Přehled skupin převzetí služeb při selhání a osvědčené postupy – Azure SQL Managed Instance
Platí pro: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Funkce skupin převzetí služeb při selhání umožňuje spravovat replikaci a převzetí služeb při selhání všech uživatelských databází ve spravované instanci do jiné oblasti Azure. Tento článek obsahuje přehled funkce skupiny převzetí služeb při selhání s osvědčenými postupy a doporučeními pro jeho použití se službou Azure SQL Managed Instance.
Pokud chcete tuto funkci začít používat, přečtěte si téma Konfigurace skupiny převzetí služeb při selhání pro službu Azure SQL Managed Instance.
Přehled
Funkce skupin převzetí služeb při selhání umožňuje spravovat replikaci a převzetí služeb při selhání uživatelských databází ve spravované instanci do spravované instance v jiné oblasti Azure. Skupiny převzetí služeb při selhání jsou navržené tak, aby zjednodušily nasazení a správu geograficky replikovaných databází ve velkém měřítku.
Další informace najdete v tématu Vysoká dostupnost pro spravovanou instanci Azure SQL. Informace o geografickém převzetí služeb při selhání a RTO najdete v přehledu provozní kontinuity.
Přesměrování koncového bodu
Skupiny převzetí služeb při selhání poskytují koncové body naslouchacího procesu jen pro čtení a jen pro čtení, které se během geografických převzetí služeb při selhání nezmění. Po geografickém převzetí služeb při selhání nemusíte měnit připojovací řetězec aplikace, protože připojení se automaticky směrují na aktuální primární server. Geograficky převzetí služeb při selhání přepne všechny sekundární databáze ve skupině na primární roli. Po dokončení geografického převzetí služeb při selhání se záznam DNS automaticky aktualizuje a přesměruje koncové body do nové oblasti.
Snižování zátěže úloh jen pro čtení
Pokud chcete snížit provoz do primárních databází, můžete také použít sekundární databáze ve skupině převzetí služeb při selhání k přesměrování zátěže úloh jen pro čtení. Pomocí naslouchacího procesu jen pro čtení směrujte provoz jen pro čtení do sekundární databáze, která je čitelná.
Obnovení aplikace
Pokud chcete dosáhnout plné kontinuity podnikových procesů, je přidání redundance regionální databáze pouze součástí řešení. Obnovení aplikace (služby) po závažném selhání vyžaduje obnovení všech komponent, které tvoří službu a všechny závislé služby. Mezi tyto komponenty patří klientský software (například prohlížeč s vlastním JavaScriptem), webové front-endy, úložiště a DNS. Je důležité, aby všechny komponenty byly odolné vůči stejným chybám a byly k dispozici v rámci cíle doby obnovení (RTO) vaší aplikace. Proto potřebujete identifikovat všechny závislé služby a porozumět zárukám a možnostem, které poskytují. Pak musíte provést odpovídající kroky, abyste zajistili, že vaše služba bude fungovat během převzetí služeb při selhání služeb, na kterých závisí.
Zásady převzetí služeb při selhání
Skupiny převzetí služeb při selhání podporují dvě zásady převzetí služeb při selhání:
- Spravovaná zákazníkem (doporučeno) – Zákazníci můžou provést převzetí služeb při selhání skupiny, když si všimnou neočekávaného výpadku, který má vliv na jednu nebo více databází ve skupině převzetí služeb při selhání. Pokud používáte nástroje příkazového řádku, jako je PowerShell, Azure CLI nebo rest API, hodnota zásad převzetí služeb při selhání pro spravovanou zákazníkem je
manual. - Spravováno Microsoftem – V případě rozsáhlého výpadku, který má vliv na primární oblast, zahájí Microsoft převzetí služeb při selhání všech ovlivněných skupin převzetí služeb při selhání, které mají nakonfigurované zásady převzetí služeb při selhání spravované Microsoftem. Převzetí služeb při selhání spravované Microsoftem se nespustí pro jednotlivé skupiny převzetí služeb při selhání ani pro podmnožinu skupin převzetí služeb při selhání v oblasti. Pokud používáte nástroje příkazového řádku, jako je PowerShell, Azure CLI nebo rozhraní REST API, hodnota zásad převzetí služeb při selhání pro spravované Microsoftem je
automatic.
