Automatizované zálohy pro databáze Hyperscale
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Tento článek vysvětluje funkci automatizovaného zálohování s databázemi Hyperscale ve službě Azure SQL Database.
Databáze Hyperscale používají jedinečnou architekturu s vysoce škálovatelnými úrovněmi výkonu úložiště a výpočetních prostředků. Zálohy hyperškálování jsou založené na snímcích a jsou téměř okamžité. Zálohy protokolů se ukládají v dlouhodobém úložišti Azure po dobu uchovávání záloh.
Architektura Hyperscale nevyžaduje úplné, rozdílové zálohování ani zálohování protokolů. Frekvence zálohování, náklady na úložiště, plánování, redundance úložiště a možnosti obnovení se liší od jiných databází ve službě Azure SQL Database.
Výkon zálohování a obnovení
Oddělení úložiště a výpočetních prostředků umožňuje Hyperscale odesílat operace zálohování a obnovení do vrstvy úložiště, aby se eliminovala spotřeba prostředků na výpočetních replikách. Zálohování databází nemá vliv na výkon primárních nebo sekundárních výpočetních replik.
Operace zálohování a obnovení databází Hyperscale jsou rychlé bez ohledu na velikost dat, protože používají snímky úložiště. Zálohování je prakticky okamžité.
Databázi můžete obnovit k libovolnému bodu v čase v rámci doby uchovávání záloh pomocí:
- Vrátí se k příslušným snímkům souborů.
- Použití transakčních protokolů k zajištění transakční konzistentně obnovené databáze.
Obnovení proto není operace velikosti dat, která zůstává stejná. Obnovení databáze Hyperscale ve stejné oblasti Azure se dokončí v minutách místo hodin nebo dnů, a to i u databází s více terabajty.
Změna redundance úložiště při vydávání obnovení může způsobit delší dobu obnovení, protože obnovení je velikost dat, a proto je čas úměrný velikosti databáze.
Vytváření nových databází obnovením existující zálohy nebo kopírováním databáze využívá také oddělení výpočetních prostředků a úložiště v Hyperscale. Kopie můžete vytvářet pro účely vývoje nebo testování, a to i u více terabajtových databází v minutách ve stejné oblasti, když použijete stejný typ úložiště.
Uchování záloh
Výchozí krátkodobé uchovávání záloh pro databáze Hyperscale je 7 dnů.
Krátkodobé uchovávání záloh v rozsahu 1 až 35 dnů a dlouhodobé uchovávání záloh (LTR) pro databáze Hyperscale je obecně dostupné od září 2023. Další informace najdete v tématu Dlouhodobé uchovávání – Azure SQL Database a Azure SQL Managed Instance.
Plánování zálohování
V případě databází úrovně Hyperscale se neprovádí tradiční úplné ani rozdílové zálohování ani zálohování transakčních protokolů. Místo toho se vytvářejí běžné snímky úložiště datových souborů.
Vygenerované transakční protokoly se zachovají stejně jako pro nakonfigurovanou dobu uchovávání informací. V době obnovení se na obnovený snímek úložiště použijí relevantní záznamy transakčního protokolu. Výsledkem je transakční konzistentní databáze bez ztráty dat v zadaném bodu v čase v rámci doby uchovávání.
