Zpracovává chyby, z nichž může zotavení při připojování ke vzdálené službě nebo prostředku trvat různě dlouho. Umožňuje zlepšit stabilitu a odolnost aplikace.
Kontext a problém
V distribuovaném prostředí můžou volání vzdálených prostředků a služeb selhat z důvodu přechodných chyb, jako jsou pomalé síťové připojení, vypršení časových limitů nebo přetížené nebo nedostupné prostředky. Tyto chyby se obvykle po kratší době opraví samy a robustní cloudová aplikace by měla být připravena je zvládnout pomocí strategie, jako je model Opakování.
Můžou však nastat i situace, kdy jsou chyby způsobeny nepředvídatelnými událostmi a jejich oprava může trvat déle. Tyto chyby můžou být různě závažné, od částečného výpadku připojení až po úplné selhání služby. V těchto situacích může být zbytečné, aby se aplikace opakovaně pokoušela provést operaci, která pravděpodobně nebude úspěšná. Místo toho by aplikace měla rychle přijmout, že se operace nezdařila a měla by tuto chybu příslušně zpracovat.
Kromě toho pokud je služba velmi zaneprázdněná, selhání v jedné části systému může vést k dalším selháním. Například u operace, která vyvolává službu, je možné nakonfigurovat vypršení časového limitu. Pokud služba neodpoví v daném limitu, operace vrátí zprávu o neúspěšném provedení. Tato strategie však může způsobit zablokování velkého počtu souběžných žádostí o stejnou operaci až do vypršení časového limitu. Tyto blokované žádosti můžou blokovat důležité systémové prostředky, jako paměť, vlákna, připojení k databázím atd. V důsledku toho může dojít k vyčerpání těchto prostředků a tím k selhání dalších pravděpodobně nesouvisejících částí systému, které potřebují použít stejné prostředky. V těchto situacích by bylo vhodnější, kdyby operace selhala okamžitě a pokusila se vyvolat službu pouze tehdy, když bude pravděpodobné, že uspěje. Nastavení kratšího časového limitu může přispět k vyřešení tohoto problému. Časový limit by ale neměl být tak krátký, aby se operace většinou nezdařila, přestože žádost o službu by byla nakonec úspěšná.
Řešení
Model Jistič, který zpopularizoval Michael Nygard ve své knize Release It!, může zabránit tomu, aby se aplikace opakovaně pokoušela provést operaci, která pravděpodobně selže. Umožní aplikaci pokračovat bez čekání na opravu chyby a bez plýtvání cykly procesoru při zjišťování, že se jedná o přetrvávající chybu. Model Jistič taky umožňuje zjistit, jestli byla chyba opravena. Pokud se problém jeví jako vyřešený, může aplikace zkusit vyvolat operaci.
Účel modelu Jistič se liší od modelu Opakování. Model Opakování umožňuje aplikaci opakovat operaci s předpokladem, že bude úspěšná. Model Jistič zabraňuje aplikaci provést operaci, která pravděpodobně selže. Aplikace může tyto dva modely zkombinovat a pomocí modelu Opakování vyvolat operaci prostřednictvím jističe. Logika opakovaných pokusů by však měla brát ohled na výjimky vrácené jističem a pokud jistič signalizuje, že chyba není přechodná, neměla by provádět opakované pokusy.
Jistič funguje jako proxy pro operace, které můžou selhat. Proxy by měl sledovat počet chyb, ke kterým v poslední době došlo, a pomocí těchto informací rozhodnout, jestli má operace pokračovat nebo se má rovnou vrátit výjimka.
Proxy je možné implementovat jako stavový stroj s těmito stavy, které odpovídají funkci elektrického jističe:
Uzavřený: Žádost z aplikace se směruje na operaci. Proxy zaznamenává počet nedávných chyb a pokud je volání operace neúspěšné, tento počet navýší. Pokud počet chyb za určité časové období překročí zadanou hodnotu, proxy přejde do stavu Otevřený. V tomto okamžiku proxy spustí časovač časového limitu a po vypršení tohoto časovače přejde do stavu Částečně otevřený.
