Doporučená pravidla upozornění pro clustery Kubernetes
Výstrahy ve službě Azure Monitor aktivně identifikují problémy související se stavem a výkonem vašich prostředků Azure. Tento článek popisuje, jak povolit a upravit sadu doporučených pravidel upozornění metrik, která jsou předdefinovaná pro vaše clustery Kubernetes.
Typy pravidel upozornění
U clusterů Kubernetes se používají dva typy pravidel upozornění na metriky.
| Typ pravidla upozornění | Popis |
|---|---|
| Pravidla upozornění metriky Prometheus | Použijte data metrik shromážděná z clusteru Kubernetes ve spravované službě Azure Monitoru pro Prometheus. Tato pravidla vyžadují povolení prometheus ve vašem clusteru a jsou uložená ve skupině pravidel Prometheus. |
| Pravidla upozornění na metriky platformy | Použijte metriky, které se automaticky shromažďují z clusteru AKS a ukládají se jako pravidla upozornění služby Azure Monitor. |
Povolení doporučených pravidel upozornění
Pomocí jedné z následujících metod povolte doporučená pravidla upozornění pro váš cluster. Pro stejný cluster můžete povolit pravidla upozornění na metriku Prometheus i platformu.
Poznámka:
Pokud chcete povolit doporučená upozornění v clusterech Kubernetes s podporou arc, jsou šablony ARM jedinou podporovanou metodou.
Pomocí webu Azure Portal se skupina pravidel Prometheus vytvoří ve stejné oblasti jako cluster.
V nabídce Upozornění pro váš cluster vyberte Nastavit doporučení.
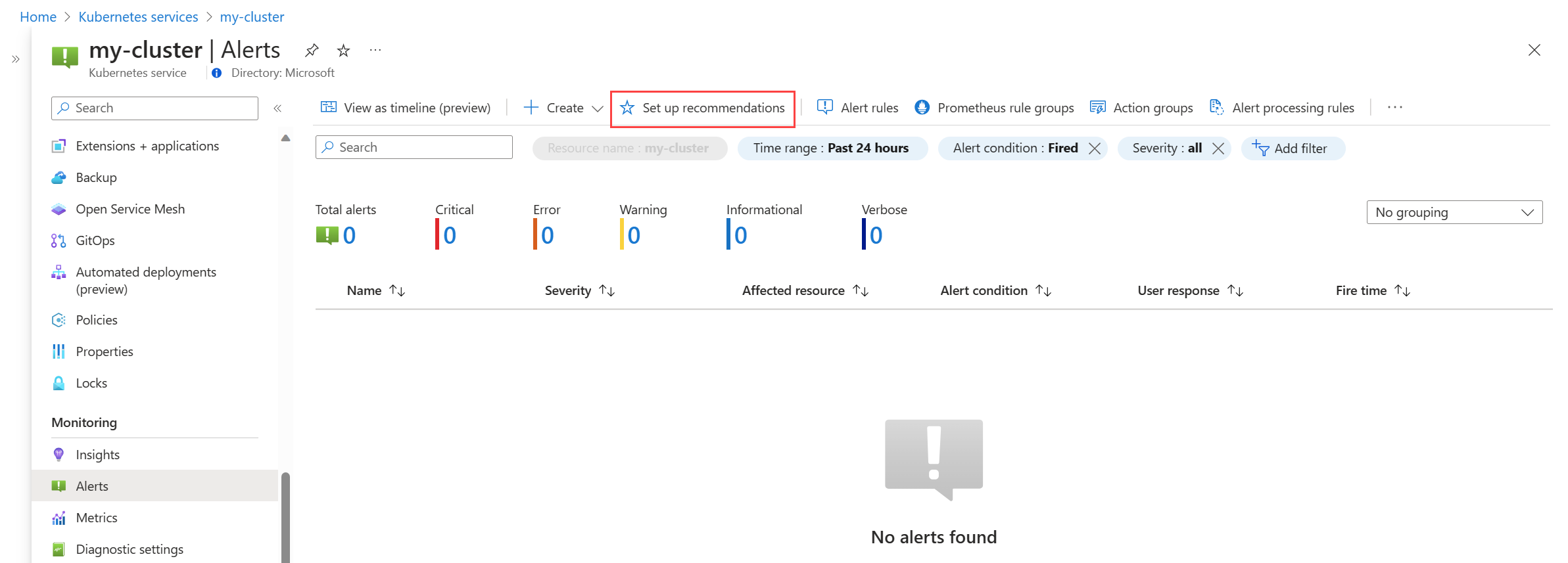
Dostupná pravidla upozornění platformy Prometheus a platformy se zobrazují s pravidly prometheus uspořádanými podle podů, clusterů a úrovní uzlů. Pokud chcete tuto sadu pravidel povolit, přepněte skupinu pravidel Prometheus. Rozbalením skupiny zobrazíte jednotlivá pravidla. Můžete ponechat výchozí hodnoty nebo zakázat jednotlivá pravidla a upravit jejich název a závažnost.
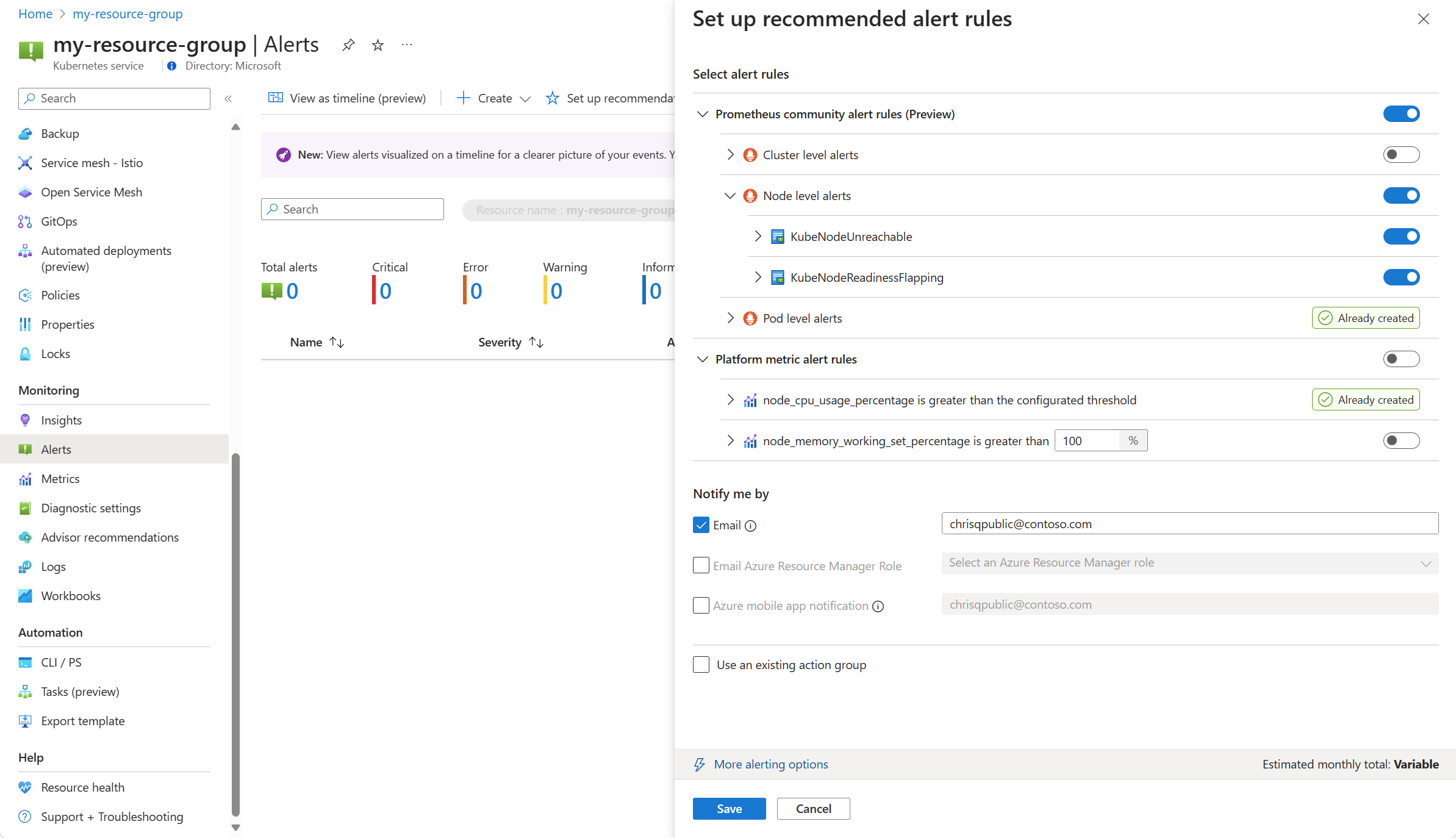
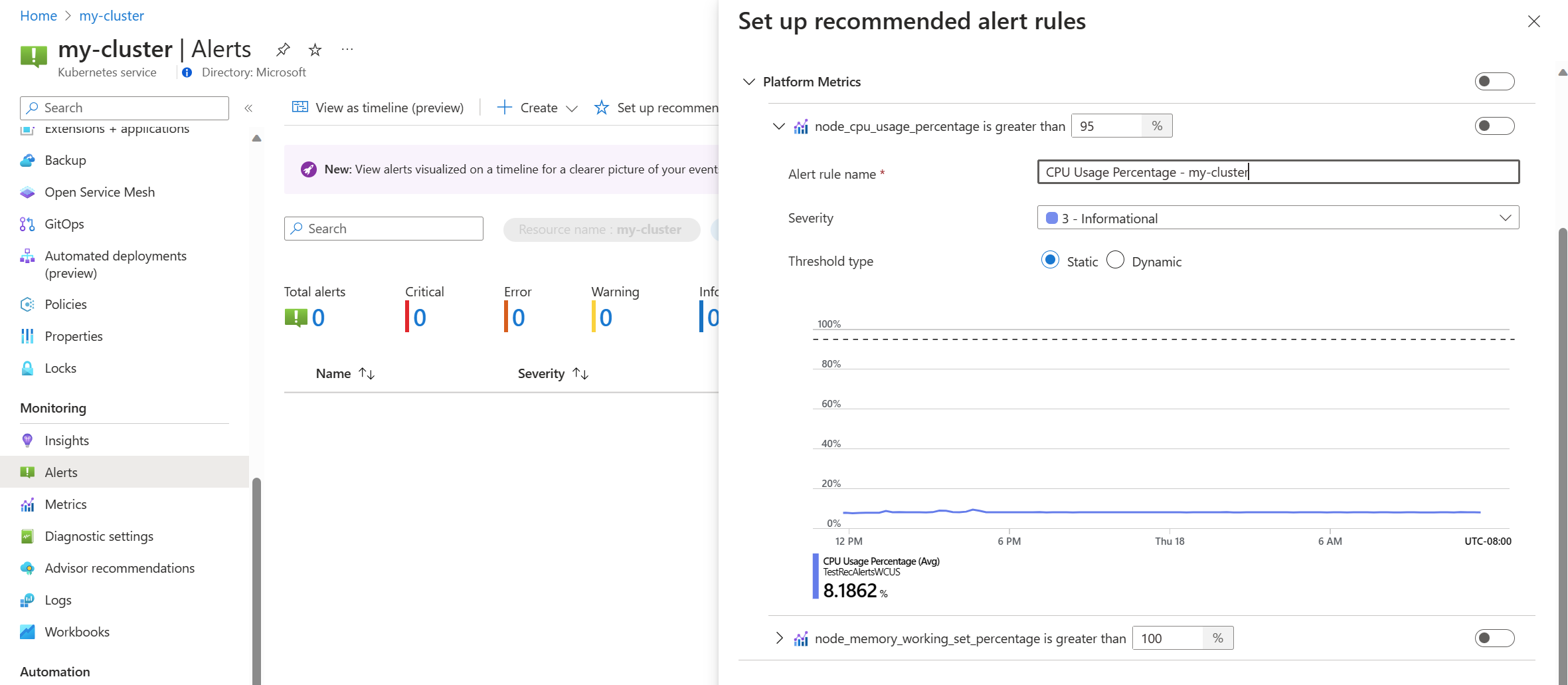
Přepnutím pravidla metriky platformy toto pravidlo povolíte. Pravidlo můžete rozšířit a upravit jeho podrobnosti, jako je název, závažnost a prahová hodnota.
Vyberte jednu nebo více metod oznámení, abyste vytvořili novou skupinu akcí, nebo vyberte existující skupinu akcí s podrobnostmi oznámení pro tuto sadu pravidel upozornění.
Kliknutím na Uložit uložte skupinu pravidel.



Úprava doporučených pravidel upozornění
Po vytvoření skupiny pravidel nemůžete k úpravám pravidel použít stejnou stránku na portálu. U metrik Prometheus musíte upravit skupinu pravidel a upravit v ní všechna pravidla, včetně povolení všech pravidel, která ještě nejsou povolená. U metrik platformy můžete upravit každé pravidlo upozornění.
V nabídce Upozornění pro váš cluster vyberte Nastavit doporučení. Všechna pravidla nebo skupiny pravidel, které už byly vytvořeny, budou označeny jako již vytvořené.
Rozbalte pravidlo nebo skupinu pravidel. Klikněte na Zobrazit skupinu pravidel pro Prometheus a Zobrazit pravidlo upozornění pro metriky platformy.

Pro skupiny pravidel Prometheus:
výběrem možnosti Pravidla zobrazíte pravidla upozornění ve skupině.
Klikněte na ikonu Upravit vedle pravidla, které chcete upravit. K úpravě pravidla použijte doprovodné materiály v části Vytvoření pravidla upozornění.

Po dokončení úprav pravidel ve skupině klikněte na Uložit a uložte skupinu pravidel.
Pro metriky platformy:
Kliknutím na tlačítko Upravit otevřete podrobnosti pravidla upozornění. K úpravě pravidla použijte doprovodné materiály v části Vytvoření pravidla upozornění.



Zakázání skupiny pravidel upozornění
Zakažte skupinu pravidel, aby přestala přijímat výstrahy z pravidel v ní.
Podívejte se na skupinu pravidel upozornění pro Prometheus nebo pravidlo upozornění na metriku platformy, jak je popsáno v tématu Úpravy doporučených pravidel upozornění.
V nabídce Přehled vyberte Zakázat.

Doporučené podrobnosti o pravidle upozornění
Následující tabulky uvádějí podrobnosti o jednotlivých doporučených pravidlech upozornění. Zdrojový kód pro každý z nich je k dispozici na GitHubu spolu s průvodci odstraňováním potíží od komunity Prometheus.
Pravidla upozornění komunity Prometheus
Upozornění na úrovni clusteru
| Název upozornění | Popis | Výchozí prahová hodnota | Časový rámec (minuty) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Kvóta prostředků procesoru přidělená oborům názvů překračuje dostupné prostředky procesoru v uzlech clusteru o více než 50 % za posledních 5 minut. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Kvóta prostředků paměti přidělená oborům názvů překračuje dostupné paměťové prostředky v uzlech clusteru o více než 50 % za posledních 5 minut. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Jeden nebo více kontejnerů v rámci podů bylo zabito kvůli událostem mimo paměť (OOM) za posledních 5 minut. | >0 | 5 |
| KubeClientErrors | Míra chyb klienta (stavové kódy HTTP začínající 5xx) v požadavcích rozhraní API Kubernetes překračuje 1 % celkové frekvence požadavků rozhraní API za posledních 15 minut. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Trvalý objem se zaplňuje a očekává se, že vyhodnocuje dostupný prostor vyhodnocovaný podle dostupného poměru místa, využitého prostoru a předpověděného lineárního trendu dostupného prostoru za posledních 6 hodin. Tyto podmínky se vyhodnocují za posledních 60 minut. | – | 60 |
| KubePersistentVolumeInodesFillingUp | Během posledních 15 minut je k dispozici méně než 3 % uzlů inode v rámci trvalého svazku. | <0.03 | 15 |
| KubePersistentVolumeErrors | Jeden nebo více trvalých svazků je ve fázi selhání nebo čekání na vyřízení za posledních 5 minut. | >0 | 5 |
| KubeContainerWaiting | Nejméně jeden kontejner v rámci podů Kubernetes je ve stavu čekání za posledních 60 minut. | >0 | 60 |
| KubeDaemonSetNotScheduled | Nejméně jeden pod není naplánovaný na žádném uzlu za posledních 15 minut. | >0 | 15 |
| KubeDaemonSetMisScheduled | Nejméně jeden pod se během posledních 15 minut zmeškal v clusteru. | >0 | 15 |
| KubeQuotaAlmostFull | Využití kvót prostředků Kubernetes je mezi 90 % a 100 % pevných limitů za posledních 15 minut. | >0,9 <1 | 15 |
Upozornění na úrovni uzlu
| Název upozornění | Popis | Výchozí prahová hodnota | Časový rámec (minuty) |
|---|---|---|---|
| KubeNodeUnreachable | Uzel je za posledních 15 minut nedostupný. | 0 | 15 |
| KubeNodeReadinessFlapping | Stav připravenosti uzlu se během posledních 15 minut změnil více než 2krát. | 2 | 15 |
Upozornění na úrovni podů
| Název upozornění | Popis | Výchozí prahová hodnota | Časový rámec (minuty) |
|---|---|---|---|
| KubePVUsageHigh | Průměrné využití trvalých svazků na podech překračuje 80 % za posledních 15 minut. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Existuje neshoda mezi požadovaným počtem replik a počtem dostupných replik za posledních 10 minut. | – | 10 |
| KubeStatefulSetReplicasMismatch | Počet připravených replik v StatefulSet neodpovídá celkovému počtu replik v sadě StatefulSet za posledních 15 minut. | – | 15 |
| KubeHpaReplicasMismatch | Horizontální automatické škálování podů v clusteru neodpovídá požadovanému počtu replik za posledních 15 minut. | – | 15 |
| KubeHpaMaxedOut | Horizontální automatické škálování podů (HPA) v clusteru běží na maximálních replikách za posledních 15 minut. | – | 15 |
| KubePodCrashLooping | Jeden nebo více podů je v pod podmínky CrashLoopBackOff, kde se pod po spuštění neustále chybově ukončí a po posledních 15 minutách se úspěšně obnoví. | >=1 | 15 |
| KubeJobStale | Nejméně jedna instance úlohy se po dobu posledních 6 hodin úspěšně nedokončila. | >0 | 360 |
| KubePodContainerRestart | Nejméně jeden kontejner v rámci podů v clusteru Kubernetes se během poslední hodiny restartoval alespoň jednou. | >0 | 15 |
| KubePodReadyStateLow | Procento podů v připraveném stavu klesne podů za posledních 5 minut podů podů do 80 % pro jakékoli nasazení nebo démona v clusteru Kubernetes. | <0.8 | 5 |
| KubePodFailedState | Nejméně jeden pod je ve stavu selhání za posledních 5 minut. | >0 | 5 |
| KubePodNotReadyByController | Nejméně jeden pod není ve stavu připraveno (tj. ve fázi Čeká na vyřízení nebo Neznámý) za posledních 15 minut. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | Pozorované generování StatefulSet Kubernetes neodpovídá jeho generování metadat za posledních 15 minut. | – | 15 |
| KubeJobFailed | Během posledních 15 minut došlo k selhání jedné nebo několika úloh Kubernetes. | >0 | 15 |
| KubeContainerAverageCPUHigh | Průměrné využití procesoru na kontejner za posledních 5 minut překračuje 95 %. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | Průměrné využití paměti na kontejner překračuje 95 % za posledních 5 minut. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | 99. percentil latence spuštění podu překračuje 60 sekund za posledních 10 minut. | >60 | 10 |
Pravidla upozornění metriky platformy
| Název upozornění | Popis | Výchozí prahová hodnota | Časový rámec (minuty) |
|---|---|---|---|
| Procento procesoru uzlu je větší než 95 % | Procento procesoru uzlu je za posledních 5 minut větší než 95 %. | 95 | 5 |
| Procento pracovní sady paměti uzlu je větší než 100 % | Procento pracovní sady paměti uzlu je za posledních 5 minut větší než 100 %. | 100 | 5 |
Upozornění na metriky Starší verze Container Insights (Preview)
Pravidla metrik v Container Insights budou vyřazena 31. května 2024 (to bylo dříve oznámeno 14. března 2026). Tato pravidla nebyla k dispozici k vytvoření pomocí portálu od 15. srpna 2023. Tato pravidla byla ve verzi Public Preview, ale budou vyřazena bez dosažení obecné dostupnosti, protože jsou nyní k dispozici nová doporučená upozornění na metriky popsaná v tomto článku.
Pokud jste už tato starší pravidla upozornění povolili, měli byste je zakázat a povolit nové prostředí.
Zakázání pravidel upozornění na metriky
- V nabídce Přehledy pro váš cluster vyberte Doporučené výstrahy (Preview).
- Změňte stav pro každé pravidlo upozornění na Zakázáno.
Starší mapování upozornění
Následující tabulka mapuje každou ze starších upozornění metrik Container Insights na ekvivalentní doporučené upozornění metriky Prometheus.
| Upozornění doporučené vlastní metriky | Ekvivalentní upozornění na doporučenou metriku Prometheus nebo platformu | Podmínka |
|---|---|---|
| Počet dokončených úloh | KubeJobStale (výstrahy na úrovni podů) | Nejméně jedna instance úlohy se po dobu posledních 6 hodin úspěšně nedokončila. |
| Procento využití procesoru kontejneru | KubeContainerAverageCPUHigh (výstrahy na úrovni podů) | Průměrné využití procesoru na kontejner za posledních 5 minut překračuje 95 %. |
| Paměť pracovní sady kontejnerů % | KubeContainerAverageMemoryHigh (výstrahy na úrovni podů) | Průměrné využití paměti na kontejner překračuje 95 % za posledních 5 minut. |
| Počet neúspěšných podů | KubePodFailedState (výstrahy na úrovni podů) | Nejméně jeden pod je ve stavu selhání za posledních 5 minut. |
| Procento procesoru uzlu | Procento procesoru uzlu je větší než 95 % (metrika platformy) | Procento procesoru uzlu je za posledních 5 minut větší než 95 %. |
| Využití disku uzlu % | – | Průměrné využití disku pro uzel je větší než 80 %. |
| Stav uzlu NotReady | KubeNodeUnreachable (upozornění na úrovni uzlu) | Uzel je za posledních 15 minut nedostupný. |
| Pracovní sada uzlů – % paměti | Procento pracovní sady paměti uzlu je větší než 100 % | Procento pracovní sady paměti uzlu je za posledních 5 minut větší než 100 %. |
| Kontejnery OOM vysílané službou OOM | KubeContainerOOMKilledCount (upozornění na úrovni clusteru) | Jeden nebo více kontejnerů v rámci podů bylo zabito kvůli událostem mimo paměť (OOM) za posledních 5 minut. |
| Procento využití trvalého svazku | KubePVUsageHigh (upozornění na úrovni podů) | Průměrné využití trvalých svazků na podech překračuje 80 % za posledních 15 minut. |
| Procento připravených podů | KubePodReadyStateLow (výstrahy na úrovni podů) | Procento podů v připraveném stavu klesne podů za posledních 5 minut podů podů do 80 % pro jakékoli nasazení nebo démona v clusteru Kubernetes. |
| Počet restartujících se kontejnerů | KubePodContainerRestart (upozornění na úrovni podů) | Nejméně jeden kontejner v rámci podů v clusteru Kubernetes se během poslední hodiny restartoval alespoň jednou. |
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro