Cílové zóny dat
Cílové zóny dat jsou připojené k cílové zóně správy dat pomocí partnerského vztahu virtuální sítě. Každá cílová zóna dat se považuje za cílovou zónu související s architekturou cílové zóny Azure.
Důležité
Před zřízením cílové zóny dat se ujistěte, že je nasazený provozní model DevOps a CI/CD a nasadí se cílová zóna správy dat.
Každá cílová zóna dat má několik vrstev, které umožňují flexibilitu pro integraci dat služby a datové produkty, které obsahuje. Novou cílovou zónu dat můžete nasadit se standardní sadou služeb, které umožní cílové zóně dat začít ingestovat a analyzovat data.
Vaše předplatné Azure přidružené k cílové zóně dat má následující strukturu:
| Vrstva | Požaduje se | Skupiny prostředků |
|---|---|---|
| Základní služby | Ano |
|
| Datová aplikace | Volitelné |
|
| Vizualizace | Volitelné |
Poznámka:
Datová aplikace vytváří jeden nebo více datových produktů.
Architektura cílové zóny dat
Architektura cílové zóny dat znázorňuje vrstvy, jejich skupiny prostředků a služby, které každá skupina prostředků obsahuje. Architektura také poskytuje přehled všech skupin a rolí přidružených k cílové zóně dat a také rozsah jejich přístupu k řídicím rovinám a rovinám dat.

Tip
Než nasadíte cílovou zónu dat, nezapomeňte zvážit počet počátečních cílových zón dat, které chcete nasadit.
Tuto architekturu použijte jako výchozí bod. Stáhněte si soubor Visia a upravte ho tak, aby vyhovoval vašim konkrétním obchodním a technickým požadavkům při plánování implementace cílové zóny dat.
Vrstva základních služeb
Vrstva základních služeb zahrnuje všechny služby potřebné k povolení cílové zóny dat v kontextu analýzy v cloudovém měřítku. Následující tabulka uvádí skupiny prostředků, které poskytují standardní sadu dostupných služeb v každé cílové zóně dat, kterou nasadíte.
| Skupina prostředků | Vyžadováno | Popis |
|---|---|---|
network-rg |
Ano | Sítě |
databricks-monitoring-rg |
Volitelné | Monitorování pracovních prostorů Azure Databricks |
hive-rg |
Volitelné | Metastore Hive pro Azure Databricks |
storage-rg |
Ano | Služby Data Lakes |
external-data-rg |
Ano | Nahrání úložiště ingestování |
runtimes-rg |
Ano | Moduly runtime pro sdílenou integraci |
mgmt-rg |
Ano | Agenti CI/CD |
metadata-ingestion-rg |
Volitelné | Příjem dat nezávislý na datech |
databricks-monitoring-rg |
Volitelné | Pracovní prostor služby Log Analytics pro pracovní prostory Databricks v cílové zóně |
shared-synapse-rg |
Volitelné | Sdílená služba Azure Synapse |
shared-databricks-rg |
Volitelné | Sdílený pracovní prostor Azure Databricks |
Sítě
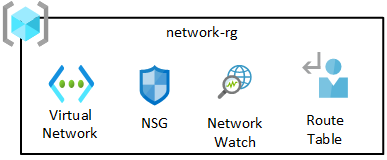
Skupina síťových prostředků obsahuje základní komponenty, mezi které patří Azure Network Watcher, skupiny zabezpečení sítě (NSG) a virtuální síť. Všechny tyto služby se nasadí do jedné skupiny prostředků.
Virtuální síť cílové zóny dat je automaticky v partnerském vztahu s virtuální sítí cílové zóny pro správu dat a virtuální sítí vašeho předplatného připojení.
Monitorování pracovních prostorů Azure Databricks
Tato skupina prostředků je volitelná a nasazuje se pouze pomocí Azure Databricks.
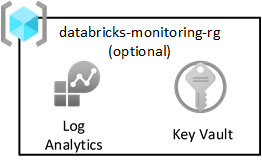
Vzor cílové zóny Azure doporučuje odesílat všechny protokoly do centrálního pracovního prostoru služby Log Analytics. Každá cílová zóna dat ale zahrnuje také skupinu prostředků monitorování pro zachycení protokolů Sparku z Databricks. Každá skupina prostředků obsahuje sdílený pracovní prostor služby Log Analytics a Azure Key Vault pro ukládání klíčů Log Analytics.
Důležité
K zachycení protokolů Azure Databricks Spark použijte pracovní prostor služby Log Analytics ve skupině prostředků monitorování Databricks.
