Správa zásad indexování ve službě Azure Cosmos DB
PLATÍ PRO: ![]() NoSQL
NoSQL
Ve službě Azure Cosmos DB se data indexují podle zásad indexování definovaných pro každý kontejner. Výchozí zásady indexování pro nově vytvořené kontejnery u všech řetězců a čísel vynucují indexy rozsahu. Tuto zásadu můžete přepsat vlastními zásadami indexování.
Poznámka:
Metoda aktualizace zásad indexování popsaných v tomto článku se týká pouze služby Azure Cosmos DB for NoSQL. Přečtěte si o indexování ve službě Azure Cosmos DB pro MongoDB a sekundárním indexování ve službě Azure Cosmos DB pro Apache Cassandra.
Příklady zásad indexování
Tady je několik příkladů zásad indexování zobrazených ve formátu JSON. Zobrazují se na webu Azure Portal ve formátu JSON. Stejné parametry je možné nastavit prostřednictvím Azure CLI nebo jakékoli sady SDK.
Zásady odhlášení pro selektivní vyloučení některých cest vlastností
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Zásady výslovného souhlasu se selektivním zahrnutím některých cest vlastností
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Poznámka:
Obecně doporučujeme používat zásady indexování, které se odhlašují. Azure Cosmos DB proaktivně indexuje všechny nové vlastnosti, které se můžou přidat do datového modelu.
Použití prostorového indexu pouze na konkrétní cestě vlastnosti
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Příklady zásad indexování vektorů
Kromě zahrnutí nebo vyloučení cest pro jednotlivé vlastnosti můžete také zadat vektorový index. Obecně platí, že indexy vektorů by měly být zadány vždy, když VectorDistance se systémová funkce používá k měření podobnosti mezi vektorem dotazu a vektorovou vlastností.
Poznámka:
Abyste mohli ve službě Azure Cosmos DB for NoSQL noSQL používat vektorové vyhledávání ve službě Azure Cosmos DB for NoSQL, musíte se zaregistrovat ve verzi Preview.>
Důležité
Zásada indexování vektorů musí být na cestě definované v zásadách vektoru kontejneru. Přečtěte si další informace o zásadách vektoru kontejneru.)
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Můžete definovat následující typy zásad indexu vektorů:
| Typ | Popis | Maximální rozměry |
|---|---|---|
flat |
Ukládá vektory do stejného indexu jako ostatní indexované vlastnosti. | 505 |
quantizedFlat |
Kvantuje (komprimuje) vektory před uložením do indexu. To může zlepšit latenci a propustnost za cenu malé přesnosti. | 4096 |
diskANN |
Vytvoří index založený na diskANN pro rychlé a efektivní přibližné vyhledávání. | 4096 |
quantizedFlat Typy indexů flat využívají index služby Azure Cosmos DB k ukládání a čtení jednotlivých vektorů při hledání vektorů. Vektorové vyhledávání s indexem jsou vyhledávání hrubou flat silou a vytvářejí 100% přesnost. Existují však omezení 505 dimenzí vektorů na plochém indexu.
Index quantizedFlat ukládá do indexu kvantované nebo komprimované vektory. Vektorové vyhledávání s indexem quantizedFlat jsou také hrubou silou hledání, ale jejich přesnost může být o něco menší než 100 %, protože vektory jsou před přidáním do indexu kvantovány. Hledání vektorů by quantized flat ale mělo mít nižší latenci, vyšší propustnost a nižší náklady na RU než vektorové vyhledávání v indexu flat . Tato možnost je vhodná pro scénáře, ve kterých používáte filtry dotazů k zúžení vektorového vyhledávání na relativně malou sadu vektorů.
Index diskANN je samostatný index definovaný speciálně pro vektory využívající DiskANN, sadu vysoce výkonných algoritmů indexování vektorů vyvinutých společností Microsoft Research. Indexy DiskANN můžou nabízet některé dotazy s nejnižší latencí, dotazy s nejvyšším dotazem za sekundu (QPS) a dotazy s nejnižšími náklady na RU s vysokou přesností. Vzhledem k tomu, že diskANN je přibližný index nejbližších sousedů (ANN), může být přesnost nižší než quantizedFlat nebo flat.