Účelem časovače je umožnit systému opravit problém, který způsobil selhání předtím, než se aplikaci znovu umožní provést operaci.
Otevřený: Žádost z aplikace selže okamžitě a do aplikace se vrátí výjimka.
Částečně otevřený: Od aplikace může projít a vyvolat operaci omezený počet žádostí. Pokud jsou tyto žádosti úspěšné, předpokládá se, že chyba způsobující selhání byla odstraněna a jistič přejde do stavu Uzavřený (čítač selhání se vynuluje). Pokud některý požadavek selže, jistič předpokládá, že chyba je stále k dispozici, takže se vrátí do stavu Otevření a restartuje časovač časového limitu, aby systém získal další časové období pro zotavení od selhání.
Stav Částečně otevřený je užitečný v tom, že brání zahlcení obnovující se služby novými žádostmi. Během obnovování může služba zpracovat určité omezené množství žádostí, ale větší množství žádostí může způsobit, že jí znovu vyprší časový limit nebo selže.
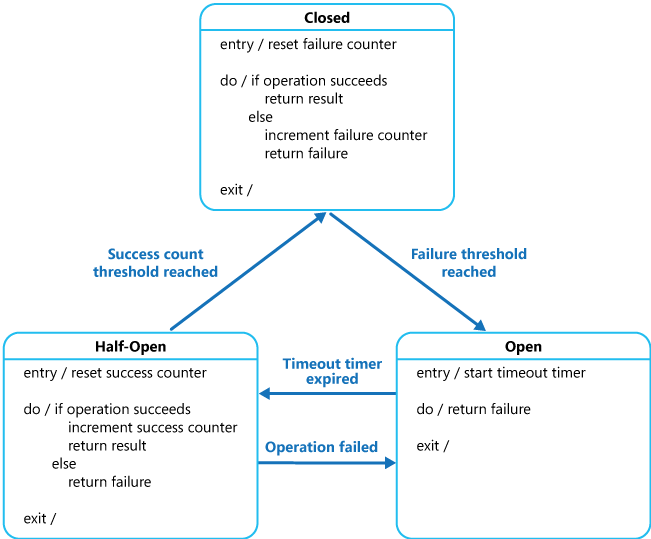
Čítač selhání použitý ve stavu Uzavřený, který můžete vidět na obrázku, je časový. Vynuluje se automaticky v pravidelných intervalech. Zabrání se tím přechodu jističe do stavu Otevřený, pokud dochází k občasnému selhání. Hodnota počtu selhání, která přepne jistič do stavu Otevřený, se dosáhne, pouze pokud dojde k určitému počtu selhání během daného časového intervalu. Čítač použitý ve stavu Částečně otevřený zaznamenává počet úspěšných pokusů o vyvolání operace. Jistič se vrátí do stavu Uzavřený po určitém počtu po sobě jdoucích úspěšných vyvolání operace. Pokud některé vyvolání selže, jistič hned přejde do stavu Otevřený. Čítač úspěšných pokusů se vynuluje, jakmile jistič přejde do stavu Částečně otevřený.
Způsob obnovení systému se řeší externě, například obnovením nebo restartováním komponenty, která selhala, nebo obnovením síťového připojení.
Model Jistič poskytuje stabilitu, zatímco se systém obnovuje po chybě, a minimalizuje dopad na výkon. Může pomoci udržovat dobu odezvy systému tím, že rychle odmítne žádost o operaci, která pravděpodobně selže, a nečeká na vypršení časového limitu operace nebo odpověď, která nikdy nepřijde. Pokud jistič vyvolá událost pokaždé, když změní stav, je možné pomocí těchto informací sledovat stav části systému chráněné jističem nebo upozornit správce v případě, že jistič přejde do stavu Otevřený.