Další informace najdete v tématu Monitorování Azure Databricks.
Metastore Hive pro Azure Databricks
Tato skupina prostředků je volitelná a měla by se nasadit jenom s Azure Databricks.
Metastore Hive pro Azure Databricks zřídí databázi Azure Database for MySQL a trezor klíčů. Všechny pracovní prostory Azure Databricks ve vaší cílové zóně dat používají tento metastor jako externí metastore Apache Hive.
Další informace najdete v tématu Externí metastore Apache Hive.
Data Lake Services
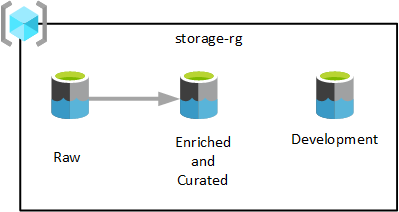
Jak je znázorněno v předchozím diagramu, tři účty Azure Data Lake Storage Gen2 se zřídí v jedné skupině prostředků služby Data Lake Services. Data transformovaná v různých fázích se ukládají do jednoho z datových jezer cílové zóny vašich dat. Data jsou dostupná pro využití analytickými týmy, datovými vědami a vizualizacemi.
Vrstvy Data Lake používají různé terminologie v závislosti na technologii a dodavateli. Tato tabulka obsahuje pokyny k použití podmínek pro analýzy v cloudovém měřítku:
| Analýzy v cloudovém měřítku | Delta Lake | Další podmínky | Popis |
|---|---|---|---|
| Nezpracováno | Bronzový | Cíl a shoda | Tabulky příjmu dat |
| Obohacený | Silver | Zóna standardizace | Upřesňující tabulky Uložená úplná entita, sady záznamů připravené pro spotřebu ze systémů záznamu. |
| Uspořádáno | Gold | Zóna produktu | Funkce nebo agregované tabulky Primární zóna pro aplikace, týmy a uživatele pro využívání datových produktů |
| Vývoj | -- | Zóna vývoje | Umístění datových inženýrů a vědců, které tvoří analytický sandbox i zónu vývoje produktů. |
Poznámka:
V předchozím diagramu má každá cílová zóna dat tři datová jezera. V závislosti na vašich požadavcích ale můžete chtít konsolidovat nezpracované, rozšířené a kurátorované vrstvy do jednoho účtu úložiště a udržovat další účet úložiště označovaný jako vývoj pro uživatele dat, aby mohli přinést další užitečné datové produkty.
Další informace naleznete v tématu:
- Přehled služby Azure Data Lake Storage pro analýzy v cloudovém měřítku
- Standardizace dat
- Zřízení účtů Azure Data Lake Storage Gen2 pro každou cílovou zónu dat
- Klíčové aspekty služby Azure Data Lake Storage
- Řízení přístupu a konfigurace data Lake ve službě Azure Data Lake Storage
Nahrání úložiště ingestování
Vydavatelé dat třetích stran musí zadávat data do vaší platformy, aby je týmy datových aplikací mohly načíst do svých datových jezer. Jak je vidět na následujícím diagramu, vaše skupina prostředků úložiště pro nahrávání umožňuje zřídit úložiště objektů blob pro třetí strany.
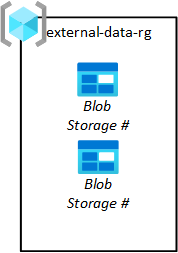
Vaše týmy datových aplikací požadují tyto objekty blob úložiště. Jejich žádosti pak schválí váš provozní tým cílové zóny dat. Data by se měla odebrat ze zdrojového objektu blob úložiště po načtení z objektu blob úložiště do nezpracovaných dat.
Důležité
Vzhledem k tomu, že se objekty blob azure Storage zřizují podle potřeby , měli byste nejprve nasadit prázdnou skupinu prostředků služby úložiště v každé cílové zóně dat.
Moduly runtime pro sdílenou integraci
Nasaďte virtuální počítač s místním prostředím Integration Runtime do cílové zóny dat. Hostujte ji ve skupině prostředků sdílené integrace. Toto nasazení umožňuje rychle připojit datové produkty do cílové zóny dat.
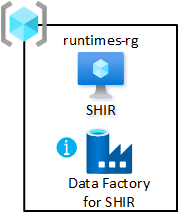
Povolení skupiny prostředků:
- Ve skupině prostředků sdílené integrace vaší cílové zóny dat vytvořte aspoň jednu službu Azure Data Factory. Použijte ho jenom pro propojení sdíleného místního prostředí Integration Runtime, ne pro datové kanály.
- Vytvořte a nakonfigurujte místní prostředí Integration Runtime na virtuálním počítači.
- Přidružte místní prostředí Integration Runtime k datovým továrnám Azure v cílových zónách dat.
- Nastavte Službu Azure Automation tak, aby pravidelně aktualizovala místní prostředí Integration Runtime.
Poznámka:
Výše uvedené nasazení poskytuje nasazení jednoho virtuálního počítače s místním prostředím Integration Runtime. Místní prostředí Integration Runtime můžete přidružit k několika místním počítačům nebo virtuálním počítačům v Azure. Tyto počítače se nazývají uzly. K místnímu prostředí Integration Runtime můžete mít přidružené až čtyři uzly. Výhody, které mají několik uzlů na místních počítačích s nainstalovanou bránou pro logickou bránu, jsou:
- Vyšší dostupnost místního prostředí Integration Runtime, aby už nedošlo k jedinému bodu selhání v řešení pro velké objemy dat nebo integraci cloudových dat. Tato dostupnost pomáhá zajistit kontinuitu při použití až čtyř uzlů.
- Lepší výkon a propustnost během přesunu dat mezi místními a cloudovými úložišti dat. Získejte další informace o porovnání výkonu.
Více uzlů můžete přidružit instalací softwaru integration runtime v místním prostředí z webu Download Center. Pak ho zaregistrujte pomocí některého z ověřovacích klíčů získaných z rutiny New-AzDataFactoryV2IntegrationRuntimeKey , jak je popsáno v tomto kurzu.
Podrobné informace o vysoké dostupnosti a škálovatelnosti Azure Datafactory
Důležité
Nasaďte moduly runtime sdílené integrace co nejblíže zdroji dat. Jejich nasazení neomezuje vaše nasazení prostředí Integration Runtime v cílové zóně dat nebo do cloudů třetích stran. Místo toho poskytuje záložní zdroj dat nativní pro cloud v oblasti.
Agenti CI/CD
Agenti CI/CD pomáhají nasazovat datové aplikace a změny do cílové zóny dat.
Další informace najdete v tématu Agenti azure Pipeline.
Příjem dat nezávislý na datech
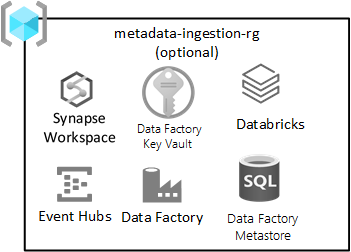
Tato skupina prostředků je volitelná a nezakazuje vám nasadit cílovou zónu.
Tato skupina prostředků platí, pokud máte (nebo vyvíjíte) modul pro příjem dat, který automaticky ingestuje data na základě registrace metadat (včetně připojovací řetězec, cesty ke kopírování dat z a do a plánu příjmu dat. Skupina prostředků pro příjem dat a zpracování má pro tento druh architektury klíčové služby.
Nasaďte instanci služby Azure SQL Database pro uchovávání metadat používaných službou Azure Data Factory. Zřízení služby Azure Key Vault pro ukládání tajných kódů souvisejících se službami automatizovaného příjmu dat Mezi tyto tajné kódy patří:
- Přihlašovací údaje metastoru služby Azure Data Factory
- Přihlašovací údaje instančního objektu pro váš automatizovaný proces příjmu dat
Další informace najdete v tématu Jak automatizované architektury příjmu dat podporují analýzy na úrovni cloudu v Azure.
Mezi služby zahrnuté v této skupině prostředků patří:
| Služba | Požaduje se | Pokyny |
|---|---|---|
| Azure Data Factory | Ano | Azure Data Factory je váš orchestrační modul pro nezávislé na příjmu dat. |
| Azure SQL DB | Ano | Azure SQL DB je metastor pro Službu Azure Data Factory. |
| Event Hubs nebo IoT Hub | Volitelné | Event Hubs nebo IoT Hub můžou poskytovat streamování v reálném čase do služby Event Hubs a také dávkové zpracování a zpracování streamování prostřednictvím technického pracovního prostoru Databricks. |
| Azure Databricks | Volitelné | Azure Databricks nebo Azure Synapse Spark můžete nasadit pro použití s modulem pro příjem dat, který je nezávislý na datech. |
| Azure Synapse | Volitelné | Azure Databricks nebo Azure Synapse Spark můžete nasadit tak, aby se používaly s modulem pro příjem dat, který je nezávislý na datech. |
Sdílená databricks
Tato skupina prostředků je volitelná a nasazuje se pouze pomocí Azure Databricks. Každý člen vaší cílové zóny dat může používat pracovní prostor Databricks.
Azure Databricks je klíčovým příjemcem služby Azure Data Lake Storage. Operace atomických souborů jsou optimalizované pro analytické moduly Sparku. Tato optimalizace urychlí dokončení úloh Sparku, které se týkají problémů se službou Azure Databricks.
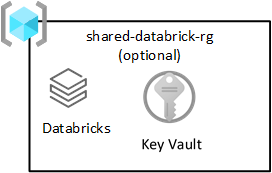
Důležité
Pracovní prostor Azure Databricks označovaný jako pracovní prostor Azure Databricks (analýza) je zřízený pro všechny datové vědce a DataOps, jak je znázorněno ve skupině prostředků sdílených produktů.
Tento pracovní prostor můžete nakonfigurovat tak, aby se připojil k Azure Data Lake pomocí předávání Microsoft Entra nebo řízení přístupu k tabulce. V závislosti na vašem případu použití můžete podmíněný přístup nakonfigurovat jako další bezpečnostní opatření.
Při integraci Azure Databricks postupujte podle osvědčených postupů analýzy v cloudovém měřítku:
- Zabezpečený přístup k Azure Data Lake Gen2 z Azure Databricks
- Osvědčené postupy pro Azure Databricks
Vzor cílové zóny Azure doporučuje odesílat všechny protokoly do centrálního pracovního prostoru služby Log Analytics. Každá cílová zóna dat ale obsahuje také skupinu prostředků monitorování pro zachycení protokolů Sparku z Databricks.
Sdílená služba Azure Synapse Analytics
Tato skupina prostředků je volitelná.
Během počátečního nastavení cílové zóny dat se nasadí jeden pracovní prostor Azure Synapse Analytics pro použití všemi datovými analytiky a vědci ve vaší skupině prostředků sdílených produktů.
Pokud se vyžaduje správa nákladů a dobíjení, můžete pro datové produkty nastavit více pracovních prostorů Synapse. Týmy datových aplikací můžou využít vyhrazené pracovní prostory Azure Synapse Analytics k vytvoření vyhrazených fondů Azure SQL Database jako úložiště dat pro čtení používané vrstvou vizualizace.
Důležité
Zabráníte použití sdíleného pracovního prostoru Azure Synapse pro vytváření datových produktů tím, že pracovní prostor uzamknete, aby se povolily pouze dotazy SQL na vyžádání. Je tam pouze pro zneužítelné účely.
Datová aplikace
Každá cílová zóna dat může mít více datových produktů. Tyto datové produkty můžete vytvořit ingestováním dat ze zdroje. Můžete také vytvořit datové produkty z jiných datových produktů ve stejné cílové zóně dat nebo z jiných cílových zón dat. Na vytvoření datového produktu se vztahuje schválení správce údajů.
Skupina prostředků datového produktu
Produkt skupiny prostředků vašeho datového produktu zahrnuje všechny služby potřebné k vytvoření datového produktu. Například pro MySQL je vyžadována služba Azure Database, kterou používá vizualizační nástroj. Data se musí ingestovat a transformovat, než se přejdou do databáze MySQL. V tomto případě můžete službu Azure Database for MySQL a Azure Data Factory nasadit do skupiny prostředků datového produktu.
Tip
Pokud se rozhodnete neimplementovat modul nezávislý na datech pro příjem dat z provozních zdrojů nebo pokud složitá připojení nejsou v modulu nezávislá na datech usnadnit, vytvořte zdrojovou aplikaci dat, která je zarovnaná. Další informace najdete v tématu Datové aplikace (zarovnané zdroje)
Další informace o onboardingu datových produktů najdete v tématu Analytické datové produkty v cloudovém měřítku v Azure.
Vizualizace
Pro každou cílovou zónu dat se vytvoří prázdná skupina prostředků vizualizace. Vyplňte tuto skupinu prostředků službami, které potřebujete k implementaci řešení vizualizace. Použití existující virtuální sítě umožňuje vašemu řešení připojit se k datovým produktům.
Tato skupina prostředků může hostovat virtuální počítače pro vizualizační služby třetích stran.
Tip
Vzhledem k nákladům na licencování může být výhodnější nasadit do cílové zóny správy dat produkty vizualizace třetích stran a aby se tyto produkty mohly připojovat mezi cílovými zónami dat, aby se mohly data vrátit zpět.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro