Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Storage
Generuje předem vyplněná zobrazení nad daty v jednom nebo několika úložištích dat v případě, že data nejsou pro požadované operace dotazů ideálně naformátovaná. To může pomoct podpořit efektivní dotazování a extrahování dat a zlepšit výkon aplikace.
Kontext a problém
Při ukládání dat se většinou vývojáři a správci dat prioritně zaměřují na způsob uložení dat a jejich čtení je až na druhém místě. Formát zvoleného úložiště obvykle úzce souvisí s formátem dat, požadavky na správu velikosti dat, integritou dat a typem používaného úložiště. Když například používáte úložiště dokumentů NoSQL, data se často reprezentují jako řada agregací, z nichž každá obsahuje všechny informace pro danou entitu.
To však může mít na dotazy negativní vliv. Když dotaz potřebuje pouze podmnožinu dat z některých entit, jako je například souhrn objednávek pro několik zákazníků bez všech podrobností každé objednávky, musí se extrahovat všechna data příslušných entit, aby bylo možné požadované informace získat.
Řešení
Běžným řešením pro podporu efektivního dotazování je předem vygenerovat zobrazení, které materializuje data ve formátu vhodném pro požadovanou sadu výsledků dotazu. Model materializovaného zobrazení popisuje generování předem vyplněných zobrazení dat v prostředích, ve kterých zdrojová data nejsou vhodným formátem pro dotazování, generování vhodného dotazu je obtížné nebo výkon dotazu je vzhledem k povaze dat nebo úložiště dat nízký.
Tato materializovaná zobrazení, která obsahují pouze data vyžadovaná dotazem, umožňují aplikacím rychle získat potřebné informace. Mimo spojování tabulek nebo kombinování datových entit mohou materializovaná zobrazení obsahovat aktuální hodnoty počítaných sloupců nebo datových položek, výsledky kombinování hodnot nebo provádění transformací na datových položkách a hodnoty zadané jako část dotazu. Materializované zobrazení je dokonce možné optimalizovat pro jediný dotaz.
Zásadním aspektem je, že materializované zobrazení a data, která obsahuje, je možné zcela odstranit, protože ho můžete znovu celé vytvořit ze zdrojových úložišť dat. Materializované zobrazení se nikdy neaktualizuje přímo aplikací, a proto jde o specializovanou mezipaměť.
Když se zdrojová data zobrazení změní, je nutné ho aktualizovat, aby obsahovalo nové informace. Můžete naplánovat, aby se to dělo automaticky nebo když systém zjistí změnu původních dat. V některých případech může být potřeba toto zobrazení znovu ručně vygenerovat. Obrázek ukazuje příklad toho, jak je možné materializované zobrazení použít.
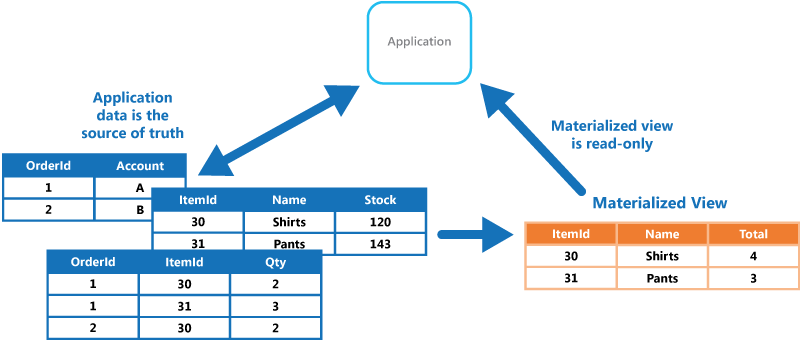
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
Jak a kdy se bude zobrazení aktualizovat. V ideálním případě se znovu vygeneruje v reakci na událost označující změnu zdrojových dat, což však může vést k nadměrným nákladům, pokud se zdrojová data mění často. Další možností pro vygenerování nového zobrazení je zvážit použití plánované úlohy, externí aktivační události nebo manuální akce.
V některých systémech, například když používáte model Event Sourcing k udržování úložiště pouze událostí, které upravily data, jsou materializovaná zobrazení nezbytná. Jediný způsob, jak získat informace z úložiště událostí, může být předvyplnění zobrazení prověřením všech událostí pro určení aktuálního stavu. Pokud model Event Sourcing nepoužíváte, měli byste zvážit, zda je materializované zobrazení užitečné, nebo ne. Materializovaná zobrazení jsou obvykle speciálně přizpůsobená jednomu nebo malému počtu dotazů. Když se používá mnoho dotazů, materializovaná zobrazení mohou mít ve výsledku nepřijatelné požadavky na úložnou kapacitu a náklady úložiště.
Zvažte dopad na konzistenci dat, když zobrazení generujete a když ho aktualizujte (pokud máte nastavený plán). Pokud se zdrojová data mění v době, kdy se zobrazení generuje, kopie dat v zobrazení nebude plně v souladu z původními daty.
Zvažte, kam budete zobrazení ukládat. Zobrazení se nemusí nacházet ve stejném úložišti nebo oddílu jako původní data. Může to být podmnožina složená z několika různých diskových oddílů.
Pokud se zobrazení ztratí, lze ho znovu vytvořit. Proto pokud je zobrazení přechodné a používá se pouze ke zlepšení výkonu dotazů tím, že odráží současný stav dat nebo se snaží vylepšit škálovatelnost, je možné ho uložit do mezipaměti nebo do nějakého méně spolehlivého umístění.
Když definujete materializované zobrazení, maximalizujte jeho hodnotu přidáním položek nebo sloupců dat na základě výpočtu nebo transformace existujících položek dat nebo případné kombinace těchto hodnot.
Kde to mechanismus úložiště podporuje, zvažte indexování materializovaného zobrazení, abyste dále zvýšili výkon. Většina relačních databází a řešení pro velké objemy dat založených na službě Apache Hadoop podporuje u zobrazení indexování.
Kdy se má tento model použít
Tento model je vhodný v následujících případech:
- Vytváření materializovaných zobrazení z dat, která se obtížně přímo dotazují, nebo kde dotazy musí být velmi komplexní, aby extrahovaly normalizovaně, částečně strukturovaně nebo nestrukturovaně uložená data.
- Vytváření dočasných zobrazení, která mohou výrazně zlepšit výkon dotazů nebo mohou jednat přímo jako zdrojová zobrazení nebo objekty přenosu dat u uživatelských rozhraní, vytváření sestav nebo zobrazení.
- Podporování příležitostně připojených nebo odpojených scénářů, u kterých není připojení k úložišti dat vždy k dispozici. Zobrazení je v tomto případě možné uložit do místní mezipaměti.
- Zjednodušení dotazů a zveřejnění dat pro experimentování takovým způsobem, který nevyžaduje znalost formátu zdrojových dat. Například spojením různých tabulek v jedné či více databázích nebo jedné či více doménách v úložištích NoSQL a následným formátování dat, aby byla vhodná pro jejich případné použití.
- Poskytnutí přístupu k určitým podmnožinám zdrojových dat, které by kvůli bezpečnosti nebo ochraně osobních údajů neměly být obecně přístupné, upravitelné nebo zveřejněné uživatelům.
- Přemostění různých úložišť dat kvůli využití jejich jednotlivých možností. Například použití cloudového úložiště, které je efektivní pro zapisování jako úložiště referenčních dat, a relační databáze, která nabízí dobrý výkon na dotazování a čtení pro uložení materializovaných zobrazení.
- Pokud používáte mikroslužby, doporučuje se je volně propojit, včetně jejich úložiště dat. Materializovaná zobrazení vám proto můžou pomoct s konsolidací dat z vašich služeb. Pokud materializovaná zobrazení nejsou v architektuře mikroslužeb nebo konkrétním scénáři vhodná, zvažte, jestli máte dobře definované hranice, které odpovídají návrhu řízenému doménou (DDD) a agregují data při vyžádání.
Tento model není vhodný v následujících případech:
- Zdrojová data jsou jednoduchá a snadno dotazatelná.
- Zdrojová data se velmi rychle mění nebo je možné k nim získat přístup bez použití zobrazení. V těchto případech byste se měli vyhnout nárokům na zpracování z vytváření zobrazení.
- Konzistence dat má vysokou prioritu. Zobrazení nemusí být vždy plně konzistentní s původními daty.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu materializovaného zobrazení v návrhu úlohy k řešení cílů a principů zahrnutých v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Materializovaná zobrazení ukládají výsledky složitých výpočtů nebo dotazů bez nutnosti překompilace databázového stroje nebo klienta pro každou žádost. Tento návrh snižuje celkovou spotřebu prostředků. - PE:08 Výkon dat |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Následující obrázek zobrazuje příklad použití modelu materializovaného zobrazení k vygenerování souhrnu prodeje. Data v tabulkách Order (objednávka), OrderItem (položka) a Customer (zákazník) v samostatných oddílech v účtu úložiště Azure se zkombinovala, aby vygenerovala zobrazení udávající celkovou hodnotu prodeje každého produktu v kategorii Electronics (elektronika) společně s počtem zákazníků, kteří si každou položku zakoupili.
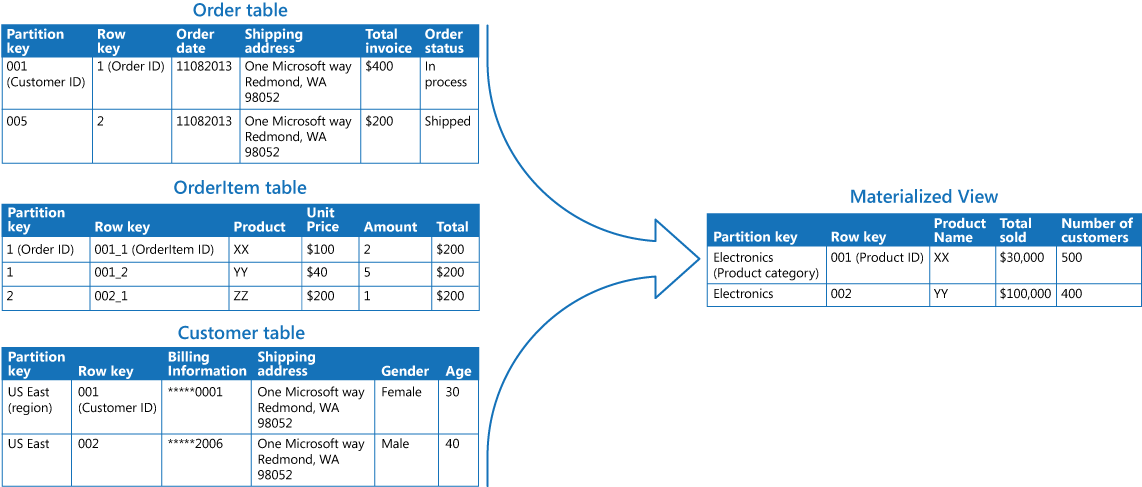
Vytvoření tohoto materializovaného zobrazení vyžaduje komplexní dotazy. Zveřejněním výsledku dotazu ve formě materializovaného zobrazení ale uživatelé mohou jednoduše získat výsledky a použít je přímo nebo je začlenit do jiného dotazu. Toto zobrazení se pravděpodobně použije v systému vytváření sestav nebo v řídicím panelu a je možné ho aktualizovat na základě plánu (například týdně).
I když tento příklad používá úložiště tabulek Azure, mnoho systémů pro správu relačních databází také poskytuje nativní podporu materializovaných zobrazení.
Další kroky
- Úvod do konzistence dat. Souhrnné informace v materializovaném zobrazení je nutné spravovat, aby odrážely podkladové hodnoty dat. Jelikož se hodnoty dat mění, není příliš praktické souhrn dat aktualizovat v reálném čase a místo toho je lepší implementovat konzistentní přístup. Shrnuje problémy kolem udržování konzistentnosti distribuovaných dat a popisuje výhody a nevýhody různých modelů konzistence.
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující vzory:
- Model dělení zodpovědnosti příkazů a dotazů (CQRS): používá se k aktualizaci informací v materializovaném zobrazení a funguje tak, že reaguje na události, ke kterým dochází, když se podkladové hodnoty dat mění.
- Event Sourcing vzor Použijte ve spojení s modelem CQRS k udržení informací v materializovaném zobrazení. Když se hodnoty dat, na kterých je materializované zobrazení založené, změní, systém může vyvolat události, které tyto změny popisují a uloží je do úložiště událostí.
- Model tabulky indexů: data v materializovaném zobrazení se obvykle uspořádávají podle primárního klíče, ale dotazy mohou z tohoto zobrazení potřebovat načíst informace prozkoumáním dat v jiných polích. Používá se k vytváření sekundárních indexů ze sad dat pro úložiště dat, která nativně sekundární indexy nepodporují.