Globální distribuce dat se službou Azure Cosmos DB – pod kapotou
PLATÍ PRO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Skřítek
Skřítek ![]() Stůl
Stůl
Azure Cosmos DB je základní služba v Azure, takže je nasazená ve všech oblastech Azure po celém světě, včetně veřejného, suverénního, ministerstva obrany (DoD) a cloudů pro státní správu.
Na vysoké úrovni jsou data kontejneru Azure Cosmos DB horizontálně rozdělena do mnoha sad replik, které replikují zápisy v každé oblasti. Repliky nastaví trvale zápisy pomocí kvora většiny.
Každá oblast obsahuje všechny datové oddíly kontejneru Azure Cosmos DB a může obsluhovat čtení i zápisy v případech, kdy je povolené zápisy do více oblastí. Pokud je váš účet Azure Cosmos DB distribuovaný napříč oblastmi Azure N , bude existovat alespoň N x 4 kopie všech vašich dat.
V datovém centru nasazujeme a spravujeme Službu Azure Cosmos DB na masivní razítka počítačů s vyhrazeným místním úložištěm. V rámci datového centra se služba Azure Cosmos DB nasazuje napříč mnoha clustery, z nichž každý může běžet více generací hardwaru. Počítače v clusteru se obvykle šíří mezi 10 až 20 domén selhání pro zajištění vysoké dostupnosti v rámci oblasti. Následující obrázek znázorňuje topologii globálního distribučního systému služby Azure Cosmos DB:
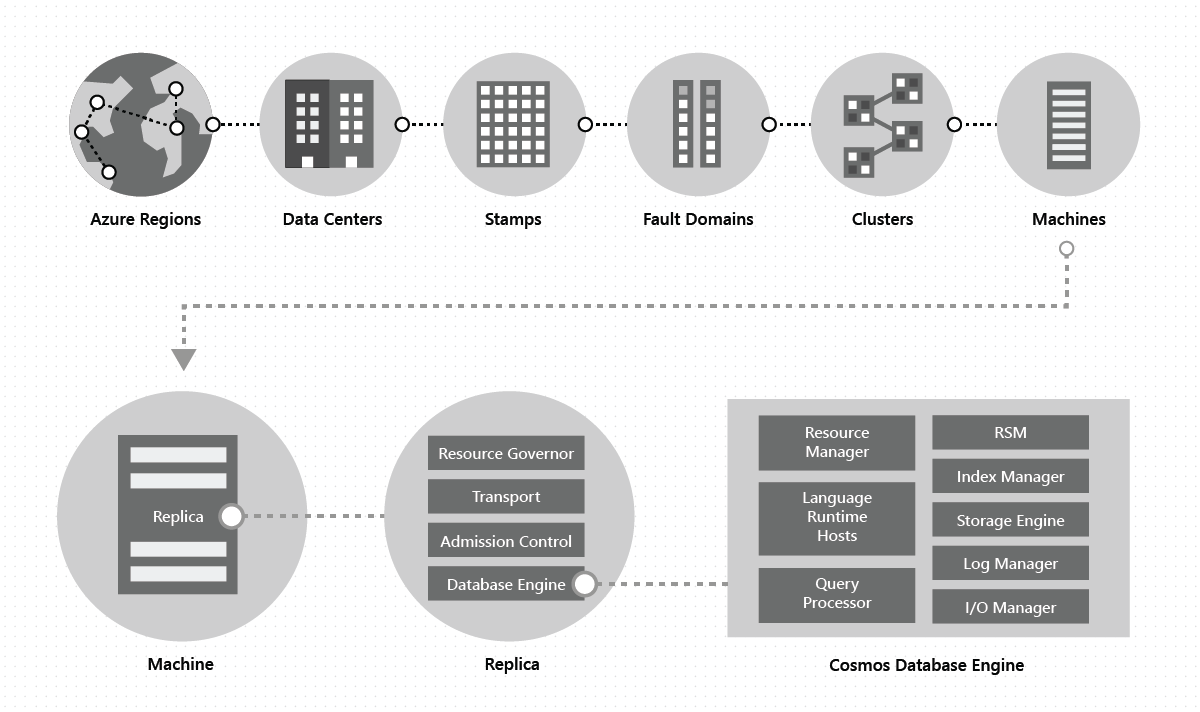
Globální distribuce ve službě Azure Cosmos DB je na klíč: Kdykoli můžete několika kliknutími nebo programově přidat nebo odebrat geografické oblasti přidružené k databázi Azure Cosmos DB. Databáze Azure Cosmos DB se zase skládá ze sady kontejnerů Azure Cosmos DB. Kontejnery ve službě Azure Cosmos DB slouží jako logické jednotky distribuce a škálovatelnosti. Kolekce, tabulky a grafy, které vytvoříte, jsou (interně) jen kontejnery Azure Cosmos DB. Kontejnery jsou zcela nezávislé na schématu a poskytují rozsah dotazu. Data v kontejneru Azure Cosmos DB se při příjmu dat automaticky indexují. Automatické indexování umožňuje uživatelům dotazovat se na data bez potíží se správou schématu nebo indexu, zejména v globálně distribuovaném nastavení.
V dané oblasti se data v kontejneru distribuují pomocí klíče oddílu, který zadáte a transparentně spravuje základní fyzické oddíly (místní distribuce).
Každý fyzický oddíl se také replikuje napříč geografickými oblastmi (globální distribuce).
Když aplikace využívající Službu Azure Cosmos DB elasticky škáluje propustnost kontejneru Azure Cosmos DB nebo využívá více úložiště, Azure Cosmos DB transparentně zpracovává operace správy oddílů (rozdělení, klonování, odstranění) ve všech oblastech. Azure Cosmos DB bez ohledu na škálování, distribuci nebo selhání nadále poskytuje jednu systémovou image dat v rámci kontejnerů, které jsou globálně distribuovány napříč libovolným počtem oblastí.
Jak je znázorněno na následujícím obrázku, data v kontejneru se distribuují ve dvou dimenzích – v rámci oblasti a napříč oblastmi po celém světě:
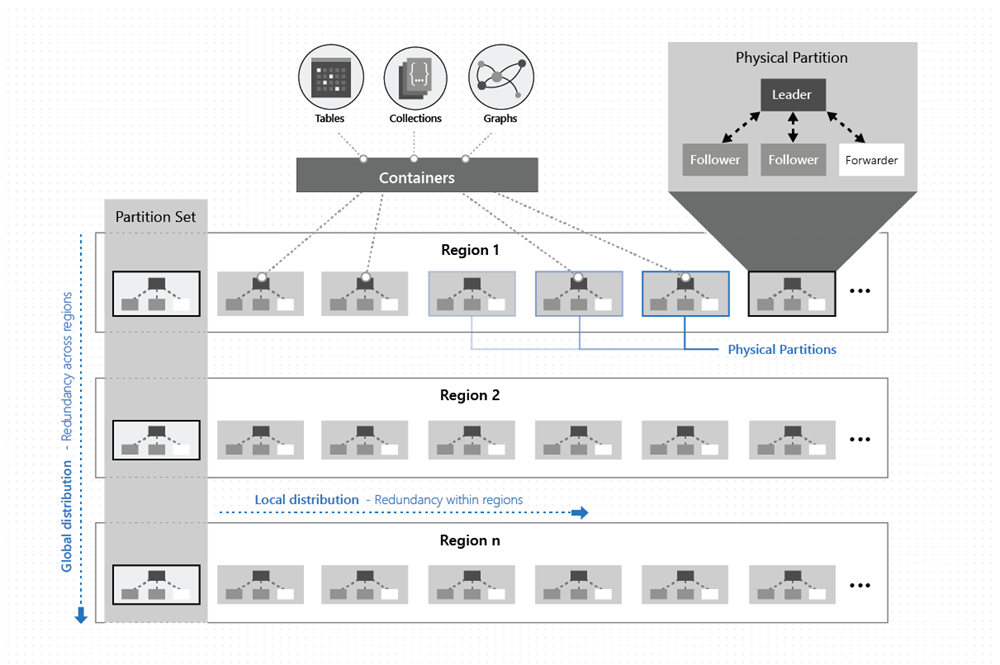
Fyzický oddíl je implementovaný skupinou replik, označovanou jako sada replik. Každý počítač hostuje stovky replik, které odpovídají různým fyzickým oddílům v rámci pevné sady procesů, jak je znázorněno na obrázku výše. Repliky odpovídající fyzickým oddílům se dynamicky umísťují a vyrovnávají zatížení mezi počítači v clusteru a datových centrech v rámci oblasti.
Replika jednoznačně patří do tenanta služby Azure Cosmos DB. Každá replika hostuje instanci databázového stroje služby Azure Cosmos DB, která spravuje prostředky i přidružené indexy. Databázový stroj Azure Cosmos DB pracuje se systémem typů založeným na sekvenci záznamů atomů (ARS). Modul je nezávislý na konceptu schématu, rozmazaní hranice mezi strukturou a hodnotami instancí záznamů. Azure Cosmos DB dosahuje plného nezávislého schématu tím, že automaticky indexuje vše při příjmu dat efektivním způsobem, což umožňuje uživatelům dotazovat se na globálně distribuovaná data, aniž by museli řešit správu schématu nebo indexu.
Databázový stroj Azure Cosmos DB se skládá z komponent, včetně implementace několika primitivních prvků koordinace, jazykových modulů runtime, procesoru dotazů a subsystémů úložiště a indexování zodpovědných za transakční úložiště a indexování dat. Aby byl zajištěna stálost a vysoká dostupnost, databázový stroj uchovává svá data a indexy na discích SSD a replikuje je mezi instancemi databázového stroje v replikách v uvedeném pořadí. Větší tenanti odpovídají většímu měřítku propustnosti a úložiště a mají buď větší nebo více replik, nebo obojí. Každá komponenta systému je plně asynchronní – žádné vlákno nikdy neblokuje a každé vlákno funguje krátkodobě, aniž by došlo k zbytečným přepínačům vlákna. Omezování rychlosti a zpětné tlaky se ukládají do celého zásobníku od řízení přístupu ke všem vstupně-výstupním cestám. Databázový stroj Azure Cosmos DB je navržený tak, aby využíval jemně odstupňovanou souběžnost a poskytoval vysokou propustnost při provozu v rámci frugalních systémových prostředků.
Globální distribuce služby Azure Cosmos DB spoléhá na dvě klíčové abstrakce – sady replik a sady oddílů. Sada replik je modulární blok Lego pro koordinaci a sada oddílů je dynamické překrytí jednoho nebo více geograficky distribuovaných fyzických oddílů. Abychom pochopili, jak globální distribuce funguje, musíme tyto dvě klíčové abstrakce pochopit.
Sady replik
Fyzický oddíl je materializován jako skupina replik s automatickým přístupem a dynamicky s vyrovnáváním zatížení rozložená mezi více domén selhání, označovaná jako sada replik. Tato sada souhrnně implementuje replikovaný protokol stavového počítače, aby byla data v rámci fyzického oddílu vysoce dostupná, odolná a konzistentní. Členství v sadě replik je dynamické – neustále kolísá mezi NMin a NMax na základě selhání, operací správy a času neúspěšných replik k opětovnému vygenerování nebo obnovení. Na základě změn členství protokol replikace také překonfiguruje velikost kvora pro čtení a zápis. K rovnoměrné distribuci propustnosti přiřazené k danému fyzickému oddílu používáme dva nápady:
Za prvé, náklady na zpracování žádostí o zápis na vedoucího serveru jsou vyšší než náklady na použití aktualizací v následníku. V souladu s tím je vedoucího programu rozpočtován více systémových prostředků než sledujících.
Za druhé, pokud je to možné, kvorum čtení pro danou úroveň konzistence se skládá výhradně z následných replik. Vyhneme se kontaktování vedoucího pracovníka pro poskytování čtení, pokud není vyžadováno. Pro pět modelů konzistence, které Azure Cosmos DB podporuje, využíváme řadu nápadů z průzkumu provedeného ve vztahu zatížení a kapacity v systémech založených na kvoru .
Sady oddílů
Skupina fyzických oddílů, jedna z každé nakonfigurované oblasti databáze Azure Cosmos DB, se skládá ke správě stejné sady klíčů replikovaných napříč všemi nakonfigurovanými oblastmi. Tato vyšší koordinační primitiva se nazývá sada oddílů – geograficky distribuovaný dynamický překryv fyzických oddílů, které spravují danou sadu klíčů. Zatímco daný fyzický oddíl (sada replik) je v rámci clusteru vymezený, sada oddílů může zahrnovat clustery, datacentra a geografické oblasti, jak je znázorněno na následujícím obrázku:
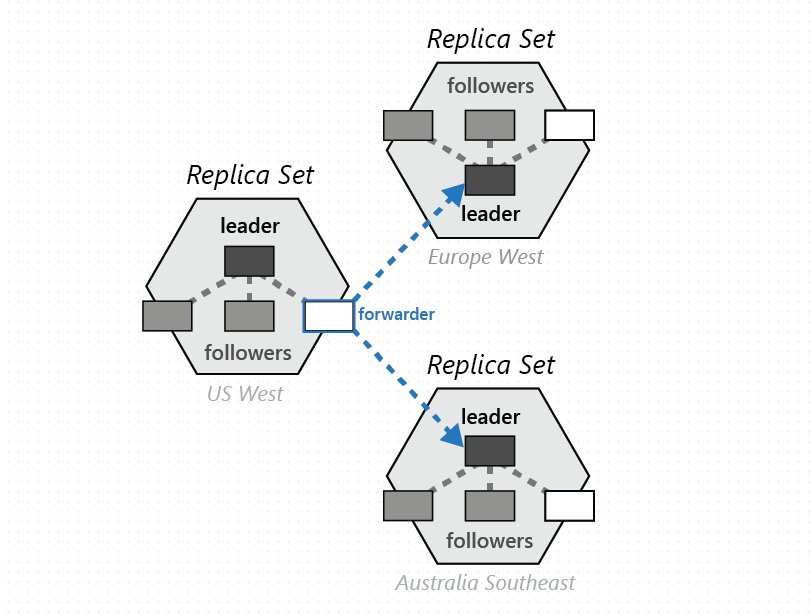
Sadu oddílů si můžete představit jako geograficky rozptýlenou "super replikovanou sadu", která se skládá z několika sad replik, které vlastní stejnou sadu klíčů. Podobně jako u sady replik je členství v sadě oddílů také dynamické – kolísá na základě implicitních operací správy fyzických oddílů a přidává nebo odebírá nové oddíly do/z dané sady oddílů (například při horizontálním navýšení kapacity v kontejneru, přidání nebo odebrání oblasti do databáze Azure Cosmos DB nebo při selhání). Na základě toho, že každý oddíl (sady oddílů) spravuje členství v sadě oddílů v rámci vlastní sady replik, je členství plně decentralizované a vysoce dostupné. Během rekonfigurace sady oddílů se vytvoří také topologie překrytí mezi fyzickými oddíly. Topologie se dynamicky vybírá na základě úrovně konzistence, zeměpisné vzdálenosti a dostupné šířky pásma sítě mezi zdrojovým a cílovým fyzickými oddíly.
Služba umožňuje nakonfigurovat databáze Azure Cosmos DB s jednou oblastí zápisu nebo několika oblastmi zápisu a v závislosti na volbě jsou sady oddílů nakonfigurované tak, aby přijímaly zápisy přesně v jedné nebo ve všech oblastech. Systém využívá dvouúrovňový vnořený protokol pro konsensus – jedna úroveň funguje v replikách sady replik fyzického oddílu, který přijímá zápisy, a druhý funguje na úrovni sady oddílů a poskytuje kompletní záruky řazení pro všechny potvrzené zápisy v rámci sady oddílů. Tato vícevrstvý vnořená shoda je důležitá pro implementaci našich striktních smluv SLA pro zajištění vysoké dostupnosti a také implementace modelů konzistence, které Azure Cosmos DB nabízí svým zákazníkům.
Řešení konfliktů
Náš návrh šíření aktualizací, řešení konfliktů a sledování kauzality je inspirovaný předchozí prací na algoritmech epidemie a systému Bayou. Zatímco jádra nápadů přežila a poskytují pohodlný rámec odkazu pro komunikaci návrhu systému služby Azure Cosmos DB, prošly také významnou transformací, protože jsme je použili v systému Azure Cosmos DB. To bylo potřeba, protože předchozí systémy nebyly navrženy ani se zásadami správného řízení prostředků ani se škálováním, ve kterém služba Azure Cosmos DB potřebuje fungovat, ani k poskytování funkcí (například omezené konzistence neagresivity) a striktnějších a komplexních smluv SLA, které Azure Cosmos DB poskytuje svým zákazníkům.
Vzpomeňte si, že sada oddílů je distribuovaná napříč několika oblastmi a řídí se replikačním protokolem služby Azure Cosmos DB (zápisy do více oblastí), který replikuje data mezi fyzické oddíly, které tvoří danou sadu oddílů. Každý fyzický oddíl (sady oddílů) přijímá zápisy a obsluhuje čtení obvykle klientům, kteří jsou v dané oblasti místní. Zápisy přijaté fyzickým oddílem v rámci oblasti jsou trvale potvrzené a vysoce dostupné v rámci fyzického oddílu předtím, než se potvrdí klientovi. Jedná se o nezávazné zápisy a šíří se do dalších fyzických oddílů v sadě oddílů pomocí anti-entropického kanálu. Klienti si mohou vyžádat nezávazné nebo potvrzené zápisy předáním hlavičky požadavku. Šíření anti entropie (včetně frekvence šíření) je dynamické na základě topologie sady oddílů, regionální blízkosti fyzických oddílů a nakonfigurované úrovně konzistence. Azure Cosmos DB se v sadě oddílů řídí primárním schématem potvrzení s dynamicky vybraným oddílem arbiteru. Výběr arbiteru je dynamický a je nedílnou součástí rekonfigurace sady oddílů na základě topologie překrytí. Potvrzené zápisy (včetně víceřádkových nebo dávkových aktualizací) jsou zaručené, že se budou řadit.
K detekci a řešení konfliktů aktualizací používáme zakódované vektorové hodiny (obsahující ID oblasti a logické hodiny odpovídající každé úrovni konsensu v sadě replik a sadě oddílů). Topologie a algoritmus výběru partnerského vztahu jsou navržené tak, aby zajistily pevnou a minimální velikost úložiště a minimální síťové režie vektorů verzí. Algoritmus zaručuje striktní konvergenční vlastnost.
Pro databáze Azure Cosmos DB nakonfigurované s více oblastmi zápisu nabízí systém řadu flexibilních zásad automatického řešení konfliktů, ze kterých si můžou vývojáři vybírat, včetně:
- Last-Write-Wins (LWW), která ve výchozím nastavení používá vlastnost časového razítka definovanou systémem (která je založená na protokolu hodin synchronizace času). Azure Cosmos DB také umožňuje zadat jakoukoli jinou vlastní číselnou vlastnost, která se má použít pro řešení konfliktů.
- Zásada řešení konfliktů definovaná aplikací (vlastní) (vyjádřená pomocí procedur sloučení), která je určená pro sémantiku definovanou aplikací při sousouhlasení konfliktů. Tyto postupy se vyvolávají při detekci konfliktů zápisu do zápisu pod vedením databázové transakce na straně serveru. Systém poskytuje přesně jednou záruku pro provádění procesu sloučení jako součást protokolu závazku. K dispozici je několik ukázek řešení konfliktů, se kterými si můžete pohrát.
Modely konzistence
Bez ohledu na to, jestli nakonfigurujete databázi Azure Cosmos DB s jednou nebo více oblastmi zápisu, můžete si vybrat z pěti dobře definovaných modelů konzistence. U několika oblastí zápisu je několik zajímavých aspektů úrovní konzistence:
Konzistence s ohraničenou neschytností zaručuje, že všechna čtení budou v předponách K nebo T sekundách od posledního zápisu v některé z oblastí. Kromě toho je zaručeno, že čtení s ohraničenou konzistencí nestarosti je monotónní a s konzistentními zárukami předpony. Anti-entropy protokol funguje rychlostí omezené a zajišťuje, že předpony se neshromažďují a zpětný tlak na zápisy není nutné použít. Konzistence relací zaručuje monotónní čtení, monotónní zápis, čtení vlastních zápisů, zápis sleduje záruky čtení a konzistentní předpony po celém světě. U databází nakonfigurovaných se silnou konzistencí se výhody (nízká latence zápisu, vysoká dostupnost zápisu) několika oblastí zápisu nevztahují, protože synchronní replikace napříč oblastmi.
Sémantika pěti modelů konzistence ve službě Azure Cosmos DB je zde popsaná a matematicky popsána pomocí specifikací TLA+ vysoké úrovně.
Další kroky
Další informace o konfiguraci globální distribuce najdete v následujících článcích:
- Přidání nebo odebrání oblastí z databázového účtu
- Jak vytvořit vlastní zásady řešení konfliktů
- Pokoušíte se naplánovat kapacitu migrace do služby Azure Cosmos DB? Informace o stávajícím databázovém clusteru můžete použít k plánování kapacity.
- Pokud víte, že je počet virtuálních jader a serverů ve vašem existujícím databázovém clusteru, přečtěte si o odhadu jednotek žádostí pomocí virtuálních jader nebo virtuálních procesorů.
- Pokud znáte typické sazby požadavků pro vaši aktuální úlohu databáze, přečtěte si informace o odhadu jednotek žádostí pomocí plánovače kapacity služby Azure Cosmos DB.