Příklady složených zásad indexování
Kromě zahrnutí nebo vyloučení cest pro jednotlivé vlastnosti můžete také zadat složený index. Chcete-li provést dotaz, který má ORDER BY klauzuli pro více vlastností, je pro tyto vlastnosti vyžadován složený index . Pokud dotaz obsahuje filtry spolu s řazením více vlastností, možná budete potřebovat více než jeden složený index.
Složené indexy mají také výhodu výkonu pro dotazy, které mají více filtrů, nebo filtr i klauzuli ORDER BY.
Poznámka:
Složené cesty mají implicitní, /? protože indexuje se pouze skalární hodnota v této cestě. Zástupný /* znak není podporován ve složených cestách. Neměli byste zadávat /? ani /* ve složené cestě. Složené cesty také rozlišují malá a velká písmena.
Složený index definovaný pro (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Složený index pro název a věk se vyžaduje pro následující dotazy:
Dotaz č. 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Dotaz č. 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Tento složený index přináší následující dotazy a optimalizuje filtry:
Dotaz č. 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Dotaz č. 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Složený index definovaný pro (název ASC, věk ASC) a (název ASC, age DESC)
V rámci stejné zásady indexování můžete definovat více složených indexů.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Složený index definovaný pro (název ASC, věk ASC)
Je volitelné zadat objednávku. Pokud není zadáno, pořadí je vzestupné.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Vyloučit všechny cesty vlastností, ale zachovat aktivní indexování
Tuto zásadu můžete použít, pokud je aktivní funkce TTL (Time-to-Live), ale k použití služby Azure Cosmos DB jako čistě úložiště klíč-hodnota nejsou potřeba žádné další indexy.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Bez indexování
Tato zásada vypne indexování. Pokud indexingMode je nastavená hodnota none, nemůžete v kontejneru nastavit hodnotu TTL.
{
"indexingMode": "none"
}
Aktualizace zásad indexování
Ve službě Azure Cosmos DB je možné zásady indexování aktualizovat pomocí některé z následujících metod:
- Pomocí webu Azure Portal
- Použití Azure CLI
- Pomocí prostředí PowerShell
- Použití jedné ze sad SDK
Aktualizace zásad indexování aktivuje transformaci indexu. Průběh této transformace lze také sledovat ze sad SDK.
Poznámka:
Při aktualizaci zásad indexování se zápisy do služby Azure Cosmos DB nepřerušují. Další informace o transformacích indexování
Důležité
Odebrání indexu se projeví okamžitě, zatímco přidání nového indexu nějakou dobu trvá, protože vyžaduje transformaci indexování. Při nahrazení jednoho indexu jiným (například nahrazení jednoho indexu vlastností složeným indexem) nezapomeňte nejprve přidat nový index a potom počkat na dokončení transformace indexu před odebráním předchozího indexu ze zásad indexování. Jinak to negativně ovlivní vaši schopnost dotazovat se na předchozí index a může narušit všechny aktivní úlohy, které odkazují na předchozí index.
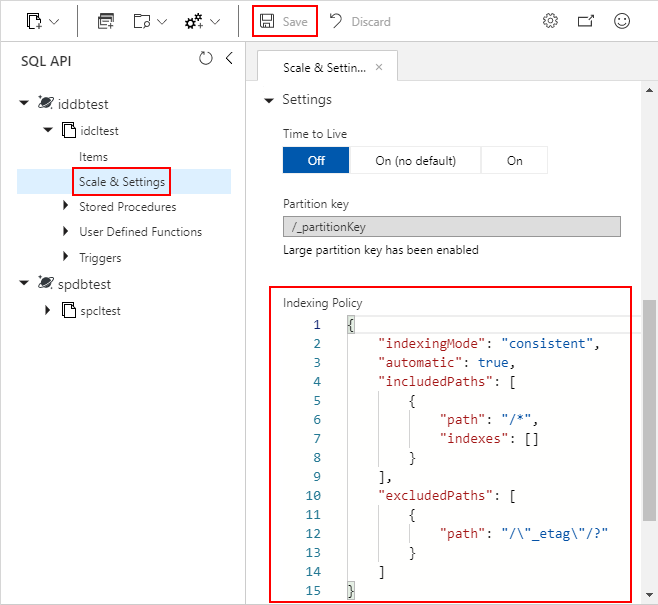
Použití portálu Azure Portal
Kontejnery Azure Cosmos DB ukládají své zásady indexování jako dokument JSON, který vám azure Portal umožňuje přímo upravovat.
Přihlaste se k portálu Azure.
Vytvořte nový účet služby Azure Cosmos DB nebo vyberte existující účet.
Otevřete podokno Průzkumník dat a vyberte kontejner, na který chcete pracovat.
Vyberte Škálovat a nastavení.
Upravte dokument JSON zásad indexování, jak je znázorněno v těchto příkladech.
Až budete hotovi, zvolte tlačítko Uložit.
Použití Azure CLI
Pokud chcete vytvořit kontejner s vlastní zásadou indexování, přečtěte si téma Vytvoření kontejneru s vlastními zásadami indexu pomocí rozhraní příkazového řádku.
Použití PowerShellu
Pokud chcete vytvořit kontejner s vlastní zásadou indexování, přečtěte si téma Vytvoření kontejneru s vlastními zásadami indexu pomocí PowerShellu.
Použití sady .NET SDK
Objekt ContainerProperties ze sady .NET SDK v3 zveřejňuje IndexingPolicy vlastnost, která umožňuje změnit IndexingMode a přidat nebo odebrat IncludedPaths a ExcludedPaths. Další informace najdete v tématu Rychlý start: Klientská knihovna Azure Cosmos DB for NoSQL pro .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Chcete-li sledovat průběh transformace indexu, předejte RequestOptions objekt, který nastaví PopulateQuotaInfo vlastnost na true. Načtěte hodnotu z hlavičky x-ms-documentdb-collection-index-transformation-progress odpovědi.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Rozhraní API sady SDK V3 fluent umožňuje napsat tuto definici stručným a efektivním způsobem při definování vlastních zásad indexování při vytváření nového kontejneru:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Použití sady Java SDK
Objekt DocumentCollection ze sady Java SDK zveřejňuje getIndexingPolicy() metody a setIndexingPolicy() metody. Objekt IndexingPolicy , se kterým manipuluje, umožňuje změnit režim indexování a přidat nebo odebrat zahrnuté a vyloučené cesty. Další informace najdete v tématu Rychlý start: Vytvoření aplikace Java pro správu dat Azure Cosmos DB for NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Pokud chcete sledovat průběh transformace indexu v kontejneru, předejte RequestOptions objekt, který požaduje naplnění informací o kvótách. Načtěte hodnotu z hlavičky x-ms-documentdb-collection-index-transformation-progress odpovědi.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Použití sady Node.js SDK
Rozhraní ContainerDefinition ze sady Node.js SDK zveřejňuje indexingPolicy vlastnost, která umožňuje změnit indexingMode a přidat nebo odebrat includedPaths a excludedPaths. Další informace najdete v tématu Rychlý start – Klientská knihovna Azure Cosmos DB for NoSQL pro Node.js.
Načtěte podrobnosti kontejneru:
const containerResponse = await client.database('database').container('container').read();
Nastavte režim indexování na konzistentní:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Přidání zahrnuté cesty včetně prostorového indexu:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Přidat vyloučenou cestu:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Aktualizujte kontejner změnami:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Chcete-li sledovat průběh transformace indexu v kontejneru, předejte RequestOptions objekt, který nastaví populateQuotaInfo vlastnost na true. Načtěte hodnotu z hlavičky x-ms-documentdb-collection-index-transformation-progress odpovědi.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Použití sady Python SDK
Při použití sady Python SDK V3 se konfigurace kontejneru spravuje jako slovník. Z tohoto slovníku můžete získat přístup k zásadám indexování a všem jeho atributům. Další informace najdete v tématu Rychlý start: Klientská knihovna Azure Cosmos DB for NoSQL pro Python.
Načtěte podrobnosti kontejneru:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Nastavte režim indexování na konzistentní:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definujte zásadu indexování s zahrnutou cestou a prostorovým indexem:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Definujte zásadu indexování s vyloučenou cestou:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Přidejte složený index:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Aktualizujte kontejner změnami:
response = client.ReplaceContainer(containerPath, container)
Další kroky
Další informace o indexování najdete v následujících článcích:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro