných informací) odkaz na zákazníka, který tu žádost vyvolal. Tento kontext poskytuje cenné informace o stavu aplikace v době zachycení dat monitorování.
Zaznamenejte všechny požadavky a umístění nebo oblasti, ze kterých se tyto požadavky provádějí. Tyto informace vám můžou pomoct při určování, jestli existují nějaká aktivní místa specifická pro polohu. Tyto informace mohou být užitečné také při rozhodování, zda přerozdělit aplikaci nebo data, která využívá.
Zaznamenejte a pečlivě zaznamenejte podrobnosti o výjimkách. Důležité informace o ladění se často ztratí v důsledku špatného zpracování výjimek. Zachyťte úplné podrobnosti o výjimkách, které aplikace vyvolá, včetně jakýchkoli vnitřních výjimek a dalších kontextových informací. Pokud je to možné, zahrňte zásobník volání.
Buďte konzistentní v datech, která zachycují různé prvky aplikace, protože to může pomoct při analýze událostí a jejich korelaci s požadavky uživatelů. Zvažte použití komplexního a konfigurovatelného balíčku protokolování ke shromažďování informací místo toho, aby vývojáři přijali stejný přístup jako implementovali různé části systému. Shromážděte data z klíčových čítačů výkonu, jako je objem provedených vstupně-výstupních operací, využití sítě, počet požadavků, využití paměti a využití procesoru. Některé služby infrastruktury mohou poskytovat vlastní specifické čítače výkonu, například počet připojení k databázi, rychlost provádění transakcí a počet transakcí, které jsou úspěšné nebo neúspěšné. Aplikace můžou také definovat vlastní specifické čítače výkonu.
Protokolujte všechna volání externích služeb, jako jsou databázové systémy, webové služby nebo jiné služby na úrovni systému, které jsou součástí infrastruktury. Zaznamenává informace o době potřebné k provedení každého volání a o úspěchu nebo selhání hovoru. Pokud je to možné, zachyťte informace o všech pokusech o opakování a selháních všech přechodných chyb, ke kterým dochází.
Zajištění kompatibility se systémy telemetrie
V mnoha případech se informace, které instrumentace vytváří, generují jako řadu událostí a předávají se samostatnému systému telemetrie pro účely zpracování a analýzy. Telemetrický systém je obvykle nezávislý na jakékoli konkrétní aplikaci nebo technologii, ale očekává, že informace budou následovat podle konkrétního formátu, který je obvykle definován schématem. Schéma efektivně určuje kontrakt, který definuje datová pole a typy, které může ingestovat telemetrický systém. Schéma by mělo být generalizováno tak, aby umožňovalo data přicházející z celé řady platforem a zařízení. Jedním z příkladů široce používané architektury a schématu je OpenTelemetry.
Společné schéma by mělo obsahovat pole, která jsou společná pro všechny události instrumentace, jako je název události, čas události, IP adresa odesílatele a podrobnosti potřebné pro korelaci s jinými událostmi (například ID uživatele, ID zařízení a ID aplikace). Mějte na paměti, že jakýkoli počet zařízení může vyvolat události, takže schéma by nemělo záviset na typu zařízení. Kromě toho mohou různá zařízení vyvolat události pro stejnou aplikaci; aplikace může podporovat roaming nebo jinou formu distribuce mezi zařízeními.
Schéma může také zahrnovat pole domény, která jsou relevantní pro konkrétní scénář, který je společný v různých aplikacích. Může se jednat o informace o výjimkách, událostech spuštění a ukončení aplikace a o úspěchu nebo selhání volání rozhraní API webové služby. Všechny aplikace, které používají stejnou sadu polí domény, by měly generovat stejnou sadu událostí, což umožňuje sestavit sadu běžných sestav a analýz.
Schéma může nakonec obsahovat vlastní pole pro zaznamenání podrobností událostí specifických pro aplikaci.
Osvědčené postupy pro instrumentaci aplikací
Následující seznam shrnuje osvědčené postupy instrumentace distribuované aplikace spuštěné v cloudu.
Usnadnit čtení a analýzu protokolů. Pokud je to možné, používejte strukturované protokolování. Buďte struční a popisní ve zprávách protokolu.
Ve všech protokolech identifikujte zdroj a zadejte informace o kontextu a časování při zápisu každého záznamu protokolu.
Pro všechna časová razítka použijte stejné časové pásmo a formát. To pomáhá korelovat události pro operace, které zahrnují hardware a služby spuštěné v různých geografických oblastech.
Kategorizuje protokoly a zapisuje zprávy do příslušného souboru protokolu.
Nezveřejňujte citlivé informace o systému nebo osobních údajích o uživatelích. Před uložením těchto informací je vyčistěte, ale ujistěte se, že jsou zachovány důležité detaily. Odeberte například ID a heslo z libovolného připojovacího řetězce databáze, ale zapište zbývající informace do protokolu, aby analytik mohl určit, že systém přistupuje ke správné databázi. Protokolujte všechny kritické výjimky, ale povolte správci zapnout a vypnout protokolování pro nižší úrovně výjimek a upozornění. Zachyťte a zaznamenejte také všechny informace logiky opakování. Tato data můžou být užitečná při monitorování přechodného stavu systému.
Trasování volání mimo proces, jako jsou požadavky na externí webové služby nebo databáze.
Nekombinujte zprávy protokolu s různými požadavky na zabezpečení ve stejném souboru protokolu. Například do stejného protokolu nezapisujte informace o ladění a auditu.
S výjimkou událostí auditování se ujistěte, že všechna volání protokolování jsou operace aktivované a zapomenuté, které neblokují průběh obchodních operací. Události auditování jsou výjimečné, protože jsou pro firmu klíčové a dají se klasifikovat jako základní součást obchodních operací.
Ujistěte se, že je protokolování rozšiřitelné a nemá žádné přímé závislosti na konkrétním cíli. Například místo psaní informací pomocí System.Diagnostics.Trace definujte abstraktní rozhraní (například ILogger), které zveřejňuje metody protokolování a které je možné implementovat prostřednictvím libovolných vhodných prostředků.
Ujistěte se, že veškeré protokolování je bezporuchové a nikdy nezpůsobí žádné kaskádové chyby. Protokolování nesmí vyvolat žádné výjimky.
Zacházejte s instrumentací jako s probíhajícím iterativním procesem a pravidelně kontrolujte protokoly, nejen v případě problému.
Shromažďování a ukládání dat
Fáze shromažďování procesu monitorování se zabývá načtením informací, které instrumentace generuje, formátováním těchto dat, aby se usnadnila spotřeba fáze analýzy/diagnostiky a uložení transformovaných dat do spolehlivého úložiště. Data instrumentace shromážděná z různých částí distribuovaného systému se dají uchovávat v různých umístěních a s různými formáty. Kód aplikace může například generovat soubory protokolu trasování a generovat data protokolu událostí aplikace, zatímco výkonové čítače, které monitorují klíčové aspekty infrastruktury, kterou vaše aplikace používá, lze zachytit jinými technologiemi. Jakékoli komponenty a služby třetích stran, které vaše aplikace používá, můžou poskytovat informace instrumentace v různých formátech pomocí samostatných trasovacích souborů, úložiště objektů blob nebo dokonce vlastního úložiště dat.
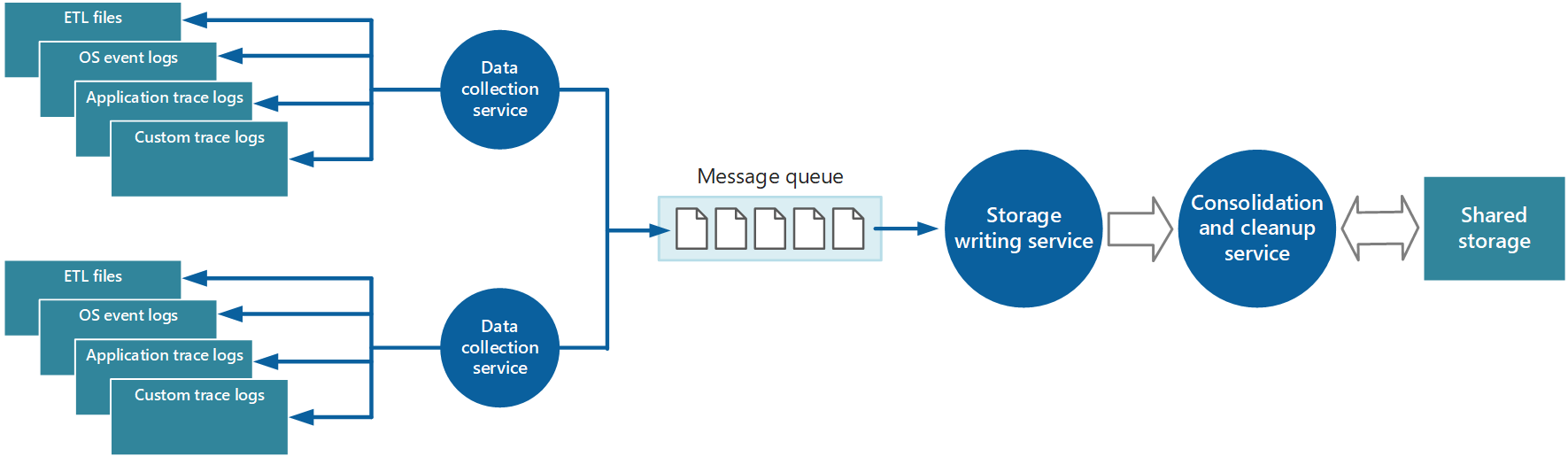
Shromažďování dat se často provádí prostřednictvím služby shromažďování dat, která může běžet samostatně z aplikace, která generuje data instrumentace. Obrázek 2 znázorňuje příklad této architektury a zvýrazňuje subsystém shromažďování dat instrumentace.
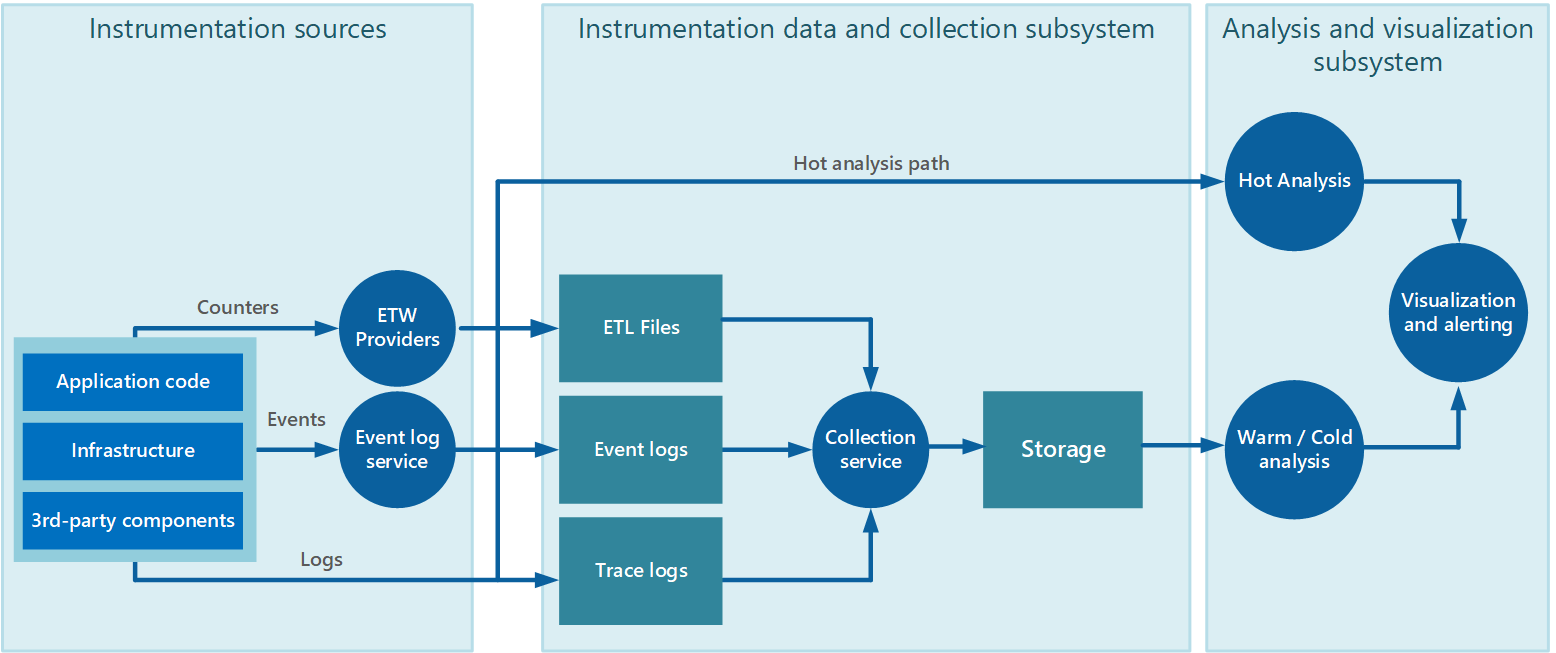
Obrázek 2 – Shromažďování dat instrumentace
Toto je zjednodušené zobrazení. Služba sběru nemusí být nutně jediným procesem a může obsahovat mnoho komponent běžících na různých strojích, jak je popsáno v následujících částech. Kromě toho, pokud je potřeba rychle provést analýzu některých telemetrických dat (horká analýza, jak je popsáno v části Podpora horké, teplé a studené analýzy dále v tomto dokumentu), mohou místní komponenty, které pracují mimo službu shromažďování, provádět úlohy analýzy okamžitě. Obrázek 2 znázorňuje tuto situaci u vybraných událostí. Po analytickém zpracování je možné výsledky odeslat přímo do subsystému vizualizace a upozorňování. Data, která jsou předmětem teplé nebo studené analýzy, se uchovávají v úložišti, zatímco čeká na zpracování.
Pro aplikace a služby Azure poskytuje Azure Diagnostics jedno z možných řešení pro zachytávání dat. Azure Diagnostics shromažďuje data z následujících zdrojů pro každý výpočetní uzel, agreguje je a pak je nahraje do Služby Azure Storage:
- Protokoly služby IIS
- Protokoly neúspěšných žádostí služby IIS
- Protokoly událostí Windows
- Čítače výkonu
- Soubory se záznamem o selhání
- Protokoly infrastruktury Azure Diagnostics
- Vlastní protokoly chyb
- Zdroj událostí .NET
- Trasování událostí pro Windows na základě manifestu
Další informace najdete v článku Azure: Základy telemetrie a řešení potíží.
Strategie shromažďování dat instrumentace
Vzhledem k elastické povaze cloudu a abyste se vyhnuli nutnosti ručního načítání telemetrických dat z každého uzlu v systému, měli byste zajistit přenos dat do centrálního umístění a konsolidovat. V systému, který zahrnuje více datacenter, může být užitečné nejprve shromažďovat, konsolidovat a ukládat data v jednotlivých oblastech a pak agregovat regionální data do jednoho centrálního systému.
Pokud chcete optimalizovat využití šířky pásma, můžete se rozhodnout přenášet méně urgentní data v blocích jako dávky. Data však nesmí být zpožděna na neomezenou dobu, zejména pokud obsahují informace citlivé na čas.
Stahování a odesílání dat instrumentace
Subsystém shromažďování dat instrumentace může aktivně načítat data instrumentace z různých protokolů a dalších zdrojů pro každou instanci aplikace ( pull model). Nebo může fungovat jako pasivní přijímač, který čeká na odeslání dat ze součástí, které tvoří každou instanci aplikace ( model push).
Jedním z přístupů k implementaci pull modelu (modelu vyžádání obsahu) je použití monitorovacích agentů, kteří běží lokálně s každou instancí aplikace. Agent monitorování je samostatný proces, který pravidelně načítá telemetrická data shromážděná v místním uzlu a zapisuje tyto informace přímo do centralizovaného úložiště, které všechny instance sdílené aplikace. Jedná se o mechanismus, který implementuje agent Azure Monitoru . Každou výpočetní instanci je možné nakonfigurovat tak, aby zaznamenávala diagnostické a další informace o trasování, které jsou uložené místně. Agent monitorování, který běží společně s jednotlivými instancemi, shromažďuje zadaná data a odesílá je do služby Azure Monitor. Některé elementy, jako jsou protokoly služby IIS, výpisy stavu při chybě a vlastní protokoly chyb, se zapisují do úložiště blob. Data z protokolu událostí systému Windows, událostí ETW a čítačů výkonu jsou zaznamenávány do úložiště tabulek. Tento mechanismus znázorňuje obrázek 3.
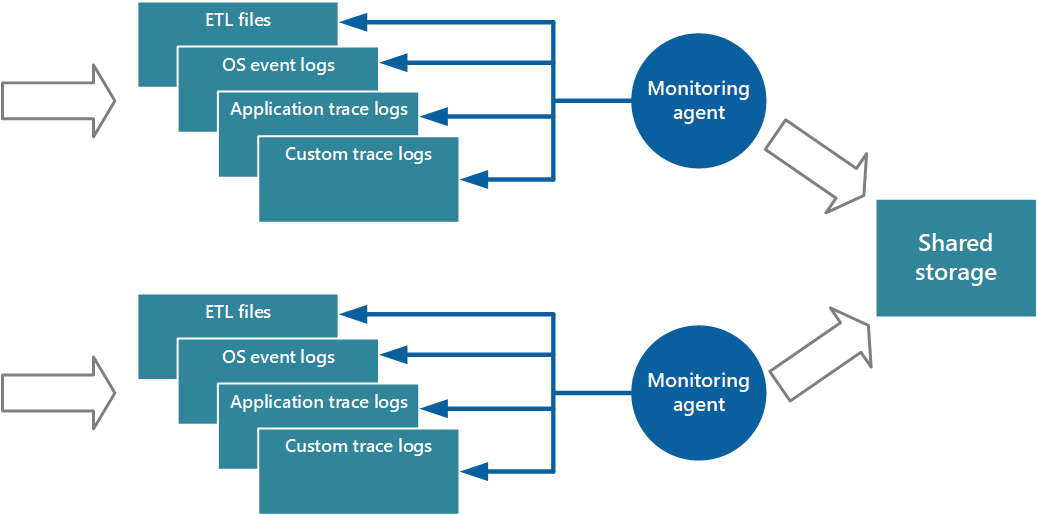
Obrázek 3 – Použití monitorovacího agenta k vyžádání informací a zápisu do sdíleného úložiště
Poznámka:
Použití agenta monitorování se ideálně hodí k zachytávání dat instrumentace, která se přirozeně stahují ze zdroje dat. Příkladem jsou informace z dynamických spravovacích zobrazení SQL Serveru nebo délka fronty služby Azure Service Bus.
Je možné použít právě popsaný přístup k ukládání telemetrických dat pro malou aplikaci běžící na omezeném počtu uzlů v jednom umístění. Složitá a vysoce škálovatelná globální cloudová aplikace ale může generovat obrovské objemy dat ze stovek výpočetních instancí, databázových horizontálních oddílů a dalších služeb. Tato záplava dat může snadno zahltit šířku pásma vstupně-výstupních operací dostupnou v jediném centrálním umístění. Proto musí být vaše řešení telemetrie škálovatelné, aby se při rozšiřování systému nestalo úzkým hrdlem. V ideálním případě by vaše řešení mělo zahrnovat určitou redundanci, aby se snížila rizika ztráty důležitých informací monitorování (například auditování nebo fakturačních dat), pokud se část systému nezdaří.
Pokud chcete tyto problémy vyřešit, můžete implementovat řazení do front, jak je znázorněno na obrázku 4. V této architektuře místní agent monitorování (pokud ho lze správně nakonfigurovat) nebo, pokud ne, použije se vlastní služba shromažďování dat, odesílá data do fronty. Samostatný proces spuštěný asynchronně (služba zápisu do úložiště na obrázku 4) přebírá data v této frontě a zapisuje je do sdíleného úložiště. Fronta zpráv je vhodná pro tento scénář, protože poskytuje sémantiku „alespoň jednou“, což pomáhá zajistit, aby se data zařazená do fronty po publikování neztratila. Službu zápisu do úložiště můžete implementovat pomocí samostatného procesu na pozadí.
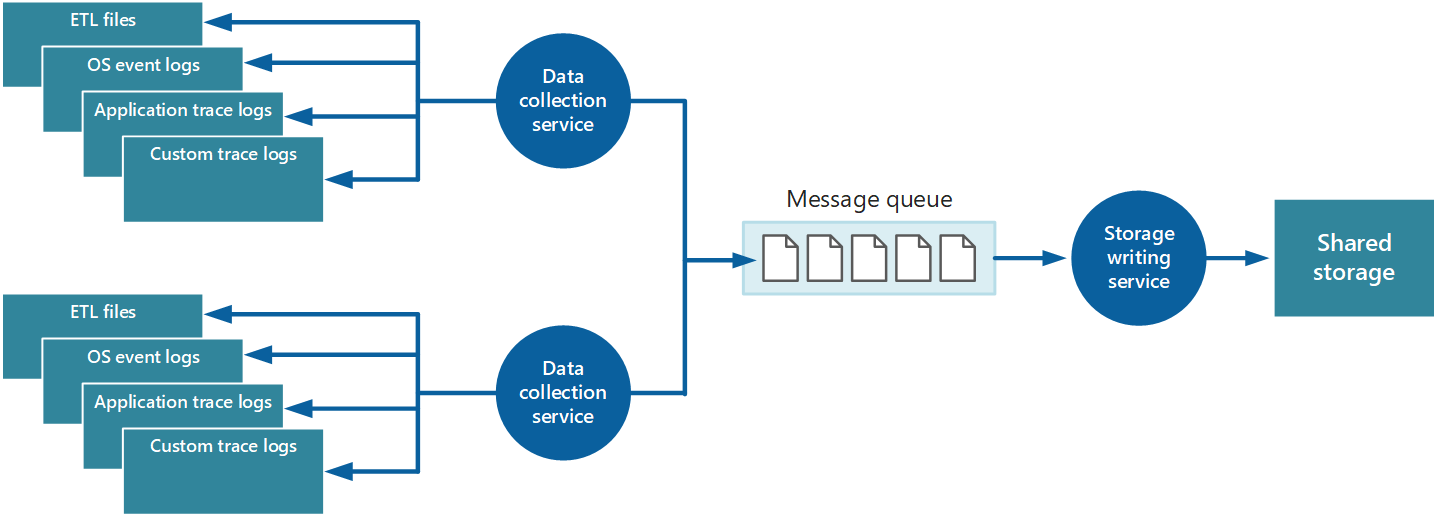
Obrázek 4 – Použití fronty k ukládání dat instrumentace do vyrovnávací paměti
Místní služba shromažďování dat může přidávat data do fronty hned po přijetí. Fronta funguje jako vyrovnávací paměť a služba zápisu do úložiště může načítat a zapisovat data vlastním tempem. Ve výchozím nastavení fronta pracuje na principu „první dovnitř, první ven“. Pokud ale zprávy obsahují data, která se musí zpracovávat rychleji, můžete je upřednostnit a urychlit je ve frontě. Další informace najdete ve vzorci Prioritní fronta. Případně můžete použít různé kanály (například témata služby Service Bus) k směrování dat do různých cílů v závislosti na požadované formě analytického zpracování.
Kvůli škálovatelnosti můžete spustit více instancí služby zápisu do úložiště. Pokud existuje velký objem událostí, můžete pomocí centra událostí odesílat data do různých výpočetních prostředků pro zpracování a úložiště.
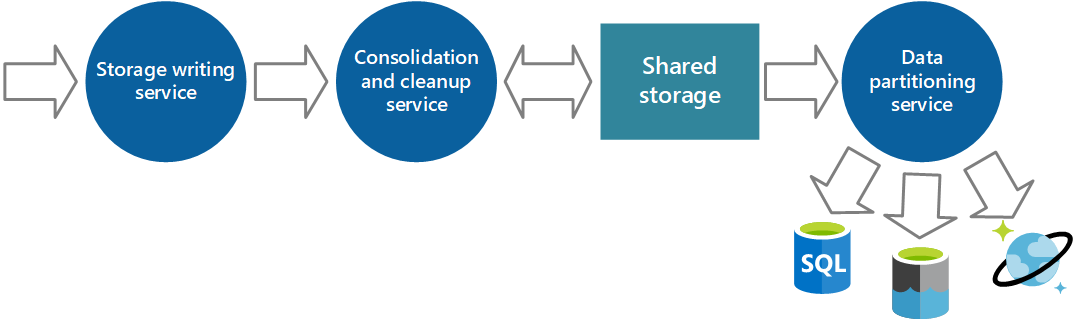
Konsolidace dat z instrumentace
Data instrumentace, která služba shromažďování dat načítá z jedné instance aplikace, poskytují lokalizované zobrazení stavu a výkonu dané instance. Aby bylo možné vyhodnotit celkový stav systému, je nutné konsolidovat některé aspekty dat v místních zobrazeních. Můžete to provést po uložení dat, ale v některých případech je můžete dosáhnout také při shromažďování dat. Místo přímého zápisu do sdíleného úložiště mohou data instrumentace projít samostatnou službou konsolidace dat, která kombinuje data a funguje jako proces filtrování a čištění. Například instrumentační data, která obsahují stejné korelační informace, jako je ID aktivity, mohou být sloučena. (Je možné, že uživatel začne provádět obchodní operaci na jednom uzlu a pak se v případě selhání uzlu přenese do jiného uzlu nebo v závislosti na konfiguraci vyrovnávání zatížení.) Tento proces může také detekovat a odebírat duplicitní data (vždy možnost, pokud služba telemetrie používá fronty zpráv k odesílání dat instrumentace do úložiště). Obrázek 5 znázorňuje příklad této struktury.
Obrázek 5 – Konsolidace a vyčištění dat instrumentace pomocí samostatné služby
Ukládání dat instrumentace
Předchozí diskuze znázorňují spíše zjednodušený pohled na způsob ukládání dat instrumentace. Ve skutečnosti může dávat smysl ukládat různé typy informací pomocí technologií, které jsou nejvhodnější pro způsob, jakým bude každý typ pravděpodobně použit.
Úložiště objektů blob a tabulek Azure má například určité podobnosti v tom, jakým způsobem se k nim přistupuje. Mají ale omezení v operacích, které můžete provádět jejich použitím, a členitost uložených dat se liší. Pokud potřebujete provádět analytičtější operace nebo vyžadujete funkce fulltextového vyhledávání dat, může být vhodnější použít úložiště dat, které poskytuje funkce optimalizované pro konkrétní typy dotazů a přístupu k datům. Například:
- Data čítačů výkonu se dají uložit do SQL databáze, která umožňuje analýzu ad hoc.
- Protokoly trasování můžou být lépe uložené ve službě Azure Cosmos DB.
- Informace o zabezpečení se dají zapsat do HDFS.
- Informace, které vyžadují fulltextové vyhledávání, je možné ukládat prostřednictvím Elasticsearch (což může také urychlit vyhledávání pomocí bohatého indexování).
Můžete implementovat další službu, která pravidelně načítá data ze sdíleného úložiště, oddílů a filtruje data podle jejich účelu, a pak je zapíše do příslušné sady úložišť dat, jak je znázorněno na obrázku 6. Tato funkce se dá taky zahrnout do procesu konsolidace a čištění, aby se data zapisovala do těchto úložišť přímo při načítání, místo aby se ukládala do přechodného sdíleného úložiště. Každý z těchto přístupů má své výhody a nevýhody. Implementace samostatné služby dělení snižuje zatížení služby konsolidace a čištění a v případě potřeby umožňuje alespoň některé dělené data vygenerovat v případě potřeby (v závislosti na tom, kolik dat se uchovává ve sdíleném úložišti). Využívá ale další prostředky. Navíc může docházet ke zpoždění mezi přijetím dat instrumentace z jednotlivých instancí aplikace a převodem těchto dat na využitelné informace.
Obrázek 6 – Dělení dat podle analytických požadavků a požadavků na úložiště.
Stejná data instrumentace se můžou dát využít k více účelům. Čítače výkonu lze například použít k zajištění historického zobrazení výkonu systému v průběhu času. Tyto informace se dají zkombinovat s jinými údaji o využití a na základě toho se můžou generovat fakturační údaje zákazníků. V těchto situacích mohou být stejná data odeslána do více než jednoho cíle, jako je databáze dokumentů, která může fungovat jako dlouhodobé úložiště pro uchovávání fakturačních údajů, a multidimenzionální úložiště pro zpracování komplexní analýzy výkonu.
Měli byste také zvážit, jak jsou data naléhavě nutná. Data, která poskytují informace pro upozorňování, musí být rychle přístupná, takže by se měla uchovávat v rychlém úložišti dat a indexovaná nebo strukturovaná za účelem optimalizace dotazů, které systém upozornění provádí. V některých případech může být nutné, aby služba telemetrie, která shromažďuje data v každém uzlu, aby data naformátovála a uložila místně, aby vás místní instance systému upozornění mohla rychle informovat o jakýchkoli problémech. Stejná data se dají odeslat do služby zápisu do úložiště znázorněné na předchozích obrázcích a zároveň uložit do centrálního úložiště, pokud jsou potřebná i k jiným účelům.
Informace, které se používají pro více zvažované analýzy, vytváření sestav a zjišťování historických trendů, jsou méně naléhavé a mohou být uloženy způsobem, který podporuje dolování dat a ad hoc dotazy. Další informace najdete v části Podpora horké, teplé a studené analýzy dále v tomto dokumentu.
Rotaci logů a uchovávání dat
Instrumentace může generovat značné objemy dat. Tato data se dají uchovávat na několika místech, počínaje nezpracovanými soubory protokolu, trasovacími soubory a dalšími informacemi zachycenými v každém uzlu do konsolidovaného, vyčištěného a děleného zobrazení těchto dat uložených ve sdíleném úložišti. V některých případech je možné po zpracování a přenosu dat z každého uzlu odebrat původní nezpracovaná zdrojová data. V jiných případech může být nutné nebo užitečné uložit nezpracované informace. Například data generovaná pro účely ladění můžou být nejlépe ponechána v nezpracované podobě, ale pak je možné je rychle zahodit po opravě všech chyb.
Data o výkonu mají často delší životnost, aby je bylo možné použít ke zjišťování trendů výkonu a k plánování kapacity. Konsolidované zobrazení těchto dat se většinou po omezené období uchovává online, aby se k němu dal rychle získat přístup. Potom je můžete archivovat nebo zahodit. Data shromažďovaná za účelem měření a fakturace zákazníkům může být potřeba nechat uložené bez omezení. Kromě toho můžou zákonné požadavky diktovat, že informace shromážděné pro účely auditování a zabezpečení musí být také archivovány a uloženy. Tato data jsou také citlivá a může být nutné je zašifrovat nebo jinak chránit, aby se zabránilo manipulaci. Nikdy byste neměli zaznamenávat hesla uživatelů ani jiné informace, které by mohly být použity k podvodu s identitou. Tyto podrobnosti by měly být z dat odstraněny před uložením.
Vzorkování mimo provoz
Je užitečné ukládat historická data, která umožňují vysledovat dlouhodobé trendy. Místo ukládání starých dat v celém rozsahu může být možné data snížit tak, aby se snížila jejich rozlišení a ušetřily náklady na úložiště. Například místo úspory indikátorů výkonu po minutách můžete konsolidovat data, která jsou starší než měsíc, a vytvořit zobrazení po hodinách.
Osvědčené postupy pro shromažďování a ukládání protokolových záznamů
Následující seznam shrnuje osvědčené postupy pro zachytávání a ukládání informací o protokolování:
Agent monitorování nebo služba shromažďování dat by měly běžet jako služba mimo zpracování a měla by být jednoduchá k nasazení.
Veškerý výstup z agenta monitorování nebo služby shromažďování dat by měl být nezávislý formát, který je nezávislý na počítači, operačním systému nebo síťovém protokolu. Například emitovat informace v samopopisujícím formátu, jako je JSON, MessagePack nebo Protobuf, místo ETL/ETW. Použití standardního formátu umožňuje systému vytvářet kanály zpracování; komponenty, které čtou, transformují a odesílají data ve schváleném formátu, je možné snadno integrovat.
Proces monitorování a shromažďování dat musí být bezpečný a nesmí aktivovat žádné kaskádové chybové podmínky.
V případě přechodného selhání při odesílání informací do jímky dat by měl být agent monitorování nebo služba shromažďování dat připraveny změnit pořadí telemetrických dat tak, aby se nejdříve odesílaly nejnovější informace. (Agent monitorování nebo služba shromažďování dat se může podle vlastního uvážení rozhodnout, že starší data zahodí, nebo že je uloží místně a přenese je později, aby dohnala zpoždění.)
Analýza dat a diagnostika problémů
Důležitou součástí procesu monitorování a diagnostiky je analýza shromážděných dat, aby získala přehled o celkové pohodě systému. Měli byste definovat vlastní klíčové ukazatele výkonu a metriky výkonu a je důležité pochopit, jak můžete strukturovat data shromážděná tak, aby splňovala vaše požadavky analýzy. Je také důležité pochopit, jak data zachycená v různých metrikách a souborech protokolů korelují, protože tyto informace můžou být klíčem ke sledování posloupnosti událostí a k diagnostice problémů, které nastanou.
Jak je popsáno v části Konsolidace dat instrumentace, data pro každou část systému se obvykle zaznamenávají místně, ale obvykle je potřeba je kombinovat s daty generovanými v jiných lokalitách, které se účastní systému. Tyto informace vyžadují pečlivou korelaci, aby bylo zajištěno, že se data zkombinují přesně. Například data o využití pro operaci můžou zahrnovat uzel, který je hostitelem webu, ke kterému se uživatel připojí, uzel, který spouští samostatnou službu, ke které se přistupuje v rámci této operace, a úložiště dat uchovávané na jiném uzlu. Tyto informace musí být svázané, aby poskytovaly celkový přehled o využití prostředků a zpracování operace. Některé předběžné zpracování a filtrování dat může probíhat na uzlu, na kterém jsou data zachycena, zatímco agregace a formátování pravděpodobně probíhají na centrálním uzlu.
Podpora horké, střední a studené analýzy
Analýza a přeformátování dat pro účely vizualizace, vytváření sestav a upozorňování může být složitý proces, který využívá vlastní sadu prostředků. Některé formy monitorování jsou časově kritické a vyžadují okamžitou analýzu dat, aby byla efektivní. Tato analýza se označuje jako horká analýza. Mezi příklady patří analýzy, které jsou potřeba k upozorňování, a některé aspekty monitorování zabezpečení (například zjišťování útoku na systém). Data potřebná pro tyto účely musí být rychle dostupná a strukturovaná pro efektivní zpracování. V některých případech může být nutné přesunout zpracování analýzy do jednotlivých uzlů, kde se data uchovávají.
Jiné formy analýzy jsou méně časově kritické a můžou vyžadovat určité výpočty a agregaci po přijetí nezpracovaných dat. Tomu se říká teplá analýza. Analýza výkonu často spadá do této kategorie. V tomto případě izolovaná jedna událost výkonu pravděpodobně nebude statisticky významná. (Příčinou může být náhlé špičky nebo závada.) Data z řady událostí by měla poskytovat spolehlivější přehled o výkonu systému.
K diagnostice problémů se stavem je možné použít také teplou analýzu. Událost zdraví se obvykle zpracovává prostřednictvím rychlé analýzy a může okamžitě vyvolat výstrahu. Operátor by měl být schopný podrobně prozkoumat důvody události týkající se stavu systému zkoumáním dat ze sekundární cesty. Tato data by měla obsahovat informace o událostech, které vedly k problému, jenž způsobil zdravotní událost.
Některé typy monitorování generují dlouhodobé data. Tuto analýzu je možné provést později, pravděpodobně podle předdefinovaného plánu. V některých případech může analýza potřebovat komplexní filtrování velkých objemů dat zachycených v určitém časovém období. To se nazývá studená analýza. Klíčovým požadavkem je, aby se data po zachycení bezpečně ukládaly. Například monitorování a auditování využití vyžaduje přesný přehled o stavu systému v pravidelných bodech v čase, ale tyto informace o stavu nemusí být k dispozici ke zpracování okamžitě po shromáždění.
Operátor může také použít studenou analýzu k poskytování dat pro prediktivní analýzu stavu. Operátor může shromažďovat historické informace za určité období a používat je ve spojení s aktuálními daty o stavu (načtenými z horké cesty) k zjišťování trendů, které by mohly brzy způsobit problémy se stavem. V těchto případech může být nutné vyvolat výstrahu, aby bylo možné provést nápravnou akci.
Korelace dat
Data, která instrumentace zachycuje, můžou poskytnout snímek stavu systému, ale účelem analýzy je zajistit, aby tato data byla užitečná. Například:
- Co způsobilo vysoké zatížení I/O operací na úrovni systému v určitou dobu?
- Jedná se o výsledek velkého počtu databázových operací?
- Odráží se to v době odezvy databáze, počtu transakcí za sekundu a doby odezvy aplikace ve stejné době?
Pokud ano, jednou z nápravných akcí, které by mohly snížit zatížení, může být rozdělení dat na více serverů. Kromě toho může dojít k výjimkám v důsledku chyby v jakékoli úrovni systému. Výjimka na jedné úrovni často aktivuje jinou chybu na výše uvedené úrovni.
Z těchto důvodů musíte být schopni korelovat různé typy dat monitorování na jednotlivých úrovních, abyste vytvořili celkový přehled o stavu systému a aplikacích, které na nich běží. Tyto informace pak můžete použít k rozhodování o tom, jestli systém funguje přijatelně nebo ne, a určit, co se dá udělat, aby se zlepšila kvalita systému.
Jak je popsáno v části Informace o korelaci dat, musíte zajistit, aby nezpracovaná data instrumentace obsahovala dostatečné informace o kontextu a ID aktivity pro podporu požadovaných agregací pro korelace událostí. Tato data se navíc můžou uchovávat v různých formátech a může být nutné tyto informace analyzovat, aby byly převedeny do standardizovaného formátu pro analýzu.
Řešení potíží a diagnostika problémů
Diagnostika vyžaduje schopnost určit příčinu chyb nebo neočekávané chování, včetně provádění analýzy původní příčiny. Mezi požadované informace obvykle patří:
- Podrobné informace z protokolů událostí a trasování, a to buď pro celý systém, nebo pro zadaný subsystém během zadaného časového intervalu.
- Kompletní trasování zásobníku vyplývající z výjimek a chyb jakékoli zadané úrovně, ke kterým dochází v systému nebo v zadaném subsystému během stanoveného období.
- Výpisy chyb pro jakékoli selhané procesy buď kdekoli v systému, nebo v zadaném subsystému během zadaného časového intervalu.
- Protokoly aktivit zaznamenávají operace prováděné všemi uživateli nebo pro vybrané uživatele během zadaného období.
Analýza dat pro účely řešení potíží často vyžaduje hluboké technické znalosti architektury systému a různých komponent, které řešení tvoří. V důsledku toho se často vyžaduje velký stupeň ručního zásahu k interpretaci dat, stanovení příčin problémů a doporučení vhodné strategie k jejich opravě. Může být vhodné uložit kopii těchto informací v původním formátu a zpřístupnit ji pro studenou analýzu odborníkem.
Vizualizace dat a vyvolávání výstrah
Důležitým aspektem jakéhokoli monitorovacího systému je schopnost prezentovat data takovým způsobem, aby operátor mohl rychle odhalit trendy nebo problémy. Důležité je také schopnost rychle informovat operátora, pokud došlo k významné události, která může vyžadovat pozornost.
Prezentace dat může mít několik forem, včetně vizualizace pomocí řídicích panelů, upozornění a reportování.
Vizualizace pomocí řídicích panelů
Nejběžnějším způsobem vizualizace dat je použití řídicích panelů, které můžou zobrazovat informace jako řadu grafů, grafů nebo jiné ilustrace. Tyto položky lze parametrizovat a analytik by měl mít možnost vybrat důležité parametry (například časové období) pro každou konkrétní situaci.
Řídicí panely je možné uspořádat hierarchicky. Řídicí panely nejvyšší úrovně můžou poskytnout celkový přehled o jednotlivých aspektech systému, ale operátor může přejít k podrobnostem. Například řídicí panel, který znázorňuje celkové vstupně-výstupní operace disku pro systém, by měl analytikům umožnit zobrazit sazby vstupně-výstupních operací pro každý jednotlivý disk a zjistit, jestli jedno nebo více konkrétních zařízení představuje nepřiměřený objem provozu. V ideálním případě by měl řídicí panel zobrazovat také související informace, jako je zdroj každého požadavku (uživatel nebo aktivita), který generuje tento vstupně-výstupní operace. Tyto informace se pak dají použít k určení, jestli (a jak) rovnoměrněji rozložit zatížení mezi zařízení a jestli by systém fungoval lépe, kdyby bylo přidáno více zařízení.
Řídicí panel může také použít barevné kódování nebo jiné vizuální pomůcky k označení hodnot, které se zobrazují neobvykle nebo které jsou mimo očekávaný rozsah. Použití předchozího příkladu:
- Disk s rychlostí vstupně-výstupních operací, která se blíží maximální kapacitě v delším období (horký disk), je možné zvýraznit červeně.
- Disk s rychlostí vstupně-výstupních operací, která se pravidelně spouští na maximálním limitu v krátkých obdobích (teplý disk), je možné zvýraznit žlutě.
- Disk, který vykazuje normální využití, se dá zobrazit zeleně.
Aby systém řídicího panelu fungoval efektivně, musí mít nezpracovaná data, se kterými může pracovat. Pokud vytváříte vlastní systém řídicích panelů nebo používáte řídicí panel vyvinutý jinou organizací, musíte pochopit, která data instrumentace potřebujete shromažďovat, na jaké úrovni členitosti a jak by měl řídicí panel využívat.
Kromě zobrazení informací také dobrý řídicí panel umožňuje analytikům klást otázky na tyto informace. Některé systémy poskytují nástroje pro správu, které může operátor použít k provádění těchto úloh a zkoumání podkladových dat. Případně v závislosti na úložišti, které se používají k uložení těchto informací, může být možné tato data dotazovat přímo nebo je importovat do nástrojů, jako je Microsoft Excel pro další analýzu a vytváření sestav.
Poznámka:
Přístup k řídicím panelům byste měli omezit na oprávněné pracovníky, protože tyto informace můžou být komerčně citlivé. Měli byste také chránit podkladová data pro řídicí panely, abyste uživatelům zabránili v jejich změně.
Vyvolávání výstrah
Upozorňování je proces analýzy dat monitorování a instrumentace a generování oznámení v případě zjištění významné události.
Upozorňování pomáhá zajistit, aby systém zůstal v pořádku, responzivní a zabezpečený. Je to důležitá součást každého systému, který uživatelům zaručuje výkon, dostupnost a ochranu osobních údajů, kde by mohla být data potřeba okamžitě zpracována. Operátor může být muset být upozorněn na událost, která výstrahu aktivovala. Výstrahy lze také použít k vyvolání systémových funkcí, jako je automatické škálování.
Upozorňování obvykle závisí na následujících datech instrumentace:
- Události zabezpečení. Pokud protokoly událostí naznačují, že dochází k opakovaným selháním ověřování nebo autorizace, může být systém napaden a operátor by měl být informován.
- Metriky výkonu: Systém musí rychle reagovat, pokud určitá metrika výkonu překročí zadanou prahovou hodnotu.
- Informace o dostupnosti Pokud se zjistí chyba, může být nutné rychle restartovat jeden nebo více subsystémů nebo přejít na záložní zdroj. Opakované chyby v subsystému můžou znamenat vážnější obavy.
Operátoři můžou dostávat informace o upozorněních pomocí mnoha kanálů doručování, jako jsou e-mail, pager nebo SMS. Výstraha může také obsahovat informace o tom, jak kritická situace je. Řada systémů upozorňování podporuje skupiny odběratelů a všichni operátoři, kteří jsou členy stejné skupiny, můžou přijímat stejnou sadu výstrah.
Systém upozorňování by měl být přizpůsobitelný a příslušné hodnoty z podkladových dat instrumentace je možné zadat jako parametry. Tento přístup umožňuje operátorům filtrovat data a zaměřit se na tyto prahové hodnoty nebo kombinace hodnot, které jsou zajímavé. V některých případech je možné systému výstrah poskytnout nezpracovaná data instrumentace. V jiných situacích může být vhodnější zadat agregovaná data. (Upozornění se může aktivovat například v případě, že využití procesoru uzlu překročilo 90 procent za posledních 10 minut). Podrobnosti poskytované systému výstrah by také měly obsahovat všechny příslušné souhrnné a kontextové informace. Tato data můžou pomoct snížit možnost, že falešně pozitivní události zasílaly výstrahu.
Reportování
Reporting se používá ke generování celkového pohledu na systém. Kromě aktuálních informací může obsahovat historická data. Požadavky na hlášení spadají do dvou širokých kategorií: provozní hlášení a hlášení o bezpečnosti.
Provozní reporting obvykle zahrnuje následující aspekty:
- Agregace statistik, které můžete použít k pochopení využití zdrojů celého systému nebo specifikovaných subsystémů během zadaného časového okna.
- Identifikace trendů ve využití zdrojů pro celý systém nebo specifikované subsystémy během zadaného období.
- Monitorování výjimek, ke kterým došlo v celém systému nebo v zadaných subsystémech během zadaného období
- Určení efektivity aplikace z hlediska nasazených prostředků a zjištění, jestli je možné snížit objem prostředků (a jejich související náklady), aniž by to zbytečně ovlivnilo výkon.
Bezpečnostní reportování se zaměřuje na sledování využití systému zákazníky. Může zahrnovat:
- Auditování uživatelských operací To vyžaduje zaznamenávání jednotlivých požadavků, které každý uživatel provádí, spolu s daty a časy. Data by měla být strukturovaná tak, aby správce mohl rychle rekonstruovat posloupnost operací, které uživatel provádí v zadaném období.
- Sledování prostředků, které uživatel používá To vyžaduje zaznamenání, jak každý uživatelský požadavek přistupuje k různým prostředkům, které tvoří systém, a jak dlouho to trvá. Správce musí být schopen tato data použít k vygenerování sestavy využití uživatelem v zadaném období, případně pro účely fakturace.
Pomocí dávkových procesů se mohou zprávy generovat podle určeného časového plánu v mnoha případech. (Latence obvykle není problém.) V případě potřeby by ale měly být dostupné i pro generování ad hoc. Pokud například ukládáte data do relační databáze, jako je Azure SQL Database, můžete pomocí nástroje, jako je SQL Server Reporting Services, extrahovat a formátovat data a prezentovat je jako sadu sestav.
Další kroky
- Přehled služby Azure Monitor
- Monitorování, diagnostika a řešení problémů s Microsoft Azure Storage
- Přehled upozornění v Microsoft Azure
- Co je Application Insights?
- Diagnostika výkonu pro virtuální počítače Azure
- Stáhněte a nainstalujte SQL Server Data Tools (SSDT) pro Visual Studio
Související prostředky
- Pokyny k automatickému škálování popisují, jak snížit režii správy snížením potřeby operátora průběžně monitorovat výkon systému a rozhodovat se o přidávání nebo odebírání prostředků.
- Model monitorování koncových bodů stavu popisuje, jak implementovat funkční kontroly v aplikaci, ke které mají externí nástroje přístup prostřednictvím vystavených koncových bodů v pravidelných intervalech.
- Model prioritní fronty ukazuje, jak určit prioritu zpráv zařazených do fronty, aby byly přijaté naléhavé žádosti a aby je bylo možné zpracovat před méně naléhavémi zprávami.