Pokud chcete ověřit, že aplikace a služby fungují správně, můžete použít model monitorování koncových bodů stavu. Tento model určuje použití funkčních kontrol v aplikaci. Externí nástroje můžou k těmto kontrolám přistupovat v pravidelných intervalech prostřednictvím vystavených koncových bodů.
Kontext a problém
Je vhodné monitorovat webové aplikace a back-endové služby. Monitorování pomáhá zajistit, aby aplikace a služby byly k dispozici a správně fungovaly. Obchodní požadavky často zahrnují monitorování.
Monitorování cloudových služeb je někdy obtížnější než místní služby. Jedním z důvodů je, že nemáte úplnou kontrolu nad hostitelským prostředím. Další je, že služby obvykle závisejí na jiných službách, které dodavatelé platformy a další poskytují.
Mnoho faktorů ovlivňuje aplikace hostované v cloudu. Mezi příklady patří latence sítě, výkon a dostupnost základních výpočetních a úložných systémů a šířka pásma sítě mezi nimi. Služba může selhat zcela nebo částečně kvůli některému z těchto faktorů. Pokud chcete zajistit požadovanou úroveň dostupnosti, musíte v pravidelných intervalech ověřit, že vaše služba funguje správně. Smlouva o úrovni služeb (SLA) může určovat úroveň, kterou potřebujete splnit.
Řešení
Implementujte monitorování stavu odesláním požadavků do koncového bodu ve vaší aplikaci. Aplikace by měla provést potřebné kontroly a pak vrátit indikaci jejího stavu.
Kontrola v rámci monitorování stavu obvykle kombinuje dva faktory:
- Kontroly (pokud existuje), které aplikace nebo služba provádí v reakci na požadavek na koncový bod ověření stavu
- Analýza výsledků nástrojem nebo architekturou, která provádí kontrolu stavu
Kód odpovědi označuje stav aplikace. Volitelně kód odpovědi také poskytuje stav komponent a služeb, které aplikace používá. Monitorovací nástroj nebo architektura provádí kontrolu latence nebo doby odezvy.
Následující obrázek obsahuje přehled modelu.
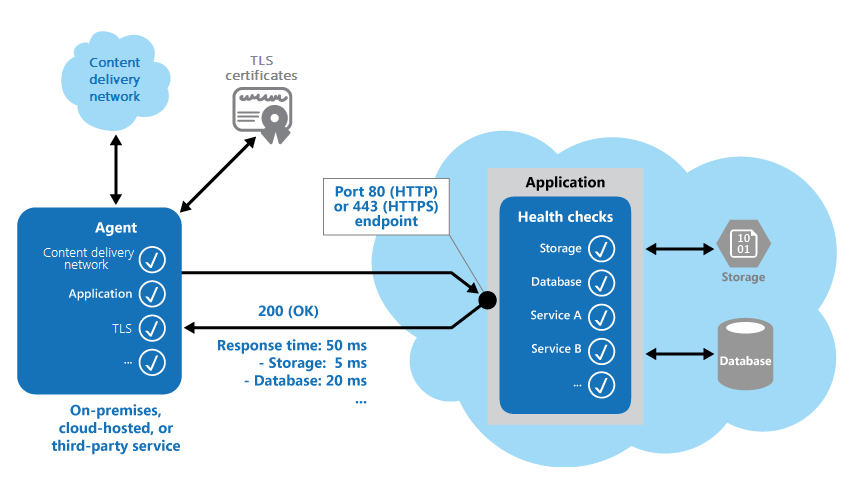
Kód monitorování stavu v aplikaci může také spouštět další kontroly, které určí:
- Dostupnost a doba odezvy cloudového úložiště nebo databáze.
- Stav jiných prostředků nebo služeb, které aplikace používá. Tyto prostředky a služby můžou být v aplikaci nebo mimo ni.
Služby a nástroje jsou k dispozici, které monitorují webové aplikace odesláním požadavku do konfigurovatelné sady koncových bodů. Tyto služby a nástroje pak vyhodnotí výsledky podle sady konfigurovatelných pravidel. Je poměrně snadné vytvořit koncový bod služby pro jediný účel provádění některých funkčních testů v systému.
Mezi typické kontroly, které nástroje monitorování provádějí, patří:
- Ověřování kódu odpovědi. Odpověď HTTP s hodnotou 200 (OK) třeba udává, že aplikace odpověděla bez chyby. Monitorovací systém může také zkontrolovat další kódy odpovědí a poskytnout komplexnější výsledky.
- Kontrola obsahu odpovědi za účelem zjištění chyb, i když je stavový kód 200 (OK). Kontrolou obsahu můžete zjistit chyby, které ovlivňují pouze část vrácené webové stránky nebo odpovědi služby. Můžete například zkontrolovat název stránky nebo vyhledat konkrétní frázi, která indikuje, že aplikace vrátila správnou stránku.
- Měření doby odezvy. Hodnota zahrnuje latenci sítě a dobu, kterou aplikace trvala k vydání požadavku. Zvětšující se hodnota může znamenat vznikající problém s aplikací nebo sítí.
- Kontrola prostředků nebo služeb umístěných mimo aplikaci Příkladem je síť pro doručování obsahu, kterou aplikace používá k doručování obsahu z globálních mezipamětí.
- Kontrola vypršení platnosti certifikátů TLS
- Měření doby odezvy vyhledávání DNS pro adresu URL aplikace Tato kontrola měří latenci DNS a selhání DNS.
- Ověření adresy URL, kterou vrací vyhledávání DNS. Ověřením můžete zajistit správnost položek. Můžete také zabránit přesměrování škodlivých požadavků, které můžou mít za následek útok na váš server DNS.
Pokud je to možné, je také užitečné tyto kontroly spustit z různých místních nebo hostovaných umístění a pak porovnat doby odezvy. V ideálním případě byste měli monitorovat aplikace z umístění, která jsou blízko zákazníkům. Pak získáte přesné zobrazení výkonu z každého umístění. Tento postup poskytuje robustnější kontrolní mechanismus. Výsledky vám také můžou pomoct při rozhodování:
- Kde nasadit aplikaci
- Jestli se má nasadit ve více než jednom datacentru
Pokud chcete zajistit, aby vaše aplikace správně fungovala pro všechny zákazníky, spusťte testy na všech instancích služby, které zákazníci používají. Pokud je například zákaznické úložiště rozložené mezi více než jeden účet úložiště, měl by proces monitorování zkontrolovat každý účet.
Problémy a důležité informace
Při rozhodování o implementaci tohoto modelu zvažte následující body:
Zamyslete se nad tím, jak ověřit odpověď. Určete například, jestli je stavový kód 200 (OK) dostatečný k ověření správného fungování aplikace. Kontrola stavového kódu je minimální implementace tohoto modelu. Stavový kód poskytuje základní míru dostupnosti aplikace. Kód ale poskytuje málo informací o operacích, trendech a možných nadcházejících problémech v aplikaci.
Určete počet koncových bodů, které se mají zveřejnit pro aplikaci. Jedním z přístupů je zveřejnit alespoň jeden koncový bod pro základní služby, které aplikace používá, a druhý pro služby s nižší prioritou. Pomocí tohoto přístupu můžete jednotlivým výsledkům monitorování přiřadit různé úrovně důležitosti. Zvažte také zveřejnění dalších koncových bodů. Pro každou základní službu můžete zveřejnit jednu, abyste zvýšili členitost monitorování. Kontrola stavu může například zkontrolovat databázi, úložiště a externí službu geografického kódování, kterou aplikace používá. Každá z nich může vyžadovat jinou úroveň doby provozu a doby odezvy. Služba geokódování nebo jiná úloha na pozadí může být několik minut nedostupná. Aplikace ale může být stále v pořádku.
Rozhodněte se, jestli se má použít stejný koncový bod pro monitorování a obecný přístup. Stejný koncový bod můžete použít pro oba, ale navrhnout konkrétní cestu pro kontroly stavu. Parametr /health můžete například použít v koncovém bodu obecného přístupu. Díky tomuto přístupu můžou monitorovací nástroje v aplikaci spouštět některé funkční testy. Mezi příklady patří registrace nového uživatele, přihlášení a umístění testovací objednávky. Zároveň můžete také ověřit, že je dostupný obecný přístupový koncový bod.
Určete typ informací, které se mají ve službě shromažďovat v reakci na žádosti o monitorování. Musíte také určit, jak tyto informace vrátit. Většina existujících nástrojů a architektur se dívá jenom na stavový kód protokolu HTTP, který koncový bod vrátí. Pokud chcete vrátit a ověřit další informace, možná budete muset vytvořit vlastní monitorovací nástroj nebo službu.
Zjistěte, kolik informací se má shromáždit. Provádění nadměrného zpracování během kontroly může aplikaci přetížit a ovlivnit ostatní uživatele. Doba zpracování může také překročit časový limit monitorovacího systému. V důsledku toho může systém označit aplikaci jako nedostupnou. Většina aplikací zahrnuje instrumentaci, jako jsou obslužné rutiny chyb a čítače výkonu. Tyto nástroje můžou protokolovat výkon a podrobné informace o chybách, což může stačit. Místo vrácení dalších informací z kontroly stavu zvažte použití těchto dat.
Zvažte ukládání stavu koncového bodu do mezipaměti. Spuštění kontroly stavu často může být nákladné. Pokud je například stav hlášen prostřednictvím řídicího panelu, nechcete, aby každý požadavek na řídicí panel aktivoval kontrolu stavu. Místo toho pravidelně kontrolujte stav systému a stav do mezipaměti. Zveřejněte koncový bod, který vrací stav uložený v mezipaměti.
Naplánujte konfiguraci zabezpečení pro koncové body monitorování. Konfigurací zabezpečení můžete pomoct chránit koncové body před veřejným přístupem, což může být následující:
- Vystavení aplikace útokům se zlými úmysly
- Riskujte vystavení citlivých informací.
- Přilákejte útoky na odepření služeb (DoS).
Zabezpečení se obvykle konfiguruje v konfiguraci aplikace. Pak můžete nastavení snadno aktualizovat bez restartování aplikace. Zvažte použití jednoho nebo více z těchto postupů:
Zabezpečte koncový bod vyžadováním ověření. Pokud monitorovací služba nebo nástroj podporuje ověřování, můžete v hlavičce požadavku použít ověřovací klíč zabezpečení. Můžete také předat přihlašovací údaje s požadavkem. Při použití ověřování zvažte přístup ke koncovým bodům kontroly stavu. Například služba Aplikace Azure má integrovanou kontrolu stavu, která se integruje s funkcemi ověřování a autorizace služby App Service.
Použijte skrytý koncový bod. Například zveřejnit koncový bod na jiné IP adrese, než kterou používá výchozí adresa URL aplikace. Nakonfigurujte koncový bod na nestandardním portu HTTP. Zvažte také použití složité cesty k testovací stránce. V konfiguraci aplikace můžete obvykle zadat další adresy koncových bodů a porty. V případě potřeby můžete přidat položky pro tyto koncové body na server DNS. Pak se nemusíte přímo zadávat IP adresu.
Zveřejněte na koncový bod metodu, která přijímá parametr, jako je hodnota klíče nebo hodnota režimu operace. Když požadavek dorazí, může kód spustit konkrétní testy, které závisí na hodnotě parametru. Kód může vrátit chybu 404 (Nenalezena), pokud nerozpozná hodnotu parametru. V konfiguraci aplikace je možné definovat hodnoty parametrů.
Použijte samostatný koncový bod, který provádí základní funkční testy bez ohrožení provozu aplikace. S tímto přístupem můžete snížit dopad útoku DoS. V ideálním případě nepoužívejte test, který může zveřejnit citlivé informace. Někdy musíte vrátit informace, které by mohly být užitečné pro útočníka. V tomto případě zvažte, jak chránit koncový bod a data před neoprávněným přístupem. Spoléhat se na obskurzitu nestačí. Zvažte také použití připojení HTTPS a šifrování citlivých dat, i když tento přístup zvyšuje zatížení serveru.
Rozhodněte se, jak zajistit, aby agent monitorování fungoval správně. Jedním z přístupů je zveřejnění koncového bodu, který vrací hodnotu z konfigurace aplikace nebo náhodné hodnoty, kterou můžete použít k otestování agenta. Také se ujistěte, že monitorovací systém provádí kontroly sám o sobě. Můžete použít vlastní test nebo integrovaný test, abyste zabránili monitorovacímu systému v vydávání falešně pozitivních výsledků.
Kdy se má tento model použít
Tento model je vhodný pro:
- Monitorování webů a webových aplikací k ověření dostupnosti
- Monitorování webů a webových aplikací ke kontrole správného fungování
- Monitorování služeb střední vrstvy nebo sdílených služeb za účelem detekce a izolace selhání, které mohou narušit jiné aplikace.
- Doplnění stávající instrumentace v aplikaci, jako jsou čítače výkonu a obslužné rutiny chyb. Kontrola ověření stavu nenahrazuje požadavky aplikace pro protokolování a auditování. Instrumentace může poskytnout cenné informace pro existující architekturu, která monitoruje čítače a protokoly chyb, aby se zjistila selhání nebo jiné problémy. Instrumentace ale nemůže poskytnout informace, pokud aplikace není k dispozici.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu monitorování koncových bodů stavu v návrhu úlohy k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Tyto koncové body podporují upozornění na spolehlivost a řídicí panely úloh. Mohou být také použity jako signál pro samoopravení nápravy. - RE:07 Samoopravení a sebezáchování - RE:10 Strategie monitorování a upozorňování |
| Efektivita provozu pomáhá poskytovat kvalitu úloh prostřednictvím standardizovaných procesů a týmové soudržnosti. | Standardizace, které koncové body stavu se mají zveřejnit, a úroveň podrobností ve výsledcích vaší úlohy vám pomůže určit prioritu problémů se tříděním. - OE:07 Monitorovací systém |
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Koncové body stavu zlepšují logiku vyrovnávání zatížení směrováním provozu pouze na uzly, které jsou ověřené jako v pořádku. S další konfigurací můžete také získat metriky o dostupné kapacitě uzlu. - PE:05 Škálování a dělení |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
K hlášení stavu komponent infrastruktury aplikací můžete použít ASP.NET middlewarové kontroly stavu a knihoven. Tato architektura poskytuje způsob, jak hlásit kontroly stavu konzistentním způsobem. Implementuje mnoho postupů, které tento článek popisuje. Například kontroly stavu ASP.NET zahrnují externí kontroly, jako je připojení k databázi a konkrétní koncepty, jako jsou živé testy a testy připravenosti.
Na GitHubu je k dispozici několik ukázkových implementací, které používají ASP.NET kontroly stavu.
Monitorování koncových bodů v aplikacích hostovaných v Azure
Mezi možnosti monitorování koncových bodů v aplikacích Azure patří:
- Použijte integrované funkce monitorování Azure, jako je Azure Monitor.
- Použijte službu třetí strany nebo architekturu, jako je Microsoft System Center Operations Manager.
- Vytvořte vlastní nástroj nebo službu, která běží na vašem vlastním serveru nebo na hostovaném serveru.
I když Azure poskytuje komplexní možnosti monitorování, můžete k poskytování dalších informací použít další služby a nástroje. Application Insights, funkce Monitorování, je určená pro vývojové týmy. Tato funkce vám pomůže pochopit, jak vaše aplikace funguje a jak se používá. Application Insights monitoruje četnost požadavků, doby odezvy, míry selhání a míry závislostí. Může vám pomoct určit, jestli vás externí služby zpomalují.
Podmínky, které můžete monitorovat, závisí na hostitelském mechanismu, který zvolíte pro vaši aplikaci. Všechny možnosti v této části podporují pravidla upozornění. Pravidlo upozornění používá webový koncový bod, který zadáte v nastavení služby. Tento koncový bod by měl včas reagovat, aby systém upozornění mohl zjistit, jestli aplikace správně funguje. Další informace najdete v tématu Vytvoření nového pravidla upozornění.
Pokud dojde k závažnému výpadku, provoz klienta by měl být směrovatelný na nasazení aplikace, které je dostupné napříč jinými oblastmi nebo zónami. Tato situace je dobrým případem pro připojení mezi místy a globální vyrovnávání zatížení. Volba závisí na tom, jestli je aplikace interní nebo externí. Služby, jako jsou Azure Front Door, Azure Traffic Manager nebo sítě pro doručování obsahu, můžou směrovat provoz napříč oblastmi na základě dat, která sondy stavu poskytují.
Traffic Manager je služba směrování a vyrovnávání zatížení. Může použít řadu pravidel a nastavení k distribuci požadavků do konkrétních instancí vaší aplikace. Kromě směrování požadavků může Traffic Manager pravidelně testovat adresu URL, port a relativní cestu. Cíle příkazu ping zadáte s cílem určit, které instance vaší aplikace jsou aktivní a reagují na požadavky. Pokud Traffic Manager zjistí stavový kód 200 (OK), označí aplikaci jako dostupnou. Každý jiný stavový kód způsobí, že Traffic Manager aplikaci označí jako offline. Konzola Traffic Manageru zobrazuje stav každé aplikace. Každé pravidlo můžete nakonfigurovat tak, aby přesměrovává požadavky na jiné instance aplikace, které reagují.
Traffic Manager počká na určitou dobu , než obdrží odpověď z adresy URL monitorování. Ujistěte se, že se v tomto okamžiku spustí ověřovací kód stavu. Povolte latenci sítě pro dobu odezvy z Traffic Manageru do vaší aplikace a zpět.
Další kroky
Následující pokyny jsou užitečné pro implementaci tohoto modelu:
- Pokyny k monitorování stavu v aplikacích založených na mikroslužbách
- Monitorování stavu aplikací pro spolehlivost, součást architektury Azure Well-Architected Framework
- Vytvoření nového pravidla upozornění