Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Azure Cosmos DB for PostgreSQL se už pro nové projekty nepodporuje. Tuto službu nepoužívejte pro nové projekty. Místo toho použijte jednu z těchto dvou služeb:
Azure Cosmos DB for NoSQL můžete použít pro distribuované databázové řešení navržené pro vysoce škálovatelné scénáře s 99,999% smlouvou o úrovni služeb (SLA), okamžitým automatickým škálováním a automatickým převzetím služeb při selhání napříč několika oblastmi.
Použijte funkci Elastic Clusters služby Azure Database for PostgreSQL pro horizontálně dělené PostgreSQL pomocí opensourcového rozšíření Citus.
Výběr distribučního sloupce tabulky představuje jedno z nejdůležitějších rozhodnutí při modelování. Azure Cosmos DB for PostgreSQL ukládá řádky do shardů na základě hodnoty distribučního sloupce těchto řádků.
Správná volba seskupí související data na stejných fyzických uzlech, což umožňuje rychlé dotazy a přidává podporu pro všechny funkce SQL. Nesprávná volba způsobí, že systém běží pomalu.
Obecné tipy
Tady jsou čtyři kritéria pro výběr ideálního distribučního sloupce pro distribuované tabulky.
Vyberte sloupec, který je centrální součástí úlohy aplikace.
Tento sloupec si můžete představit jako "srdce", "centrální část" nebo "přirozenou dimenzi" pro dělení dat.
Příklady:
-
device_idv pracovní zátěži IoT -
security_idfinanční aplikace, která slouží ke sledování cenných papírů -
user_idv analýze uživatelů -
tenant_idpro víceklientské aplikace SaaS
-
Vyberte sloupec s slušnou kardinalitou a rovnoměrným statistickým rozdělením.
Sloupec by měl mít mnoho hodnot a být rovnoměrně a důkladně rozprostřen mezi všechny shardy.
Příklady:
- Kardinalita větší než 1000
- Nevybíjejte sloupec, který má stejnou hodnotu u velkého procenta řádků (nerovnoměrná distribuce dat).
- V úloze SaaS může způsobit nerovnoměrnou distribuci dat to, že jeden tenant je mnohem větší než ostatní. V takovém případě můžete pomocí izolace tenanta vytvořit vyhrazený horizontální oddíl pro zpracování tenanta.
Vyberte sloupec, který má výhody pro vaše stávající dotazy.
Pro transakční nebo provozní úlohu (kde většina dotazů trvá jen několik milisekund), vyberte sloupec, který se zobrazí jako filtr v
WHEREklauzulích pro nejméně 80 % dotazů. Sloupecdevice_idnapříklad vSELECT * FROM events WHERE device_id=1.Pro analytickou úlohu (kde většina dotazů trvá 1 až 2 sekundy) vyberte sloupec, který umožňuje paralelizaci dotazů napříč pracovními uzly. Například sloupec, který se často vyskytuje v klauzulích GROUP BY, nebo dotazovaný na více hodnot najednou.
Vyberte sloupec, který se nachází ve většině velkých tabulek.
Tabulky nad 50 GB by se měly distribuovat. Výběr stejného distribučního sloupce pro všechny umožňuje konsolidovat data pro tento sloupec na pracovních uzlech. Spolulokace umožňuje efektivní provádění JOINů a agregací a vynucování cizích klíčů.
Ostatní (menší) tabulky můžou být místní nebo referenční tabulky. Pokud menší tabulka potřebuje SPOJIT s distribuovanými tabulkami, vytvořte ji jako referenční tabulku.
Příklady použití
Viděli jsme obecná kritéria pro výběr distribučního sloupce. Teď se podíváme, jak se vztahují na běžné případy použití.
Aplikace s více tenanty
Architektura s více tenanty používá k distribuci dotazů napříč uzly v clusteru formu hierarchického modelování databáze. Horní část hierarchie dat se označuje jako ID tenanta a musí být uložena ve sloupci v každé tabulce.
Azure Cosmos DB for PostgreSQL kontroluje dotazy, aby zjistil, které ID tenanta zahrnují, a najde odpovídající shard tabulky. Dotaz se směruje na jeden pracovní uzel, který obsahuje shard. Spuštění dotazu se všemi relevantními daty umístěnými na stejném uzlu se nazývá kolokace.
Následující diagram znázorňuje kolokaci v datovém modelu s více tenanty. Obsahuje dvě tabulky, Účty a Kampaně, z nichž každá je distribuována account_id. Stínovaná pole představují části. Zelené šardy jsou uloženy společně na jednom pracovním uzlu a modré šardy jsou uloženy na dalším pracovním uzlu. Všimněte si, že dotaz spojení mezi účty a kampaněmi obsahuje všechna potřebná data na jednom uzlu, pokud jsou obě tabulky omezené na stejnou account_id.