Každá zásada převzetí služeb při selhání má jedinečnou sadu případů použití a odpovídající očekávání týkající se rozsahu převzetí služeb při selhání a ztráty dat, jak shrnuje následující tabulka:
| Zásady převzetí služeb při selhání | Rozsah převzetí služeb při selhání | Případ použití | Potenciální ztráta dat |
|---|---|---|---|
| Spravovaná zákazníkem (Doporučeno) |
Skupiny převzetí služeb při selhání | Na jednu nebo více databází ve skupinách převzetí služeb při selhání má vliv výpadek a stát se nedostupným. Můžete zvolit převzetí služeb při selhání. | Ano |
| Spravováno společností Microsoft | Všechny skupiny převzetí služeb při selhání v oblasti | Rozsáhlý výpadek v datacentru, zóně dostupnosti nebo oblasti způsobuje nedostupnost databází a tým služby Microsoft Azure SQL se rozhodne aktivovat vynucené převzetí služeb při selhání. Tuto možnost použijte pouze v případě, že chcete delegovat odpovědnost za zotavení po havárii do Microsoftu a aplikace je tolerantní k rto (výpadku) nejméně jedné hodiny nebo více. |
Ano |
Spravovaná zákazníkem
Ve výjimečných případech nemusí integrovaná dostupnost nebo vysoká dostupnost stačit ke zmírnění výpadku a databáze ve skupině převzetí služeb při selhání můžou být nedostupné po dobu, která není přijatelná pro smlouvu o úrovni služeb (SLA) aplikací využívajících databáze. Databáze můžou být nedostupné kvůli lokalizovaným problémům, které mají vliv jenom na několik databází, nebo můžou být na úrovni datacentra, zóny dostupnosti nebo oblasti. V každém z těchto případů můžete k obnovení provozní kontinuity zahájit vynucené převzetí služeb při selhání.
Nastavení zásad převzetí služeb při selhání na spravovanou zákazníkem se důrazně doporučuje, protože vám zajistí kontrolu nad tím, kdy se má zahájit převzetí služeb při selhání a obnovit provozní kontinuitu. Převzetí služeb při selhání můžete zahájit, když zjistíte neočekávaný výpadek, který má vliv na jednu nebo více databází ve skupině převzetí služeb při selhání.
Spravováno společností Microsoft
Díky zásadám převzetí služeb při selhání spravovaným Microsoftem se odpovědnost za zotavení po havárii deleguje do služby Azure SQL. Aby služba Azure SQL iniciovala vynucené převzetí služeb při selhání, musí být splněny následující podmínky:
- Na datacentra, zónu dostupnosti nebo výpadek na úrovni oblasti způsobené přírodní událostí havárie, změnami konfigurace, chybami softwaru nebo selháním hardwarových komponent a mnoha databází v dané oblasti dojde k ovlivnění.
- Období odkladu vypršelo. Vzhledem k tomu, že ověření rozsahu a zmírnění rizik závisí na lidských akcích, nedá se období odkladu nastavit pod jednu hodinu.
Po splnění těchto podmínek služba Azure SQL zahájí vynucené převzetí služeb při selhání pro všechny skupiny převzetí služeb při selhání v oblasti, ve které jsou nastavené zásady převzetí služeb při selhání spravované Microsoftem.
Důležité
K otestování a implementaci plánu zotavení po havárii použijte zásady převzetí služeb při selhání spravované zákazníkem. Nespoléhejte se na převzetí služeb při selhání spravované microsoftem, které může microsoft provádět pouze za extrémních okolností. U všech skupin převzetí služeb při selhání v oblasti, ve které jsou nastavené zásady převzetí služeb při selhání spravované Microsoftem, se zahájí převzetí služeb při selhání. Nejde ho zahájit pro jednotlivé skupiny převzetí služeb při selhání. Pokud potřebujete možnost selektivního převzetí služeb při selhání skupiny převzetí služeb při selhání, použijte zásady převzetí služeb při selhání spravované zákazníkem.
Zásady převzetí služeb při selhání nastavte na spravované Microsoftem jenom v těchto případech:
- Chcete delegovat odpovědnost za zotavení po havárii do služby Azure SQL.
- Aplikace je tolerantní vůči nedostupnosti vaší databáze nejméně po dobu jedné hodiny nebo více.
- Je přijatelné aktivovat vynucené převzetí služeb při selhání po uplynutí období odkladu, protože skutečný čas vynuceného převzetí služeb při selhání se může výrazně lišit.
- Je přijatelné, aby všechny databáze ve skupině převzetí služeb při selhání převzaly služby při selhání bez ohledu na konfiguraci redundance zóny nebo stavu dostupnosti. Přestože databáze nakonfigurované pro redundanci zón jsou odolné vůči zónovým selháním a nemusí to mít vliv na výpadek, budou se i nadále převzít služby při selhání, pokud jsou součástí skupiny převzetí služeb při selhání se zásadami převzetí služeb při selhání spravované Microsoftem.
- Je přijatelné mít vynucené převzetí služeb při selhání databází ve skupině převzetí služeb při selhání bez zohlednění závislosti aplikace na jiných službách nebo komponentách Azure používaných aplikací, což může způsobit snížení výkonu nebo nedostupnost aplikace.
- Je přijatelné, aby došlo k neznámé ztrátě dat, protože přesný čas vynuceného převzetí služeb při selhání nelze řídit a ignoruje stav synchronizace sekundárních databází.
- Všechny primární a sekundární databáze ve skupině převzetí služeb při selhání a všechny relace geografické replikace mají stejnou úroveň služby, výpočetní úroveň (zřízenou nebo bezserverovou) a velikost výpočetních prostředků (DTU nebo virtuální jádra). Pokud cíl na úrovni služby (SLO) všech databází neodpovídá, zásady převzetí služeb při selhání se nakonec aktualizují ze služby Microsoft Managed na zákazníky spravované službou Azure SQL.
Když Microsoft aktivuje převzetí služeb při selhání, přidá se do protokolu aktivit služby Azure Monitor položka pro název operace Převzetí služeb při selhání skupiny převzetí služeb při selhání Azure SQL. Položka obsahuje název skupiny převzetí služeb při selhání v části Prostředek a událost iniciovaná jedním spojovníkem (-), který označuje, že převzetí služeb při selhání inicioval Microsoft. Tyto informace najdete také na stránce protokolu aktivit nového primárního serveru nebo instance na webu Azure Portal.
Terminologie a možnosti
Skupina převzetí služeb při selhání (MLHA)
Skupina převzetí služeb při selhání umožňuje, aby všechny uživatelské databáze ve spravované instanci převzaly služby při selhání jako jednotka do jiné oblasti Azure pro případ, že primární spravovaná instance přestane být dostupná kvůli výpadku primární oblasti. Vzhledem k tomu, že skupiny převzetí služeb při selhání pro službu SQL Managed Instance obsahují všechny uživatelské databáze v instanci, je možné pro instanci nakonfigurovat pouze jednu skupinu převzetí služeb při selhání.
Důležité
Název skupiny převzetí služeb při selhání musí být globálně jedinečný v rámci domény
.database.windows.net.Primární
Spravovaná instance, která je hostitelem primárních databází ve skupině převzetí služeb při selhání.
Sekundární
Spravovaná instance, která je hostitelem sekundárních databází ve skupině převzetí služeb při selhání. Sekundární oblast nemůže být ve stejné oblasti Azure jako primární.
Důležité
Pokud databáze obsahuje objekty OLTP v paměti, primární a sekundární instance geografické repliky musí mít odpovídající úrovně služby, protože objekty OLTP v paměti se nacházejí v paměti. Nižší úroveň služby v instanci geografické repliky může vést k problémům s nedostatkem paměti. Pokud k tomu dojde, sekundární replika může selhat obnovit databázi, což způsobí nedostupnost sekundární databáze spolu s objekty OLTP v paměti v sekundární geografické oblasti. To může zase způsobit neúspěšné převzetí služeb při selhání. Abyste tomu předešli, ujistěte se, že úroveň služby sekundární instance odpovídá úrovni služby primární databáze. Upgrady na úrovni služby můžou být operace s velikostí dat a jejich dokončení může chvíli trvat.
Převzetí služeb při selhání (bez ztráty dat)
Převzetí služeb při selhání provádí úplnou synchronizaci dat mezi primární a sekundární databází předtím, než sekundární přepne na primární roli. Tím se zaručuje žádná ztráta dat. Převzetí služeb při selhání je možné pouze v případech, kdy je primární přístupný. Převzetí služeb při selhání se používá v následujících scénářích:
- Provedení postupu zotavení po havárii (DR) v produkčním prostředí v případě, že ztráta dat není přijatelná
- Přemístění úlohy do jiné oblasti
- Po zmírnění výpadku vraťte úlohu do primární oblasti (navrácení služeb po obnovení).
Vynucené převzetí služeb při selhání (potenciální ztráta dat)
Vynucené převzetí služeb při selhání okamžitě přepne sekundární roli na primární roli, aniž by čekalo na nedávné změny, které se rozšíří z primární role. Výsledkem této operace může být potenciální ztráta dat. Vynucené převzetí služeb při selhání se používá jako metoda obnovení během výpadků, když primární server není přístupný. Po zmírnění výpadku se starý primární server automaticky znovu připojí a stane se novou sekundární. Převzetí služeb při selhání je možné provést, aby se navrácení služeb po obnovení vrátily repliky do původních primárních a sekundárních rolí.
Období odkladu se ztrátou dat
Vzhledem k tomu, že se data replikují do sekundární pomocí asynchronní replikace, může vynucené převzetí služeb při selhání skupin se zásadami převzetí služeb při selhání spravované Microsoftem způsobit ztrátu dat. Zásady převzetí služeb při selhání můžete přizpůsobit tak, aby odrážely odolnost vaší aplikace vůči ztrátě dat. Konfigurací
GracePeriodWithDataLossHoursmůžete řídit, jak dlouho služba Azure SQL čeká před zahájením vynuceného převzetí služeb při selhání, což může vést ke ztrátě dat.
Zóna DNS
Jedinečné ID, které se automaticky vygeneruje při vytvoření nové spravované instance SQL. Pro tuto instanci je zřízený certifikát SAN (Multi-Domain) pro ověření připojení klienta k jakékoli instanci ve stejné zóně DNS. Dvě spravované instance ve stejné skupině převzetí služeb při selhání musí sdílet zónu DNS.
Naslouchací proces pro čtení i zápis pro skupinu převzetí služeb při selhání
Záznam CNAME DNS, který odkazuje na aktuální primární záznam. Vytvoří se automaticky při vytvoření skupiny převzetí služeb při selhání a umožní úlohu čtení i zápisu transparentně znovu připojit k primárnímu serveru, když se primární změny po převzetí služeb při selhání změní. Při vytvoření skupiny převzetí služeb při selhání ve spravované instanci SQL se záznam DNS CNAME adresy URL naslouchacího procesu vytvoří jako
<fog-name>.<zone_id>.database.windows.net.Naslouchací proces jen pro čtení pro skupinu převzetí služeb při selhání
Záznam CNAME DNS, který odkazuje na aktuální sekundární. Vytvoří se automaticky při vytvoření skupiny převzetí služeb při selhání a umožní, aby se úloha SQL jen pro čtení transparentně připojila k sekundárnímu serveru, když se sekundární změny po převzetí služeb při selhání změní. Při vytvoření skupiny převzetí služeb při selhání ve spravované instanci SQL se záznam DNS CNAME adresy URL naslouchacího procesu vytvoří jako
<fog-name>.secondary.<zone_id>.database.windows.net. Ve výchozím nastavení je převzetí služeb při selhání naslouchacího procesu jen pro čtení zakázané, protože zajišťuje, že výkon primárního serveru nebude ovlivněn, když je sekundární server offline. To ale také znamená, že se relace jen pro čtení nebudou moct připojit, dokud se sekundární neobnoví. Pokud nemůžete tolerovat výpadky relací jen pro čtení a můžete primární přenosy jen pro čtení i pro zápis pro čtení použít na úkor potenciálního snížení výkonu primárního serveru, můžete povolit převzetí služeb při selhání pro naslouchacíAllowReadOnlyFailoverToPrimaryproces jen pro čtení konfigurací vlastnosti. V takovém případě se provoz jen pro čtení automaticky přesměruje na primární, pokud sekundární není k dispozici.Poznámka:
Tato
AllowReadOnlyFailoverToPrimaryvlastnost se projeví jenom v případě, že je povolená zásada převzetí služeb při selhání spravovaná Microsoftem a aktivovala se vynucené převzetí služeb při selhání. V takovém případě, pokud je vlastnost nastavena na True, bude nová primární obsluhovat relace jen pro čtení a zápis i jen pro čtení.
Architektura skupiny převzetí služeb při selhání
Skupina převzetí služeb při selhání musí být nakonfigurovaná v primární instanci a připojí ji k sekundární instanci v jiné oblasti Azure. Všechny uživatelské databáze v instanci budou replikovány do sekundární instance. Systémové databáze jako master a msdb nebudou replikovány.
Následující diagram znázorňuje typickou konfiguraci geograficky redundantní cloudové aplikace využívající spravovanou instanci a skupinu převzetí služeb při selhání:
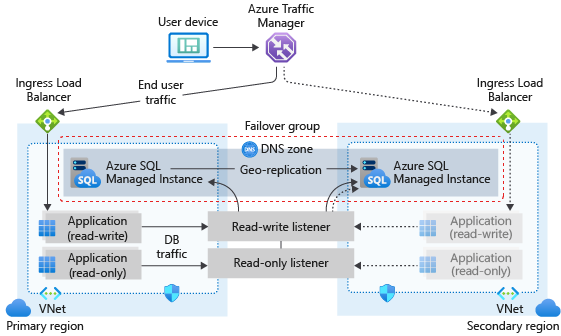
Pokud vaše aplikace jako datovou vrstvu používá službu SQL Managed Instance, postupujte podle obecných pokynů a osvědčených postupů popsaných v tomto článku při navrhování provozní kontinuity.
Vytvoření instance geograficky sekundární
Aby se zajistilo neinterrupované připojení k primární spravované instanci SQL po převzetí služeb při selhání, musí být primární i sekundární instance ve stejné zóně DNS. Zaručuje, že stejný certifikát SAN (Multi-Domain) lze použít k ověření klientských připojení k některé ze dvou instancí ve skupině převzetí služeb při selhání. Jakmile je vaše aplikace připravená pro produkční nasazení, vytvořte sekundární spravovanou instanci SQL v jiné oblasti a ujistěte se, že sdílí zónu DNS s primární spravovanou instancí SQL. Můžete to udělat zadáním volitelného parametru během vytváření. Pokud používáte PowerShell nebo rozhraní REST API, název volitelného parametru je DNSZonePartner. Název odpovídajícího volitelného pole na webu Azure Portal je Primární spravovaná instance.
Důležité
První spravovaná instance vytvořená v podsíti určuje zónu DNS pro všechny následné instance ve stejné podsíti. To znamená, že dvě instance ze stejné podsítě nemůžou patřit do různých zón DNS.
Další informace o vytvoření sekundární spravované instance SQL ve stejné zóně DNS jako primární instance najdete v tématu Konfigurace skupiny převzetí služeb při selhání pro spravovanou instanci Azure SQL.
Použití spárovaných oblastí
Z výkonnostních důvodů nasaďte obě spravované instance do spárovaných oblastí. Skupiny převzetí služeb při selhání SQL Managed Instance ve spárovaných oblastech mají v porovnání s nespárovanými oblastmi lepší výkon.
Azure SQL Managed Instance se řídí osvědčeným postupem nasazení, kdy se ve stejnou dobu obvykle nenasazují spárované oblasti Azure. Není však možné předpovědět, která oblast se nejprve upgraduje, takže pořadí nasazení není zaručené. Někdy se primární instance upgraduje jako první a někdy se sekundární instance upgraduje jako první.
V situacích, kdy je spravovaná instance Azure SQL součástí skupiny převzetí služeb při selhání a instance ve skupině nejsou ve spárovaných oblastech Azure, vyberte pro primární a sekundární databázi různé plány časových období údržby. Vyberte například časové období údržby v týdnu pro vaši geografickou sekundární databázi a časové období víkendové údržby pro vaši geografickou primární databázi.
Povolení a optimalizace toku provozu geografické replikace mezi instancemi
Připojení mezi podsítěmi virtuální sítě, které hostují primární a sekundární instanci, musí být vytvořeno a udržováno kvůli nepřerušovanému toku provozu geografické replikace. Existuje několik způsobů, jak zajistit připojení mezi instancemi, mezi kterými si můžete vybrat na základě topologie sítě a zásad:
Globální partnerský vztah virtuálních sítí (VNet Peering) je doporučený způsob, jak vytvořit připojení mezi dvěma instancemi ve skupině převzetí služeb při selhání. Pomocí páteřní infrastruktury Microsoftu poskytuje privátní připojení mezi partnerskými virtuálními sítěmi s nízkou latencí a velkou šířkou pásma. V komunikaci mezi partnerskými virtuálními sítěmi se nevyžaduje žádný veřejný internet, brány ani další šifrování.
Počáteční počáteční seeding
Při vytváření skupiny převzetí služeb při selhání mezi spravovanými instancemi existuje počáteční počáteční fáze před zahájením replikace dat. Počáteční fáze počátečního seedingu je nejdelší a nejdražší součástí operace. Po dokončení počátečního seedingu se data synchronizují a replikují se pouze následné změny dat. Doba potřebnou k dokončení počátečního počátečního počátečního seedingu závisí na velikosti dat, počtu replikovaných databází, intenzitě úloh na primárních databázích a rychlosti propojení mezi virtuálními sítěmi hostujícími primární a sekundární instanci, která většinou závisí na způsobu navázání připojení. Za normálních okolností a při navázání připojení s využitím doporučeného globálního partnerského vztahu virtuálních sítí je rychlost počátečního nastavení až 360 GB za hodinu pro službu SQL Managed Instance. Seeding se provádí pro dávku uživatelských databází paralelně – ne nutně pro všechny databáze najednou. Pokud je v instanci hostováno mnoho databází, může být potřeba více dávek.
Pokud je rychlost propojení mezi těmito dvěma instancemi pomalejší než to, co je potřeba, je pravděpodobné, že doba potřebná k osázení bude výrazně ovlivněna. Můžete použít uvedenou počáteční počáteční rychlost, počet databází, celkovou velikost dat a rychlost propojení a odhadnout, jak dlouho bude počáteční fáze trvat před zahájením replikace dat. Například v případě jedné databáze o velikosti 100 GB by počáteční počáteční fáze trvala přibližně 1,2 hodiny, pokud by propojení dokázalo nasdílit 84 GB za hodinu a pokud nejsou k dispozici žádné další počáteční databáze. Pokud propojení může přenášet pouze 10 GB za hodinu, může počáteční rozdělení databáze o velikosti 100 GB trvat přibližně 10 hodin. Pokud existuje více databází k replikaci, počáteční fáze se spustí paralelně a v kombinaci s pomalou rychlostí propojení může počáteční fáze trvat výrazně déle, zejména pokud paralelní počáteční dělení dat ze všech databází překročí dostupnou šířku pásma propojení.
Důležité
V případě extrémně nízké rychlosti nebo zaneprázdněného propojení, které způsobí, že počáteční počáteční fáze počátečního intervalu trvá, než vyprší časový limit vytvoření skupiny převzetí služeb při selhání. Proces vytvoření se automaticky zruší po 6 dnech.
Správa geografického převzetí služeb při selhání do geograficky sekundární instance
Skupina převzetí služeb při selhání spravuje geografické převzetí služeb při selhání všech databází v primární spravované instanci. Při vytvoření skupiny se každá databáze v instanci automaticky geograficky replikuje do sekundární instance. Skupiny převzetí služeb při selhání nemůžete použít k zahájení částečného převzetí služeb při selhání podmnožina databází.
Důležité
Pokud dojde k vyřazení databáze v primární spravované instanci, automaticky se zahodí také na geograficky sekundární spravovanou instanci.
Použití naslouchacího procesu pro čtení i zápis (primární MI)
Pro úlohy čtení a zápisu použijte <fog-name>.zone_id.database.windows.net jako název serveru. Připojení se automaticky směrují na primární. Tento název se po převzetí služeb při selhání nezmění. Geografické převzetí služeb při selhání zahrnuje aktualizaci záznamu DNS, takže nová připojení klientů se směrují na novou primární síť až po aktualizaci mezipaměti DNS klienta. Vzhledem k tomu, že sekundární instance sdílí zónu DNS s primárním serverem, klientská aplikace se k ní bude moct znovu připojit pomocí stejného certifikátu SÍTĚ SAN na straně serveru. Stávající klientská připojení je potřeba ukončit a pak znovu vytvořit, aby se směrovala na novou primární síť. Naslouchací proces pro čtení i zápis a naslouchací proces jen pro čtení nelze dosáhnout prostřednictvím veřejného koncového bodu pro spravovanou instanci.
Použití naslouchacího procesu jen pro čtení (sekundární MI)
Pokud máte logicky izolované úlohy jen pro čtení, které jsou odolné vůči latenci dat, můžete je spustit v sekundární geografické oblasti. Pokud se chcete připojit přímo k geografické sekundární oblasti, použijte <fog-name>.secondary.<zone_id>.database.windows.net jako název serveru.
Ve vrstvě Pro důležité obchodní informace podporuje služba SQL Managed Instance použití replik jen pro čtení k přesměrování zpracování úloh dotazů jen pro čtení pomocí ApplicationIntent=ReadOnly parametru v připojovací řetězec. Pokud jste nakonfigurovali geograficky replikovanou sekundární lokalitu, můžete se pomocí této funkce připojit k replice jen pro čtení v primárním umístění nebo v geograficky replikovaném umístění:
- Pokud se chcete připojit k replice jen pro čtení v primárním umístění, použijte
ApplicationIntent=ReadOnlya<fog-name>.<zone_id>.database.windows.net. - Pokud se chcete připojit k replice jen pro čtení v sekundárním umístění, použijte
ApplicationIntent=ReadOnlya<fog-name>.secondary.<zone_id>.database.windows.net.
Naslouchací proces pro čtení i zápis a naslouchací proces jen pro čtení nelze dosáhnout prostřednictvím veřejného koncového bodu pro spravovanou instanci.
Potenciální snížení výkonu po převzetí služeb při selhání
Typická aplikace Azure používá více služeb Azure a skládá se z několika součástí. Geografické převzetí služeb při selhání skupiny se aktivuje na základě stavu samotných komponent Azure SQL. Výpadky nemusí mít vliv na ostatní služby Azure v primární oblasti a jejich součásti můžou být v tomto regionu stále dostupné. Jakmile se primární databáze přepnou do sekundární oblasti, může se zvýšit latence mezi závislými komponentami. Zajistěte redundanci všech komponent aplikace v sekundární oblasti a převzetí služeb při selhání součástí aplikace společně s databází, aby výkon aplikace nebyl ovlivněn vyšší latencí mezi oblastmi.
Potenciální ztráta dat po vynuceném převzetí služeb při selhání
Pokud dojde k výpadku v primární oblasti, nedávné transakce se nemusí replikovat do sekundární geografické oblasti a v případě vynuceného převzetí služeb při selhání může dojít ke ztrátě dat.
Aktualizace DNS
Aktualizace DNS naslouchacího procesu pro čtení a zápis se provede okamžitě po zahájení převzetí služeb při selhání. Tato operace nezpůsobí ztrátu dat. Proces přepínání databázových rolí ale za normálních podmínek může trvat až 5 minut. Dokud se nedokončí, některé databáze v nové primární instanci budou stále jen pro čtení. Pokud se spustí převzetí služeb při selhání pomocí PowerShellu, operace přepnutí role primární repliky je synchronní. Pokud se zahájí pomocí webu Azure Portal, uživatelské rozhraní indikuje stav dokončení. Pokud je inicializováno pomocí rozhraní REST API, pomocí standardního mechanismu dotazování Azure Resource Manageru monitorujte dokončení.
Důležité
Ruční plánované převzetí služeb při selhání použijte k přesunutí primárního umístění zpět do původního umístění, jakmile dojde ke zmírnění výpadku, který způsobil geografické převzetí služeb při selhání.
Úspora nákladů s využitím repliky zotavení po havárii bez licence
Náklady na licence SQL Serveru můžete ušetřit tak, že nakonfigurujete sekundární spravovanou instanci tak, aby se používala pouze pro zotavení po havárii (DR). Postup nastavení najdete v tématu Konfigurace pohotovostní repliky bez licence pro službu Azure SQL Managed Instance.
Pokud sekundární instance není použita pro úlohy čtení, Microsoft vám poskytne bezplatný počet virtuálních jader, aby odpovídaly primární instanci. Stále se vám účtují poplatky za výpočetní prostředky a úložiště používané sekundární instancí. Skupiny převzetí služeb při selhání podporují pouze jednu repliku – replika musí být buď replika pro čtení, nebo určená jako replika jen pro zotavení po havárii.
Povolení scénářů závislých na objektech ze systémových databází
Systémové databáze se nereplikují do sekundární instance ve skupině převzetí služeb při selhání. Pokud chcete povolit scénáře, které závisí na objektech ze systémových databází, vytvořte stejné objekty v sekundární instanci a udržujte je synchronizované s primární instancí.
Pokud například plánujete používat stejná přihlášení v sekundární instanci, nezapomeňte je vytvořit se stejným identifikátorem SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Další informace viz Replikace přihlašovacích údajů a úloh agenta.
Synchronizace vlastností instance a instancí zásad uchovávání informací
Instance ve skupině převzetí služeb při selhání zůstávají samostatné prostředky Azure a žádné změny konfigurace primární instance se automaticky replikují do sekundární instance. Nezapomeňte provést všechny relevantní změny v primární i sekundární instanci. Pokud například změníte redundanci úložiště zálohování nebo zásady dlouhodobého uchovávání záloh v primární instanci, nezapomeňte ji také změnit v sekundární instanci.
Škálování instancí
Můžete vertikálně navýšit nebo snížit kapacitu primární a sekundární instance na jinou velikost výpočetních prostředků v rámci stejné úrovně služby nebo na jinou úroveň služby. Při vertikálním navýšení kapacity ve stejné úrovni služby doporučujeme nejprve vertikálně navýšit kapacitu sekundární geografické oblasti a pak vertikálně navýšit kapacitu primární úrovně. Při vertikálním snížení kapacity ve stejné úrovni služby otočte pořadí: nejprve vertikálně snížit kapacitu primárního serveru a pak vertikálně snížit kapacitu sekundární úrovně. Toto doporučení se vynucuje při škálování instance na jinou úroveň služby. Posloupnost operací se vynucuje při škálování úrovně služby a virtuálních jader a úložiště.
Toto pořadí se doporučuje zejména proto, aby se během procesu upgradu nebo downgradu zabránilo problému s přetížením instance v sekundární geografické oblasti s nižší skladovou položkou, kterou by tak bylo potřeba znovu naplnit.
Důležité
- V případě instancí ve skupině převzetí služeb při selhání se změna úrovně služby na úroveň Další generace pro obecné účely nebo z ní nepodporuje. Před úpravou repliky musíte nejprve odstranit skupinu převzetí služeb při selhání a po provedení změny znovu vytvořit skupinu převzetí služeb při selhání.
- Existuje známý problém, který může ovlivnit přístupnost škálované instance pomocí přidruženého naslouchacího procesu skupiny převzetí služeb při selhání.
Zabránění ztrátě důležitých dat
Kvůli vysoké latenci širokých sítí používá geografická replikace mechanismus asynchronní replikace. Asynchronní replikace umožňuje neuložené ztrátě dat, pokud primární selže. Aby bylo možné chránit důležité transakce před ztrátou dat, vývojář aplikace může okamžitě po potvrzení transakce zavolat sp_wait_for_database_copy_sync uloženou proceduru. Volání sp_wait_for_database_copy_sync blokuje volající vlákno do poslední potvrzené transakce byla přenášena a posílena v transakčním protokolu sekundární databáze. Nečeká však na přehrání přenášených transakcí (znovu) na sekundárním serveru. sp_wait_for_database_copy_sync je vymezen na konkrétní odkaz geografické replikace. Tento postup může volat každý uživatel s právy k připojení k primární databázi.
Pokud chcete zabránit ztrátě dat během uživatelem zahájeného plánovaného geografického převzetí služeb při selhání, automaticky a dočasně se změní synchronní replikace a pak provede převzetí služeb při selhání. Replikace se po dokončení geografického převzetí služeb při selhání vrátí do asynchronního režimu.
Poznámka:
sp_wait_for_database_copy_sync zabraňuje ztrátě dat po geografickém převzetí služeb při selhání pro konkrétní transakce, ale nezaručuje úplnou synchronizaci pro přístup pro čtení. Zpoždění způsobené voláním sp_wait_for_database_copy_sync procedury může být významné a závisí na velikosti dosud nepřesílaného transakčního protokolu v primárním okamžiku volání.
Stav skupiny převzetí služeb při selhání
Skupina převzetí služeb při selhání hlásí svůj stav popisující aktuální stav replikace dat:
- Počáteční počáteční seeding – počáteční počáteční počáteční seeding probíhá po vytvoření skupiny převzetí služeb při selhání, dokud nebudou v sekundární instanci inicializovány všechny uživatelské databáze. Proces převzetí služeb při selhání nejde zahájit, když je skupina převzetí služeb při selhání ve stavu Počáteční, protože uživatelské databáze se ještě nekopírují do sekundární instance.
- Synchronizace – obvyklý stav skupiny převzetí služeb při selhání To znamená, že se změny dat v primární instanci replikují asynchronně do sekundární instance. Tento stav nezaručuje, že se data v každém okamžiku plně synchronizují. Kvůli asynchronní povaze procesu replikace mezi instancemi ve skupině převzetí služeb při selhání může dojít ke změnám dat z primárního primárního serveru. Automatické i ruční převzetí služeb při selhání je možné zahájit, když je skupina převzetí služeb při selhání ve stavu Synchronizace.
- Probíhá převzetí služeb při selhání – tento stav označuje, že probíhá proces převzetí služeb při selhání automaticky nebo ručně zahájený. Pokud je skupina převzetí služeb při selhání v tomto stavu, nelze zahájit žádné změny skupiny převzetí služeb při selhání ani další převzetí služeb při selhání.
Navrácení služeb po obnovení
Pokud jsou skupiny převzetí služeb při selhání nakonfigurované pomocí zásad převzetí služeb při selhání spravované Microsoftem, zahájí se vynucené převzetí služeb při selhání na geograficky sekundární server během scénáře havárie podle definovaného období odkladu. Navrácení služeb po obnovení do původního primárního serveru musí být inicializováno ručně.
Interoperabilita funkcí
Zálohování
Úplné zálohování se provádí v následujících scénářích:
- Před počátečním počátečním předvysažením začnete při vytváření skupiny převzetí služeb při selhání.
- Po převzetí služeb při selhání.
Úplná záloha je velikost operace dat, která se nedá přeskočit ani odložit a může nějakou dobu trvat. Doba, která trvá dokončení, závisí na velikosti dat, počtu databází a intenzitě úloh v primárních databázích. Úplné zálohování může výrazně zpozdit počáteční počáteční počáteční seeding a může buď zpozdit nebo zabránit operaci převzetí služeb při selhání v nové instanci krátce po převzetí služeb při selhání.
Služba Log Replay
Databáze migrované do služby Azure SQL Managed Instance pomocí služby LRS (Log Replay Service) se nedají přidat do skupiny převzetí služeb při selhání, dokud nebude proveden krok přímé migrace. Databáze migrovaná pomocí LRS je ve stavu obnovení, dokud nedojde k přímé migraci a databáze ve stavu obnovení není možné přidat do skupiny převzetí služeb při selhání. Při pokusu o vytvoření skupiny převzetí služeb při selhání s databází v obnovovacím stavu dochází ke zpoždění při vytváření skupiny převzetí služeb při selhání, dokud se obnovení databáze nevytvoří.
Transakční replikace
Použití transakční replikace s instancemi, které jsou ve skupině převzetí služeb při selhání, je podporováno. Pokud ale nakonfigurujete replikaci před přidáním spravované instance SQL do skupiny převzetí služeb při selhání, replikace se pozastaví, jakmile začnete vytvářet skupinu převzetí služeb při selhání, a monitor replikace zobrazí stav Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Replikace se obnoví po úspěšném vytvoření skupiny převzetí služeb při selhání.
Pokud je spravovaná instance SQL vydavatele nebo distributora ve skupině převzetí služeb při selhání, musí správce spravované instance SQL vyčistit všechny publikace na staré primární instanci a po převzetí služeb při selhání je znovu nakonfigurovat na nové primární instanci. Projděte si průvodce transakční replikací pro krok aktivit, které jsou v tomto scénáři potřeba.
Oprávnění a omezení
Před konfigurací skupiny převzetí služeb při selhání zkontrolujte seznam oprávnění a omezení .
Programová správa skupin převzetí služeb při selhání
Skupiny převzetí služeb při selhání je možné spravovat také programově pomocí Azure PowerShellu, Azure CLI a rozhraní REST API. Další informace najdete v konfiguraci skupiny převzetí služeb při selhání.
Postup zotavení po havárii
Doporučený způsob, jak provést postup zotavení po havárii, je použití ručního plánovaného převzetí služeb při selhání podle následujícího kurzu: Testovací převzetí služeb při selhání.
Provedení postupu pomocí vynuceného převzetí služeb při selhání se nedoporučuje, protože tato operace neposkytuje ochranné mantinely proti ztrátě dat. Je však možné dosáhnout bezeztrátového vynuceného převzetí služeb při selhání dat zajištěním splnění následujících podmínek před zahájením vynuceného převzetí služeb při selhání:
- Úloha se zastaví v primární spravované instanci.
- Všechny dlouhotrvající transakce byly dokončeny.
- Všechna klientská připojení k primární spravované instanci byla odpojena.
- Stav skupiny převzetí služeb při selhání je Synchronizace.
Před volitelným navázáním připojení k nové primární spravované instanci a spuštěním úlohy čtení i zápisu se stav skupiny převzetí služeb při selhání přepnul z probíhajícího převzetí služeb při selhání na Synchronizaci.
Pokud chcete provést navrácení služeb po obnovení bezeztrátového obnovení do původních rolí spravované instance, důrazně doporučujeme použít ruční plánované převzetí služeb při selhání místo vynuceného převzetí služeb při selhání. Pokud chcete pokračovat v vynuceném navrácení služeb po obnovení, postupujte následovně:
- Postupujte stejně jako u převzetí služeb při selhání bezeztrátového převzetí služeb při selhání.
- Delší doba provádění navrácení služeb po obnovení se očekává, pokud se vynucené navrácení služeb po obnovení spustí krátce po dokončení počátečního vynuceného převzetí služeb při selhání, protože musí čekat na dokončení nevyřízených automatických operací zálohování v bývalé primární spravované instanci.
Související obsah
- Konfigurace skupiny převzetí služeb při selhání
- Přidání spravované instance do skupiny převzetí služeb při selhání pomocí PowerShellu
- Konfigurace pohotovostní repliky bez licence pro službu Azure SQL Managed Instance
- Přehled kontinuity podnikových procesů s Azure SQL Managed Instance
- Automatizované zálohování ve službě Azure SQL Managed Instance
- Obnovení databáze ze zálohy ve službě Azure SQL Managed Instance