Model je přizpůsobitelný a je možné ho upravit podle typu možného selhání. U jističe můžete například použít časovač s rostoucím časovým limitem vypršení. Jistič můžete nejprve umístit do otevřeného stavu po dobu několika sekund, a pokud se chyba nevyřešila, zvyšte časový limit na několik minut atd. V některých případech může být užitečné, aby stav Otevřený místo vrácení chyby a vyvolání výjimky vrátil výchozí hodnotu, která má smysl pro aplikaci.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
Zpracování výjimek. Aplikace vyvolávající operaci prostřednictvím jističe musí být připravena ke zpracování vyvolaných výjimek, pokud bude operace nedostupná. Způsob zpracování výjimek bude záviset na aplikaci. Aplikace může například dočasně snížit svoji funkčnost, vyvolat alternativní operaci s cílem provést stejnou úlohu nebo získat stejná data, nebo nahlásit výjimku uživateli a požádat jej, aby operaci zkusil později znovu.
Typy výjimek. Žádost může selhat z mnoha důvodů, z nichž některé můžou ukazovat na vážnější typ selhání než jiné. Žádost například může selhat, protože ve vzdálené službě došlo k chybě a obnovení bude trvat několik minut nebo z důvodu vypršení časového limitu v případě dočasně přetížené služby. Jistič pravděpodobně bude moct prozkoumat typy výjimek, ke kterým došlo, a upravit svoji strategii podle jejich povahy. Například pro přechod jističe do stavu Otevřený může být potřeba více výjimek vypršení časového limitu v porovnání s počtem selhání z důvodu úplné nedostupnosti služby.
Protokolování. Jistič by měl protokolovat všechny neúspěšné žádosti (a případně i úspěšné žádosti), aby správce mohl sledovat stav operace.
Obnovitelnost. Model Jistič byste měli nakonfigurovat tak, aby odpovídal pravděpodobnému modelu obnovení operace, kterou chrání. Pokud například jistič zůstane ve stavu Otevřený delší dobu, může vyvolávat výjimky i v případě, že příčina selhání už byla odstraněna. Podobně může jistič kolísat a snižovat dobu odezvy aplikací, pokud se přepíná ze stavu Otevřený do stavu Částečně otevřený příliš rychle.
Testování neúspěšných operací. Ve stavu Otevřený může jistič místo určování, kdy přejít do stavu Částečně otevřený pomocí časovače, pravidelně pingovat na vzdálenou službu nebo prostředek, aby určil, jestli už jsou dostupné. Toto pingnutí může mít podobu pokusu o vyvolání operace, která předtím selhala, nebo může využívat speciální operaci poskytnutou vzdálenou službou specificky pro testování stavu služby, jak popisuje článek o modelu Monitorování stavu pomocí koncových bodů.
Ruční přepsání. V systému, kde je doba obnovení selhávající operace velmi proměnlivá, je vhodné poskytnout možnost ručního resetování, která správci umožní zavřít jistič (a vynulovat čítač selhání). Podobně může správce vynutit přechod jističe do stavu Otevřený (a vynulovat čítač vypršení časového limitu), pokud je operace chráněná jističem dočasně nedostupná.
Souběžnost: K jednomu jističi může přistupovat velké množství souběžných instancí aplikace. Implementace by neměla blokovat souběžné žádosti nebo přidávat nadměrnou režii ke každému volání operace.
Rozlišení prostředků. Dávejte pozor při použití jednoho jističe pro jeden typ prostředku, pokud se může jednat o více podkladových nezávislých zprostředkovatelů. Například v úložišti dat, které obsahuje víc horizontálních oddílů, může být jeden horizontální oddíl plně dostupný a jiný může mít dočasný problém. Pokud se odpovědi na chybu v těchto scénářích sloučí, aplikace se může pokusit o přístup do některých horizontálních oddílů i přes vysokou pravděpodobnost selhání, zatímco přístup do jiných horizontálních oddílů může být blokovaný, přestože by byl pravděpodobně úspěšný.