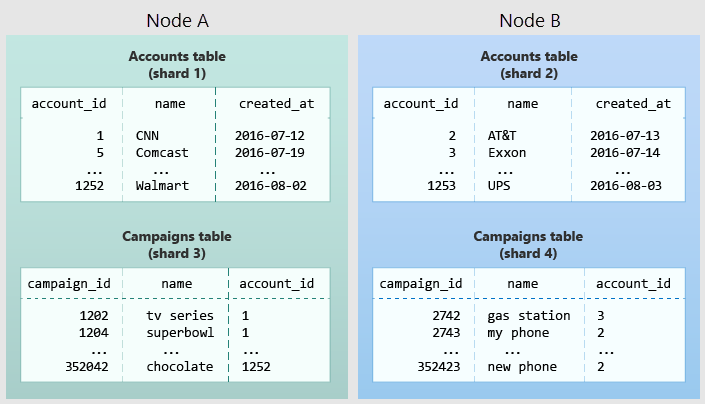
Pokud chcete tento návrh použít ve vlastním schématu, určete, co představuje tenanta ve vaší aplikaci. Mezi běžné instance patří společnost, účet, organizace nebo zákazník. Název sloupce bude něco podobného company_id nebo customer_id. Prozkoumejte každý z vašich dotazů a zeptejte se sami sebe, fungoval by, kdyby obsahoval více klauzulí WHERE, aby se omezily všechny tabulky na řádky se stejným identifikátorem nájemce? Dotazy v modelu s více tenanty jsou vymezeny na tenanta. Dotazy na prodej nebo inventář jsou například vymezeny v určitém obchodě.
Osvědčené postupy
- Distribuujte tabulky podle společného sloupce tenant_id. Například v aplikaci SaaS, kde jsou tenanti společnostmi, bude tenant_id pravděpodobně company_id.
- Převod malých tabulek mezi tenanty na referenční tabulky. Pokud několik tenantů sdílí malou tabulku informací, distribuujte ji jako referenční tabulku.
- Omezte filtrování všech aplikačních dotazů podle tenant_id. Každý dotaz by měl požadovat informace pro jednoho tenanta najednou.
Příklad sestavení tohoto typu aplikace najdete v kurzu s více tenanty.
Aplikace v reálném čase
Architektura s více tenanty představuje hierarchickou strukturu a používá kolokaci dat ke směrování dotazů na tenanta. Naproti tomu architektury v reálném čase závisí na konkrétních distribučních vlastnostech jejich dat, aby bylo dosaženo vysoce paralelního zpracování.
Jako termín pro distribuční sloupce v modelu v reálném čase používáme "ID entity". Typické entity jsou uživatelé, hostitelé nebo zařízení.
Dotazy v reálném čase obvykle požádají o číselné agregace seskupené podle data nebo kategorie. Azure Cosmos DB for PostgreSQL odesílá tyto dotazy do každého shardu pro částečné výsledky a sestaví konečnou odpověď na koordinační uzel. Dotazy běží nejrychleji, když co nejvíce uzlů přispívá, a když žádný jeden uzel nesmí provádět nepřiměřenou práci.
Osvědčené postupy
- Zvolte sloupec s vysokou kardinalitou jako distribuční sloupec. Pro porovnání je pole Stav v tabulce objednávek s hodnotami New, Paid a Shipped špatnou volbou distribučního sloupce. Připouští pouze tyto omezené hodnoty, což omezuje počet shardů, které mohou uchovávat data, a počet uzlů, které je mohou zpracovat. Mezi sloupci s vysokou kardinalitou je také vhodné zvolit sloupce, které se často používají v klauzulích GROUP BY nebo jako klíče pro spojení.
- Zvolte sloupec se sudým rozdělením. Pokud distribuujete tabulku na sloupci zkresleném směrem k určitým běžným hodnotám, data v tabulce mají tendenci se hromadit v určitých fragmentech. Uzly, které obsahují tyto části, nakonec dělají více práce než jiné uzly.
- Distribuce tabulek faktů a dimenzí ve společných sloupcích Tabulka faktů může mít pouze jeden distribuční klíč. Tabulky, které se spojují na jiném klíči, nebudou umístěny společně s tabulkou faktů. Zvolte jednu dimenzi, kterou umístíte na základě četnosti spojování a velikosti řádků, které se spojují.
- Změňte některé tabulky dimenzí na referenční tabulky. Pokud tabulku dimenzí nelze společně s tabulkou faktů připojit, můžete zlepšit výkon dotazů tak, že distribuujete kopie tabulky dimenzí do všech uzlů ve formě referenční tabulky.
V kurzu řídicího panelu v reálném čase si můžete přečíst příklad, jak tento druh aplikace sestavit.
Data časových řad
V úloze časových řad se aplikace dotazují na poslední informace, zatímco archivují staré informace.
Nejběžnější chybou při modelování informací časových řad ve službě Azure Cosmos DB for PostgreSQL je použití samotného časového razítka jako distribučního sloupce. Rozdělování pomocí hash na základě času distribuuje čas zdánlivě náhodně do různých shardů spíše než udržováním časových rozsahů pohromadě ve stejných shardech. Dotazy, které zahrnují čas, se obecně vztahují k časovým rozsahům, například k nejnovějším datům. Tento typ distribuce hodnot hash vede ke zvýšení zátěže sítě.
Osvědčené postupy
- Nevybírejte časové razítko jako distribuční sloupec. Zvolte jiný distribuční sloupec. V aplikaci s více tenanty použijte ID tenanta nebo v aplikaci v reálném čase použijte ID entity.
- Místo toho používejte dělení tabulek PostgreSQL podle času. Dělení tabulky slouží k rozdělení velké tabulky časově uspořádaných dat do několika zděděných tabulek s každou tabulkou obsahující různé časové rozsahy. Distribuce particionované tabulky v Postgresu vytváří shardy pro zděděné tabulky.
Další kroky
- Zjistěte, jak kolokace mezi distribuovanými daty pomáhá rychle spouštět dotazy.
- Seznamte se s distribučním sloupcem distribuované tabulky a dalšími užitečnými diagnostickými dotazy.