Umožňuje aplikaci řešit přechodná selhání při pokusu o připojení k prostředku služby nebo síťovému prostředku, a to transparentním opakováním operace, která selhala. Může se tak zlepšit stabilita aplikace.
Kontext a problém
Aplikace, která komunikuje s prvky běžícími v cloudu, musí být citlivá na přechodné chyby, ke kterým může v tomto prostředí docházet. K takovým chybám patří momentální ztráta síťového připojení k součástem a službám, dočasná nedostupnost služby nebo vypršení časových limitů, ke kterému dochází, když je služba přetížená.
Tyto chyby se obvykle opraví samy. Pokud se akce, která vyvolala chybu, se vhodným zpožděním zopakuje, bude pravděpodobně úspěšná. Například databázová služba, která zpracovává velký počet souběžných požadavků, může implementovat strategii omezování, která dočasně odmítne všechny další požadavky, dokud se jeho úloha nezpřesní. Aplikaci, která se pokusí o přístup k databázi, se nemusí připojení podařit. Pokud se ale aplikace pokusí po určité prodlevě znovu, může uspět.
Řešení
V cloudu by se měly očekávat přechodné chyby a aplikace by měla být navržená tak, aby je elegantně a transparentně zpracovávala. Tím minimalizujete dopady chyb, které můžou mít na obchodní úlohy, které aplikace provádí. Nejběžnějším vzorem návrhu, který se má řešit, je zavést mechanismus opakování.
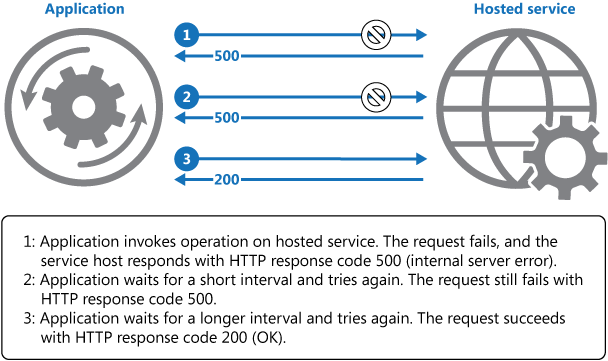
Výše uvedený diagram znázorňuje vyvolání operace v hostované službě pomocí mechanismu opakování. Pokud je žádost po předdefinovaném počtu pokusů neúspěšná, měla by aplikace jednat s chybou jako s výjimkou a odpovídajícím způsobem ji zpracovat.
Poznámka:
Vzhledem k běžné povaze přechodných chyb jsou teď integrované mechanismy opakování dostupné v mnoha klientských knihovnách a cloudových službách s určitou mírou konfigurovatelnosti počtu maximálních opakování, zpoždění mezi opakovanými pokusy a dalšími parametry. Integrovanou podporu opakování pro mnoho služeb Azure najdete tady a Microsof Entity Framework poskytuje zařízení pro opakování neúspěšných databázových operací.
Strategie opakování
Když se aplikace pokusí poslat žádost vzdálené službě a zjistí chybu, může tuto chybu řešit pomocí následujících strategií:
Zrušení. Pokud to vypadá, že chyba není přechodná nebo že opakovaná akce nebude úspěšná, měla by aplikace operaci zrušit a ohlásit výjimku.
Zkuste to znovu okamžitě. Pokud je konkrétní nahlášená chyba neobvyklá nebo vzácná, například že se síťový paket během přenosu poškodí, nejlepší postup může být okamžité opakování požadavku.
Opakování po časové prodlevě. Pokud je chyba způsobená jedním z nejběžnějších selhání připojení nebo zaneprázdnění, může síť nebo služba potřebovat krátkou dobu, než se problémy s připojením opraví nebo se vymaže backlog práce, takže programově zpozdí opakování dobrou strategii. V mnoha případech by se mělo zvolit období mezi opakovanými pokusy, aby se požadavky z více instancí aplikace co nejvíce rovnoměrně rozložily, aby se snížila pravděpodobnost přetížení zaneprázdněné služby.