Zrychlené jištění. Odpověď na selhání může někdy obsahovat dostatek informací na to, aby se jistič ihned aktivoval a zůstal aktivní po minimální dobu. Například odpověď na chybu ze sdíleného prostředku, který je přetížený, může signalizovat, že okamžité opakování se nedoporučuje, a že aplikace by pokus měla opakovat za několik minut.
Poznámka:
Služba může vrátit chybu HTTP 429 (příliš mnoho žádostí), pokud omezuje klienta, nebo chybu HTTP 503 (služba nedostupná), pokud je služba momentálně nedostupná. Odpověď může obsahovat další informace, jako je předpokládané trvání zpoždění.
Přehrávání neúspěšných žádostí. Ve stavu Otevřený může jistič místo pouhého rychlého selhání taky zaznamenat podrobnosti jednotlivých žádostí do deníku a zajistit, aby se tyto žádosti přehrály, jakmile budou vzdálený prostředek nebo služba dostupné.
Nevhodné časové limity u externích služeb. Jistič nemusí být schopný plně ochránit aplikace před operacemi, které se nezdaří v externích službách s nakonfigurovaným dlouhým časovým limitem vypršení. Pokud je časový limit příliš dlouhý, může být předtím, než jistič označí operaci za neúspěšnou, vlákno s jističem delší dobu blokované. Mezitím se mnoho dalších instancí aplikace taky může pokoušet vyvolat službu prostřednictvím jističe a zablokovat větší množství vláken, než všechna selžou.
Kdy se má tento model použít
Použijte tento model:
- Jestli chcete zabránit aplikaci ve vyvolávání vzdálené služby nebo v přístupu ke sdílenému prostředku, pokud má tato operace velkou pravděpodobnost neúspěchu.
Tento model se nedoporučuje:
- Ke zpracování přístupu k místním soukromým prostředkům v aplikaci, jako je například struktura dat v paměti. V tomto prostředí by použití jističe navýšilo režii v systému.
- Jako náhrada za zpracování výjimek v obchodní logice vašich aplikací.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu Jistič v návrhu úlohy k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Tento model brání přetížení chybné závislosti. Tento model můžete také použít k aktivaci řádného snížení výkonu úlohy. Jističe jsou často svázané s automatickým obnovením, aby poskytovaly samozásobování i samoopravení. - RE:03 Analýza režimu selhání - RE:07 Přechodné chyby - RE:07 Sebezáchování |
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Tento model zabraňuje přístupu při opakování při chybě, což může vést k nadměrnému využití prostředků během obnovení závislostí a může také přetížit výkon závislosti, která se pokouší o obnovení. - PE:07 Kód a infrastruktura - PE:11 Odpovědi na živé problémy |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Ve webové aplikaci se několik stránek plní daty načtenými z externí služby. Pokud je v systému implementované minimální ukládání do mezipaměti, většina přístupů na tyto stránky způsobí zpoždění odezvy služby. U připojení z webové aplikace ke službě se dá nakonfigurovat doba vypršení časového limitu (obvykle 60 sekund) a pokud služba v tomto limitu neodpoví, logika v jednotlivých webových stránkách bude předpokládat, že služba je nedostupná a způsobí výjimku.
Pokud ale dojde k selhání služby a systém bude hodně vytížený, můžou být uživatelé nuceni čekat až 60 sekund, než se zobrazí výjimka. V důsledku pak může dojít k vyčerpání prostředků, jako je paměť, připojení a vlákna, což může bránit ostatním uživatelům v připojení k systému, i když nepřistupují na stránky, které načítají data ze služby.
Vyčerpání prostředků by se dalo oddálit škálováním systému přidáním dalších webových serverů a implementací vyrovnávání zatížení, ale problém se tím nevyřeší, protože žádosti uživatelů i nadále nebudou reagovat a stále se může stát, že všechny webové servery vyčerpají všechny prostředky.