Monitorování spotřeby úložiště zálohování
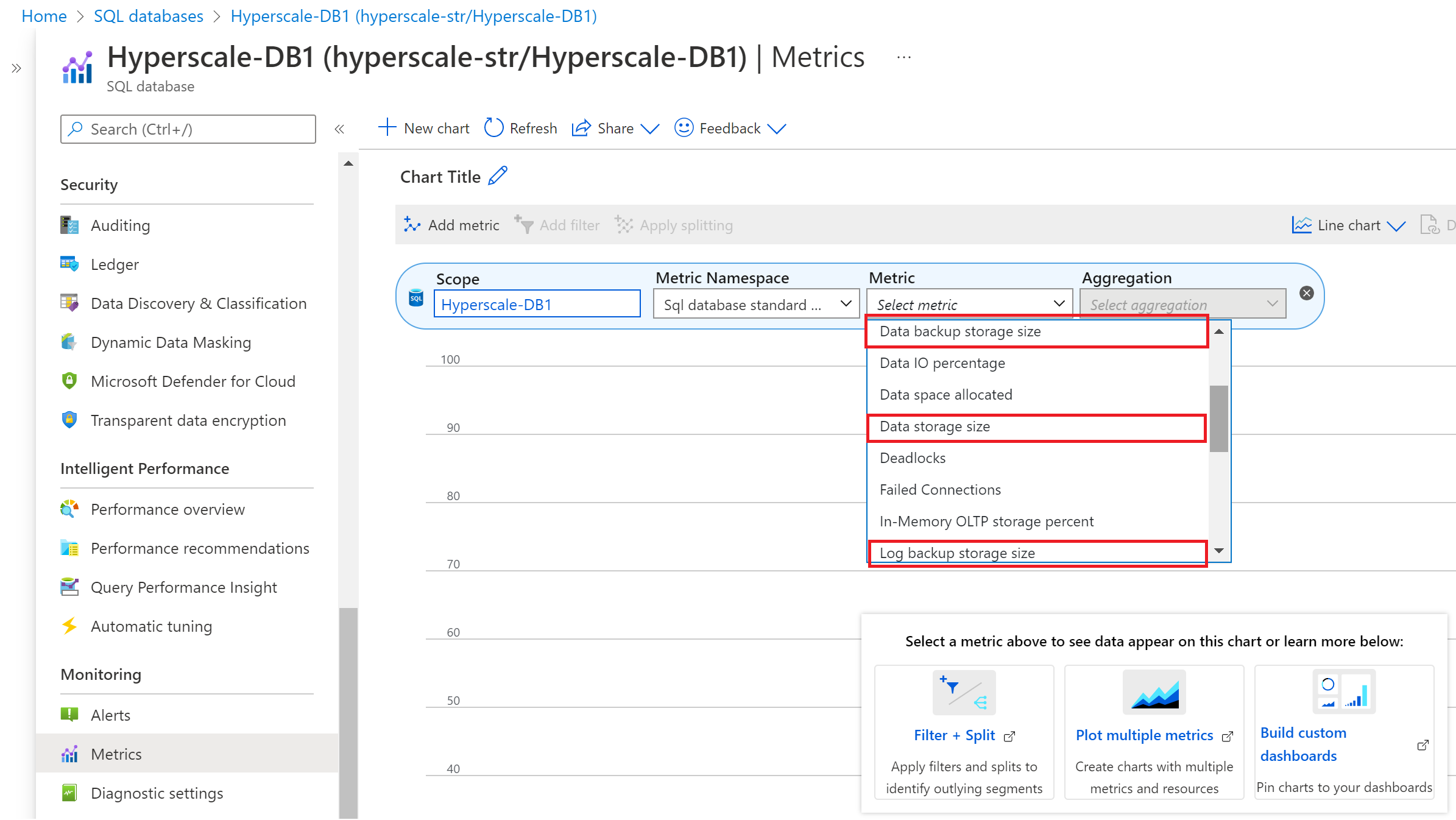
V Hyperscale hlásí metriky Služby Azure Monitor následující informace o spotřebě:
- Velikost úložiště zálohování dat (velikost zálohování snímků)
- Velikost úložiště dat (přidělená velikost databáze)
- Velikost úložiště zálohování protokolů (velikost zálohování transakčních protokolů)
Pokud chcete zobrazit metriky zálohování a úložiště dat na webu Azure Portal, postupujte takto:
- Přejděte do databáze Hyperscale, pro kterou chcete monitorovat metriky zálohování a úložiště dat.