Pokud opakovaná žádost selže, může aplikace počkat a udělat další pokus. V případě potřeby se tento proces může opakovat s narůstajícími zpožděními mezi opakovanými pokusy až do určitého maximálního počtu žádostí. Zpoždění se může zvětšovat přírůstkově nebo exponenciálně v závislosti na typu selhání a pravděpodobnosti, že se během této doby podaří chybu opravit.
Aplikace by měla všechny pokusy o přístup ke vzdálené službě provádět pomocí kódu, který implementuje zásady opakování odpovídající některé z výše uvedených strategií. Žádosti odesílané různým službám můžou podléhat různým zásadám.
Aplikace by měla protokolovat podrobnosti chyb a neúspěšné operace. Tyto informace jsou užitečné pro operátory. To znamená, že aby se zabránilo zahlceným operátorům s upozorněními na operace, kdy byly následné pokusy o úspěšné pokusy úspěšné, je nejlepší protokolovat časná selhání jako informační položky a pouze selhání posledního pokusu o opakování jako skutečnou chybu. Tady je příklad , jak by tento model protokolování vypadal.
Pokud je služba často nedostupná nebo přetížená, bývá to způsobené tím, že vyčerpala svoje prostředky. Četnost těchto chyb můžete snížit horizontálním navýšením kapacity služby. Pokud je třeba databázová služba neustále přetížená, může být prospěšné databázi rozdělit a rozložit zatížení mezi několik serverů.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti.
Dopad na výkon
Zásady opakování by měly být vyladěné tak, aby odpovídaly obchodním požadavkům aplikace a povaze selhání. U některých nekritických operací je rychlé vygenerování chyby lepší než několikanásobné opakování, které může mít dopad na propustnost aplikace. Například v interaktivní webové aplikaci, která přistupuje ke vzdálené službě, je lepší selhat po menším počtu opakovaných pokusů pouze s krátkou prodlevou mezi opakovanými pokusy a zobrazit uživateli vhodnou zprávu (například "zkuste to znovu později"). U dávkové aplikace může být vhodnější zvětšit počet opakovaných pokusů s exponenciálně rostoucím zpožděním mezi pokusy.
Agresivní zásady opakování s minimální prodlevou mezi pokusy a velkým počtem opakování můžou ještě více degradovat přetíženou službu, která běží na hranici své kapacity. Takové zásady opakování můžou mít dopad i na odezvu aplikace, která se neustále pokouší provést neúspěšnou operaci.
Pokud žádost selže i po značném počtu opakování, je lepší, když aplikace zabrání příchodu dalších žádostí do stejného prostředku a okamžitě ohlásí chybu. Až časový interval vyprší, může aplikace pokusně propustit jednu nebo více žádostí, aby zjistila, jestli budou úspěšné. Další informace o této strategii najdete v článku o modelu Jistič.
Idempotentnost
Zvažte, jestli je operace idempotentní. Pokud ano, dá se ze své podstaty bezpečně opakovat. Jinak může opakování způsobit, že se operace provede více než jednou a s nezamýšlenými vedlejšími účinky. Služba může třeba žádost přijmout, úspěšně ji zpracovat, ale nepodaří se jí odeslat odpověď. V tomto okamžiku může logika opakování poslat žádost znovu, protože předpokládá, že první žádost nebyla přijata.
Typ výjimky
Žádost posílaná službě může selhat z nejrůznějších důvodů a v závislosti na povaze chyby můžou být vyvolány různé výjimky. Některé výjimky signalizují chybu, která se dá rychle vyřešit, jiné signalizují, že chyba má delší trvání. Je užitečné, když zásady opakování upraví na základě typu výjimky dobu mezi opakovanými pokusy.
Konzistence transakcí
Zvažte, jak opakování operace, která je součástí transakce, ovlivní celkovou konzistenci transakce. Vylaďte zásady opakování pro transakční operace tak, abyste maximalizovali šanci na úspěch a omezili nutnost vracet zpět všechny kroky transakce.
Obecné pokyny
Zajistěte, aby veškerý kód opakování byl plně testovaný na nejrůznější chybové stavy. Zkontrolujte, jestli opakování nemá vážný dopad na výkon nebo spolehlivost aplikace, jestli nezpůsobuje nadměrné zatížení služeb a prostředků nebo negeneruje konflikty časování nebo kritické body.
Logiku opakování implementujte jenom v případě, že plně rozumíte kontextu neúspěšné operace. Pokud třeba úloha obsahující zásady opakování vyvolá jinou úlohu, které také obsahuje zásady opakování, může tato další vrstva opakování značně prodloužit zpracování. Pak může být lepší nakonfigurovat úlohu nižší úrovně tak, aby rychle vygenerovala chybu a ohlásila příčinu chyby úloze, která tuto úlohu vyvolala. Tato úloha vyšší úrovně pak může chybu zpracovat na základě vlastních zásad.
Zaznamujte všechna selhání připojení, která způsobují opakování, aby bylo možné identifikovat základní problémy s aplikací, službami nebo prostředky.
Prozkoumejte chyby, ke kterým bude s největší pravděpodobností u služby nebo prostředku docházet, a snažte se zjistit, jestli nejsou dlouhodobé nebo konečné. Pokud jsou, je lepší takovou chybu zpracovat jako výjimku. Aplikace může výjimku ohlásit nebo zaprotokolovat a pak se pokusit pokračovat – tak, že vyvolá alternativní službu (pokud je dostupná), nebo poskytne omezenou funkčnost. Další informace o zjišťování a zpracování dlouhodobých chyb najdete v článku o modelu Jistič.
Kdy se má tento model použít
Tento model použijte v případě, že v aplikaci při komunikaci se vzdálenou službou nebo přístupu ke vzdálenému prostředku může docházet k přechodným chybám. Předpokládá se, že tyto chyby budou krátkodobé, takže když se původně neúspěšná žádost zopakuje, může při příštím pokusu uspět.
Tento model nebude pravděpodobně vhodný v následujících případech:
- Když bude chyba nejspíš dlouhodobá – protože pak může opakování pokusů mít dopad na odezvu aplikace. Opakování žádosti, která bude nejspíš neúspěšná, může být pro aplikaci jenom ztráta času a prostředků.
- Pro zpracování selhání, která nejsou způsobená přechodnými chybami – například zpracování vnitřních výjimek způsobených chybami v obchodní logice aplikace.
- Jako alternativní řešení problémů se škálovatelností systému. Pokud v aplikaci dochází k častým chybám z přetížení, obvykle to signalizuje, že by se u příslušné služby nebo prostředku měla vertikálně navýšit kapacita.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu opakování v návrhu úlohy k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Zmírnění přechodných chyb v distribuovaném systému je základní technika pro zlepšení odolnosti úloh. - RE:07 Sebezáchování - RE:07 Přechodné chyby |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Další kroky
Než začnete psát vlastní logiku opakování, zvažte použití obecné architektury, jako je Polly pro .NET nebo Resilience4j pro Javu.
Při zpracování příkazů, které mění obchodní data, mějte na paměti, že opakování může vést k provedení akce dvakrát, což může být problematické, pokud je tato akce něco jako účtování platební karty zákazníka. Použití vzoru Idempotenci popsaného v tomto blogovém příspěvku vám může pomoct s těmito situacemi.
Související prostředky
Model spolehlivé webové aplikace ukazuje, jak použít vzor opakování u webových aplikací konvergovaných v cloudu.
Pro většinu služeb Azure zahrnují klientské sady SDK integrovanou logiku opakování. Další informace najdete v doprovodných materiálech k opakování služeb Azure.
Model Jistič. Pokud se dá očekávat, že selhání bude dlouhodobější, může být vhodnější implementovat model Jistič. Kombinace vzorů opakování a jističe poskytuje komplexní přístup ke zpracování chyb.