Zahrnutí jističe do logiky, která se připojuje ke službě a načítá data, by mohlo problém vyřešit a zpracovávat selhání služby elegantněji. Žádosti uživatelů se sice i nadále nezdaří, ale nezdaří se rychleji a prostředky nebudou blokované.
Třída CircuitBreaker uchovává informace o stavu jističe v objektu, který implementuje rozhraní ICircuitBreakerStateStore zobrazené v následujícím kódu.
interface ICircuitBreakerStateStore
{
CircuitBreakerStateEnum State { get; }
Exception LastException { get; }
DateTime LastStateChangedDateUtc { get; }
void Trip(Exception ex);
void Reset();
void HalfOpen();
bool IsClosed { get; }
}
Vlastnost State označuje aktuální stav jističe a je buď Open (Otevřený), HalfOpen (Částečně otevřený) nebo Closed (Zavřený), podle definice výpočtu CircuitBreakerStateEnum. Vlastnost IsClosed by měla mít hodnotu true, pokud je jistič zavřený, a hodnotu closed, pokud je otevřený nebo částečně otevřený. Metoda Trip přepíná stav jističe na otevřený a zaznamenává výjimku, která změnu stavu způsobila a datum a čas, kdy k ní došlo. Tyto informace vrací vlastnosti LastException a LastStateChangedDateUtc. Metoda Reset uzavírá jistič a metoda HalfOpen jej uvádí do částečně otevřeného stavu.
Třída InMemoryCircuitBreakerStateStore v příkladu obsahuje implementaci rozhraní ICircuitBreakerStateStore. Třída CircuitBreaker vytváří instanci této třídy pro uložení stavu jističe.
Metoda ExecuteAction ve třídě CircuitBreaker zahrne operaci určenou jako delegát Action. Pokud je jistič zavřený, ExecuteAction vyvolá delegáta Action. Pokud se operace nezdaří, obslužná rutina výjimky zavolá TrackException. Tím se jistič nastaví do otevřeného stavu. Tento tok znázorňuje následující příklad.
public class CircuitBreaker
{
private readonly ICircuitBreakerStateStore stateStore =
CircuitBreakerStateStoreFactory.GetCircuitBreakerStateStore();
private readonly object halfOpenSyncObject = new object ();
...
public bool IsClosed { get { return stateStore.IsClosed; } }
public bool IsOpen { get { return !IsClosed; } }
public void ExecuteAction(Action action)
{
...
if (IsOpen)
{
// The circuit breaker is Open.
... (see code sample below for details)
}
// The circuit breaker is Closed, execute the action.
try
{
action();
}
catch (Exception ex)
{
// If an exception still occurs here, simply
// retrip the breaker immediately.
this.TrackException(ex);
// Throw the exception so that the caller can tell
// the type of exception that was thrown.
throw;
}
}
private void TrackException(Exception ex)
{
// For simplicity in this example, open the circuit breaker on the first exception.
// In reality this would be more complex. A certain type of exception, such as one
// that indicates a service is offline, might trip the circuit breaker immediately.
// Alternatively it might count exceptions locally or across multiple instances and
// use this value over time, or the exception/success ratio based on the exception
// types, to open the circuit breaker.
this.stateStore.Trip(ex);
}
}
Následující příklad ukazuje kód (vynechaný v předchozí příkladu), který se spustí, pokud není jistič uzavřený. Nejprve ověří, jestli byl jistič otevřený po dobu delší, než je doba určená místním polem OpenToHalfOpenWaitTime ve třídě CircuitBreaker. Pokud ano, metoda ExecuteAction nastaví jistič do částečně otevřeného stavu. Potom se pokusí provést operaci určenou delegátem Action.
Pokud operace proběhne úspěšně, jistič se obnoví do zavřeného stavu. Pokud se operace nezdaří, jistič se přepne zpět do otevřeného stavu a čas výskytu výjimky se aktualizuje, aby jistič počkal další časový úsek, než se pokusí provést operaci znovu.
Pokud byl jistič otevřený jen krátkou dobu, kratší než hodnota OpenToHalfOpenWaitTime, metoda ExecuteAction jednoduše vyvolá výjimku CircuitBreakerOpenException a vrátí chybu, která způsobila přechod jističe do otevřeného stavu.
Kromě toho pomocí zámku zabrání jističi v tom, aby se pokoušel provádět souběžná volání operace, zatímco je v částečně otevřeném stavu. Souběžný pokus o vyvolání operace se zpracuje, jako kdyby byl jistič otevřený, a nezdaří se s výjimkou, jak je popsáno dále.
...
if (IsOpen)
{
// The circuit breaker is Open. Check if the Open timeout has expired.
// If it has, set the state to HalfOpen. Another approach might be to
// check for the HalfOpen state that had be set by some other operation.
if (stateStore.LastStateChangedDateUtc + OpenToHalfOpenWaitTime < DateTime.UtcNow)
{
// The Open timeout has expired. Allow one operation to execute. Note that, in
// this example, the circuit breaker is set to HalfOpen after being
// in the Open state for some period of time. An alternative would be to set
// this using some other approach such as a timer, test method, manually, and
// so on, and check the state here to determine how to handle execution
// of the action.
// Limit the number of threads to be executed when the breaker is HalfOpen.
// An alternative would be to use a more complex approach to determine which
// threads or how many are allowed to execute, or to execute a simple test
// method instead.
bool lockTaken = false;
try
{
Monitor.TryEnter(halfOpenSyncObject, ref lockTaken);
if (lockTaken)
{
// Set the circuit breaker state to HalfOpen.
stateStore.HalfOpen();
// Attempt the operation.
action();
// If this action succeeds, reset the state and allow other operations.
// In reality, instead of immediately returning to the Closed state, a counter
// here would record the number of successful operations and return the
// circuit breaker to the Closed state only after a specified number succeed.
this.stateStore.Reset();
return;
}
}
catch (Exception ex)
{
// If there's still an exception, trip the breaker again immediately.
this.stateStore.Trip(ex);
// Throw the exception so that the caller knows which exception occurred.
throw;
}
finally
{
if (lockTaken)
{
Monitor.Exit(halfOpenSyncObject);
}
}
}
// The Open timeout hasn't yet expired. Throw a CircuitBreakerOpen exception to
// inform the caller that the call was not actually attempted,
// and return the most recent exception received.
throw new CircuitBreakerOpenException(stateStore.LastException);
}
...
Aplikace chrání operaci pomocí objektu CircuitBreaker tak, že vytvoří instanci třídy CircuitBreaker, vyvolá metodu ExecuteAction a určí operaci, která se má provést, jako parametr. Aplikace by měla být v případě selhání operace připravená zachytit výjimku CircuitBreakerOpenException, protože jistič je otevřený. Podívejte se na ukázku kódu:
var breaker = new CircuitBreaker();
try
{
breaker.ExecuteAction(() =>
{
// Operation protected by the circuit breaker.
...
});
}
catch (CircuitBreakerOpenException ex)
{
// Perform some different action when the breaker is open.
// Last exception details are in the inner exception.
...
}
catch (Exception ex)
{
...
}
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující modely:
Model spolehlivé webové aplikace ukazuje, jak u webových aplikací konvergovaných v cloudu použít model jističe.
Model opakování. Popisuje, jak může aplikace řešit předpokládaná dočasná selhání při pokusu o připojení k prostředku služby nebo síťovému prostředku, a to transparentním opakováním operace, která původně selhala.
Model monitorování koncových bodů stavu Jistič může otestovat stav služby tím, že odešle žádost do koncového bodu určeného službou. Služba by měla vrátit informaci o svém stavu.