- V části Monitorování vyberte stránku Metriky.
- V rozevíracím seznamu Metriky vyberte úložiště zálohování dat, velikost úložiště dat a metriky úložiště zálohování protokolů s odpovídajícím pravidlem agregace.
Snížení spotřeby úložiště zálohování
Spotřeba úložiště zálohování pro databázi Hyperscale závisí na době uchovávání, výběru oblasti, redundanci úložiště zálohování a typu úlohy. Zvažte některé z následujících technik ladění, které snižují spotřebu úložiště zálohování pro databázi Hyperscale:
- Snižte dobu uchovávání záloh na minimum pro vaše potřeby.
- Vyhněte se velkým operacím zápisu, jako je údržba indexů, častěji, než potřebujete. Doporučení k údržbě indexů najdete v tématu Optimalizace údržby indexů za účelem zlepšení výkonu dotazů a snížení spotřeby prostředků.
- U velkých operací načítání dat zvažte použití komprese dat, pokud je to vhodné.
tempdbMísto trvalých tabulek v logice aplikace použijte databázi k ukládání dočasných výsledků nebo přechodných dat.- Místně redundantní nebo zónově redundantní úložiště zálohování používejte, pokud není potřeba použít funkci geografického obnovení (například vývojové/testovací prostředí).
Ceny úložišť zálohování
Náklady na úložiště zálohování úrovně Hyperscale závisí na výběru oblasti a redundance úložiště zálohování. Závisí také na typu úlohy.
U úloh náročných na zápis je vyšší pravděpodobnost častých změn datových stránek, což má za následek větší snímky úložiště. Takové úlohy také generují více transakčních protokolů, které přispívají k celkovému nákladům na zálohování. Úložiště zálohování se účtuje na základě gigabajtů spotřebovaných měsíčně. Podrobnosti o cenách najdete na stránce s cenami služby Azure SQL Database.
V případě Hyperscale se fakturovatelné úložiště záloh vypočítá takto:
Total billable backup storage size = (data backup storage size + log backup storage size)
Velikost úložiště dat není součástí fakturovatelné zálohy, protože se už fakturuje jako přidělené úložiště databáze.
Odstraněné databáze Hyperscale účtují náklady na zálohování, které podporují obnovení k určitému bodu v čase před odstraněním. U odstraněné databáze Hyperscale se fakturovatelné úložiště záloh vypočítá takto:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Velikost úložiště dat je součástí vzorce, protože přidělené databázové úložiště se neúčtuje samostatně za odstraněnou databázi. U odstraněné databáze se data ukládají po odstranění, aby bylo možné obnovit během nakonfigurované doby uchovávání záloh.
Fakturovatelné úložiště záloh pro odstraněnou databázi se po odstranění postupně snižuje. Když se zálohy už nezachovají, stane se nulou a obnovení už není možné. Pokud se jedná o trvalé odstranění a už nepotřebujete zálohy, můžete optimalizovat náklady snížením uchovávání informací před odstraněním databáze.
Monitorování nákladů na zálohování
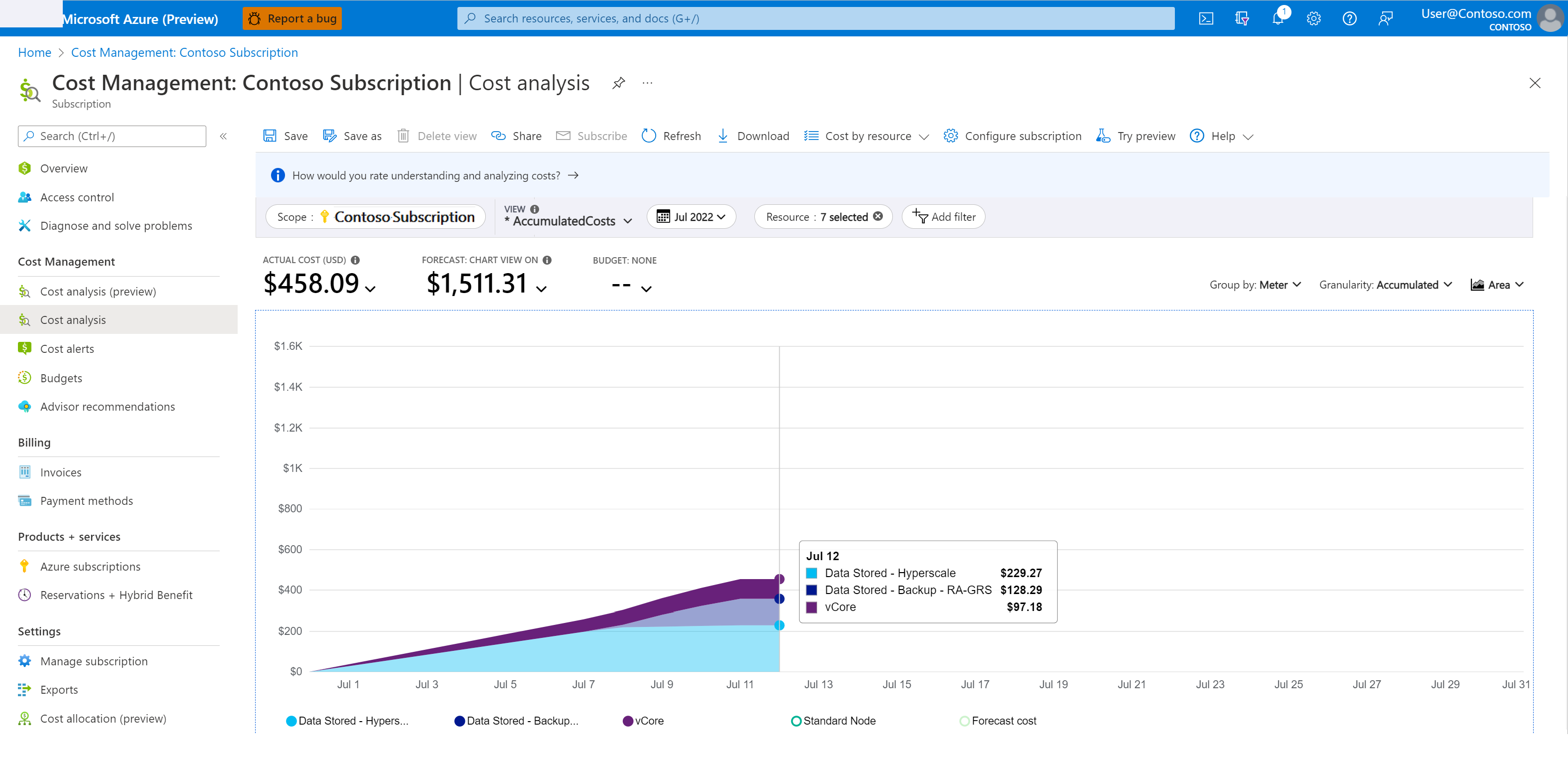
Vysvětlení nákladů na úložiště zálohování:
Na webu Azure Portal přejděte do části Cost Management + Billing.
Vyberte Analýzu nákladů služby Cost Management>.
V části Obor vyberte požadované předplatné.
Pomocí následujícího postupu vyfiltrujte časové období a službu, které vás zajímají:
- Přidejte filtr pro název služby.
- V rozevíracím seznamu zvolte sql-database .
- Přidejte další filtr pro měřič.
- Pokud chcete monitorovat náklady na zálohování pro obnovení k určitému bodu v čase, v rozevíracím seznamu vyberte Uložená data – Zálohování – RA .
Následující snímek obrazovky ukazuje ukázkovou analýzu nákladů.
Redundance úložiště dat a zálohování
Hyperscale podporuje konfigurovatelnou redundanci úložiště. Při vytváření databáze Hyperscale můžete zvolit preferovaný typ úložiště: geograficky zónově redundantní úložiště jen pro čtení (RA-GZRS), geograficky redundantní úložiště jen pro čtení (RA-GRS), zónově redundantní úložiště (ZRS) nebo místně redundantní úložiště (LRS).
- Geograficky zónově redundantní úložiště: Kopíruje zálohy synchronně napříč třemi zónami dostupnosti Azure v primární oblasti. podobně jako zónově redundantní úložiště (ZRS). Kromě toho kopíruje data asynchronně do jednoho fyzického umístění ve spárované sekundární oblasti. Momentálně je k dispozici pouze v určitých oblastech.
Další informace o tom, jak se zálohy replikují pro jiné typy úložiště, najdete v tématu Redundance úložiště zálohování.
Vzhledem k tomu, že Hyperscale používá snímky úložiště pro zálohy, data a zálohy sdílejí stejný účet úložiště. V důsledku toho je vybraná redundance úložiště zálohování použitelná pro data i zálohy.
Poznámka:
Při vytváření databáze Hyperscale pečlivě zvažte redundanci úložiště zálohování, protože ji můžete nastavit pouze při vytváření databáze. Po zřízení prostředku nemůžete toto nastavení změnit.
Aktivní geografická replikace slouží k aktualizaci nastavení redundance úložiště zálohování pro existující databázi Hyperscale s minimálními výpadky. Případně můžete použít kopírování databáze.
Upozorňující
- Geografické obnovení je zakázané, jakmile se databáze aktualizuje tak, aby používala místně redundantní nebo zónově redundantní úložiště.
- Zónově redundantní úložiště je aktuálně dostupné jenom v určitých oblastech.
- Geograficky zónově redundantní úložiště je aktuálně dostupné jenom v určitých oblastech.
Obnovení databáze Hyperscale do jiné oblasti
Možná budete muset obnovit databázi Hyperscale do oblasti, která se liší od aktuální oblasti. Mezi běžné důvody patří operace zotavení po havárii nebo přechod k podrobnostem nebo přemístění. Primární metodou je provést geografické obnovení databáze. Použijete stejný postup, který byste použili k obnovení jakékoli jiné databáze ve službě Azure SQL Database do jiné oblasti:
- Pokud v cílové oblasti ještě nemáte odpovídající server, vytvořte server v cílové oblasti. Tento server by měl vlastnit stejné předplatné jako původní (zdrojový) server.
- Postupujte podle pokynů v části geografického obnovení stránky o obnovení databáze ve službě Azure SQL Database z automatických záloh.
Poznámka:
Vzhledem k tomu, že zdroj a cíl jsou v samostatných oblastech, nemůže databáze sdílet úložiště snímků se zdrojovou databází, stejně jako v jiných geografických obnoveních. Nezeměpisná obnovení se rychle dokončí bez ohledu na velikost databáze.
Geografické obnovení databáze Hyperscale je operace velikosti dat, i když je cíl ve spárované oblasti geograficky replikovaného úložiště. Geografické obnovení proto bude trvat výrazně déle v porovnání s obnovením k určitému bodu v čase ve stejné oblasti.
Pokud je cíl ve spárované oblasti, přenos dat bude v rámci oblasti. Tento přenos bude výrazně rychlejší než přenos dat mezi oblastmi. Bude to ale i nadále operace velikosti dat.
Pokud chcete, můžete databázi zkopírovat do jiné oblasti. Tuto metodu použijte, pokud není geografické obnovení dostupné, protože není podporováno u vybraného typu redundance úložiště. Podrobnosti najdete v tématu Kopírování databáze pro Hyperscale.
Související obsah
Zálohy databází jsou důležitou součástí jakékoli strategie provozní kontinuity a zotavení po havárii, protože pomáhají chránit vaše data před náhodným poškozením nebo odstraněním.